

In our previous blog post about the new Microsoft Store, we talked about how it’s a native C#/XAML Windows application running on the UWP framework, and how it leverages .NET Native to be distributed as a 100% AOT binary with great startup performance. We also discussed how we’ve been working to refactor the codebase to make it faster, easier to maintain, and to work almost entirely in C# running on the .NET runtime.
As we recently announced at Microsoft Build in our session on Windows Application Performance, lately we’ve also worked to enable trimming in the Microsoft Store, allowing us to both improve startup times and significantly reduce binary size. In this blog post, we wanted to elaborate and introduce trimming to developers that might not be familiar with it already. We’ll explain how it works, the benefits it brings, and the tradeoffs that must be done in order to leverage it.
We’ll also use examples from our changes to the Store to explain common scenarios that might require extra work in order to make your codebase trimmable. And lastly, we’ll show you how to stay ahead by spotting code that might not be trimming friendly and architecting new code to make transitioning to trimming as smooth as possible.
So, here’s a deep dive on trimming in the .NET world! 🍿
Trimming in a nutshell
Trimming is a process that lets the compiler remove all unreferenced code and unnecessary metadata when compiling an application. In the context of the Microsoft Store, which ships as a 100% native binary produced by the .NET Native toolchain, trimming can affect both generated code as well as reflection metadata: both can be independently stripped if not needed.
Specifically, trimming is performed in the dependency reduction step of the toolchain. Here, the compiler will combine all the application code that is directly referenced, along with additional information from XAML files and from some special-cased reflection APIs, and use this information to determine all code that could ever be executed.
Everything else is just thrown away! 🧹
Why should you be interested in this? The main benefit it brings is that removing all of this unnecessary code can greatly reduce the binary size of your application, which brings down hosting costs and also makes downloads faster. It can also improve performance in some cases, especially during startup, due to the runtime having less metadata to load and keep around while executing.
Recent versions of .NET support this as well, as we’ll see later on, and they do so both through IL trimming and binary trimming (in ReadyToRun and NativeAOT builds). So almost everything in this blog post (the risks of trimming, making code suitable for being statically analyzed, etc.) applies to nearly all trimming technologies in .NET, which is why we wanted to share this with the community 🙌
How to enable .NET Native trimming
The way trimming (among other things) is controlled on .NET Native is through a runtime directive file (the generated Default.rd.xml file in a blank UWP app). In this case, this file will contain hints to instruct the compiler about how trimming should be performed. That is, directives here will force it to preserve additional members on top of those already statically determined to be necessary by the dependency reduction step.
This also means that this file can disable trimming completely, if the hint given to the compiler simply says “just keep everything”. In fact, this is what all UWP applications do by default: they will preserve all metadata for the entire application package. The default runtime directive file looks something like this:
<!-- Directives in Default.rd.xml -->
<Directives xmlns="http://schemas.microsoft.com/netfx/2013/01/metadata">
<Application>
<Assembly Name="*Application*" Dynamic="Required All" />
</Application>
</Directives>That *Application* name is a special identifier that tells the compiler to just disable trimming entirely and preserve all code in the whole application package. This makes sense as a default setting, for compatibility reasons, and is conceptually similar to how modern .NET applications work: trimming is disabled by default (even when using AOT features such as ReadyToRun), to ensure less friction and consistent behavior especially for developers migrating code. Modern .NET also uses a very similar file to allow developers to manually give hints to the compiler for things that should be preserved, if needed.
What Dynamic="Required All" does is it instructs the compiler to act as if all code in the entire application was being accessed via reflection. As such, the compiler will generate AOT code and all necessary data structures to make all that code be executable at runtime. Of course, this severely affects the binary size of the resulting application.
Instead, with trimming enabled, the behavior would be the opposite: the compiler would start compiling just the Main() method of the application and then from there it would crawl the entire package and create a graph to identify all code paths that could potentially be executed, discarding everything else.
So, all that’s really needed to get started with this is to just remove that directive, compile the app with .NET Native, and start experimenting. Creating a package without that line is also a very good idea (even without actually making sure the app works) to get a rough estimate of how much binary size could potentially be saved with trimming. This can also help to evaluate how much effort could be worth it, depending on how large this size delta is for your application. ⚗️
Common pitfalls and things that can break
Perhaps unsurprisingly, having the compiler physically delete code can have all sorts of unwanted side effects if one is not very careful. The issue is that in order for trimming to be safe, the compiler needs to be extremely accurate when trimming out code that should never be executed.
