

Microsoft recently partnered with AVEVA, an engineering, design and management software provider to the Power, Oil & Gas and Marine industries. AVEVA’s challenge is one that is becoming more and more common in the construction visualization space: ever increasing complexity of 3D data that needs to be highly interactive to a customer base that operates on mobile platforms (smartphones, tablets, and untethered headsets like HoloLens). AVEVA believes that remote rendering and live asset streaming is the way forward for their business.
As a result of our collaboration, we built 3D Streaming Toolkit, an open-source toolkit that provides an approach for developing 3D server applications that stream frames in real-time to other devices over the network. Specifically:
- A server-side C++ plugin and samples for remotely rendering and streaming 3D scenes
- Cross-platform client-side samples for receiving streamed 3D scenes, including HoloLens
- Cloud infrastructure architecture to allow large-scale deployment
- Low latency video compression using NvPipe/NVENCODE
- WebRTC extensions for 3D content and input
Background
The next interaction platform for human computing interaction is mixed reality. Mixed reality is the blanket term to encapsulate Virtual Reality, Augmented Reality, Wearable Computing and other device verticals that enhance or replace our natural senses and capabilities with human-centered technologies.
Unlike the human-computer interactions of the 20th centuries, which have been machine-focused, the future of computing in the 21st century rests decidedly in swinging the pendulum towards humanity-first solutions. The physical button including remotes, keyboards, mice, touchscreens, dials, and switches won’t disappear from our lives. Mixed reality is an additive platform that provides human beings with a broader range of ways to interact with technology, improving efficiency, experiences and expression.
Mixed reality isn’t happening in a vacuum. It is growing up in a mobile computing world. This means smaller, portable, battery powered devices that are wearable and comfortable for users. The total shipment forecast for 2020 will be over 60 million headsets. It is important to note that smartphone solutions like Google Daydream, as well as fit-to-purpose untethered headsets like the HoloLens and others already in the market, will outsell tethered solutions by 2020 with a 54% market share from 17% in 2018.
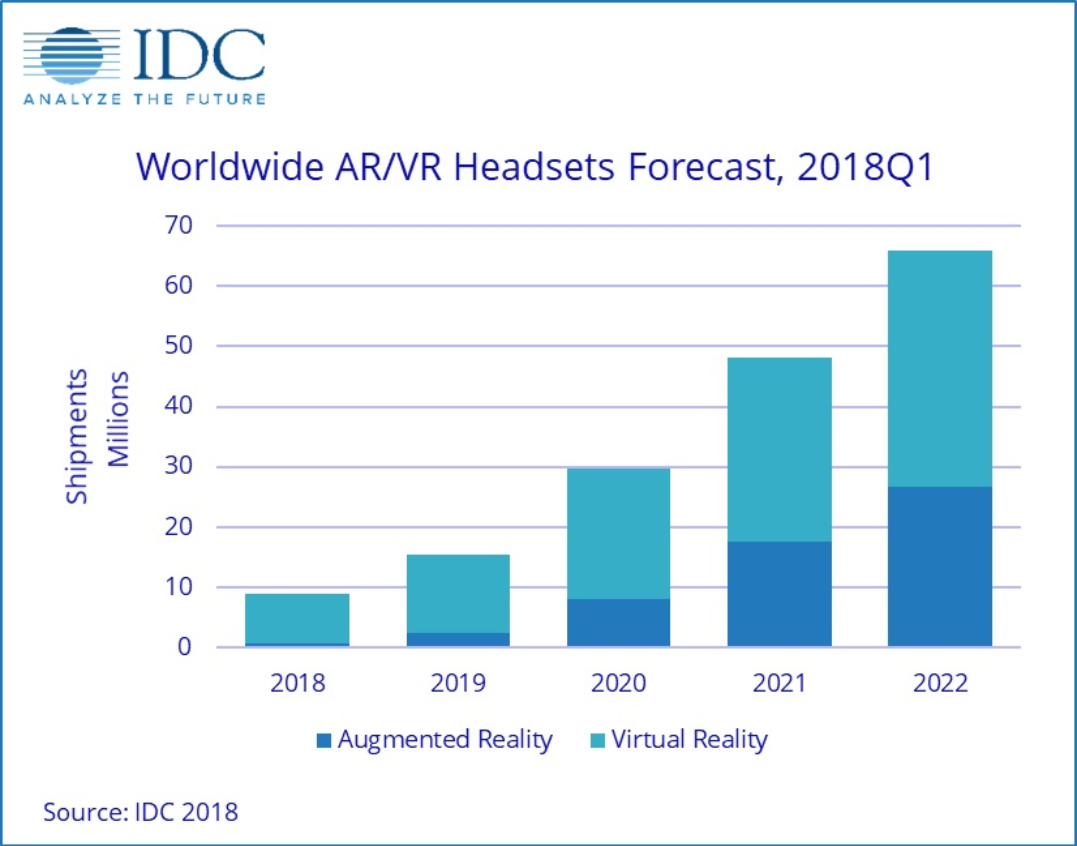
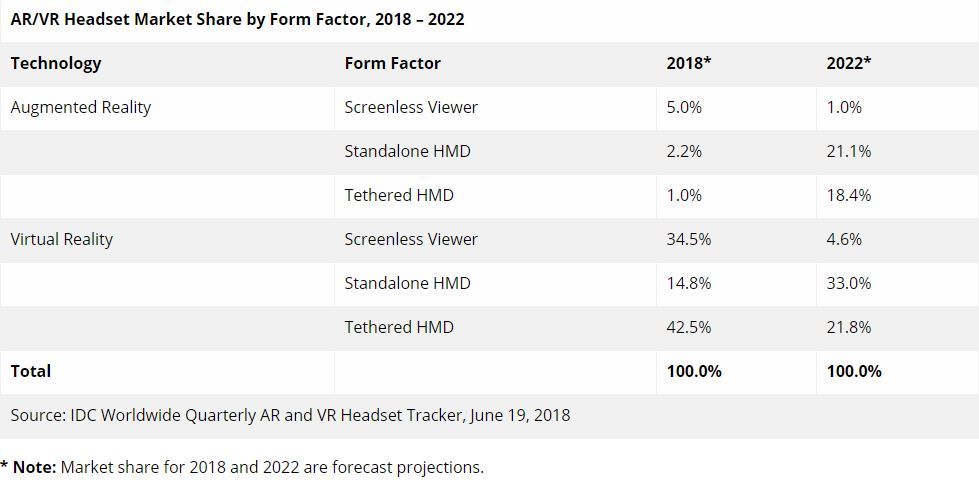
