

Introduction
Context
Our team recently partnered with an ISV who is editing a software that is operated and used by many of their customers from dedicated on-premises deployments. Our goal was to help them to build a Microsoft Teams application that would enable their customers to access their software from Microsoft Teams, in order to provide a better user experience and to leverage the Microsoft Teams platform to build new scenarios, such as native mobile application support, notifications, etc.
This Microsoft Teams application was targeted to be multi-tenants, so that the ISV could deploy it once and then enable it for all their customers through the Microsoft Teams store. We also wanted the application to connect to the on-premises deployments of the software, in a reliable and secure way.
When building a Microsoft Teams application, one constraint is that all the resources that are used by the application must be accessible from the Internet. This is because the Microsoft Teams backend services are hosted in the cloud, and the Microsoft Teams client is connecting to it over the Internet. In our case, the software was deployed on-premises, and was not accessible directly from the Internet. We needed to find a way to make it accessible from the Internet, without requiring any complex configuration on the customer side, to keep the multi-tenants / self-service from the store a simple process.
In this article, we will describe how we solved this problem, and how we built a multi-tenants Microsoft Teams application and backend that is able to connect to a legacy software running on-premises, in a secure and reliable way.
Fabrikam NimbusBridge use case
Let’s consider Fabrikam, an ISV that provides the “NimbusBridge” software, a CRM solution that runs on-premises for years in their customers’ data center. For this use case, we consider two of them: Contoso and Northwind. Fabrikam Product Officer wants to modernize NimbusBridge software and make some functionalities available through a new Microsoft Teams application.
Architecture considerations
Requirements and constraints
- Microsoft Teams applications require access to a public API to be available to retrieve / store data in an external system / software.
- Product Officer wants the Microsoft Teams application to be available in the Microsoft store and to be multi-tenants, so any of their customers can download it, parameterize it and use it directly.
- Discussing with customers’ operational team, it has been emphasized that exposing the legacy software over the Internet to allow Microsoft Teams app to reach to it directly is not an option, because of security concerns. Also, having VPN or network peering setup between an application backend and each customer network will be difficult conversation and can lead to 3 months conversations and processes to be able to use the Microsoft Teams application. Having all customers to VPN to the same multi-tenant’s backend can become a showstopper for some of them.
- The recommendation from the security IT and architecture team is to find an option where outgoing connectivity over 443 only is required.
Overview of the solution
Fabrikam has developed an agent that runs inside the corporate network, part of the NimbusBridge legacy software deployment, and that is responsible for initiating an outgoing connection to the NimbusBridge Teams backend and listening for commands sent to the broker, handling commands, and sending the responses back to the cloud.
All of this can happen without any inbound connectivity and, eventually, rely on the https 443 outbound connection, from on-premises, to make it easier to flow through corporate firewall.
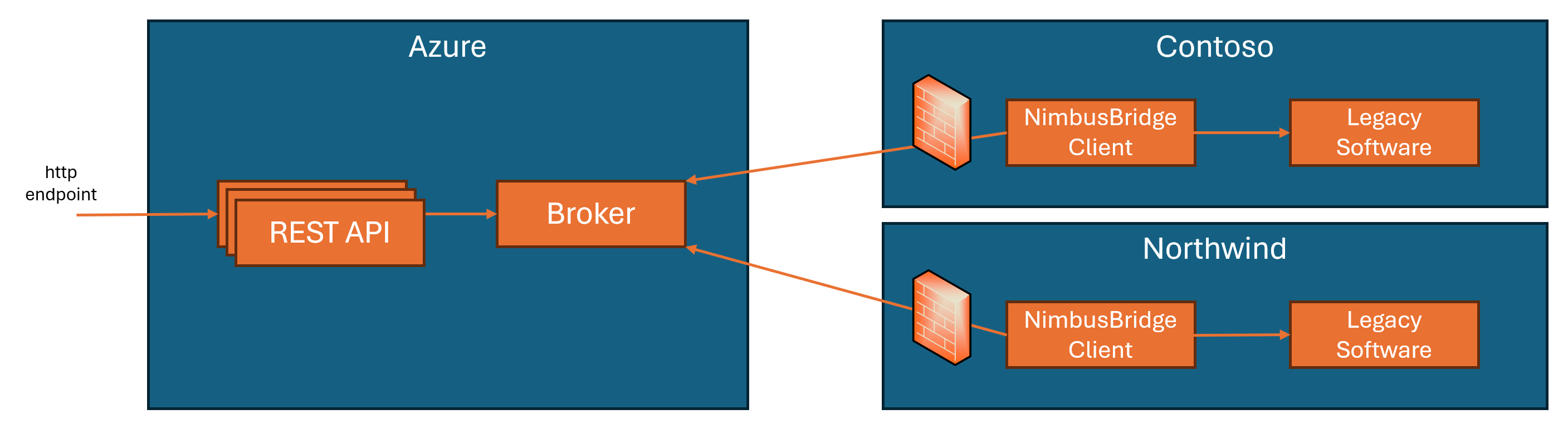
Such kind of architecture involving a broker adds a layer of asynchronism in the way the requests are sent and handled by the system, but it is still possible to choose how you want it to be implemented.
