

Introduction
With the advent of digital technology, payment methods for retail customers have evolved beyond traditional cash transactions to encompass a wide array of options. Today, customers can make purchases using credit and debit cards, mobile payment apps, contactless payments, and even cryptocurrencies in some cases. These modern payment solutions offer convenience, speed, and enhanced security, encouraging seamless transactions for both customers and retailers. Additionally, payment processors play a vital role in ensuring the swift and reliable transfer of funds, further streamlining the retail payment process. As the retail landscape continues to evolve, the focus remains on providing secure, user-friendly, and efficient payment methods to meet the dynamic needs of consumers and foster growth in the retail industry.
In this post, we will describe an engagement with a top retailer. We built a data ingestion framework that can receive payment transaction information from any data sources – internal or third party services – and process the events in near real-time. In this engagement a payment orchestrator platform from third party is used to customize and optimize all the payments through simple integrations. The ingestion framework is built to receive the payment transaction events from the payment orchestrator. The ingested data can be used to build reporting and analytics capabilities for both retailer and the merchants using the payment service from the retailer.
The problem
Payment service companies deal with several challenges, a few of which were applicable to our customer and are listed below:
- Legacy implementations of microservices with point-to-point API calls resulting in tightly coupled spaghetti-like architecture.
- Longer time to market of any new product feature or any change due to orchestration challenges resulting from poor architecture.
- Merchants were unable to access transaction level information and were only getting summaries of transactions.
- The transaction information was getting processed in daily batches bringing in high data latency.
Objective
The main objective of this blog is to walk you through the design and architecture that can be used to build a foundational capability that provides best practices for building an event based microservice system. This foundation enables the processing of the payment events received from the payment orchestrator in near real-time and helps in rapid application development and delivery. The architecture enables the customer to build real-time transaction views for merchants as well as to build reporting and analytics capabilities from the ingested data.
Though the architecture that we discuss in this blog is related to ingesting events from external payment providers, the pattern can be used to build solutions that leverage data ingested from any data source.
Architecture
The architecture is shown in Fig 1. It incorporates design considerations such as scalability, extensibility, performance, fault tolerance and self-healing. Dapr is being used as the distributed application runtime with microservices running on Azure Kubernetes Services and Azure Service Bus is being used as the message broker. This provides a robust, portable solution that enables developers to focus on building business logic and reduces the infrastructure complexity. Dapr provides reliable APIs for building portable and reliable microservices, that leverages industry best practices and focus on application logics. Azure Service Bus is used to decouple microservices from each other, providing the following benefits:
- Load-balancing work across competing workers
- Safely routing and transferring data and control across service and application boundaries
- Coordinating transactional work that requires a high-degree of reliability
This event-based data ingestion architecture starts with an external entity, the external payment orchestrator. The payment orchestrator performs all the payment transactions from a merchant’s e-commerce application. Whenever a payment is made, the external payment orchestrator emits granular transactions that can be listened to by anyone who is interested in consuming and building capabilities using the data.
There are two main data flows in this architecture:
- The first one receives the transaction data from the payment orchestrator, enriches and transforms the data and stores it in transaction database.
- The second one publishes the same data that is stored in the transaction database to a data warehouse.
