
Either I’m going to get increasingly good at apologizing to fewer and fewer people or we’re going to get better at this. I vote for the later.
We’ve had some issues with the service over the past week and a half. I feel terrible about it and I can’t apologize enough. It’s the biggest incident we’ve had since the instability created by our service refactoring in the March/April timeframe. I know it’s not much consolation but I can assure you that we have taken the issue very seriously and there are a fair number of people on my team who haven’t gotten much sleep recently.
The incident started the morning of the Visual Studio 2013 launch when we introduced some significant performance issues with the changes we made. You may not have noticed it by my presentation but for the couple of hours before I was frantically working with the team to restore the service.
At launch, we introduced the commercial terms for the service and enabled people to start paying for usage over the free level. To follow that with a couple of rough weeks is leaving a bad taste in my mouth (and yours too, I’m sure). Although the service is still officially in preview, I think it’s reasonable to expect us to do better. So, rather than start off on such a sour note, we are going to extend the “early adopter” program for 1 month giving all existing early adopters an extra month at no charge. We will also add all new paying customers to the early adopter program for the month of December – giving them a full month of use at no charge. Meanwhile we’ll be working hard to ensure things run more smoothly.
Hopefully that, at least, demonstrates that we’re committed to offering a very reliable service. For the rest of this post, I’m going to walk through all the things that happened and what we learned from them. It’s a long read and it’s up to you how much of it you want to know.
Here’s a picture of our availability graph to save 1,000 words:
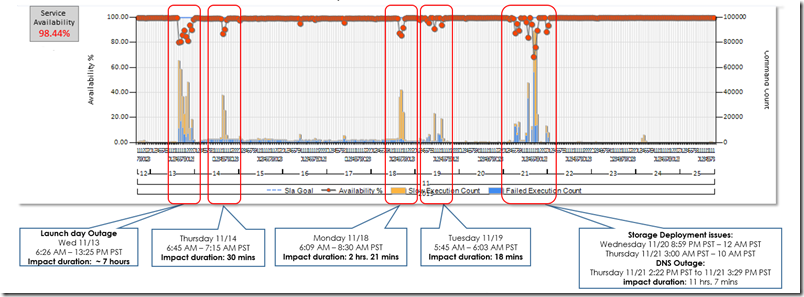
First Incident: Nov 13, 14, 18, 19
Let’s start with the symptoms. What users saw was that the service became very slow to the point of being unresponsive during peak traffic periods. Peak hours start mid-morning on the east coast of the US – right when we were doing the launch keynote 🙁
The beginning coincided with the changes we made to enable the new branding and billing right before the launch.
We’ve gotten to a fairly mature stage of dealing with live-site incidents. We detect them quickly, triage them, bring in the right developers, collaborate and fan out to all the various people who need to know/contribute, including pulling in partner teams like Azure fabric, SQL Azure, ACS, etc. Despite that this one took us a long time to diagnose for a number of reasons – for one, it was the first incident of this nature that we have ever hit (more on that in a minute).
One of the things we did fairly early on was to rollback all of the feature switches that we enabled that morning – thinking just undoing the changes would likely restore the service. Unfortunately it didn’t. And no one is completely sure why. There were some aspects of the issue that had been there for a while and were triggered by the spike in load that we saw but the bulk of the issue really was caused by the enabling of the feature flags. It’s possible that some error was made in rolling them back but, at this point they’ve been changed enough times that it’s hard to tell for certain.
Let’s talk about what we do know.
Within a fairly short period of time, we discovered that the biggest underlying symptom of the problem was SNAT port exhaustion. SNAT is a form of network address translations for outgoing calls from a service on Azure (for instance, calls from TFS –> SQLAzure, Azure storage, our accounts service, ACS, etc). For any given destination there are only 64K ports and once you exhaust them, you can no longer talk to the service – the networking infrastructure stops you. This is a design pattern you really need to think about with multi-tier, scale out services because the multiplexing across tiers with VIPs (virtual IP addresses) can explode the use of these SNAT ports.
This was the first incident that we had where the core issue was a networking mechanics issue and we didn’t have a great deal of experience. After struggling to identify what was happening for a few hours – and finally figuring out the port exhaustion issue, we pulled in the Azure networking team to provide us the expertise to further diagnose the issue. The core thing we struggled with next was figuring which service we were talking to was using up all the SNAT ports. This ultimately uncovered 2 “issues” that will get fixed:
- The Windows Azure networking infrastructure logging records which source IP address exhausted SNAT ports but not the target IP so the logs didn’t help us figure out which service was killing us. Azure has now decided to add that to their logging info to make future incidents easy to diagnose.
- We, at the VSOnline level, have pretty involved trace information. However, we eventually discovered that we were missing the trace point for the one target service that was actually the choke point here. It was our connection to ACS. We have gone back and made sure that we have trace points for every single service we talk to.
Once we understood the right code path that was causing it, we were able to focus our efforts. As with most of these things, it was not one bug but rather the interaction of several.
Send some people home
A brief aside… I was at the launch with a bunch of people when this happened. One of them was Scott Guthrie. Throughout the day we were chatting about the problems we were having and how the diagnostics were going. He gave me a piece of advice. Send some people home. He related to me a story about a particularly bad incident they had 18 month ago or so. He said the whole dev team was up for 36 hours working on it. They had a fix, deployed it and, unfortunately, not only did it not resolve the problem, it made it worse. After 36 hours of straight work, no one on the dev team was coherent enough to work effectively on the new problem. They now have a policy that after so many hours of working on a problem, they send half the team home to sleep in case they need to start rotating fresh people. That made a ton of sense to me so we did the same thing at about 8:00pm that evening.