The biggest problem for these standalone HMD (head mounted displays) is the inherent tradeoff between mobility and fidelity. However, the race has already started to bring “desktop”-class experiences to these larger volume devices. Perhaps even more importantly, there is a massive appetite for existing mobile products like smartphones and tablets that are capable of delivering high-end 3D visualization experiences far beyond any on-board GPU capabilities. With billions of these devices already in the wild and mixed reality devices following the same base platform technologies and additive technology strategy, addressing both segments is within reach.

AVEVA built a multi-discipline 3D plant design software called Everything3D (AVEVA E3D™ screenshot shown above) that increases project productivity, improves project quality and drives down project time. This software can render a full-sized plant without any loss of detail and enables engineers to make real-time changes to the plan. Such a detailed rendering requires powerful rendering power and is out of reach for any low-powered device like smartphones, tablets and headsets like HoloLens. AVEVA wanted to find a solution that can use their existing product and capabilities but work on cross-platform devices including a mixed-reality experience on HoloLens, so that engineers can interact with the content in the real-world.
The solution
After analyzing the market and AVEVA’s requirements, we decided the best solution was to develop cloud rendering capabilities for their 3D application. This approach also addressed a number of security, content management and cross-platform issues that were critical to AVEVA’s success. Our initial implementation was specifically created for AVEVA’s rendering application, but we quickly realized that the components behind this solution were re-usable and we decided to open-source a toolkit that will enable cloud rendering for any 3D application. We called it 3D Streaming Toolkit (3DSTK) and we developed it to meet the following goals:
- Low latency rendering of complex scenes
- Latency is the main blocker for any cloud-rendering scenario. Unlike consumer solutions like game streaming, with enterprise solutions we can mandate end-to-end hardware requirements to ensure smooth and predictable performance with commercial wireless access points, managed switches and carefully considered data center routing.
- With the correct configuration, our end-to-end latency from the cloud to clients is around 100ms.
