

TL;DR
Running a Retrieval-Augmented Generation (RAG) system efficiently on Windows, without internet access, and with strict performance constraints requires selecting the right inference engine. After evaluating ONNX Runtime GenAI, LlamaCPP, Hugging Face Optimum, and Triton, we found that ONNX Runtime GenAI outperformed other solutions in token throughput, latency, and wall-clock efficiency for our scenario, making it the best choice for our deployment. In this post, we break down the evaluation process, performance results, and integration details.
Introduction
Running SLM inference on Windows is often challenging due to dependency issues, lack of native support for some frameworks, and performance bottlenecks. Our goal was to build a RAG system with LangChain, ONNX Runtime GenAI, and Guardrails that can be deployed on Windows environment, ensuring:
- All computations happen locally (no cloud dependencies)
- Without internet connection
- Inference is completed under 5 seconds
- Efficient model deployment on a Windows on-prem environment
Given these constraints, we evaluated four inference engines:
- ONNX Runtime GenAI (docs)
- LlamaCPP (GitHub)
- Hugging Face Optimum (GitHub)
- Triton Inference Server (NVIDIA Triton)
Problem Statement
Given the constraints of a Windows-based RAG system, we needed to determine which inference engine would allow us to:
- Run LLM inference with minimal latency (<5s total)