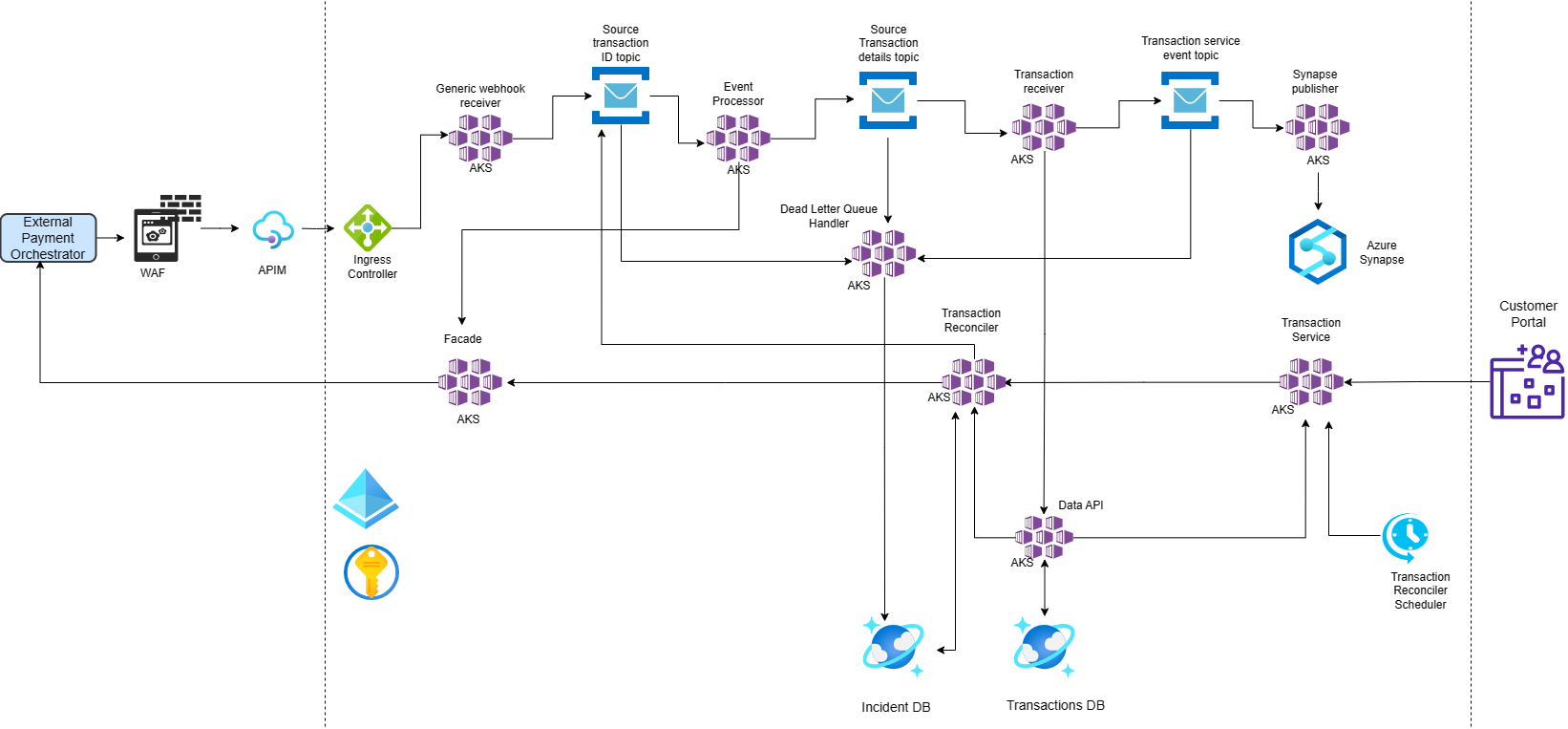
Fig 1: An event-based microservice architecture
In this architecture a Generic webhook receiver microservice, that is running in AKS, receives transaction events from third-party data providers. The implementation of this service depends on how the external data providers provide events to the consumers. The implementation should be easily extensible to adapt to other data providers. This service can be kept very lean with very basic filters and validations and publish only those events that are interesting to the downstream message broker. Normally the transaction information received by the Webhook receiver will be very minimal and often the downstream microservices will need to make a call back to external data providers to get the details of the transaction.
When downstream microservices require call back to external data providers, to enrich or transform ingested data, it is recommended to create a microservice that serves a single point of access to all out-going calls. This facade service can encapsulate the complex logic of connecting to external data providers – such as authentication, authorization, serialization, and deserialization of data etc. Having this logic in a single service avoids duplication of the same logic in many microservices.
In this architecture, the Event Processor calls the Facade service to get transaction details. The Event Processor service is a subscriber to the events published to the Message Broker by Generic webhook receiver microservice. The transaction details received from Facade service are then published by the Event Processor to another topic of the Message Broker to be transformed by a downstream service.
There can be many subscribers for transaction details published by the Event Processor to the Message Broker. In this architecture, we have one Transaction Receiver microservice as a subscriber that implements the data enrichment and transformation to a common data model. These transaction details are stored in a Transaction database. The transaction data is used for building reports that are shown in a portal for merchants. The Transaction Receiver also publishes the transformed data to another Message Broker topic. In this architecture, there is another microservice that subscribes to the topic to publish transaction details to a data warehouse for Analytical Reports.
To make this architecture fault tolerant and self-healing, there are two services included. These services handle missing events due to transient errors and exceptions in the system. The event reconciliation for missing events are handled via the Dead Letter Queue handler and Transaction Reconciler services. We will discuss in detail these two mechanisms later in the blog.
