
Partner Scenario
The United Nations Office for the Coordination of Humanitarian Affairs OCHA is responsible for planning aid responses to humanitarian crises across the world. The idea for Project Fortis, an early detection system for such crises, came about as part of a collaboration between OCHA and Microsoft.
One of OCHA’s main challenges is the manual nature of monitoring interactions across social media and local news. Their mission was to get accurate information about critical situations where OCHA would need to place humanitarian support in localized areas. It can be a long and tedious process to identify where exactly a trending topic in online media is taking place. On a daily basis, our partner needed to monitor 400+ social media and public data sources manually. Our mission was to automate and streamline this process, reducing response time and, hopefully, saving lives.
We built a real-time processing pipeline to monitor factors that contribute to humanitarian crises through conversations and posts from publicly and privately available data sources, including social media. In addition, we implemented a system that allows users to define a set of relevant keywords, geographical areas of interest and social media feeds. We then use these parameters to extract related posts and plot them on the map, based on an NLP location feature extraction approach.
In this code story, we are going to cover the first step, which is to geocode the social media posts, including:
- How we identify where trending topics are occurring
- How we use the Compromise library to determine which localities that posts mention
- How to use Azure Functions to implement this functionality
The Problem
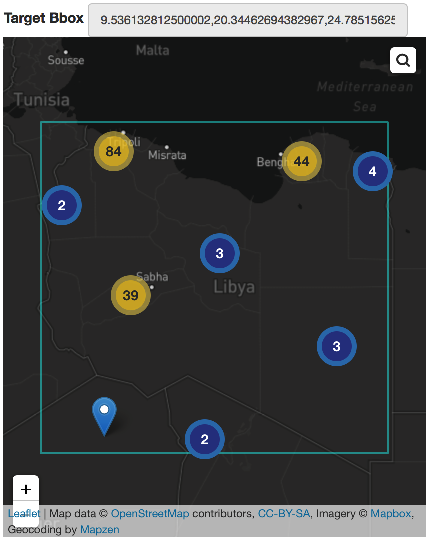
One of the primary objectives of the application is to geolocate posts filtered by topic. For example, we wanted to see a count of posts about events happening in Libya grouped by cities or villages on the map:
The process of extracting locations from a social media post involves two challenges:
- How do we define the list of localities in a region of concern?
- How do we determine if a post contains a reference to a region?
We wanted to allow the user to select an area on the map and have the service return a list of the localities in that region. We also wanted place names translated into all supported languages under the hood. Later on, these locality names will serve as searchable tokens to associate posts with a particular region.
Developing a Solution
One of the primary challenges we faced during this project was determining where trending conversations are taking place, based on the freeform text of social media posts. When a user explicitly allows a social media service to share their location, only then are their posts associated with a place. About 1% of social media posts already have a location listed; in such cases, we accept and use the location as is. However, for the other 99% of posts, we need to infer their locations based on content.
Listing Localities with Mapzen
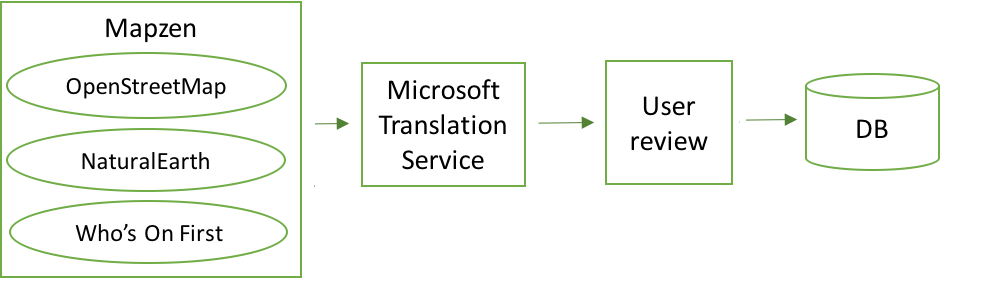
When setting up a dashboard for a new area, there is a little bit of user-assisted admin work required to define the area of interest and its localities. To help the user define the list of localities, we’ve used the Mapzen vector tile service. It provides worldwide basemap coverage sourced from OpenStreetMap, NaturalEarth and Who’s On First. Mapzen is updated daily and is a free and shared service. It accepts bounding box coordinates and a zoom level to return a list of localities with coordinates and metadata.