- Ensure maximum GPU utilization
- Optimize token generation throughput
- Remain compatible with LangChain integration
We used Microsoft’s Phi-3 Mini ONNX model (Hugging Face link) for testing, deployed on an Azure ND96amsr_A100_v4 instance (1x A100 80GB GPU).
For benchmarking, we used fixed generation length 256 tokens, with 5 warmup run and 10 repetition.
Decision: Why ONNX Runtime GenAI?
After benchmarking different inference solutions, ONNX Runtime GenAI was selected because:
- Performance: It outperformed all other options in token throughput, latency, and GPU utilization.
- Compatibility: Unlike Optimum, it allows full optimization for Phi-3 ONNX models.
- Windows Support: Unlike LlamaCPP, it doesn’t require extensive custom builds.
- Deployment Flexibility: We cannot use Triton due to on-prem restrictions (no Docker).
Performance Benchmarking
We evaluated the solutions based on:
- Token throughput (Tokens per second)
- Token generation latency
- Wall-clock latency
- Wall-clock throughput
- GPU utilization (Target: ~99%)
For benchmark, we have used script from OnnxruntimeGenai package, here is the link.
Average Token Generation Throughput (tokens per second, tps)
| Batch Size | Prompt Length | Onnxruntime-genai | LlamaCPP | HF Optimum | Speed Up ORT/LlamaCPP Ratio | Speed Up ORT/Optimum Ratio |
|---|---|---|---|---|---|---|
| 1 | 16 | 137.59 | 109.47 | 108.345 | 1.26 | 1.27 |