Common Data Model and Data Access Layer
A common data model for the transaction data helps in extending the solution to more data sources. The following are some of the design considerations for coming up with a common data model:
- The data model should be extensible to more data sources in the future.
- Keep the common attributes in a header section of the data model.
- Selection of attributes in the header section should be based on how frequently they are accessed/modified.
- The data read / write needs to be fast.
- Keep the original payload data in the data model.
By moving frequently accessed attributes to the header section, the performance of the queries are improved and the indexes can be created for the attributes in the header.
{
"Source": "source1",
"SourceId" : "source1Id",
"TransactionId" : "abc12345678",
"MerchantName": "ABC",
"BuyerId": "buyer12345",
"TransactionType": "CNPTransaction",
"Amount": 155,
"Currency" : "USD",
"Status": "PartialRefund",
"PaymentMethod": "CardDebit",
"UpdatedAt": "2023-02-30T05:39:02.587283+00:00",
"CreatedAt": "2023-03-16T03:30:33.271242+00:00",
"RefundedAt": "2023-02-28T05:39:02.587283+00:00",
"SourceData": {
"Source1": {
"<The original transaction data from payment orchestrator. The header is extracted from this source data>"
},
},
}The data access layer abstracts the actual datastore so that the application can switch from one datastore to another easily. This implements the separation of concerns pattern where all business logic is abstracted from the datastore. The Command Query Responsibility Segregation pattern can be used for implementing the data access layer to separate responsibilities for read and write operations.
Advantage of using Command Query Responsibility Segregation pattern :
- Hides the underlying tech stack and exposes a Rest API.
- Extending/Changing DB design in future is easy and has less impact on clients.
- Read and Write DBs (stack) are different
Strategies for handling errors and missing events
In an event-based software system, handling errors and missing events is a critical aspect of ensuring the reliability and consistency of the system. Since messages are the primary means of communication between different components of the system, errors or missing events can result in a wrong state of the system. In this context, it is important to have strategies in place to handle errors and missing events in a way that minimizes their impact and ensures that the system always reaches a consistent state eventually.
Dead letter handling and incident database
The purpose of the dead-letter queue is to hold messages that cannot be delivered to any receiver, or messages that could not be processed.
A message can be dead lettered at
- Application Level
- System Level
Messages can then be removed from the DLQ and inspected. An application might, with help of an operator, correct issues and resubmit the message, log the fact that there was an error, and take corrective action.
From an API and protocol perspective, the DLQ is like any other queue, except that messages can only be submitted via the dead-letter operation of the parent entity. In addition, time-to-live isn’t observed, and you can’t dead-letter a message from a DLQ. There’s no automatic cleanup of the DLQ. Messages remain in the DLQ until you explicitly retrieve them from the DLQ and complete the dead-letter message.
Classification of exceptions
In any architecture, handling exceptions is crucial because it allows the application to gracefully recover from errors, maintain stability, and provide a better user experience.
One of the essential aspects of exception handling is classifying exceptions based on their characteristics and severity. By categorizing exceptions, it is easy to implement appropriate actions to deal with each type effectively. Not all exceptions can be treated the same way; some require immediate attention and resolution, while others can be managed more passively.
This is where a dead letter mechanism comes into play. A dead letter mechanism is a feature in software systems that deals with messages or data that cannot be processed successfully due to exceptions or other issues. When an exception occurs, instead of allowing it to propagate and cause further problems, the system can direct the problematic message to a designated dead letter queue (DLQ) or an incident queue.
All exceptions are classified as either Non-Retryable Errors or Retryable Errors:
- Non-Retryable Errors
- When an incoming payload contains critical information that is malformed or missing, it’s crucial to not let it propagate further in the sequence of events as they can lead to unpredictable outcomes. The recommended action here is to log the error details and discard the payload. Additionally, it’s good practice to catch these errors in the application to prevent downstream issues. While dead-lettering is an option, it’s preferred to log and discard non-retry-able malformed payloads to keep the workflow streamlined.
- Unhandled exceptions are unforeseen errors that require manual intervention. These exceptions are not known to the system, and they can disrupt the application’s normal flow. When encountering an unhandled exception, the best course of action is to dead letter the message proactively allowing the operations team to investigate and resolve the issues promptly. Integrating observability dashboards to monitor these incidents can also provide valuable insights into system performance.
