
App Dev Manager Mike Barker builds on his previous article about Azure API Manager, exploring the pros and cons of various high availability and disaster recovery strategies.
In a previous post I discussed an approach to handling backend redundancy using Azure API Manager (APIM). In this post I want to discuss the various options for providing a high-availability (HA) and disaster recovery (DR) to your services exposed by API Manager.
Redundant Services in Azure
Before getting into the various options available let’s discuss the components which are relevant to delivering a high-availability solution within Azure.
Azure API Manager
Firstly, it is important to understand the redundancy available with API Manager. API Manager is composed of two components. There is the Service Management component which is responsible for servicing all of the administration and configuration calls, and the API Gateway component which services the actual endpoints which you are surfacing to your consumers and which routes the calls (via policy) to the backend services.
Using API Manager you can provision multiple API Gateway components (called “units” in the portal) and, under the Premium tier, these can be distributed across multiple regions (read more here). All of these gateways have the same configuration and policy definition, and therefore by default all point to the same backend endpoint. If you want your API Gateways to point to different backend endpoints you will need to modify the policy definition to route calls accordingly. Calls into API Manager will automatically be load-balanced to the closest available API Gateway, providing highly-available redundancy, as well as performance improvements to global users.
Notice however that the Service Management component does not replicate across regions, rather it exists only in the primary region. If the primary region experiences an outage, configuration changes cannot be made to the API Manager (including updating settings or policies).
Azure Traffic Manager
Azure Traffic Manager is a high-availability service which operates across Azure regions. It is a DNS-based load balancer which routes traffic globally to provide performance and resilience to your services. It uses endpoint monitoring to detect failures and, if a failure is detected, it will automatically “switch” the DNS entry served up to calls to re-route traffic to healthy endpoints.