| 1 | 64 | 136.82 | 110.26 | 107.135 | 1.24 | 1.28 |
| 1 | 256 | 134.45 | 109.42 | 105.755 | 1.23 | 1.36 |
| 1 | 1024 | 127.34 | 105.60 | 102.114 | 1.21 | 1.50 |
| 1 | 2048 | 122.62 | 102.00 | 99.345 | 1.20 | 1.59 |

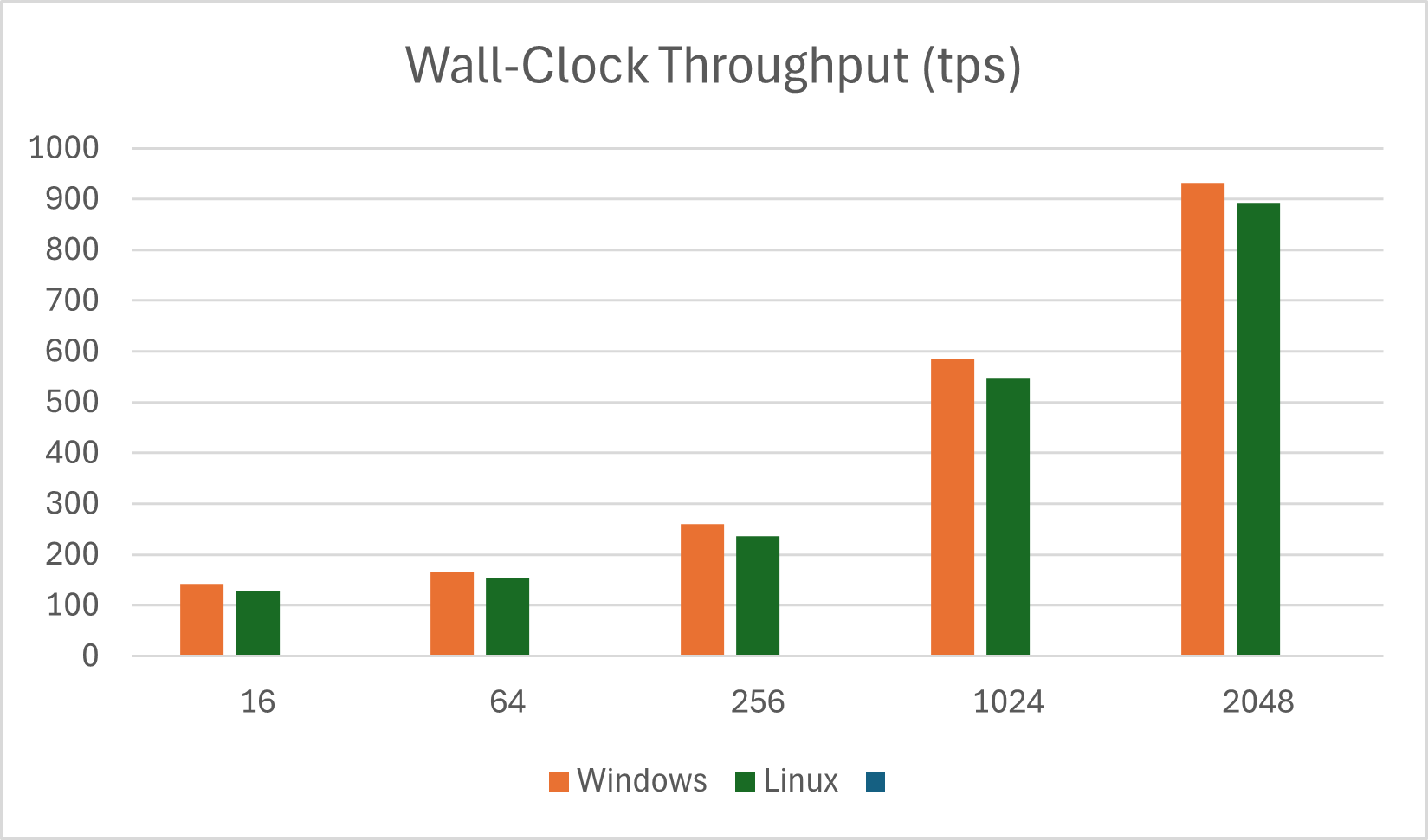
Average Wall-Clock Throughput (tps)
| Prompt Length | Windows | Linux |
|---|---|---|
| 16 | 142.18 | 129.52 |
| 64 | 166.20 | 154.18 |
| 256 | 259.48 | 235.68 |
| 1024 | 585.68 | 545.91 |
| 2048 | 932.03 | 892.12 |
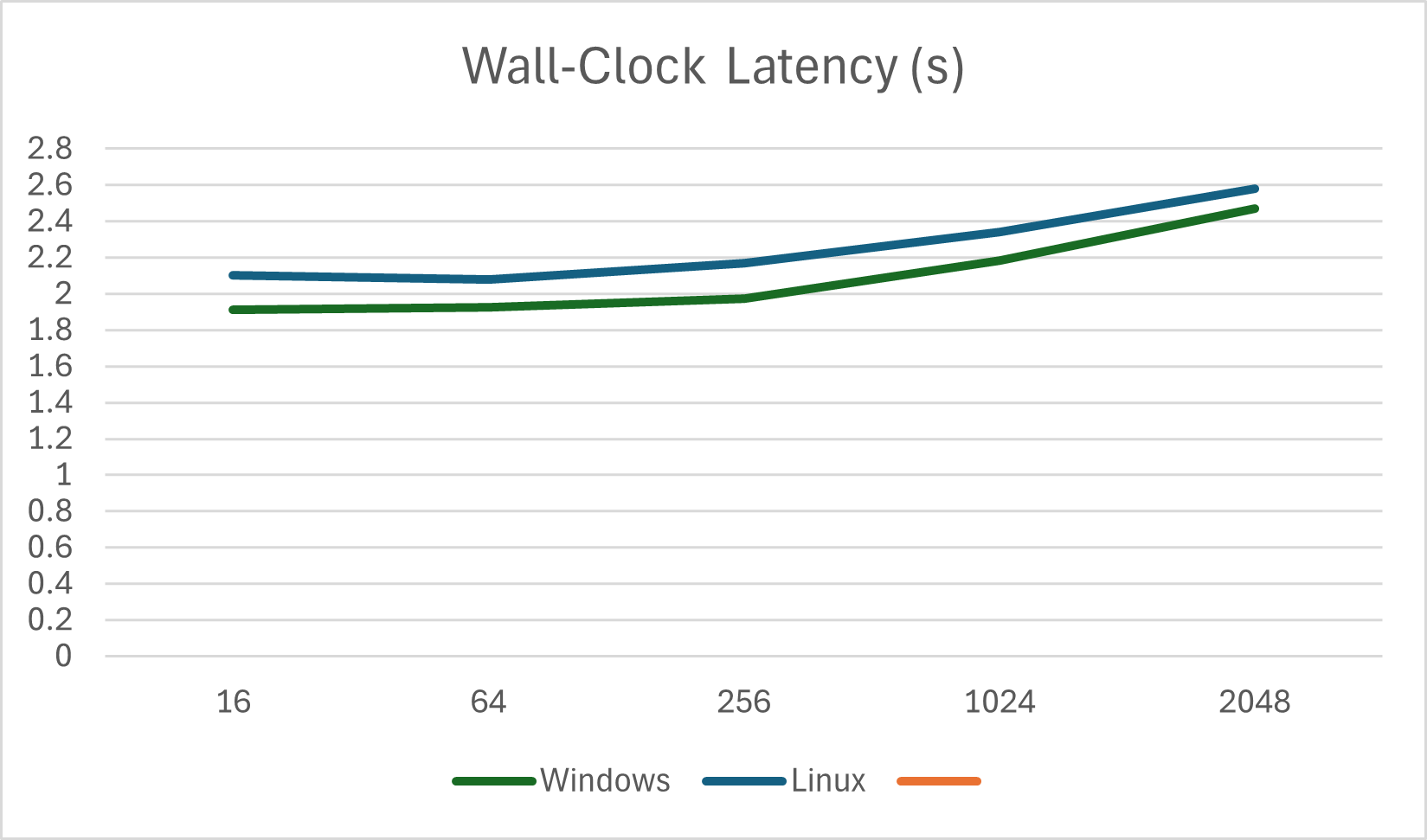
Average Wall-Clock (s)
| Prompt Length | Windows | Linux |
|---|---|---|
| 16 | 1.913120966 | 2.1 |
| 64 | 1.925366235 | 2.08 |
| 256 | 1.97314712 | 2.17 |
| 1024 | 2.185485754 | 2.34 |
| 2048 | 2.472010641 | 2.58 |
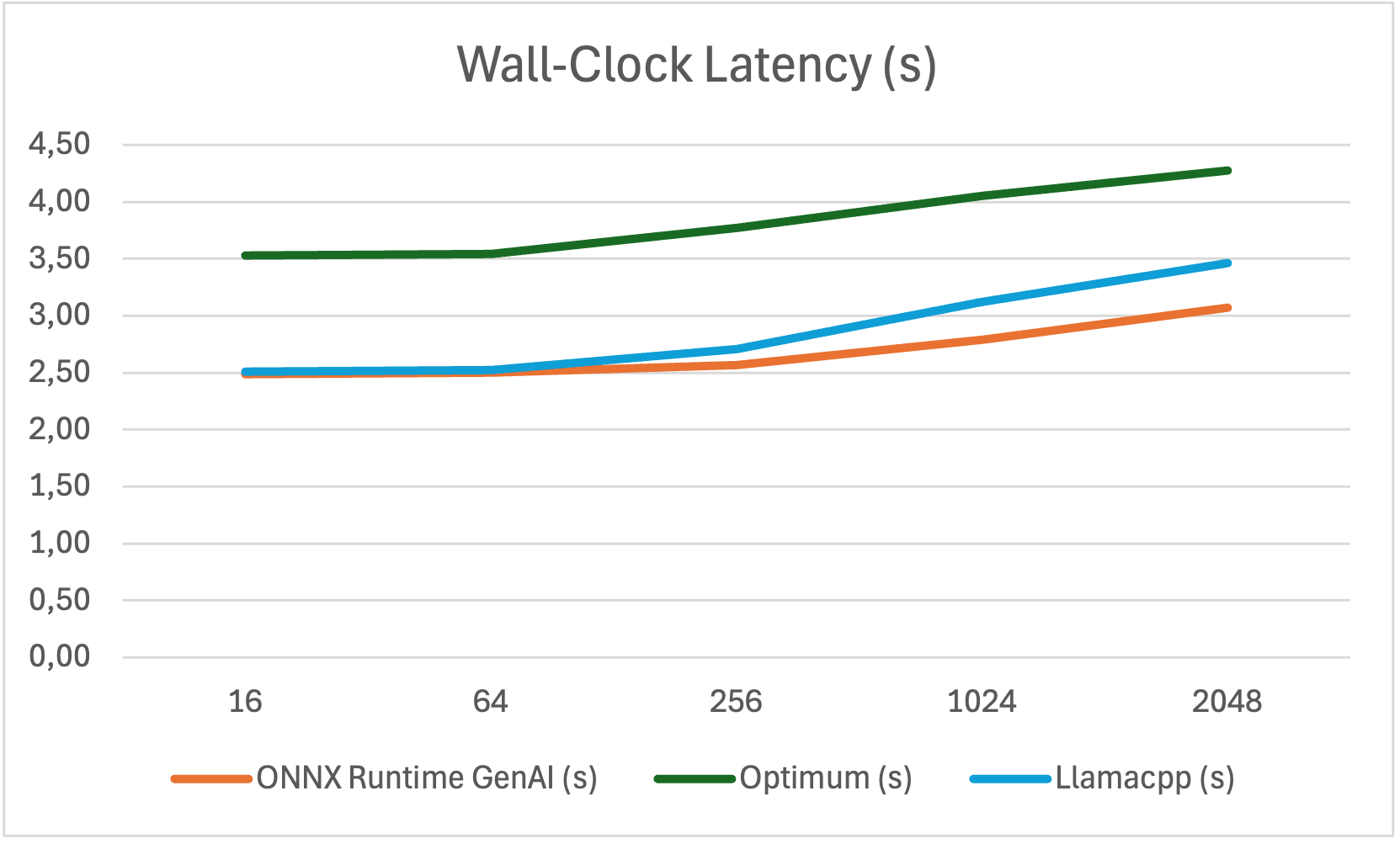
Optimum vs ONNX Runtime GenAI
Optimum’s graph optimization is limited, and it doesn’t support Phi-3. Using ONNX Runtime GenAI’s builder, we could achieve significantly better throughput and lower latency.
Wall-clock Latency Optimum vs ONNX Runtime GenAI
| Prompt Length | ONNX Runtime GenAI (s) | Optimum (s) | Llamacpp (s) |
|---|---|---|---|
| 16 | 2.491 | 3.526 | 2.51 |
| 64 | 2.502 | 3.545 | 2.52 |
| 256 | 2.571 | 3.772 | 2.71 |
| 1024 | 2.790 | 4.049 | 3.12 |
| 2048 | 3.073 | 4.279 | 3.46 |
Integration with LangChain
To integrate ONNX Runtime GenAI with LangChain, we extended BaseLLM and BaseChatModel to support ONNX inference:
def _generate(self, prompts, stop = None, run_manager = None, **kwargs):
from onnxruntime_genai import GeneratorParams,Generator
text_generations: list[str] = []
answer:str=""
# Encode prompts
input_token = self.tokenizer.encode_batch(prompts)
model_params = self._default_params
model_params.update(self.model_kwargs)
# Build generator params
params = GeneratorParams(self.model)
params.set_search_options(**model_params)
generator = Generator(self.model, params)
# Append input token
generator.append_tokens(input_token)
while not generator.is_done():
generator.generate_next_token()
new_token = generator.get_next_tokens()[0]
answer+=self.tokenizer.decode(new_token)
print(self.tokenizer_stream.decode(new_token), end='', flush=True)
text_generations.append(answer)
del generator
return LLMResult(generations=[[Generation(text=text) for text in text_generations]])We also created an ONNX conversion job using onnxruntime-genai.builder, This ensures optimized models for inference.
onnxruntime-genai.builder --model phi-3-mini --output ./phi3_optimized.onnxConclusion
Choosing the right inference engine matters for on-prem RAG systems, especially on Windows. ONNX Runtime GenAI provided:
- Best performance (higher throughput, lower latency)
- Easy integration (LangChain & onnxruntime-genai.builder)
- Optimized models for local inference
If you’re working on Windows-based AI deployments, ONNX Runtime GenAI is the way to go.