- Retryable Errors – Retryable errors often arise due to transient conditions, such as temporary connectivity issues or unavailability of resources. In scenarios like refund or business-related transactions, retrying the operation after a brief delay can resolve the issue. It’s essential to implement a robust retry mechanism with exponential backoff to avoid overwhelming the system during intermittent outages. Monitoring tools can help track the frequency of retry attempts, enabling teams to identify underlying issues and take corrective actions promptly
Exception Handling should be chained, more specific to less specific. If the exception is known/observed by the system, the application should handle it.
Dead Letter Queue Handler
The Dead Letter Queue Handler is responsible for purging messages from the dead letter queues of the various topics of the Service Bus. By categorizing errors based on their nature, such as non-retryable (malformed payloads, unhandled exceptions, etc) and retryable (transient conditions), we can implement appropriate actions to handle each situation effectively. Leveraging an incident DB for unhandled exceptions, logging and discarding non-retryable malformed payloads, and incorporating a well-designed retry mechanism for transient errors helped us to ensure a stable and responsive application environment.
The Dead Letter Queue handler can take the following actions for different types of exceptions :
- The System-level exceptions are retried as per Service Bus retry policy. The message arrives in the dead letter queue after the configured maximum delivery attempts. The DLQ Handler adds relevant metadata and sends the message to the Incident DB.
- The Application-level exceptions that are retried as per configured Dapr retry policy. Dapr provides configuration to set resiliency policies for timeouts, retries, and circuit breakers. Once the delivery count is exceeded the message arrives in the DLQ. The DLQ Handler adds relevant metadata and sends the message to the Incident DB.
- The Application-level unhandled exceptions that are unforeseen errors that require manual intervention are sent to the incident DB after adding relevant metadata
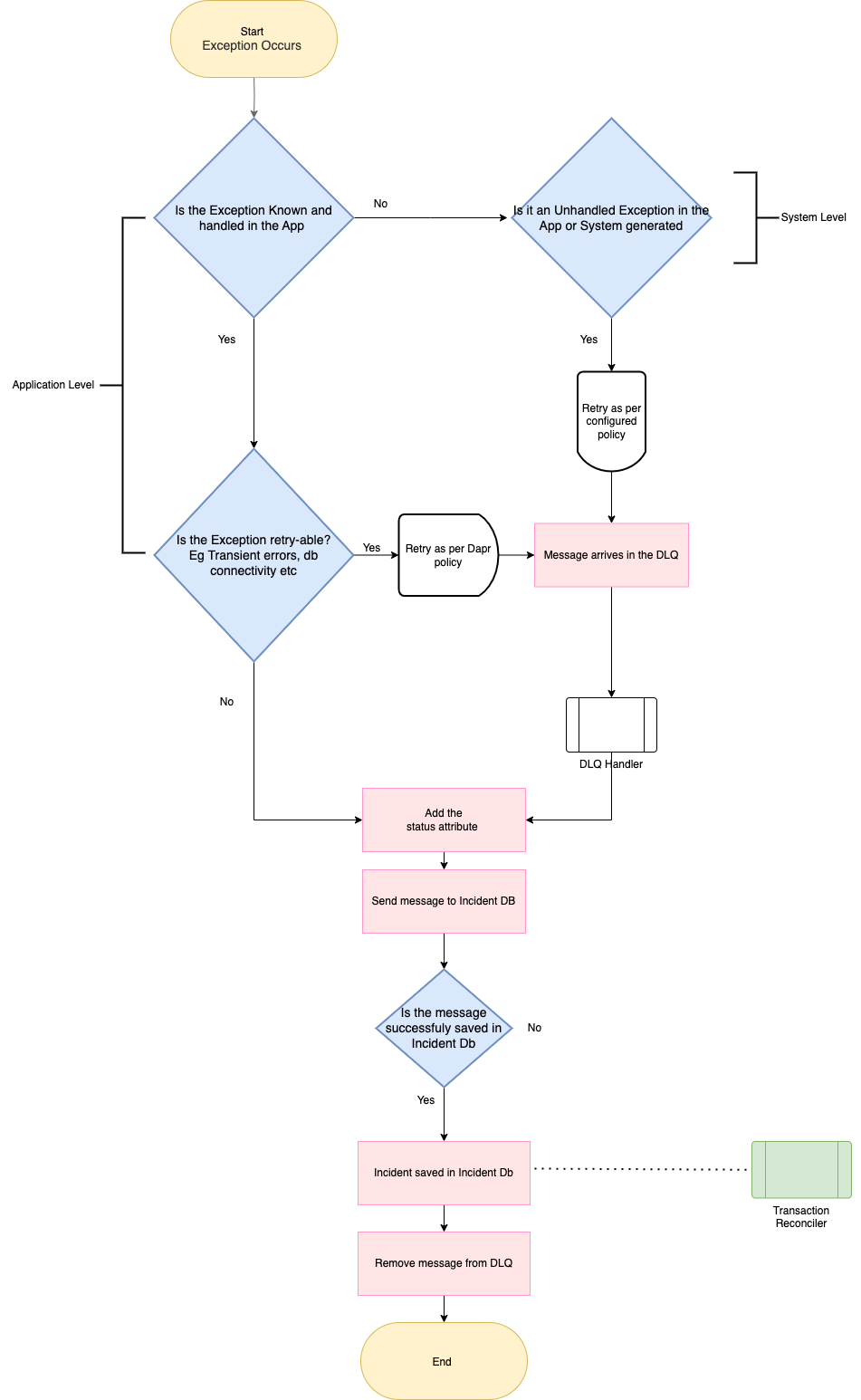
The incident DB acts as a centralized repository for all the errors and incidents. The metadata has information such as status which is assigned a value of Resolved, Retried from DLQ, Triage, or Manual Triage. This allows the operations team to investigate and resolve the issues promptly. This also makes it easier for the reconciler to know the state of the system programmatically. Integrating observability dashboards to monitor these incidents can also provide valuable insights into system performance.
Reconciliation
Reconciliation refers to the process of ensuring that the actual state of a system matches the desired state. This is typically done by comparing the current state of the system to a known good state, and then taking corrective action to bring the system back into alignment if necessary. For the payment service that is built using the payment orchestrator, the known states will be the latest payment transaction data stored in the payment orchestrator.