You can read more about how Traffic Manager works here.
Azure Font Door
Azure Front Door is a new service offered by Microsoft (at the time of writing, in public preview). It offers a point-of-entry into Microsoft’s global network and provides you with automatic failover, high-availability and optimised performance. These entry points are global distributed to ensure that, no matter where your consumers are based geographically, an entry point exists close to them. These form the edge of the Microsoft network, and once the traffic is inside this network it can be routed to your services in whatever configuration is required.
Routing is done at layer 7, which means that traffic is directly controlled by Front Door and does not rely on DNS switching.
Like Traffic Manager health probes in Front Door monitor your services to provide automatic failover in the case of failure.
Creating a Highly-Available API Service
In a typical scenario we have a backend service which are fronted by API Manager and these endpoints are exposed to consumers. If we want to provide a true highly-available solution we need redundancy at every level, including the backend services and the API Manager layer. We also want to provide maximum performance to our consumers and therefore route them to the closest available endpoint to service their request.
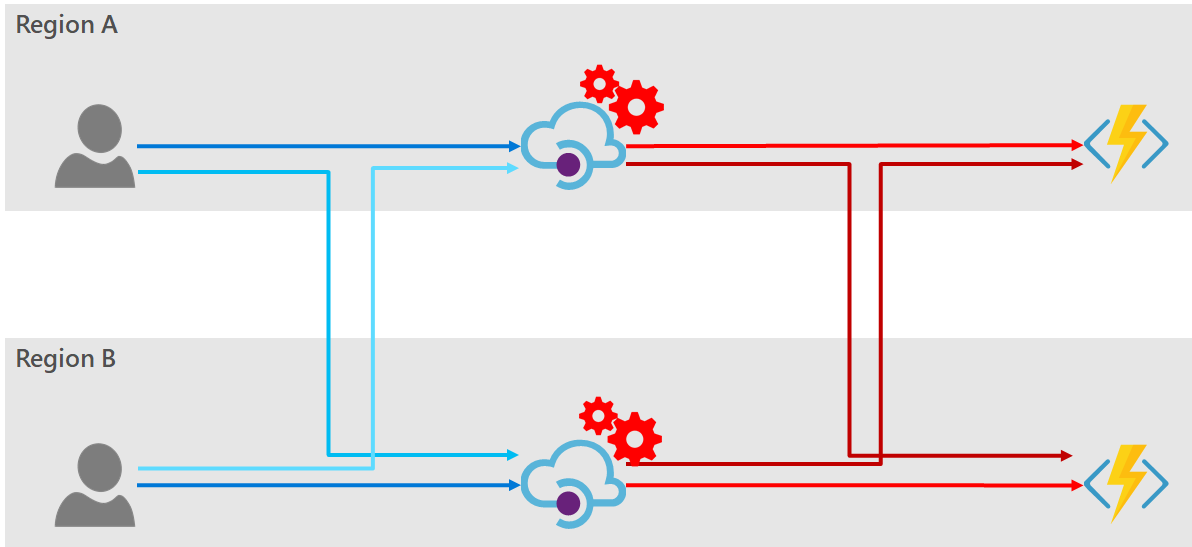
The high-level architecture diagram would look some similar to the following:
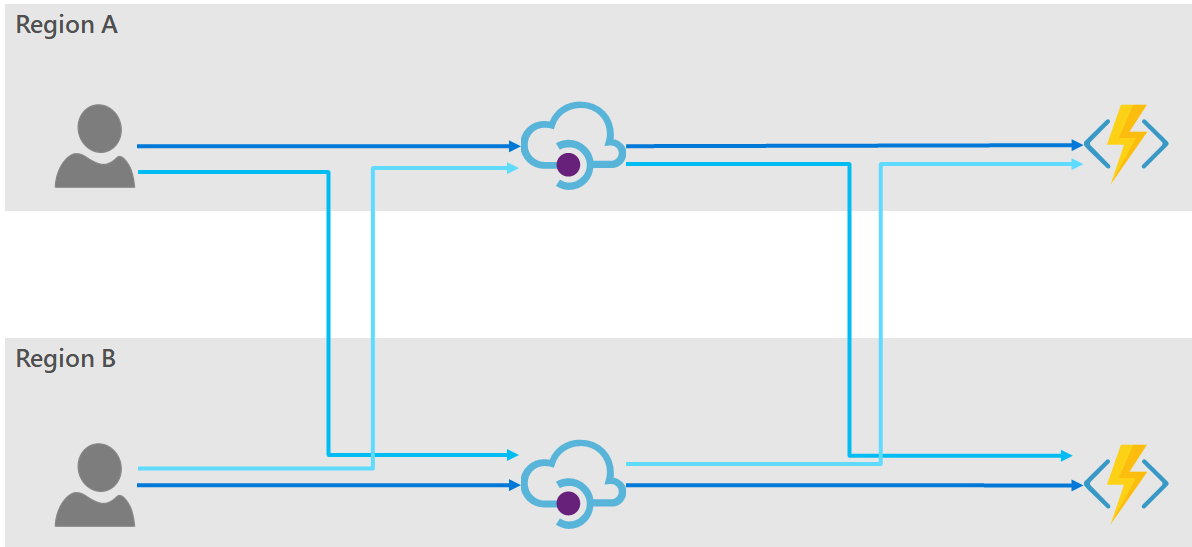
In this diagram the backend services are represented as Azure Functions, but the solutions discussed here are independent of the technology used to service the endpoint. Also, for simplicity of the diagram I have shown the consumers existing in the Azure regions, however for all the options discussed below the consumers may be globally distributed and need not originate from within Azure.
The dark blue lines show the flow of traffic under normal operating conditions; and the light blue shows the possible fail-over traffic routes.
It is now clear from this diagram that there are two places where we must provide redundancy. Firstly, redundancy of the consumer facing API (i.e. from the consumer to the API Manager); and secondly, the backend API (i.e. from the API Manager to the backend service).