- Multiple peers connected to a single instance of a server
- In a large-scale deployment, it is crucial that multiple peers can connect to a single server. This allows the re-use of the same dataset in multiple viewpoints and substantially lowers the cloud computing costs.
- Consistent delivery across heterogeneous device ecosystems
- The mobile devices on the market have extremely variable compute and GPU capabilities onboard. With cloud rendering, server hardware is managed by the enterprise and the clients are essentially playing a real-time video, a capability that is standard in almost all mobile devices on the market.
- Extremely lightweight on-device footprint
- The datasets that are useful for visualization are continually changing and are prohibitively large. It’s neither feasible nor practical to push multi-gigabyte updates down to devices to maintain shared context across users in an organization.
- With server managed context, rolling out updates can happen instantaneously to the user.
- Inherent protection of potentially sensitive IP and assets
- Often the datasets and models required to enable users to perform basic work functions are extremely sensitive IP. By keeping this off-device, they can both keep the asset current and have no worries about losing their IP due to theft, malware, or malicious agents.
- Ease of remote sharing, recording for training and supervision
- Shared POV context is critical for many traceability and transparency scenarios – law enforcement, liability, etc.
- Fast, intuitive development, scale and rollout
- For the foreseeable future (next 5-7 years) there will be a continued explosion of new hardware players as well as continual platform flux across Windows, iOS and Android. A service-based rollout strategy dramatically reduces exposure to new hardware adoption and capital expenditures for device management.
- Cloud / On-Prem solution
- For installations without low-latency networks (e.g., oil rigs, conventions, and types of transit like planes, trains, and buses) the same technology can run in a Windows Server instance locally. This was a critical need for development and testing, enabling isolation of network issues from other functional issues during development of their products and services.
The open source toolkit has the same components used for AVEVA’s solution. We simply abstracted the components to enable easy integration with other rendering applications. Now that we understand the goals of this toolkit and why it’s important for enterprise customers, let’s dive into the architecture behind 3D Streaming Toolkit.
Architecture
Instead of starting to develop a solution from scratch, the team chose to evaluate existing technologies that could be leveraged to achieve the stated goals. The team chose to make use of the WebRTC (Web Real-Time Communications) protocols and API, as well as the NVENCODE hardware encoding library from NVIDIA to enable zero-latency encoding on the server side.
NVENCODE
Most NVIDIA graphics cards include dedicated hardware for accelerated video encoding, and this capability is engaged through NVIDIA’s NVENCODE library. This library provides complete offloading of video encoding without impacting the renderer’s graphics performance. This was key to the success of our implementation, as any delay in encoding would drastically influence latency and make the experience unusable. These capabilities are also available on Virtual Machines on the cloud, like the NV series VMs from Azure.
For video encode acceleration, we chose to use NvPipe, a simple and lightweight C API library for low-latency video compression. It provides easy-to-use access to NVIDIA’s hardware-accelerated H.264 and HEVC video codecs and is a great choice to drastically lower the bandwidth required for networked interactive server/client application.
WebRTC: (http://webrtc.org/)
The WebRTC project was released by Google in 2011 as an open source project for the development of real-time communications between browser-based applications. The stated goal of WebRTC is “To enable rich, high-quality RTC applications to be developed for the browser, mobile platforms, and IoT devices, and allow them all to communicate via a common set of protocols.” The project has been widely applied to support low latency VOIP audio and video applications.
Below is a diagram outlining the typical functional blocks used by WebRTC solutions. Each client that connects to WebRTC can act as both a client and a server of audio, video, and data streams. The clients make use of a Signaling Server to establish connectivity to one another. Once connected, a STUN service is used to evaluate the connectivity options between clients in order to establish the most performant pathway for the lowest latency communications. This service allows for the possibility of direct peer-to-peer sessions. When direct connectivity between clients is not allowed by VPN, firewall, or proxy, then a TURN service is used as a message relay.