Brokers and protocols options
This section goes into some considerations about the use and choice of a broker to implement the NimbusBridge architecture.
But let’s start with the most important question: why use a broker in such scenario?
There are several advantages to using a broker when interacting with legacy software running on-premises.
First, it allows you to simplify and secure access to the legacy software, by running a component on-premises that is connected to the broker using an outbound connection and avoiding complex conversations such as VPN or network peering, especially in the context of a multi-tenants / multi-customers application.
Second, legacy software might or might not have been designed to scale out as modern cloud native applications do. Having a broker in front of it enables us to buffer the incoming requests from the cloud and handle them at the required pace.
Finally, such messages based architecture will enforce the fact that you will expose over the broker only what you want to expose from the legacy software and not an entire API / SDK, because you must write the command message and command handler code. It’s not like opening a port through a network and giving access to the entire system. It gives you full flexibility and control about how you want (must?) interact with the legacy software.
Azure offers different options for asynchronous messaging / broker. You can read more about the different choices on this page.
In the case below, we have decided to use Azure Event Hubs as a broker, essentially because of its capacity to scale / partition the data and create some stickiness between the NimbusBridge client and the NimbusBridge API server that handles the request, as well as the fact it proposes AMQP over WebSockets (e.g. https 443 outbound).
But other options might be interesting to explore, like Azure Service Bus or Azure Event Grid. Especially, Azure Event Grid offers support for MQTT 5 protocol that supports request/response pattern by design.
Architecture overview