Redundancy of Consumer-Facing API
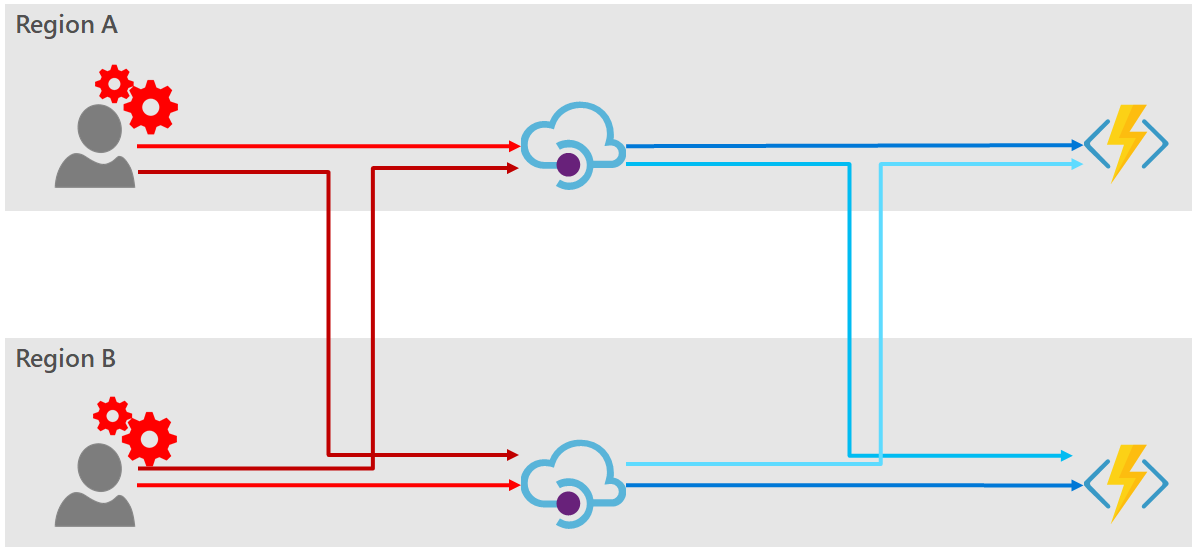
Option 1: Retry logic in the consumer
The first option when considering high-availability of the consumer-facing API is to provide two separate API Manager instances, and leave the responsibility to the consumer to retry each endpoint in the case of a failure. All logic and responsibility for doing this is pushed to the consumer. Vis:
PROs:
- This allows each consumer to access their closest region by default, and to have automatic and instantaneous failover to a redundant region in the case of a failure.
- As there are no additional Azure components there is no additional running cost, and if required lower-tier instances of API Manager (i.e. Basic or Standard) may be used, making this a relatively low-cost implementation.
CONs:
- This design is inflexible in terms of deploying instances to new regions, or worse removing an instance. Each consumer must be aware of the endpoint options which are currently available.
- The consumer is left to implement this retry pattern, causing multiple implementations for the same access logic. This can be mitigated to some extent by providing published SDKs for your services, but these must be provided in all consumer languages (C#, Java, Python, etc).
- The code required to access your service becomes expensive to implement and maintain.
- The API Manager instances must be separately provisioned, maintained and configured. These instances must then be kept in-sync.
- The maximum SLA guaranteed for either API Manager by Microsoft will be 99.9% in this configuration. No additional SLA is given for the “combined” pair.