When reflection and dynamic programming are used instead, these assumptions can end up being inaccurate, and bad things can happen. What’s worse, many of these issues can only be detected at runtime, so thoroughly testing the code is crucial to avoid introducing little ticking time bombs all over the codebase when enabling trimming. 💣
To make some examples of things that might break:
Type.GetType(string)might returnnull(the target type might even be gone entirely).Type.GetProperty(string)andType.GetMethod(string)might returnnullas well, if the compiler has accidentally removed the member we’re looking for.Activator.CreateInstance(Type)might fail to run.- Reflection-heavy code in general (eg.
Newtonsoft.Jsonfor JSON serialization) might crash or just work incorrectly, for instance by missing some properties of objects being serialized.
Some of these APIs can be slightly more resilient on .NET 6+ in cases where the target types are known at compile time, thanks to the new trimming annotations. For instance, an expression such as typeof(MyType).GetMethod("Foo") will work with trimming too, because GetMethod is annotated as accessing all public methods on the target type. Here that type is known at compile time (it’s MyType), so all of its methods will be safe to reflect upon at runtime.
.NET Native also recognizes plenty of reflection APIs in similar cases, but the fact those APIs are not annotated and that there is no analyzer available means that it’s not possible to really know for sure whether a given call is safe to trim, which makes things trickier. That is, a lot more trial and error is generally involved on .NET Native compared to .NET 6, which shows how the ongoing effort to improve things in this area by the .NET team is making things a lot better over time. 🏆
That said, trimming will still cause problems in all cases where arguments are not immediately known when building code, so trying to minimize reflection use in general is still very important. Furthermore, doing so will also allow you to save even more binary size: if you only need to access the method Foo, why would you want to keep all public methods on that type instead of just that one? Proper trimming-friendly code can help you go the extra mile there! ✈️
There are two things that can be done to work around issues caused by trimming:
- Refactoring code to just stop using these APIs entirely.
- Adding some runtime directives to give hints to the compiler (“hey, I really need this metadata!”).
We’ll see how both approaches can be used and how to choose between the two in the rest of this post.
Key point for debugging trimming
There is a crucial aspect of trimming that must be kept in mind when using it. Since trimming generally isn’t used in Debug builds, the runtime behavior can differ between Debug and Release, meaning it’s extremely important to be very careful when investigating and testing out code.
It’s good practice to regularly test Release builds with trimming enabled (or Debug ones too if trimming can be enabled there as well) to account for things that might have broken because of it. This is especially recommended after making larger changes to your application. 🔍
Case study: retrieving target properties
The first example of refactoring from the Store is about removing a pattern that is relatively common to see in applications. You might have seen code similar to this yourself in the past, especially when looking at application code. Consider a method trying to dynamically retrieve the value of some well known property:
public string TryGetIdFromObject(object obj)
{
return obj.GetType().GetProperty("Id")?.GetValue(obj) as string;
}The GetType().GetProperty(string)?.GetValue bit is quite convenient: you want to get the value of a property with a given name, and you know that this method will be used with a variety of different objects that may or may not have the property. This solves the issue in a single line of code, so it’s plausible that a developer would end up using this solution.
But, this is terrible for trimming: there is no way for the compiler to know exactly what object type will be received as input by this method, except for very specific cases where it might be able to inline the method into a callsite where the argument type was known. As a result, trimming might very well remove the reflection metadata for that property, causing that line to fail to retrieve any values.
The fix for this case is simple. Instead of relying on reflection to interact with members on any arbitrary object, the relevant members should be moved directly onto a type, with consumers leveraging the exposed type directly. This pattern is known as dependency inversion, and will be a core principle in your journey to making your codebase trimming-friendly.
In this case, we can achieve this by simply adding an interface:
public interface IHaveId
{
string Id { get; }
}And then that method would simply become:
public string TryGetIdFromObject(object obj)
{
return (obj as IHaveId)?.Id;
}This is just a minimal example, but we’re trying to introduce a mindset that rethinks how components depend on each other, in order to facilitate trimming. Let’s move to an actual example of code we have in the Store to showcase this.
In our product page, we display a button to let users perform various actions such as buying, renting, installing, etc. in an area that we refer to as “buybox”. In our code, we have a SkuSelectorConfiguration type that’s one of the components involved in setting this button. This type takes care of doing some checks on the available SKUs for the product (we have a Sku data model we’ll be using in this example) to determine how the buybox button should be configured and displayed.