The architecture diagram below describes the different components and services that can be used to implement the current use case.
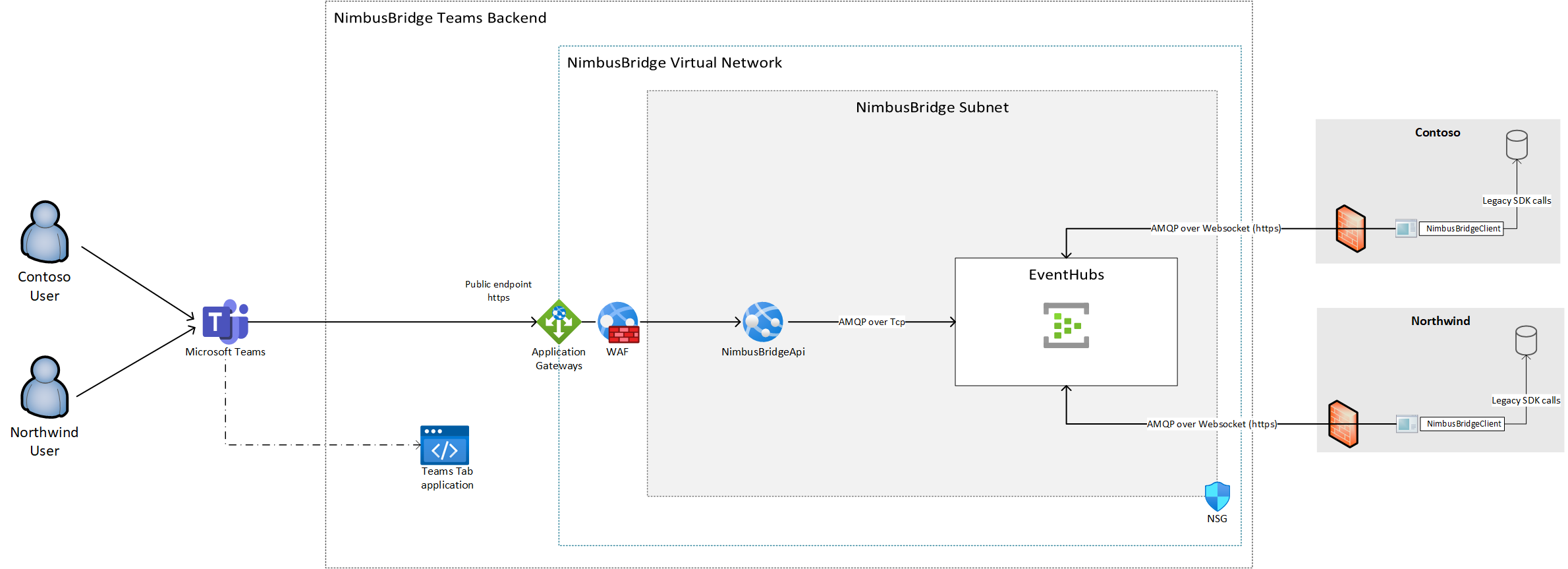
The Microsoft Teams application that is developed by NimbusBridge consists into a Tab Application hosted in Azure Static Web Apps.
The Microsoft Teams application can contact the NimbusBridge API that is hosted on Azure App Service and protected by Azure Application Gateway that offers a Layer-7 load balancer and Web Application Firewall (WAF).
Azure EventHubs is used as a message broker in this case, essentially because it can scale with many events but also allows to partition the data in a way that simplifies the request-lifetime stickiness between a given instance of NimbusBridge API (a server in the web farm) and the NimbusBridge client. See How does the system behave and scale? for more details.
Both NimbusBridge API and NimbusBridge client use the .NET Standard Event Hubs SDK to read from and write to the event hub. For this use case we are using the AMQP protocol, the main reason being that Event Hubs supports AMQP over WebSockets (e.g. over https) that we use to connect from the NimbusBridge client in order to simplify the setup at customers’ place. This way, they only require only outgoing https over 443 connections to Azure Event Hubs specific endpoint into their firewall, nothing more.
How does the system behave and scale?
This example of implementation relies on the Azure Event Hubs partitioning mechanisms for request-lifetime server stickiness and scaling. Indeed, as the overall goal here is to put the http request on-hold on the NimbusBridge API the time to send the message to Event Hubs, handle it in the NimbusBridgeClient on-premises, it is required that the response message will be sent on a partition that is listened by the API instance that has the request on hold, so it can complete it and send the response back to the original client.
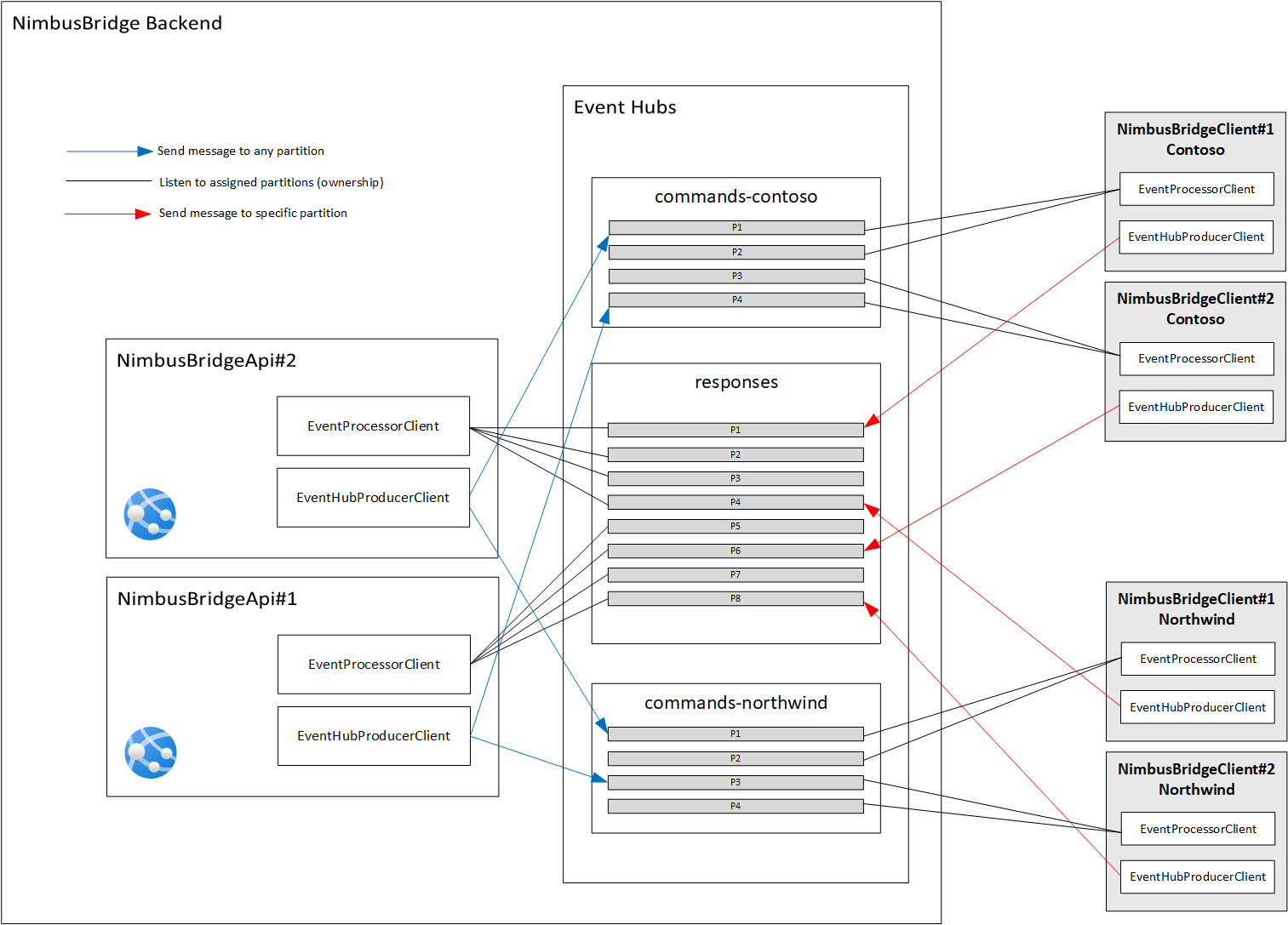
In the picture above, there is an Event Hubs namespace that contains three hubs:
- commands-contoso: this is the hub that will receive commands for the Contoso tenant from NimbusBridge API. Only the NimbusBridge client deployed into the Contoso network can read messages into this hub.
- commands-northwind: this is the hub that will receive commands for the Northwind tenant from NimbusBridge API. Only the NimbusBridge client deployed into the Northwind network can read messages into this hub.
- responses: this hub is shared by all tenants, and their NimbusBridge client can only write messages into it. It is read by NimbusBridge API to get responses from the on-premises clients. As all clients from different tenants will only write information in this hub, it’s ok to share it between the tenants. By sharing it, it helps to reduce the number of hubs that are listened to (active connections) by the servers of the web farm. Eventually, end-to-end encryption can be applied between the API client and the NimbusBridge client to guarantee the security of the data that transits into the system.
The Event Hubs .NET Standard SDK provides two important classes for our scenario:
- EventProcessorClient: this class allows you to subscribe to an Event Hub and listen to the messages.
- EventHubProducerClient: this class allows you to connect to an Event Hub and write messages.
If you are not familiar with Azure Event Hubs SDK, you can find useful samples on this page.
The EventProcessorClient has built-in support for Event Hubs partitioning which will make our scenario easier to develop. Indeed, it will automatically take care of the number of partitions that are in the hub it subscribes to and to other potential instances who subscribes to the same hub using the same consumer group. This way, it will ensure that if there are, for example, two instances of the NimbusBridge API in the web farm, both will listen to different partitions in the responses’ hub. And if one of instances fails for any reason, rebalancing will automatically happen to make sure the remaining instance can now receive messages on all partitions, until the next instance restarts properly and take ownership on some partitions again.