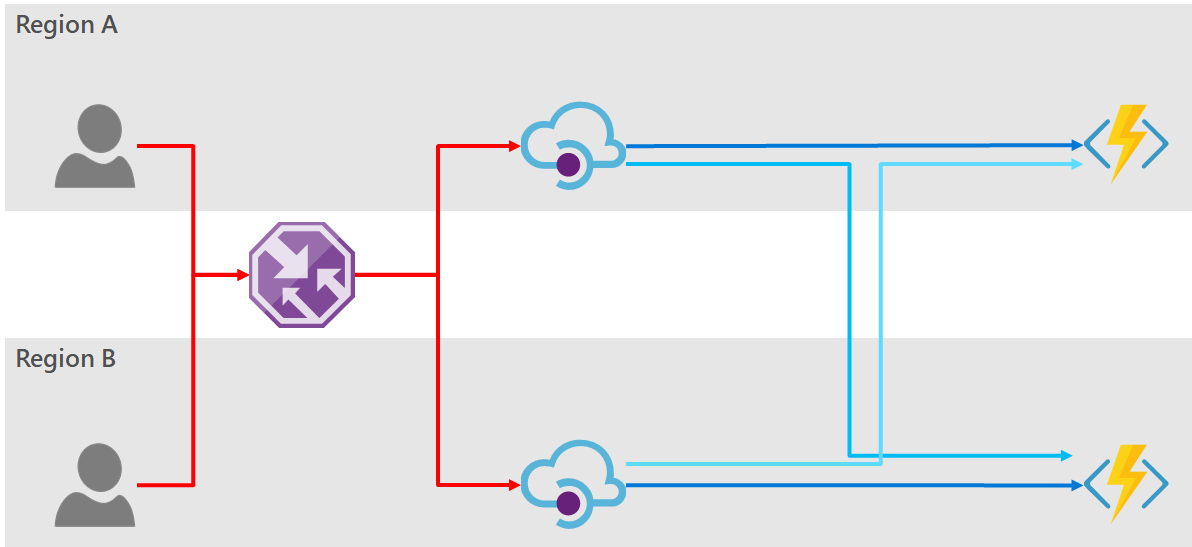
Option 2: Use Traffic Manager In Front of API Manager
The API Manager can be fronted by Azure Traffic Manager to provide load balancing and automatic failover.
PROs:
- The consumer has only one endpoint to access your service and obtain high-availability.
- The two instances of API Manager may be provided on a cheaper low-tier (Basic or Standard) option.
- Failover is automatic when a fault occurs in either API Manager instance.
- Adding and removing API Manager instances is as easy as updating the Traffic Manager.
CONs:
- Azure Traffic Manager cannot probe the endpoints (for health) faster than 10 seconds. One would likely want to allow room for transient errors (as in all cloud deployments) and so only fail on, at least, the second failed probe. This means the fail-over time for switching the DNS entry is 20 seconds.
- Consumers may (and most likely will) cache the results from DNS lookups. If multiple layers of DNS caching take place between the consumer and the Azure Traffic Manager this can cause significant delays between switching the DNS entry and the consumer using the new record.
- The multiple API Manager instance must be kept in-sync for any configuration changes.
- The maximum SLA guaranteed for either API Manager by Microsoft will be 99.9% in this configuration. No additional SLA is given for the “combined” pair.
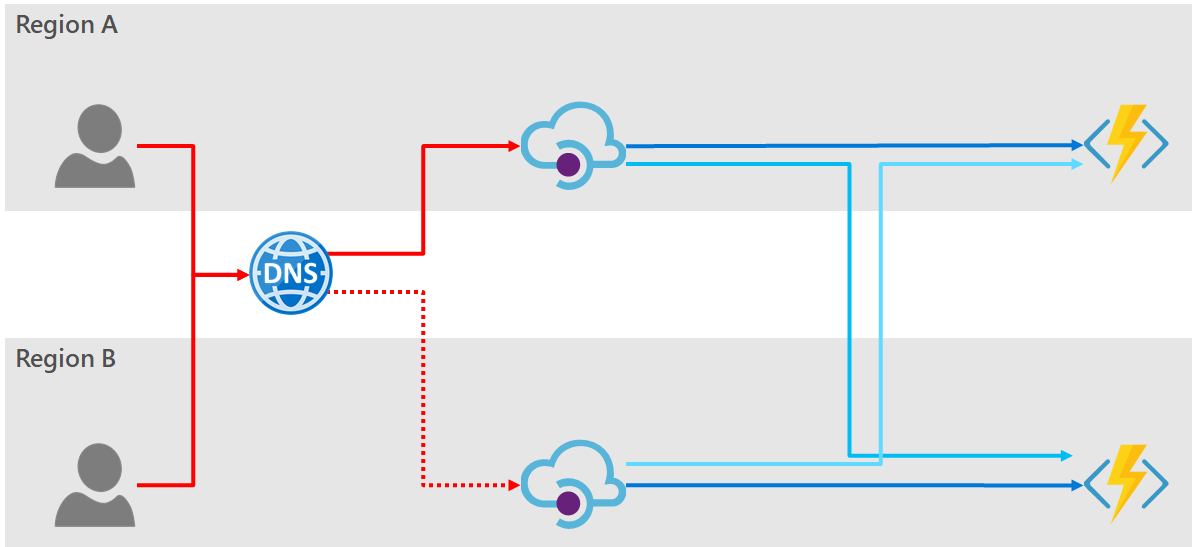
Option 3: Using Azure DNS
Just like Traffic Manager we could front the API Manager with a manually configured DNS entry. This won’t supply automatic failover, nor will it route users automatically to the closest API Manager instance, but it will provide a level of disaster recovery to our system. This is not a high-availability solution but in included here for completeness of the discussion.
