

This post presents an architectural pattern that can significantly reduce complexity and bugs by aggregating multiple complex states into a single state that more accurately reflects the end-user’s experience.
The Problem
Our team was working on an interface that was written in React. The application needed to connect to the Microsoft Graph API to create a subscription and then use information from that subscription to connect to a SignalR endpoint to receive messages related to that subscription. This sounds easy enough, but the code we inherited was managing these connections separately (different timeout policies, retry policies, backoff policies, state not coordinated between the two, etc.). We were finding that this seemingly simple process was accounting for the majority of the bugs.
If we look deeper, we can see why it was complex:
- The subscription is only valid for a short time. What happens if the renewal fails?
- What happens if the SignalR connection fails but there is still a valid subscription?
- What happens if the user loses connectivity for a few seconds, or minutes, or hours?
- What impact does that have on the SignalR connection?
- What if the disconnected state is long enough that the subscription has expired?
- What happens if the user goes to lunch and their computer goes to sleep?
- What if one user logs out and another logs in?
- With different backoff policies, the user is left waiting for the longest of the connections to restore.
When each of those connections is managed independently of the other, there are a lot of edge cases to consider. There are a lot of places in code that need logic to check different states and determine what to do. The code complexity can also be quite high. This is a recipe for unexpected behaviors.
The Solution
If we consider the user’s perspective, they just need to know if they are “connected” (has everything needed to receive messages) or “disconnected” (one or more conditions are preventing the user from receiving messages). This is a simplification of the problem that makes it easier to reason about and write code for.
Both the Graph API and SignalR connections have their own SDKs with their own timeout, retry, and backoff policies. We removed those policies and instead put all the code into a connectivity loop that runs frequently to check the state of the connections and take action to restore them if necessary. The client enters the loop connected or disconnected and exits the loop connected or disconnected (as per the above definition). If there is a change in state, the client raises or removes the “connectivity error” condition.
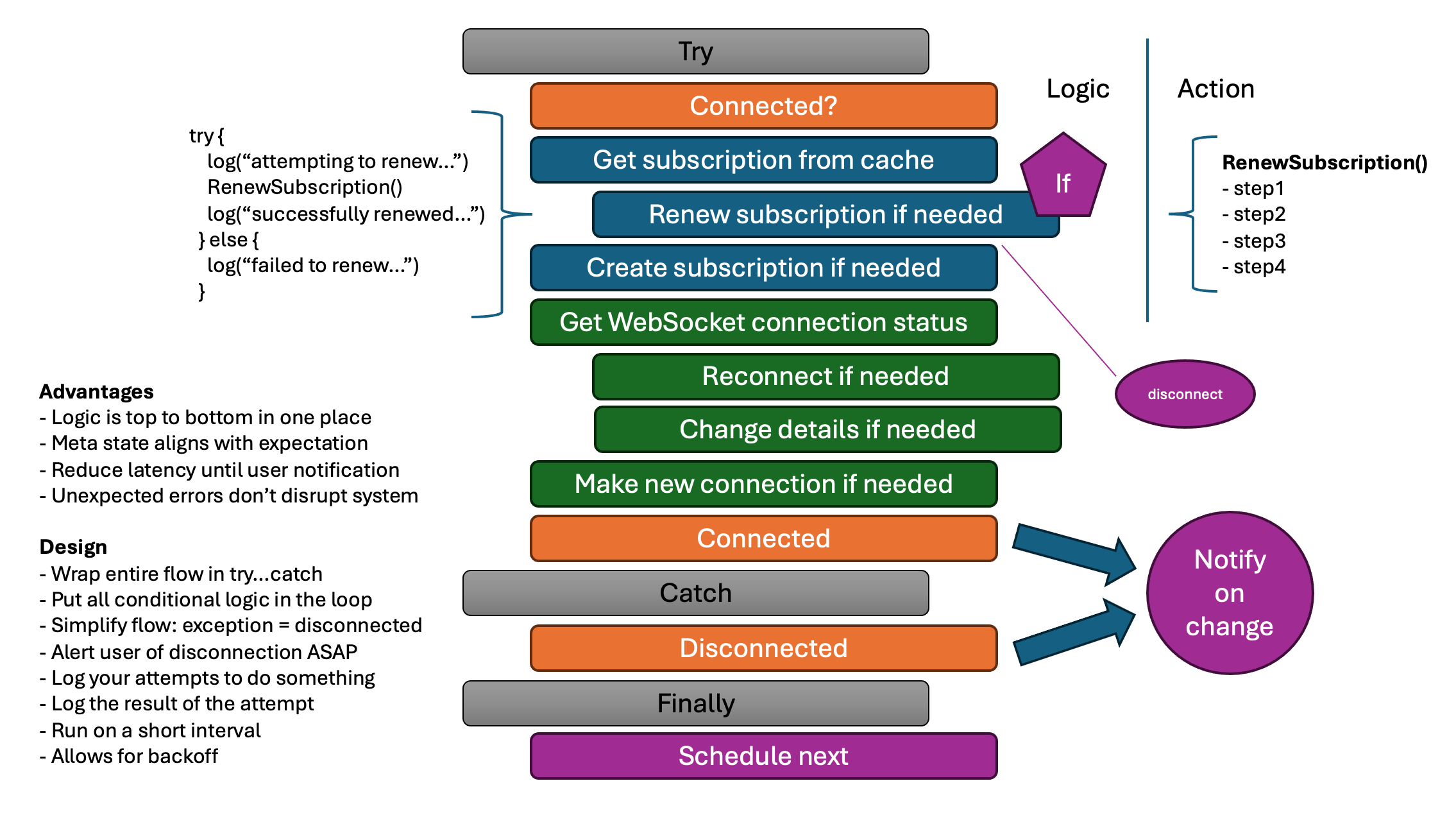
Advantages
-
Simplicity: We moved all our logic into a single function that can be read from top to bottom. It becomes very easy for a developer to determine what will happen when the function is executed. For instance, the logic that determines whether or not we need to renew the subscription is in this function, even if the code to actually renew the subscription is in a different place.
-
Notification: Rather than multiple blocks of code competing to notify the user of a problem or a correction of a problem, we now have a single place in our code that knows whether the user is connected (everything works) or disconnected (something doesn’t work).
-