According to the diagram above, let us consider that there are two instances of the NimbusBridge API. Instance number 1 is listening to responses hub partitions P5,P6,P7,P8 whereas instance number 2 is listening to responses hub partitions P1,P2,P3,P4.
In this context, if the Microsoft Teams application sends a request that is served by instance number 2, then it’s mandatory that the NimbusBridge client that handles the message sends the response into one of the partitions that is owned by instance number 2. Otherwise, the http request will never be completed and will time out.
A few important principles:
- EventProcessorClient will listen to multiple partitions in background threads and claim ownership of these partitions. Ownership is rebalanced if we add more EventProcessorClient instances (e.g. more NimbusBridge API or NimbusBridgeClient instances).
- Event Hubs checkpointing ensures that messages will be delivered at least once in the same consumer group. All NimbusBridge API instances must share the same consumer group on the “responses” hub. All NimbusBridge client instances must share the same consumer group on their “commands” hub.
- It does not make any sense to have more EventProcessorClient instances than the number of partitions. If one Event Hub has been created with 4 partitions, then it’s possible to have 4 EventProcessorClient instances with 1 thread, 2 instances with 2 threads etc. Threading is managed by the EventProcessorClient class implementation. Adding more partitions (max is 32 per EventHub) does not mean better performance. This is a fine tuning process to find the right balance between number of partitions and instances of consumers. Such kind of architecture requires to run load testing campaign to refine the numbers according to the expected load of the system (e.g. number of active users / requests).
- In the case of rebalancing while some requests are pending response from the NimbusBridge client, we accept that we could lose track of it (e.g. the response is sent to a partition that is not listened anymore by the same web server) and that the client must reissue (retry) the requests.
How it looks like in code?
One interesting challenge during this project was to make the sync http work with a broker in the middle of the system. We will not detail all the code here, but a working sample written in C# is available on this GitHub repository. To solve this challenge, we used the Task Parallel Library (TPL) and the async / await pattern, to put a request on hold while waiting for the response from the NimbusBridge client, through the broker.
As illustrated in the sequence diagram above, once an http request arrives to a web server that hosts the NimbusBridge API, the following steps are executed:
- The request is handled by the controller, and the command is sent to the event hub that is dedicated to the tenant.
- The controller puts the request on hold using a TaskCompletionSource, and waits for the response from the NimbusBridge client.
- The NimbusBridge client receives the command from the event hub and executes it.
- The NimbusBridge client sends the response to the event hub that is dedicated to the responses, on a specific partition that is listened by the web server that has the request on hold.
- The response is extracted and the TaskCompletionSource is completed with the response, so that the controller can send the response back to the client.
The controller uses a singleton service (EventHubsServerBrokerService) that listens to the responses EventHubs hub and is able to send message to the dedicated EventHubProducerClient instances, one for each tenant. This service is also responsible for storing the TaskCompletionSource instances that are used to put the http requests on hold, and to complete them when the response comes back from the NimbusBridge client, in a concurrent dictionary. It also keeps a list of the partitions that are owned by the web server, so that it can send the response to one of these partitions.
private readonly EventProcessorClient _responsesEventProcessorClient;
private readonly EventHubProducerClient _commandsEventHubProducerClient;
private readonly ConcurrentDictionary<string, TaskCompletionSource<BrokerResponseBase>> _callbacks;
private readonly HashSet<string> _partitions = new HashSet<string>();The EventProcessorClient provides events that are super useful to keep the list of monitored partitions up to date for the given instance:
_responsesEventProcessorClient.PartitionInitializingAsync += args =>
{
if(!_partitions.Contains(args.PartitionId))
{
_partitions.Add(args.PartitionId);
}
return Task.CompletedTask;
};
_responsesEventProcessorClient.PartitionClosingAsync += args =>
{
if(_partitions.Contains(args.PartitionId))
{
_partitions.Remove(args.PartitionId);
}
return Task.CompletedTask;
};The code below shows how the service “awaits” on the task completion source to put the http request on hold while it sends the command to the EventHubs hub.