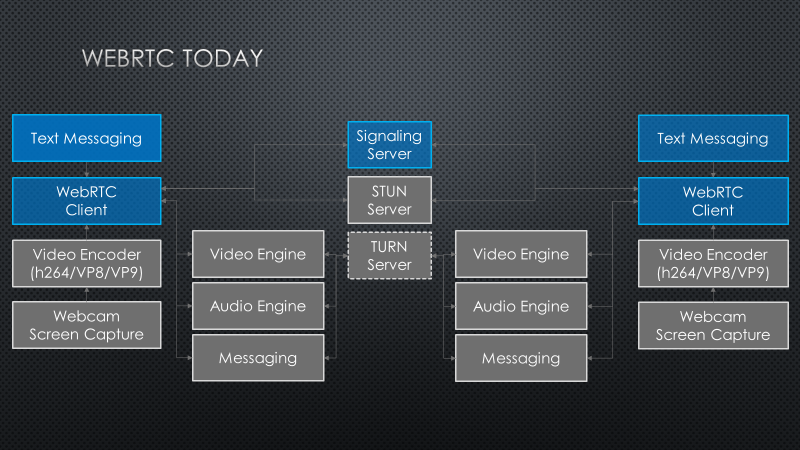
All communication between clients is managed through one or more data channels. The Video Engine is offered as a middleware service to establish a video data channel and to automate buffer, jitter, and latency management. The Audio Engine performs the same duties for audio connectivity and is tailored for efficient processing of voice data. Applications are free to establish multiple data channels for custom / arbitrary formatted messages.
The diagram below summarizes the 3DStreamingToolkit’s extensions to typical WebRTC usage. The set of video encoders is expanded to include NVIDIA NVENCODE hardware encoder library for real time encoding of 3D rendered content. A custom data channel is established to manage camera transforms and user interaction events, and these are applied by plugins that encapsulate rendering by Unity or native OpenGL or DirectX rendering engines.
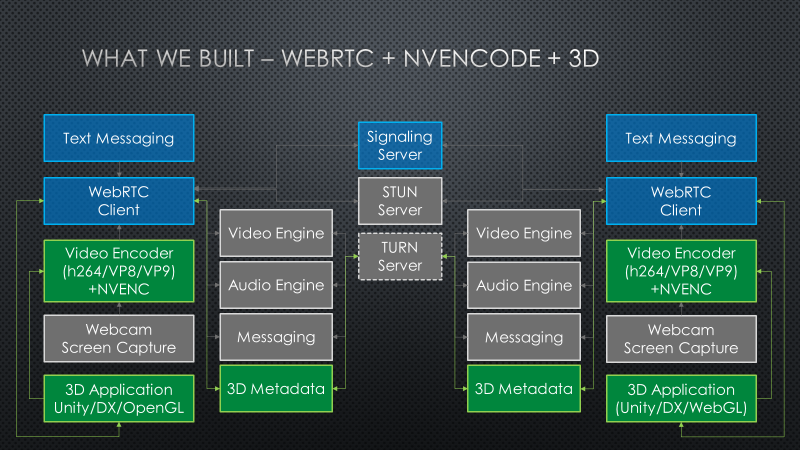
In practice, it is only useful to apply NVENCODE on the rendering server side and the WebRTC diagram can be simplified to the diagram below. Co. Since the TURN Service and rendering service are on the same network, there is no performance penalty for always making use of the TURN relay service and as a result the STUN service can be bypassed.
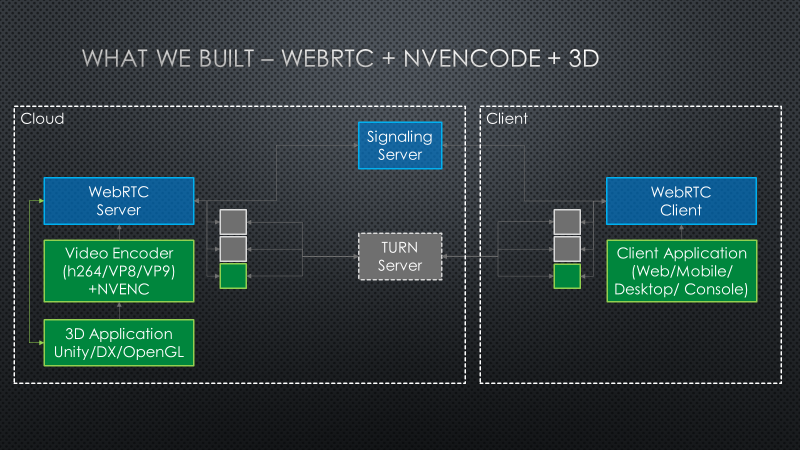
A common desired scenario is to connect multiple peers to a single instance of a server. The architecture above is targeted at a single server to a single peer, but our toolkit is also capable of a large-scale architecture to allow thousands of users to connect to a streaming experience.