The returned list of localities is in English, but obviously, many social media posts will use other languages, so we need to list of localities translated into the appropriate languages. So, the next step is to use the Microsoft Translation Service to convert the list of localities into the languages that we are searching for in the social media feeds.
Machine translation services are fantastic but not always 100% accurate. In addition, our search may include localities that are not of interest to the end user. For this reason, we give the admin an opportunity to correct translations and edit the complete localities list before saving the dashboard.
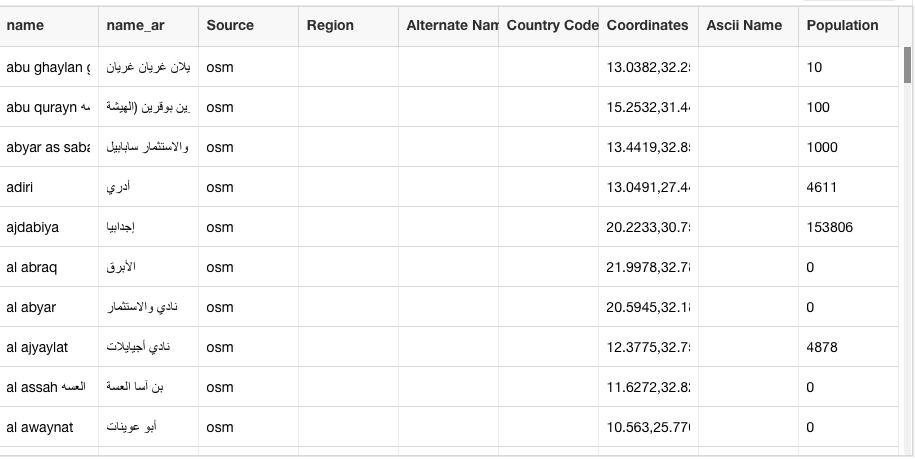
After translation and user review, we save the list and the translations of the place names for further use.
This setup procedure is a one-time process for the admin.
Identifying Localities with Compromise
The next step is to use areas’ names to determine the locations of social media posts. There are a number of issues with this approach. As mentioned before, if the post has an explicit location, such as GPS coordinates attached to it based on user permission, we can use that directly. On the other hand, if the post mentions a place but it is not geocoded directly, we still need to infer the location. Additionally, there are many ways social media users could format such a mention: in upper, lower or mixed case; punctuated with hyphens; as one word, or multiple words; and in numerous other formats. All these possibilities could cause issues with tokenizing a post. The good news is that there are libraries out there that can help us tokenize and find required text quickly.
The library we chose was an open-source JavaScript library called Compromise. This library helps with named entity recognition. It is lightweight and has its own built-in lexicon of different types of objects, such as major locations. It also supports being fed a supplementary list of objects to add to its lexicon for the tokenization.
let nlp = require('compromise');
var lexicon = {};
localities.forEach(locality => {
lexicon[location.toLowerCase()] = 'Place';
});
let mentionedLocations = nlp(sentence.toLowerCase(), lexicon).places().data();
Compromise has a feature for finding big cities without specifying a lexicon:
sentence = "A suicide attack hit the centre of New York killing one person (and the attacker) and injuring more than twenty."
mentionedLocations = nlp(sentence).places().data();
//[{ text: 'New York', normal: 'new york' }]
In our scenario, we need to detect all types of locations, from major cities like New York to small Libyan villages. As a result, we need to include all possible localities in a lexicon object, which gives us the ability to extract locations from any language:
var lexicon = { 'سوق آل عجاج': 'Place', 'سيدي يونس': 'Place' };
var sentence = "سوق آل عجاج بنغازي رأس آل حمامة سيدي يونس كما السلمانيرأس آل حمامة الغربي";
let mentionedLocations = nlp(sentence, lexicon).places().data()
//[{ text: 'سوق آل عجاج', normal: 'سوق آل عجاج' },{ text: 'سيدي يونس', normal: 'سيدي يونس' }]
Looking up a bag-of-words, like a list of localities, involves all sorts of tricky problems, which the Compromise library solves. For instance, the library detects localities with hyphenation (e.g. “Jardas-al-Abid”) even when the lexicon only contains “Jardas al Abid”:
lexicon = { 'Jardas al Abid': 'Place', 'Umm ar Rizam': 'Place', 'Tobruk': 'Place' };
sentence = "A suicide attack hit the centre of Jardas-al-Abid killing one person (and the attacker) and injuring more than twenty."
