
Hello prompt engineers,
There are a number of different strategies to support an ‘infinite chat’ using an LLM, required because large language models do not store ‘state’ across API requests and there is a limit to how large a single request can be.
In this OpenAI community question on token limit differences in API vs Chat, user damc4 outlines three well-known methods to implement infinite chat:
- Sliding context window
- Summarization
- Embeddings
The thread also suggests tools like Langchain can help to implement these approaches, but for learning purposes, we’ll examine them from first principles within the context of the Jetchat sample. This week’s blog discusses the first method – a sliding context window – in our Android OpenAI chat sample.
Before we begin…
We’re going to add a sliding window feature to the droidcon conference chat code in the Jetchat sample on GitHub.
Configuration changes
The sliding window is required because without it, eventually a long conversation will hit the token limit. In order to make this easier to test, set the OPENAI_CHAT_MODEL in Constants.kt to gpt-3.5-turbo which (currently) has a 4,096 token limit. Using the model with the lowest limit will make it easier to hit the boundary condition because we’ll need fewer interactions to test hitting the limit.
Calculating tokens
Last week’s post discussed OpenAI tokens and limits, including a link to the interactive tokenizer. The page includes links to Python and Javascript code for tokenizing inputs. Unfortunately, there doesn’t seem to be anything ‘off the shelf’ for Kotlin right now, so for now we’re going to use a rough approximation, which you can find in the Tokenizer class in the Jetchat example on GitHub.
Test data
The other thing that will help with testing is user inputs that have a ‘roughly known’ token size, so that we can reproduce the failure case easily and repeatably. From the examples last week, queries for sessions about “gradle” and “jetpack compose” result in a large number of matching embeddings that use up one- to two-thousand tokens. With just those two queries, it’s possible to trigger the error state:
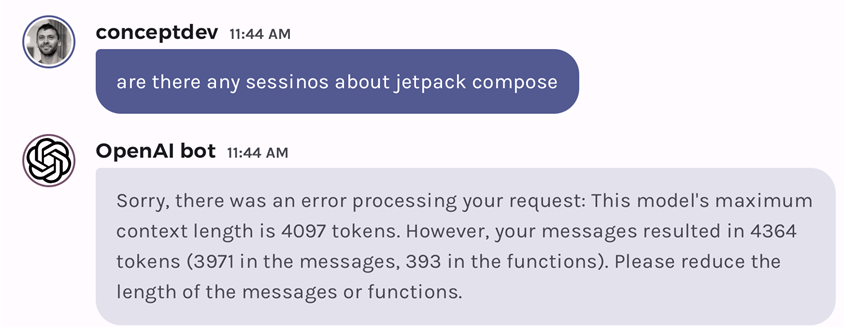
Figure 1: error when token limit is exceeded
By choosing a model with a low token limit and by testing with queries that require a large number of tokens to process, we can easily reproduce the issue, then build and test a fix.
Inexact science
As mentioned above, the Kotlin tokenizer is making a very rough guess based on averages, rather than parsing according to the well-known source. Similarly, because the Kotlin OpenAI client library abstracts away the serialization of arguments to and from JSON, we also don’t really have access to the exact payload that is being sent and received from the API. We also can’t really predict with accuracy how many tokens to expect in our response.
To get around this issue, the token calculations err on the size of overestimating, such that we’re less likely to hit edge cases where the API might be send a message that exceeds the limit. With more research it would be possible to better understand the underlying message sizes and write a better tokenizer… these are left as an exercise for the reader.
Building a sliding window (by discarding older results)
“Sliding window” is just a fancy name for a FIFO (first in first out) queue. For an AI chat feature, as the number of tokens in the conversation history approach the maximum allowed by the model, we will discard the OLDEST interactions (both user messages and model responses). Those older interactions will be ‘forgotten’ by the model when it constructs responses to new queries (although there’s nothing to stop the UI from continuing to show the older messages as a long conversation thread).
Implementation in Jetchat
There are three new classes in the Jetchat demo project to support the sliding window:
-
Tokenizer– a basic averages-based token counter (number of characters divided by four). -
CustomChatMessage– a wrapper for theChatMessageclass that’s used to calculate the token usage for the message. As noted above, this also can only approximate the token size of the underlying JSON payload. -
SlidingWindow– helper class that contains the algorithm to loop through the conversation history, checking the token-size of each message and building a new message collection that is “guaranteed” to be smaller than the model’s token limit.
The SlidingWindow class is used in the DroidconEmbeddingsWrapper class right before the chatCompletionRequest is sent, to trim down the data used as the completion request parameter. The SlidingWindow.chatHistoryToWindow() function performs the following steps:
- Set up variables and values for the algorithm.
- Checks for a system message and saves it for later (otherwise it’s the ‘oldest’ message and could be ignored).
- Loops through the entire message history from newest to oldest, because we want to preserve the newest messages.