PROs:
- DNS is a very cheap solution.
- The consumer has only one endpoint to access your service.
- The two instances of API Manager may be provided on a cheaper low-tier (Basic or Standard) option.
- The active tier can be provisioned at a higher tier, whilst the inactive region is provisioned at a lower tier. The inactive region need only be scaled-up to the higher tier when switching the DNS entry. This reduces the running cost of the solution.
- Adding and removing API Manager instances requires no additional configuration over provisioning the new region.
CONs:
- No automatic health monitoring is available, and automatic fail-over does not occur. Manual intervention is required to initiate the failover. This provides disaster recovery but not high-availability.
- Additional monitoring must be utilised to alert operations when a failover is required.
Notice that, in the event of a planned failover, first switch the DNS entry and monitor the traffic. When all traffic is routing to the secondary region it is safe to bring down the services in the primary.
Option 4: Azure Front Door
Using Azure Front Door purely for providing a high-availability layer in front of API Manager would be like trying to crack a nut with a sledgehammer. However, if you already making use of the Front Door service one can certainly embrace its load balancing functionality.
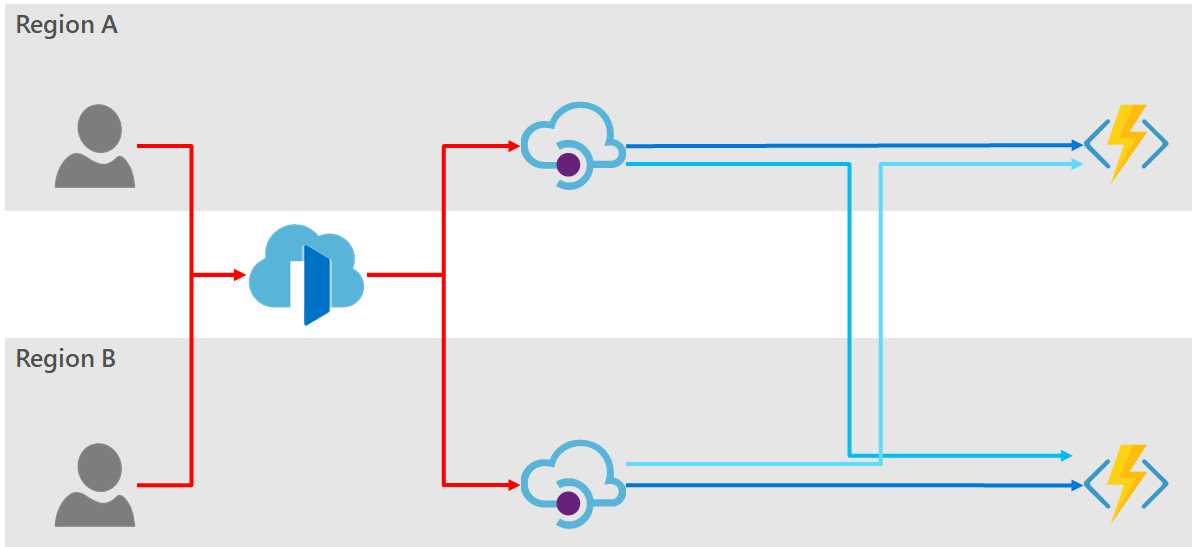
PROs:
- The consumers have only one endpoint to access your service and obtain high-availability.
