

This blog post describes a solution to protect your application against unexpected changes in the schema of third-party data which your application is consuming.
Table of Contents
The Problem
Imagine you’re developing an application with multiple components:
- A data collector which collects data from various external systems and applies some sort of logic to filter, merge or transform the data
- A Cosmos DB to which said data is saved
- An API which can read the data from the Cosmos DB
- A UI to display the data
Note that the word external is used here to describe systems that are outside of the scope of your application and are developed and maintained by someone else, even if that someone else is still within your company.
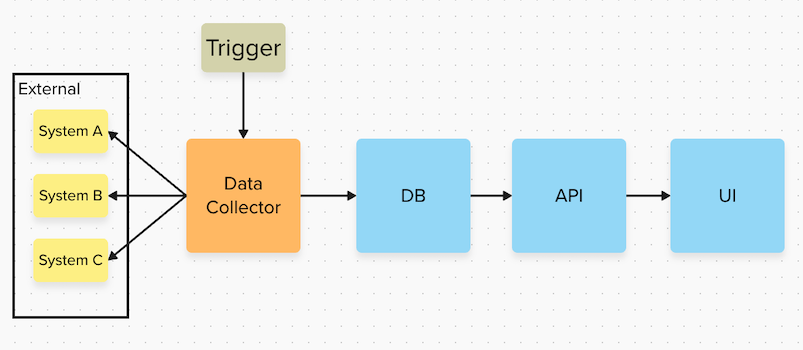
In a perfect world, these external systems have APIs which follow a versioning protocol so you have ample warning and backwards compatibility if something changes. However, the reality can be different especially if you are working in a large company with different teams publishing APIs for company internal use only (or not using APIs at all). In this environment, you have little to no control over the data schema of this external system’s data and you might be surprised by unexpected changes. In the above architecture, even a miniscule change such as changing the name of an attribute in the data coming from external system A can result in a broken UI and logs full of exceptions. Depending on your implementation, even changes in attributes that you’re not even using can cause this. If forcing the external systems to adhere to proper versioning is not an option (which is unfortunately often the case), how do you make your application more robust?
The Solution
To protect your application from unexpected data schema changes you can use data mapping. This means transforming the incoming data to your desired format before your applications starts using it. For data mapping you need a mapping specification which describes the desired data schema and where in the source data to take the values from. This way you decide what attributes are called, how they are nested, etc. You apply the mapping specification to your source data and the result will be the data in your desired format. All other parts of the application can now rely on this schema, and are shielded from any changes in the external systems.
It’s advisable to do this as early as possible to protect all parts of your application. In our example architecture, we’re implementing the data mapping in the collector.
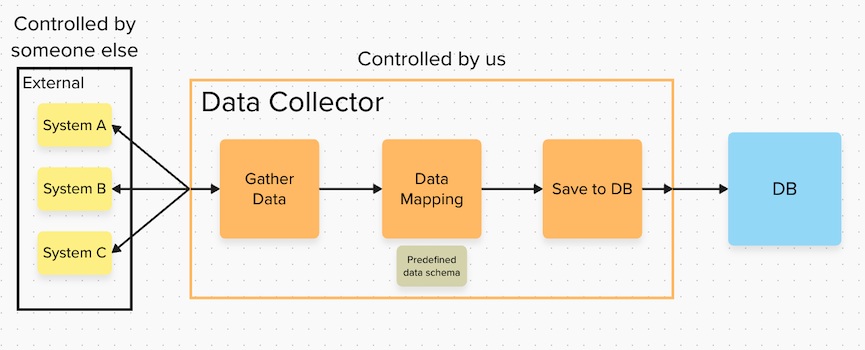
Another advantage is that now you have complete control over your data schema in only one location: your mapping file. If an external system changes its schema you need to only change the mapping file to take the source data from a different place, but you can keep the output schema intact, and the change doesn’t have to be propagated throughout your application.
The Implementation
The idea of data mapping can be implemented in many different ways, depending on which programming language your application is using and what format the data arrives in. For this example implementation, let’s assume that the application is written in python and the data arrives in JSON format.
Consider this example source data:
{
"name": "The Testing Company",
"location": "Zurich",
"size": 500,
"director": {
"dob": "1964-09-27",
"name": "Miriam Tester"
},
"building": {
"type":"office",
"year":"1948"
},
"customers": [
{
"name": "The Customer Company",
"location": "Berlin"
},
{
"name": "La Deuxieme Enterprise",
"city": "Paris"
}
]
}The mapping is specified in a separate JSON file. The attribute names in this file are the names in the final data schema, the values in this case are JMESPath expressions.