Large scale cloud architecture
The team decided to create a reference architecture for a large-scale architecture that makes is easy for any partner to deploy the components to Microsoft Azure, customize the configuration for any scenario, and start streaming a custom 3D experience.
This architecture contains the required WebRTC servers (signaling and TURN) and an orchestrator capable of monitoring and scaling up/down pools of VMs that host the rendering applications. Clients can easily connect to the signaling server and the orchestrator will decide what VM should connect to the user.
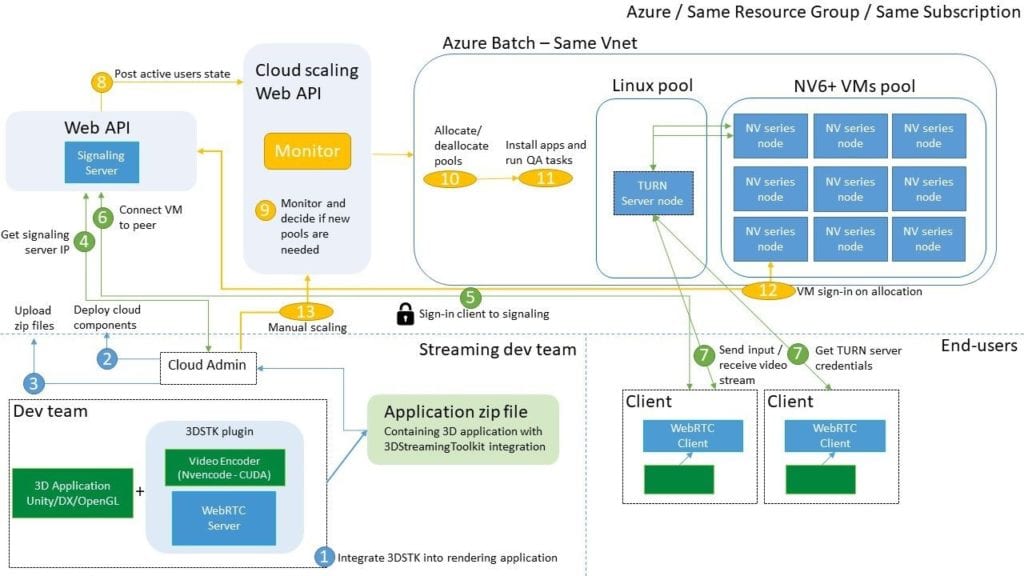
This architecture requires several complex components to enable the best possible experience. These can be found in the 3D Streaming Toolkit organization on GitHub.
For a detailed, step-by-step guide on how to get started, please check our main documentation page and follow the large scale tutorial.
Now, let’s look at some of the 3D Streaming Toolkit components in more detail:
A server-side C++ plugin and samples for remotely rendering and streaming 3D scenes
One key challenge was to develop a server-side C++ plugin that can grab the GPU buffer of any 3D application (DirectX for AVEVA’s solution), encode it with H264 NvPipe, and send it over the network to any connected client using WebRTC. The clients will then use native WebRTC components to receive and decode the H264 frame and display it on the screen as soon as it’s received.
We are keeping the RGB image buffer created by the application in the GPU memory and we are passing the pointer down to WebRTC. Once a frame is ready to be sent, our WebRTC H264 encoder extension will use NvPipe to encode the frame at the GPU level. This frame does not need any color conversion or any CPU copying to output the encoded image. This enables zero-latency encoding and it will not affect any rendering capability.