- Adding and removing gateway instances is as easy as adding to the Front Door backend pool.
- Failover is automatic when a fault occurs in any region.
- Layer 7 switch is used to provide traffic routing, meaning no failover latency due to DNS caching.
CONs:
- The fastest health probe rate for Azure Front Door is 5 seconds. This gives a much quicker failover time than Azure Traffic Manager, but it is not instantaneous.
- The multiple API Manager instance must be kept in-sync for any configuration changes.
- The maximum SLA guaranteed for either API Manager by Microsoft will be 99.9% in this configuration. No additional SLA is given for the “combined” pair.
Option 5: API Manager Redundancy
As mentioned above, the Azure API Manager’s API Gateway can be redundantly deployed, even across global regions. Using this setup our diagram becomes:
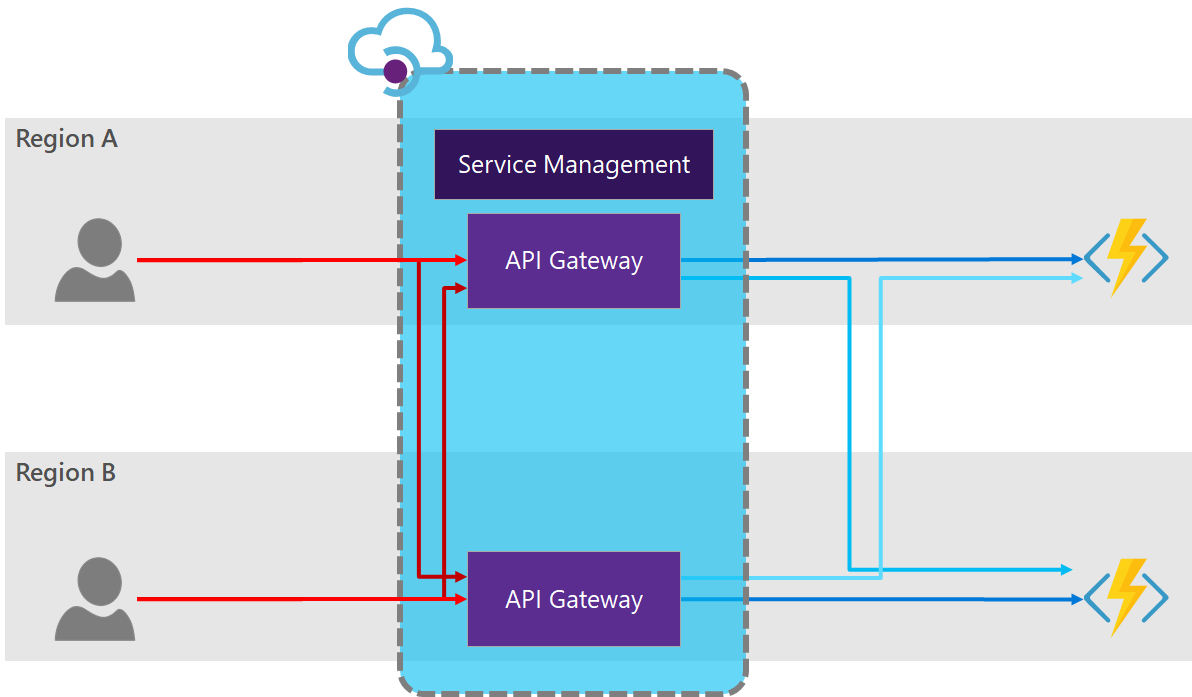
PROs:
- The consumers have only one endpoint to access your service and obtain high-availability.
- Adding and removing gateway instances is as easy as a configuration change.
- Failover is automatic when a fault occurs in any region.
- Configuration changes are automatically rolled-out to all gateways, keeping them in-sync.