In this architecture, the job of comparing the current state with the good state is performed by the Transaction Reconciler service, another microservice in the cluster. Transaction reconciler periodically fetches the list of transactions updated or created after the last run, compares that with what is saved in transactions database based on the last updated time in both places, and finds the IDs for the records that need to be corrected/created. These records correspond to missed-out events from the payment orchestrator or processing error within the system.
Transaction Reconciler first checks if the ID is present in the incident database to see if there was an error processing that transaction within the system. If the ID is not found in the incident database, it’s published to the source transaction ID topic as a new event. These events are then processed like the events received from the payment orchestrator.
Existence of the ID in the incident DB means that the reconciler must honor a retry policy as well. This is to avoid processing a transaction too many times. It might need manual intervention to fix. In these cases, the ID is published to the topic only if it hasn’t reached the retry limit. The retry count on the incident record is incremented and status is updated as reprocessed or needs manual triage depending on whether it has reached the retry limit before publishing the event.
Observability
For Microservices applications built on Dapr, the observability platform should be able to capture the logs, metrics and traces from each individual application and also correlate them. Ideally, every request should be traceable end to end. The OpenTelemetry collector can be used for tracing and logging purposes, ensuring comprehensive visibility into the application’s behavior. To efficiently analyze and monitor the OpenTelemetry collects the data, the data can be exported to log and trace analytics tools like Azure Application Insights or third-party observability platforms. This integration helps in exporting the traces, metrics, and log data to observability platform, empowering the business to gain valuable insights and effectively manage the performance and health of the Dapr-based microservices applications. In addition, the OpenTelemetry can be also used to collect infrastructure metrics and export to observability tools to get the health and performance data from servers, containers, database and other backend components in the tech stack.
Summary
This post explored how to build robust transaction processing solutions for retail customers using modern payment methods. It provided best practices and design considerations for building scalable, extensible, performant, fault-tolerant, and self-healing solutions. It presented an event-based microservice architecture that leverages Dapr, Azure Kubernetes Services, and Azure Service Bus to ingest payment transaction events from external payment orchestrators and process them in near real time. Finally, it covered various topics such as the data model, the exception handling, the reconciliation process, and the observability of the data ingestion system.
Resources
Dapr – Distributed Application Runtime
Contributors
Thanks to my colleagues who have contributed to the content for this blog post:
Arun Kumar Linda Thomas Prachi Kushwah Manjit Singh Shivam Singh Sudhir Chandra Sujoy Saha