These expressions describe where in the source data to find the value for this attribute. JMESPath is a JSON query language which allows us to search for specific values in the
source data. There can be simple JSON paths but also more complex expression like or-expressions, indices and pipes. Here’s an example mapping that would transform the above
source file into a pre-defined schema of our own choosing:
{
"company_name": "name",
"director_name": "director.name",
"office": {
"city": "location",
"size": "size",
"built_year": "building.year"
}
}The result of applying this mapping to the above file would be:
{
"company_name": "The Testing Company",
"director_name": "Miriam Tester",
"office": {
"city": "Zurich",
"size": 500,
"built_year": "1948"
}
}However, even JMESPath has its limitations. For example, it cannot map objects in a list without explicitly knowing the item index. And we might know a source attribute contains a list and we want to map all list items in the same way but we don’t know in advance how many there will be. To address this problem we are defining a convention which the mapping specification adheres to. If the value of an attribute is a list, the first item in the list will contain only the JMESPath expression for the source list. The second item will contain the mapping for each list item. In this case, the list item mapping is only relative to itself so you cannot map attributes from other parts of the data here. Here’s the modified mapping file with the list mapping:
{
"company_name": "name",
"director_name": "director.name",
"office": {
"city": "location",
"size": "size",
"built_year": "building.year"
},
"customers": [
{
"source_list_name": "customers"
},
{
"customer_name": "name",
"customer_location": "location || city"
}
]
}You’ll notice that the mapping file specifies an or-expression for the customer location. This comes in handy if we want to make our mapping backwards compatible to different
versions of the data schema or the data is inconsistent. This expression will use the value of the “location” attribute if it can find it, and use “city” otherwise.
If we agree to this convention for lists and you apply this new mapping to the source file, the resulting data would look like this:
{
"company_name": "The Testing Company",
"director_name": "Miriam Tester",
"office": {
"city": "Zurich",
"size": 500,
"built_year": "1948"
},
"customers": [
{
"customer_name": "The Customer Company",
"customer_location": "Berlin"
},
{
"customer_name": "La Deuxieme Enterprise",
"customer_location": "Paris"
}
]
}To apply this mapping with python we are using a recursive function. The data arrives as a dictionary and the mapping is pre-defined in a JSON file which is loaded into another dictionary. These are passed to the recursive function which evaluates each attribute in the mapping definition to create the result data. If the value of an attribute is a string, we expect this to be a JMESPath expression and can map the attribute directly. If it’s an object, this nested object in turn has to be mapped according to the same specification. The mapping here is still relative to the entire data structure, so different parts of the data can be mapped into each other even if they are nested. If the value of an attribute is a list all list items are mapped according to the list item mapping (which is not relative to the entire data structure anymore but only to itself).
def map_company_data(company_data: Dict[str, Any]):
# type: (...) -> Dict[str, Any]
"""Maps a company data object to predefined schema"""
with open(f"path/to/mapping.json", encoding="utf-8") as mapping_file:
mapping = json.load(mapping_file)
mapped_company_data = map_items(company_data, mapping.items())
return mapped_company_data
def map_items(data: Dict[str, Any], mapping_definition: Dict[str, Any]):
# type: (...) -> Dict[str, Any]
"""Map a dictionary to a new dictionary according to its jmespath
mapping definition (recursively)"""
mapped_data = {}
for key, value in mapping_definition:
# If the value it's a dict, nested mapping is required.
# The mapping is still relative to the entire data structure.
if isinstance(value, dict):
mapped_data[key] = map_items(data, value.items())
# If the value is a list, map according to the convention,
# first item in the list specifies the source list name,
# second one the mapping for every list item.
# Mapping here is relative only to the list item itself.
elif isinstance(value, list):
mapped_data[key] = []
source_list_name = value[0]["source_list_name"]
for item in data[source_list_name]:
mapped_item = map_items(item, value[1].items())
mapped_data[key].append(mapped_item)
# If it's not a dict or a list, it should be a
# jmespath expression as a string and can be mapped
else:
mapped_data[key] = jmespath.search(value, data)
return mapped_dataConsiderations
- Depending on your needs and the amount of control you have over the different components, data mapping could also be implemented in a different component, such as the API or the UI itself.
- If your application is not written in python or the data you’re receiving is not in JSON format, the principle of data mapping still applies you just might need to use a different mapping implementation.
Final Thoughts
In volatile environments, data mapping can protect your application from unexpected errors and crashes. Apply data mapping at the entry point of your application to reap the full benefits, such as protection from unexpected schema changes and maintaining your data schema in a single location.
Supporting Information
- Click here to view the jmespath for python library
- Click here to view the full jmespath specification
Attribution
The cover image is provided free to use by Jan van der Wolf on pexels.com