- Utilising multiple gateway deployments results in higher throughput.
- The SLA provided by Microsoft for Azure API Manager when utilising multiple multi-region deployments inside a single instance in the Premium tier increases to 99.95%.
CONs:
- API Manager must be deployed at the Premium tier to take advantage of multi-region deployment, which can be prohibitively expensive for some use cases.
- If the primary region fails the API Manager Gateway instances will still operate but no configuration changes can be made until the primary region is restored, since the Service Manager is only hosted in the primary region.
Redundancy of Backend API
That covers the various automatic options available for automatic failover of the consumer facing endpoint. Let’s look now at the backend service endpoint redundancy options.
The redundancy options for the backend API are independent of the option chosen for the consumer facing API. In the examples shown below the diagram has two separate API Manager instances but this could equally be a single API Manager instance with region gateway deployments (i.e. option 5, above).
Option 1: Per-region deployment
We could choose to connect each API Manager instance to its own backend service, with no failover.
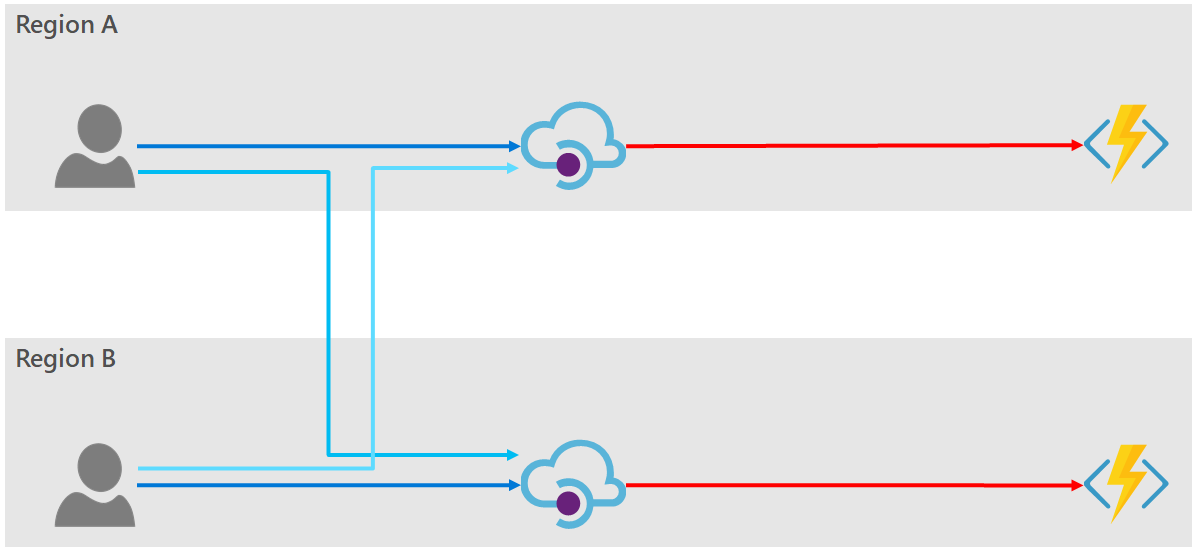
In this deployment we are not providing a totally highly-available solution, but we do protect against regional Azure outages. We can simplify the deployment of each API Manager instance by re-using the same policy in all deployments but using either configuration or custom switching logic to route to the required endpoint.
The following inbound policy fragment shows how the deployment-region (context.Deployment.Region) can be used to route traffic accordingly:

PROs:
- Very easy policy configuration in the API Manager.