Reduced Latency: As soon as any condition is met that would cause the user to be disconnected, the state is immediately changed to disconnected. This is important because timeouts and retries can take a long time to complete. If the user is disconnected, we want them to know they shouldn’t expect messages as soon as possible.
-
Reliability: We put a try…catch around all code in the function. If any unexpected conditions happen, we can catch them, alert the user the system is not functioning as expected, and can try again on the next loop. When the code related to connections was scattered throughout the application, there were often uncaught issues.
Design Considerations
When designing a state management solution similar to this, consider the following…
-
Continuity: Ensure your loop continues to run in all cases except fatal errors where you shutdown the application by wrapping everything in a try…catch. You don’t want to lose the ability to manage state because of a bug in the code.
-
Centralize: You want to ensure that all conditional logic is in this one function. This makes it easy to reason about and easy to test. If the logic to detect a condition is too complex, you could consider breaking that off into smaller functions that still allow you to have the conditional logic. For instance,
userIsLoggedIn() and subscriptionExists() and subscriptionExpired()still lets the developer know exactly how you are deciding to run this block of code without taking up a lot of space around how those conditions are detected. -
Simplify: You want to ensure that the flow of the function is as simple as possible. You want to be able to read the function from top to bottom and understand what is happening. For instance, the function we wrote knows the client is connected if there are no errors and disconnected if any errors are thrown (see above diagram). Rather than relying on a lot of branching logic we simply rely on failed conditions raising errors.
-
Fail Fast: You want to ensure that the user is notified as soon as you know they are in a failed state. You don’t want to wait for a timeout or a retry to complete before you notify the user. Often timeouts and retries can take minutes to resolve and the user would be under the mistaken impression that they are still operational.
-
Log Everything: The main purpose of this architectural pattern is improve the reliability of the application. To that end, you want to log every attempt to do something (ex.
log("attempting to renew subscription...")) and every result (ex.log("subscription renewed successfully.")orlog("subscription failed to renew.")). This will help you diagnose issues when they occur. -
Run Often: You want to alert the user quickly of any changes. We used 3 seconds. If detecting your states is time consuming, you might consider detection as a separate process and then the state management loop is just using those detections to determine the composite state.
-
Backoff: You must balance the need to alert the user quickly of state changes with the requirement not to overload your systems. If you remain in a failed state for long enough, you might consider scheduling the loop for increasing longer periods of time (ex. 3 seconds, 10 seconds, 30 seconds, 1 minute, 5 minutes, etc.).
Summary
This architectural pattern has been very successful for us. It has significantly reduced the complexity of our code and the number of bugs we have. It improved transparency (easy to read logs) and made it easier to reason about the code. We hope you find it useful as well.