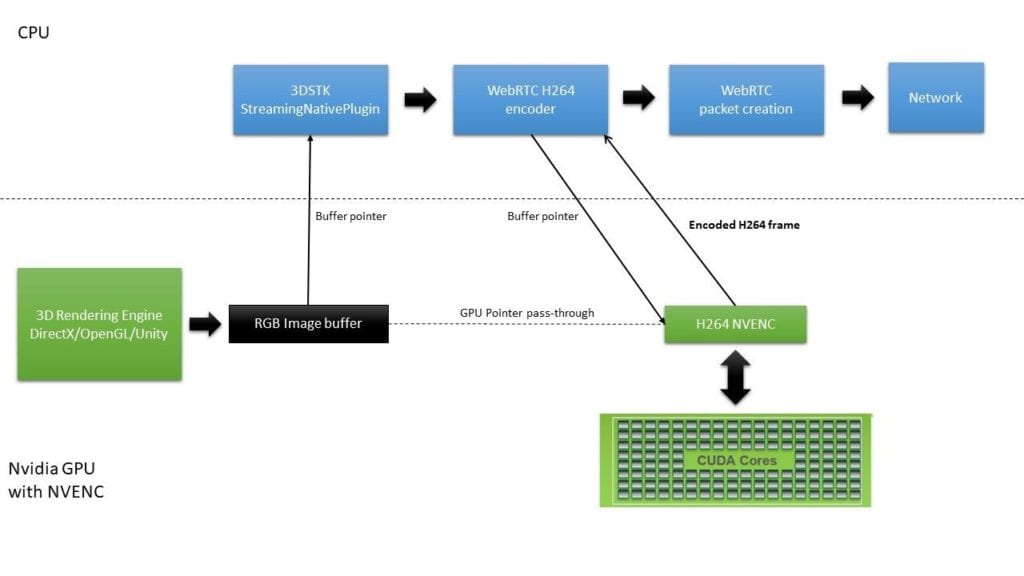
As an example of this flow, our DirectX SpinningCube server sample uses a DeviceResources class to create the correct DirectX 11 device and context:
// Initializes the device resources. g_deviceResources = new DeviceResources();
Inside the class, the device and context are created as follows:
// Creates D3D11 device.
hr = D3D11CreateDevice(
nullptr,
D3D_DRIVER_TYPE_HARDWARE,
nullptr,
createDeviceFlags,
nullptr,
0,
D3D11_SDK_VERSION,
&device,
nullptr,
&context);
hr = device->QueryInterface(__uuidof(ID3D11Device1), reinterpret_cast<void**>(&m_d3dDevice));
if (SUCCEEDED(hr))
{
(void)context->QueryInterface(
__uuidof(ID3D11DeviceContext1),
reinterpret_cast<void**>(&m_d3dContext));
}
We then create a cube renderer class that is responsible for updating the camera and rendering a ‘spinning cube’. Think of this as the main rendering application:
// Initializes the cube renderer. g_cubeRenderer = new CubeRenderer(g_deviceResources);
Now that we have a 3D scene, we need to create a WebRTC Conductor that will pass the buffer to the encoder and send it over the network:
// Initializes the conductor. DirectXMultiPeerConductor cond(fullServerConfig, g_deviceResources->GetD3DDevice());
In this case, we use a DirectXMultiPeerConductor that will allow multiple users to connect to our application. Please note that this conductor is also used for Unity servers. We also have an OpenGLMultiPeerConductor for any OpenGL application.
In our main game loop, we then check all the connected peers, update the camera transformation for each perspective, render the scene, and send the raw frame buffer to the peer conductor. This ensures that each user will have their own experience and can freely navigate the scene based on their input.
For a stereoscopic experience, we update the left/right views corresponding to each eye. Our HoloLens clients have sample code on how to project the frames correctly and display a stereoscopic experience.
for each (auto pair in cond.Peers())
{
auto peer = (DirectXPeerConductor*)pair.second.get();
// Retrieves remote peer data from map, create new if needed.
std::shared_ptr<RemotePeerData> peerData;
auto it = g_remotePeersData.find(peer->Id());
…
if (!peerData->renderTexture)
{
// Forces non-stereo mode initialization.
if (GetTickCount64() - peerData->startTick >= STEREO_FLAG_WAIT_TIME)
{
// Initialize textures
…
peerData->isStereo = false;
peerData->eyeVector = g_cubeRenderer->GetDefaultEyeVector();
peerData->lookAtVector = g_cubeRenderer->GetDefaultLookAtVector();
peerData->upVector = g_cubeRenderer->GetDefaultUpVector();
peerData->tick = GetTickCount64();
}
}
else
{
g_deviceResources->SetStereo(peerData->isStereo);
if (!peerData->isStereo)
{
// FPS limiter.