mentionedLocations = nlp(sentence, lexicon).places().data();
//[{ text: 'Jardas-al-Abid', normal: 'jardas al abid' }]
The library also recognizes place names in the possessive case (i.e. “Jardas al Abid’s center”):
sentence = "A suicide attack hit Jardas al Abid's center killing one person (and the attacker) and injuring more than twenty."
mentionedLocations = nlp(sentence, lexicon).places().data()
//[{ text: 'Jardas al Abid\'s', normal: 'jardas al abid' }]
In addition, the library recognizes place names that are followed by a punctuation mark:
sentence = "A suicide attack hit Jardas al Abid, which killed one person (and the attacker) and injured more than twenty."
mentionedLocations = nlp(sentence, lexicon).places().data()
//[{ text: 'Jardas al Abid,', normal: 'jardas al abid' }]
The way that Compromise handles corner cases allows us to solve named-entity recognition tasks with just a single line of code.
Implementing Location Inference with Azure Functions
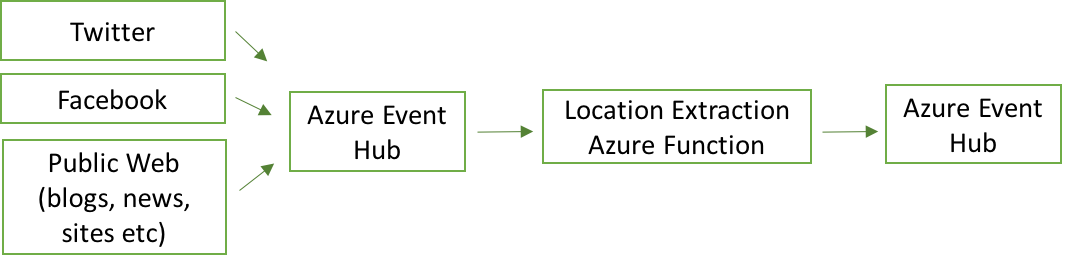
To run this solution in production, we chose Azure Functions as our hosting mechanism for the locality inference job. Azure Functions’ serverless model means we don’t have to worry about underlying infrastructure which makes this approach ideal for event-driven computing. Azure Functions can be fed from an Azure Event Hub which we were using as a normalized queue of social media posts from Twitter, Facebook, websites, and many other sources. As the function processes each post individually, if a location is found, it stores it in a second Azure Event Hub for further processing.
module.exports = function (context, input) {
try {
let sentence = input.message.message;
// process some other input parameters
if(!sentence){
let errMsg = `undefined message error occured [${input}]`;
context.log(errMsg);
context.done();
}
LocationInferenceService.findLocation(sentence, //other parameters
(locations, lang, error) => {
if(locations && locations.features.length > 0 && !error){
deliverMessageToEventHub(locations);// and other parameters
}else{
let errMsg = `No location found for message.`;
context.log(errMsg);
context.done();
return;
}
});
} catch (err) {
context.log(err);
context.done(err);
}
}
Conclusions
Access to free services such as Mapzen that are based on a variety of data providers helped us better determine location names in any region of the world.
Advancements in ML technologies and the availability of open-source libraries have significantly sped up and simplified the development of complex language processing tasks. One such library, Compromise, proved to be an elegant solution to our project’s need to optimize tokenization and search. Combined with Azure Functions, the library allowed us to support processing a huge volume of social media posts. This approach allowed us to fulfill our project goals with Fortis for UN OCHA’s mission in Libya and beyond.
We accept Pull Requests of all shapes and sizes and encourage developers to check out the Fortis GitHub repository and issue list and contribute to this incredibly important effort.