- Adds the system message back, reorders, and returns the message “window”
The code is shown here:
fun chatHistoryToWindow (conversation: MutableList<ChatMessage>): MutableList<ChatMessage> {
val tokenLimit = Constants.OPENAI_MAX_TOKENS
val expectedResponseSizeTokens = 500 // hardcoded estimate of max response size we expect (in tokens)
var tokensUsed = 0
var systemMessage: ChatMessage? = null
val tokenMax = tokenLimit - expectedResponseSizeTokens
var messagesInWindow = mutableListOf<ChatMessage>()
// check for system message (to preserve it even if others are removed)
if (conversation[0].role == ChatRole.System) {
systemMessage = conversation[0]
var systemMessageTokenCount = Tokenizer.countTokensIn(systemMessage.content)
tokensUsed += systemMessageTokenCount
}
// loop through messages until one takes us over the token limit
for (message in conversation.reversed()) {
if (message.role != ChatRole.System) {
var m = CustomChatMessage(message.role, "", message.content, message.name, message.functionCall)
if ((tokensUsed + m.getTokenCount()) < tokenMax) {
messagesInWindow.add(message)
tokensUsed += m.getTokenCount()
} else {
break // could optionally keep adding subsequent, smaller messages to context up until token limit
}
}
}
// add system message back if it existed
if (systemMessage != null) {
messagesInWindow.add(systemMessage)
}
// re-order so that system message is [0]
var orderedMessageWindow = messagesInWindow.reversed().toMutableList()
return orderedMessageWindow
}
Figure 2: sliding window algorithm
The usage in the DroidconEmbeddingsWrapper.chat() function is right before the creation of the chatCompletionRequest. The updated code passes the full conversation list of messages to the chatHistoryToWindow function, and then uses the subset of messages (the “sliding window”) that’s returned as the parameter for the chatCompletionRequest:
// implement sliding window
val chatWindowMessages = SlidingWindow.chatHistoryToWindow(conversation)
// build the OpenAI network request
val chatCompletionRequest = chatCompletionRequest {
model = ModelId(Constants.OPENAI_CHAT_MODEL)
messages = chatWindowMessages // previously sent the entire conversation
//...
Figure 3: snippet of code where the sliding window function is added into the existing chat feature
The remainder of the code is unchanged – subsequent model responses are added back to the main conversation list and the sliding window is re-calculated again for the next user query.
Fixed it!
To “prove” that the new algorithm works, the conversation in Figure 4 mimics the input used to trigger the error in Figure 1. The first two user queries – about “gradle” and “jetpack compose” – each result in a large number of embedding matches being included in the prompt (exemplified by the number of results to each – five sessions listed after the first query and ten sessions listed for the second). Prior to implementing the sliding window, the third query would have been expected to trigger an error that the maximum number of tokens was exceeded, but instead the third query (about “AI”) succeeds:
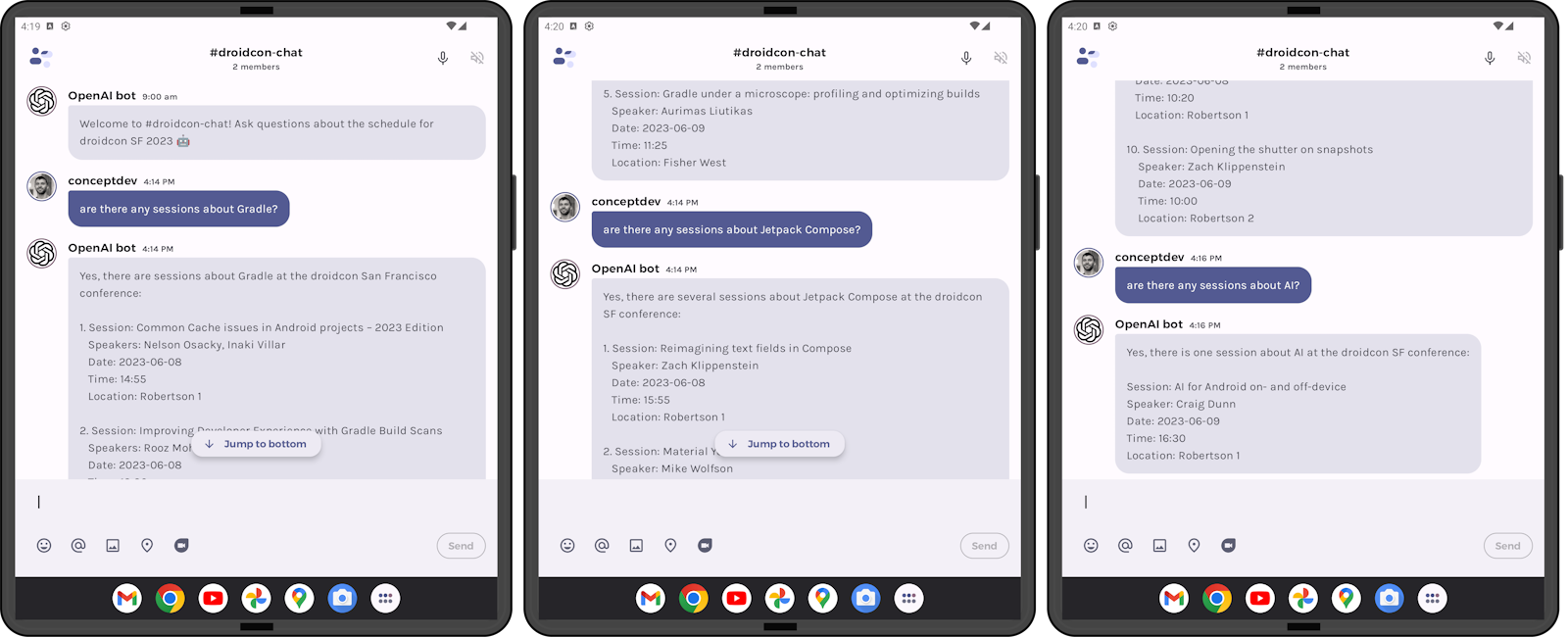
Figure 4: a three-interaction conversation where the first two questions have large embedding matches
The “proof” that the algorithm is working can be see in the logcat output (filtered by LLM-SW) shown in figure 5. The log shows each message from newest to oldest being compared against the “available tokens”, until one of the messages has so many tokens that including it would exceed the limit (114 tokens ‘available’ under the limit, and the “Gradle” query with embeddings requires 2033 tokens). That message is not included in the window, so the algorithm stops adding messages and returns the subset to be sent to the model.
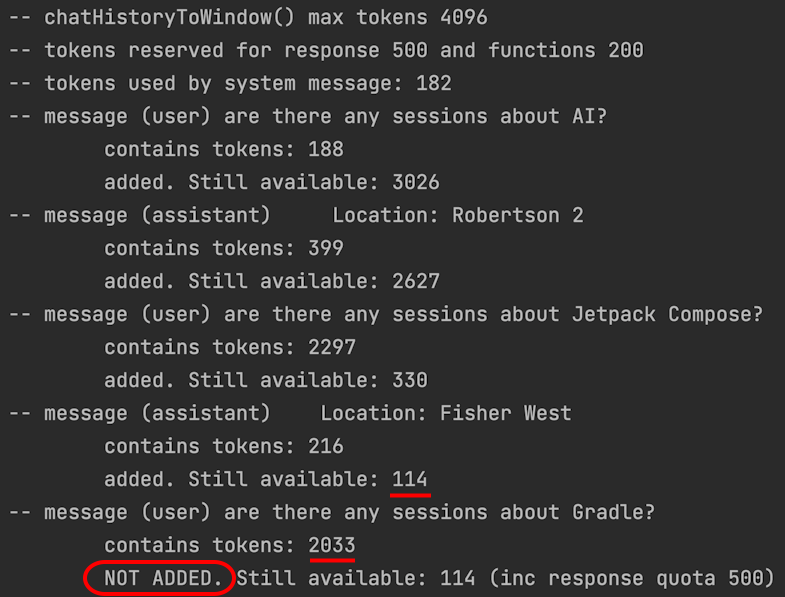
Figure 5: Logcat shows the sliding window calculation (in reverse chronological order) where the initial Gradle question and embeddings are removed from the context sent to the model
Sliding window for functions
The above examples and code snippets show queries that use embeddings to augment the model’s response. However, as discussed in the post on combining OpenAI functions with embeddings and OpenAI tokens and limits, the addition of function calls also has an impact on token usage. The local result of function calling requires another chat completion request be sent to the model to get the model’s final response.
To prevent the subsequent function call completion request from exceeding the token limit, we re-apply the sliding window algorithm to the updated conversation list, after the function-calling-messages have been added, as shown in figure 6:
// sliding window - with the function call messages we might need to remove more from the conversation history
val functionChatWindowMessages = SlidingWindow.chatHistoryToWindow(conversation)
// send the function request/response back to the model
val functionCompletionRequest = chatCompletionRequest {
model = ModelId(Constants.OPENAI_CHAT_MODEL)
messages = functionChatWindowMessages
}
Figure 6: re-apply the sliding window algorithm after including the function call request and local response
Recalculating the sliding window at this point may exclude even more older context from the start of the conversation to make room for the local function response to be added to the chat completion request.
Resources and feedback
Upcoming posts will continue the discussion about different ways to implement a long-term chat beyond a simple sliding window.
The OpenAI developer community forum has lots of discussion about API usage and other developer questions.
We’d love your feedback on this post, including any tips or tricks you’ve learning from playing around with ChatGPT prompts.
If you have any thoughts or questions, use the feedback forum or message us on Twitter @surfaceduodev.
There will be no livestream this week, but you can check out the archives on YouTube.
0 comments