const int interval = 1000 / nvEncConfig->capture_fps;
ULONGLONG timeElapsed = GetTickCount64() - peerData->tick;
if (timeElapsed >= interval)
{
peerData->tick = GetTickCount64() - timeElapsed + interval;
g_cubeRenderer->SetPosition(float3({ 0.f, 0.f, 0.f }));
g_cubeRenderer->UpdateView(
peerData->eyeVector,
peerData->lookAtVector,
peerData->upVector);
g_cubeRenderer->Render(peerData->renderTargetView.Get());
peer->SendFrame(peerData->renderTexture.Get());
}
}
// In stereo rendering mode, we only update frame whenever
// receiving any input data.
else if (peerData->isNew)
{
g_cubeRenderer->SetPosition(float3({ 0.f, 0.f, FOCUS_POINT }));
DirectX::XMFLOAT4X4 leftMatrix;
XMStoreFloat4x4(
&leftMatrix,
XMLoadFloat4x4(&peerData->projectionMatrixLeft) * XMLoadFloat4x4(&peerData->viewMatrixLeft));
DirectX::XMFLOAT4X4 rightMatrix;
XMStoreFloat4x4(
&rightMatrix,
XMLoadFloat4x4(&peerData->projectionMatrixRight) * XMLoadFloat4x4(&peerData->viewMatrixRight));
g_cubeRenderer->UpdateView(leftMatrix, rightMatrix);
g_cubeRenderer->Render(peerData->renderTargetView.Get());
peer->SendFrame(peerData->renderTexture.Get(), peerData->lastTimestamp);
peerData->isNew = false;
}
}
When SendFrame is called, the frames will be passed into the Conductor and our plugin will handle the encoding and sending the content over the network.
Cross-platform client-side samples
We created a number of client samples (iOS, Android, browser and HoloLens) that can receive the 3D frames and render them on the screen. We added input handlers, so that you can pan/move to explore the scene. Since we used WebRTC, the client-side custom components are minimal and make use of existing native WebRTC components to send input, decode the video, and display it on the screen. You can find the list of our clients here: https://3dstreamingtoolkit.github.io/docs-3dstk/#client-samples and look at our feature matrix: https://3dstreamingtoolkit.github.io/docs-3dstk/feature-matrix.html

The HoloLens client is a special case as it also allows stereoscopic rendering. With the use of frame prediction and custom matrix projections, we enabled a smooth experience that can run at 60fps. Currently, the Unity HoloLens client does not have frame prediction and we recommend the DirectX version for any production quality experiences. For more info, check our HoloLens docs: https://3dstreamingtoolkit.github.io/docs-3dstk/Clients/directx-hololens-client.html
WebRTC extensions for 3D content and input
WebRTC is a key component of our solution but we needed to add a few features to enable 3D streaming. The HoloLens client is originally based on the WebRTC UWP repo maintained by the Windows Developer Platform team at Microsoft. We published all of our changes as part of a unified native and UWP WebRTC repository.
Video frame extensions to allow pointers of RGB and texture data to be passed to the encoder
WebRTC uses I420 as the main video frame buffer across the stack, and W. To achieve this, we extended VideoFrame class and added the following methods:
// Set frame buffer.
void set_frame_buffer(uint8_t* frame_buffer) { frame_buffer_ = frame_buffer; }
// Get frame buffer.
uint8_t* frame_buffer() const { return frame_buffer_; }
NvPipe integration in the H264 encoder
NvPipe provides a simple C interface to enable low-latency encoding, and we integrated this library into the WebRTC H264 encoder plugin. We pre-compile the dll based on our branch and we keep the dll inside the server application. When the encoder is created, we dynamically load the dll and create an NvPipe instance:
hGetProcIDDLL = LoadLibrary(L"Nvpipe.dll");
if (hGetProcIDDLL == NULL) {
// Failed to load Nvpipe dll.