public async Task<TResponse> SendCommandAsync<TResponse>(EventHubsBrokerCommand command, CancellationToken cancellationToken) where TResponse : BrokerResponseBase
{
// create a task completion source that will be used to put the http request on hold until the response is received
var tcs = new TaskCompletionSource<BrokerResponseBase>(cancellationToken);
if(!_callbacks.TryAdd(command.CorrelationId, tcs))
{
throw new InvalidOperationException("A callback for the given correlation id already exists.");
}
// indicate the partitions that can be used to send the response to this command
// this is done to ensure that the response will be sent to a partition that is owned by this process / web server
// so the http request can be unblocked and the response can be sent back to the client
command.Partitions.AddRange(_partitions);
// serialize the command to json
var jsonCommand = JsonSerializer.Serialize(command);
// retrieve the producer for the tenant
if(!_producers.TryGetValue(command.TenantId, out var tenantEventHubProducerClient))
{
throw new InvalidOperationException($"No producer found for tenant {command.TenantId}.");
}
// create the event to send to the event hub
var dataBatch = await tenantEventHubProducerClient.CreateBatchAsync(cancellationToken);
dataBatch.TryAdd(new EventData(Encoding.UTF8.GetBytes(jsonCommand)));
// send the event to the event hub
await tenantEventHubProducerClient.SendAsync(dataBatch, cancellationToken);
// this is where the http request is put on hold until the response is received
// the task completion source will be completed in the OnProcessEventAsync method,
// once a response with the same correlation id is received
var brokeredResponse = await tcs.Task as TResponse;
if(brokeredResponse == null)
{
throw new InvalidCastException($"Unexpected response type has been received. Expected: {typeof(TResponse).Name}. Received: {tcs.Task.Result.GetType().Name}.");
}
return brokeredResponse;
}As you can see above, the command that is sent to the EventHubs contains a CorrelationId property. This one is used to identify the request that is on hold, and to complete it when the response will come back from a NimbusBridge client. The TaskCompletionSource is stored in a concurrent dictionary, using this correlation id as key so that it can be retrieved and completed when the response comes back.
private async Task OnProcessEventAsync(ProcessEventArgs args)
{
try
{
if(args.Data == null)
{
return;
}
// deserialize the response
// in the case of the sample, we only support the GetCustomersResponse but it might be extended to more strongly typed responses
var jsonResponse = Encoding.UTF8.GetString(args.Data.Body.ToArray());
var brokeredResponse = JsonSerializer.Deserialize<GetCustomersResponse>(jsonResponse);
if (brokeredResponse == null)
{
return;
}
if (!string.IsNullOrEmpty(brokeredResponse.CorrelationId))
{
// retrieve the task completion source that was created when the command was sent
if (_callbacks.TryGetValue(brokeredResponse.CorrelationId, out TaskCompletionSource<BrokerResponseBase>? tcs))
{
// this is where we complete the task completion source that put the http request on hold in the SendCommandAsync method
// by getting the tcs using the correlation id and setting the result, the http request is unblocked and the response is sent back to the client
tcs.SetResult(brokeredResponse);
// remove the callback from the dictionary
_callbacks.Remove(brokeredResponse.CorrelationId, out _);
}
else
{
Console.WriteLine($"No callback found for correlation id {brokeredResponse.CorrelationId} and tenant {brokeredResponse.TenantId}.");
}
}
}
finally
{
// update the checkpoint so the event processor client knows where to start processing the next time it starts
await args.UpdateCheckpointAsync();
}
}Conclusion
In this article, we described how we built a Microsoft Teams application that is able to connect to a legacy software running on-premises, in a secure and reliable way. We also described how we implemented a sync http pattern with a broker in the middle of the system, using the Task Parallel Library (TPL) and the async / await pattern. As mentioned, this was one possible option to solve that challenges and depending on the constraints you have, you might want to explore other options, such as the real-time over http pattern with Azure SignalR service or even rely on another broker than Azure Event Hubs, such as Azure Service Bus or Event Grid.
Thanks a lot to my colleagues Adina Stoll, Michael Collier and Benjamin Guinebertière for their help and feedback on this article.
Note: the picture that illustrates this article has been generated by AI on Bing Image Creator.