CONs:
- Provides only protection against total regional outages, not against a failure nor planned outages of the individual backends
Option 2: Use Traffic Manager behind API Manager
Just as we used traffic manager in front of API Manager to provide resiliency to the consumer, so too we can use it to front of the backend service. Vis:
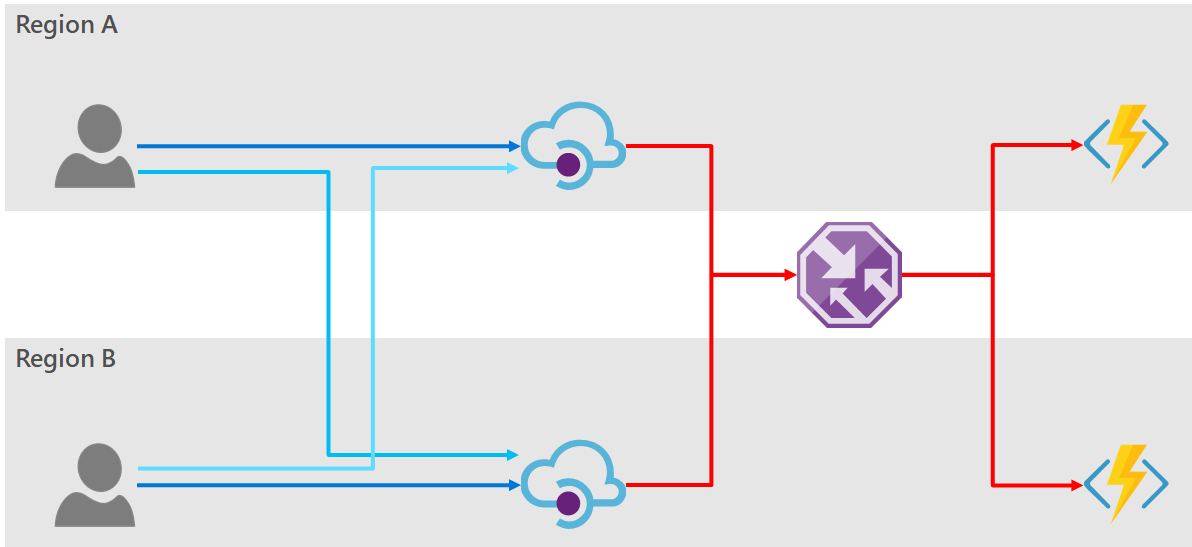
PROs:
- API Manager requires no custom routing logic at all, but only has one endpoint to access the backed service and obtain high-availability.
- Failover is automatic when a fault occurs in either backend service.
- There is no restriction to have as many API Manager deployments as backend services. We could conceivably have (say) two API Manager instances serviced by five backend services.
CONs:
- As before there is a time delay from the moment a failure occurs to when Azure Traffic Manager detects the failure and re-routes the DNS entry.
- No specifics are published on the TTL time for DNS caching within Azure API Manager. There could be an additional delay from when the DNS switch happens in Traffic Manager to when the API Manager honours the new entry.
Option 3: Custom Fail-over Logic in API Manager
As discussed in my previous article we are able to utilise logic in the API Manager’s policies to provide custom retry and failover logic in the event of a failure in the default service endpoint (the detail is omitted here for brevity).
PROs:
- Failover can be instantaneous and even protects against transient errors from the backends.
- No further Azure services are required over those of the API Manager and the backend.
CONs:
- The custom routing logic can be complex to write, and difficult to understand and maintain.
- Adding or removing backend services requires changes to be deployed to the API Manager’s policies.
Discussion of regional endpoints
Before concluding this article I also wanted to point out that, when deploying multiple gateways in a single API Manager instance, each gateway receives its own addressable endpoint URL. These are in addition to API Manager’s “global” gateway URL. The regional URLs are discoverable from the API Manager blade in the Azure portal under the Settings -> Properties.
This may be useful to test the system’s performance and accessibility via various the global endpoints.
Summary
In this article I have attempted to give a complete picture to the redundancy options available within Azure to provide disaster recovery and high-availability to your services presented through API Manager. We showed that redundancy must be considered between the consumer and API Manager, and between API Manager and the backend service. A number of options were discussed for each “hop”.
I would also like to know how you can synchronise multiple Azure API Management resources. I assume this would mean if a user subscribes (creates keys) in Region 1 then those keys would be synchronised over to Region 2?
Very interesting article. Only one question : how do you keep 2 APIM in-sync ?