LOG(LS_ERROR) << "Failed to load Nvpipe dll";
ReportError();
return WEBRTC_VIDEO_CODEC_ERROR;
}
create_nvpipe_encoder = (nvpipe_create_encoder)GetProcAddress(hGetProcIDDLL, "nvpipe_create_encoder");
m_pNvPipeEncoder = create_nvpipe_encoder(NVPIPE_H264_NV, m_encodeConfig.bitrate, m_encodeConfig.fps, m_encodeConfig.idrPeriod, m_encodeConfig.intraRefreshPeriod, m_encodeConfig.intraRefreshEnableFlag);
As explained above, we send the RGB buffer pointer down to WebRTC and when a frame is ready to be encoded, we simply pass that buffer to nvpipe and output the encoded buffer:
uint8_t* serverSendBuffer = input_frame.frame_buffer();
size_t frameSizeInBytes = bufferSize;
if (!serverSendBuffer)
{
LOG(LS_ERROR) << "Encode failed: Input buffer is empty. ";
ReportError();
return WEBRTC_VIDEO_CODEC_ERROR;
}
nvp_err_t encodeStatus = encode_nvpipe(m_pNvPipeEncoder, serverSendBuffer, bufferSize, pFrameBuffer, &frameSizeInBytes, m_encodeConfig.width, m_encodeConfig.height, m_encodeConfig.fps, NVPIPE_RGBA);
As a final step, we copy the output buffer into an encoded image so WebRTC can create the packet and send it over the network:
memcpy(encoded_image_._buffer, p_nal, frameSizeInBytes);
encoded_image_._length = frameSizeInBytes;
if (encoded_image_._length > 0) {
// Deliver encoded image.
CodecSpecificInfo codec_specific;
codec_specific.codecType = kVideoCodecH264;
codec_specific.codecSpecific.H264.packetization_mode = H264PacketizationMode::NonInterleaved;
encoded_image_callback_->OnEncodedImage(encoded_image_, &codec_specific,
&frag_header);
}
RTP package header extensions to allow HoloLens frame prediction timestamps
For HoloLens clients, we needed a way to sync frame prediction timestamps between the server and clients. To achieve this, we extended the VideoFrame and EncodedFrame classes to also hold prediction timestamps:
// Set prediction timestamp in 100-nanosecond intervals.
void set_prediction_timestamp(int64_t prediction_timestamp) { prediction_timestamp_ = prediction_timestamp; }
// Get prediction timestamp in 100-nanosecond intervals.
int64_t prediction_timestamp() const { return prediction_timestamp_; }
We also modified the packetizer header to make sure this info is sent as part of the video frame across the network:
struct RTPVideoHeader {
uint16_t width; // size
uint16_t height;
VideoRotation rotation;
int64_t prediction_timestamp;
// Sets the prediction timestamp.
last_packet->SetExtension<VideoFrameMetadata>(video_header->prediction_timestamp);
When a packet is received on the client side, we set the prediction and expose that as part of the decoded frame:
prediction_timestamp_ = last_packet->video_header.prediction_timestamp;
int32_t H264DecoderImpl::Decode(const EncodedImage& input_image,
bool /*missing_frames*/,
const RTPFragmentationHeader* /*fragmentation*/,
const CodecSpecificInfo* codec_specific_info,
int64_t /*render_time_ms*/)
…
// Obtain the |video_frame| containing the decoded image.
VideoFrame* video_frame = static_cast<VideoFrame*>(
av_buffer_get_opaque(av_frame_->buf[0]));
RTC_DCHECK(video_frame);
video_frame->set_timestamp(input_image._timeStamp);
video_frame->set_prediction_timestamp(input_image.prediction_timestamp_);
This time stamp is then used by the decoder on the HoloLens device to present the frame at the right time. For more information on how this works, please read our documentation: https://3dstreamingtoolkit.github.io/docs-3dstk/Clients/directx-hololens-client.html
There are many more components that are part of 3D Streaming Toolkit. We also have documentation and examples on how to set up authentication, OAuth 2.0 for mixed reality applications, orchestrating TURN servers, and tutorials to get started.
Conclusion and Reuse
Through our collaboration with AVEVA, we developed an open-source toolkit that enables the creation of powerful stereoscopic experiences that run on the cloud and stream to low-powered devices. This approach resolves many business issues for consistent delivery across heterogeneous device ecosystems, on-device footprint, protection of potentially sensitive IP and fast, intuitive development, scale and rollout. These were crucial to AVEVA and many other partners that have started using our open-source solution.
The solution can be adapted to any cloud-rendering scenario and we have seen many industries – including medical, manufacturing and automotive – adopting this approach . It is our hope that the work presented here will lead to further collaborations in the future on additional projects using the 3D Streaming Toolkit.