The core problem
On launch day, we enabled a feature flag that required customers to accept some “terms of service” statements. Those statements had been on the service for a while and most people had already accepted them but on launch day we started enforcing it in order to keep using the service.
However, there were 55 clients out there in the world who had automated tools set up, regularly pinging the service using accounts that no human had logged into to accept the terms of service. Those 55 clients were the trigger for the bug.
Those requests went to TFS. TFS then made a request “on behalf of the client” to our account service to validate the account’s access.
The first bug was that the account service returned a 401 – Unauthenticated error rather than a 403 – Unauthorized error when it determined that the account had not accepted the terms of service.
The second bug was that TFS, upon receiving that error, rather than just failing the request interpreted it as indicating that the ACS token that the TFS service itself used was invalid and it decided to contact ACS to refresh the token. It nulled out the token member variable and initiated an ACS request to refill it.
The third bug was that the logic that was supposed to make subsequent requests block waiting for ACS to return was broken and, instead, every other request would call ACS to refresh the token.
The net result was a storm of requests to ACS that exhausted SNAT ports and prevented authentications.
Once we did the minimal fix to address this problem (by fixing the logic that allows all requests to fall through to ACS) the situation got MUCH better and was why Monday was much better than Wed or Thurs of the previous week.
However, it turns out there was another problem hiding behind that one. Once we eliminated ACS SNAT port exhaustion, we still had a small(er) incident on Monday.
The second problem
In order to avoid calling through to the account service, we “cache” validations and check them in TFS and we save the round trip. The “main” way we do this is by wrapping the validation in the token/cookie returned to the client. So when a client comes back with the cookie TFS checks the signature, the expiration date and the claim and accepts the claim. It only falls through to the account service when this check fails.
When this logic was implemented, it was decided not to change the token format for older clients – for fear of breaking older clients and not wanting to have to update them. So instead, older clients use a more traditional “hash table” cache in TFS. It turns out that the hash table cache was broken and always caused fall through to the account service.
Unfortunately, on Monday, someone with an old client was running hundreds of thousands of requests against TFS (about 8 per second). Combined with our daily peak load, this caused a storm against the account service and again slowed things down unacceptably.
Part 2 of Monday’s incident was a bug where TFS was holding a global lock while it made a call to our accounts service. This code path is not executed on every request but it is executed often enough that it caused the lock to serialize a large number of requests that should have been executed in parallel. That contributed to the overall slow down.
As often happens in a prolonged case like this, along the way we found many other things that turned out not to be “the issue” but none-the-less are worth fixing. My favorite was a regex expression that was sucking down 25% of the CPU on an AT just to re-write the account creation URL to include the proper locale. Yeah, that’s crazy.
All-in-all it was a bad incident but quite a number of improvements will come out of it.
Retrospective
With the incident now understood and mitigated, the next thing we’ll turn our attention to is the retrospective. I think we’ll end up with a lot of learnings. Among them are:
- We really need multi-instance support. The current service is one instance. It’s scaled out but you either update it or you don’t. Aside from our ability to control with feature flags (which is very nice) all customers are affected or none. The service is now at a scale where there’s just too much risk in that. We need to be able to enable multi-instance so that we can roll out changes to smaller groups of people and observe the behavior in a production environment. We already have a team working on this but the result of this incident is that we’ve accelerated that work.
- Most sophisticated multi-threaded apps have a lock manager. A lock manager manages lock acquisition and ordering, causing illegal ordering (that might cause a deadlock) to fail immediately. This turns a potential race condition into something that’s detected every time the code path is executed. One of the things I learned here is that we need to extend that mechanism to also detect cases where we are holding onto important exhaustible resources (like connections, locks, etc) across potentially slow and unpredictable operations (like cross service calls). You have to assume any service can fail and you can not allow that failure (through resource exhaustion or any other means) to cascade into a broader failure across the service. Contain the failure to only the capabilities directly affected by the failure.
- We need to revisit our pre-production load testing. Some of these issues should have been caught before they went to production. This is a delicate balance because “there’s no place like production” but “trust thy neighbor but lock your door.”
- I think there’s another turn of the crank we can take in evolving some of our live site incident management/debugging process. This includes improvements in telemetry. We should have been able to get to the bottom of these issues sooner.
There’s more and I’m looking forward to the retrospective to get everyone’s perspective.
Second Incident: Nov 20th
Unfortunately bad luck comes in 3’s and we got hit with a pair of incidents on Wed. The first was an intermittent failure in Windows Azure Storage. It appears (but I don’t have all the facts yet) that Azure was doing an upgrade on the cluster we use for VS Online and something went wrong with the upgrade. The result were intermittent outages starting 9:00PM PST on Wed night and going through lunch time on Thurs, unfortunately right through another peak usage time for us. Then, to add insult to injury, someone made an error in some global Microsoft networking setting, breaking a DNS setting, that impacted our service and many others across Microsoft. That added about another hour to our misery in the mid-afternoon.
Now, I don’t want to point fingers here because this was another example where a failure in one of the services we consume cascaded into having a much larger impact on our service than it should have. The changes that I talked about above (managing exhaustible resources and unreliable operations) would have help significantly mitigated this incident.
All-in-all, it was an inauspicious week and a half. We are going to have incidents. Every service does. You can plan and test and be robust and there will be issues. However, what we’ve experienced recently isn’t reflective of what we are committed to providing. It’s been a painful but productive learning experience and I believe the result will be a more robust service. I appreciate your patience and we will continue to work hard to provide the best service there is. Anything less is unacceptable.
Brian
0 comments
Be the first to start the discussion.