Part of the code we used to configure these buttons used to look like this:
// Some selector for buying products
return new SkuSelectorConfiguration
{
Id = configurationId,
PropertyPath = "AvailableForPurchase",
// Other properties...
};
// Some selector for renting products
return new SkuSelectorConfiguration
{
Id = SelectorConfigurationId.BuyOrRent,
PropertyPath = "IsRental",
// Other properties...
};
// Some selector for choosing a streaming service
return new SkuSelectorConfiguration
{
Id = SelectorConfigurationId.StreamOption,
PropertyPath = "ExternalStreamingService.Id",
// Other properties
}These are a small set of all the possible SKUs. As you can see, there are quite a lot of different combinations to support. In order to make this system flexible, this SkuSelectorConfiguration type was exposing a PropertyPath property taking the path of the property to retrieve the value for. This would then be used in some other shared logic of the selector to determine the right buybox button configuration.
As a side note, this code should’ve used a nameof expression where possible instead of hardcoded literals, which would’ve made it less error prone. Of course, doing so wouldn’t have solved the issues with respect to trimming, but it’s still good to keep this feature in mind in case you had to write something similar to this. For instance, "IsRental" could have been written as nameof(Sku.IsRental), which eliminates the chance of typos and ensures the literal remains correct even when refactoring.
As you’d expect, a lot of reflection is involved here. Specifically, that code needed to parse the various property path components of that input path, and explore the target Sku object to try to retrieve the value of that (potentially nested) property being specified. When trimming is enabled, all the metadata for those properties might be gone entirely given the compiler would not see it being useful. As a result, this wouldn’t work correctly at runtime.
One way to fix this is to replace all of those string parameters to accept a Func<Sku, object?> object instead. This would allow consumers to still be able to express arbitrary paths to retrieve properties and nested properties for a given Sku object, while still making the code statically analyzable.
This also has the advantage of making the code less brittle, as it’d be no longer possible to make typos in the property path, or to forget to update a path in case a property was renamed. We will see how these two very welcome side effects are a recurring theme when doing trimming-oriented refactorings.
Here is what the selectors shown above would look like with this change:
return new SkuSelectorConfiguration
{
Id = configurationId,
PropertyAccessor = static sku => sku.AvailableForPurchase,
// Other properties...
};
// Some selector for renting products
return new SkuSelectorConfiguration
{
Id = SelectorConfigurationId.BuyOrRent,
PropertyAccessor = static sku => sku.IsRental,
// Other properties...
};
// Some selector for choosing a streaming service
return new SkuSelectorConfiguration
{
Id = SelectorConfigurationId.StreamOption,
PropertyAccessor = static sku => sku.ExternalStreamingService.Id,
// Other properties
}The result is still very easy to read, and the code is now perfectly trimming-friendly 🎉
Of course, this is a very small change, and that’s why we started here to introduce the topic. Our goal here is raising awareness on what to look out for in order to make a codebase trimming-friendly. This is important, as many of these code paths might not be perceived as potentially problematic, unless looking at them in the context of trimming.
Once you’re in this mindset and can identify and make these changes, the payoff is well worth it!
Let’s look at two more examples from the Store that required more changes and restructuring in order to allow the code to support trimming.
Case study: type name for page layout selectors in XAML
The Store has a very dynamic UI, and one of the things that makes it so is the fact that we have many different templates and layouts to display content based on several criteria, such as adapting to different form factors and screen sizes, or rearranging or restyling templates depending on the device in use or product being viewed. The end result is a rich and beautiful UX for the end user.
This was one of the areas where some refactoring had to be done to make the code more trimmer friendly. Again, this is code that was working just fine before, and had been working fine for years, but that just wasn’t meant to be used together with trimming. As such, it makes for another good example of how you can change your approach to make code better suited for static analysis.
You can imagine we had some interface to act as a template selector, that might look like this:
public interface ILayoutSelector
{
string SelectLayout(ProductModel product);
}Objects using this interface will be responsible for selecting a given layout to use for an input product, and return a string representing the resource key to get that layout from the XAML resources. All XAML resources are preserved automatically, so we don’t need to worry about trimming interfering with that aspect.
We had several controls in the Store that were working with these layout selectors in an abstract way. That is, they would be initialized with the type of layout selector to use, and then they’d try to create an instance and use that to select layouts for input products. This made them very flexible and easily reusable across different views.
The way they were initially implement though was not trimming-friendly. We had something like this:
public abstract class PageLayout
{
private ILayoutSelector _layoutSelector;
public string LayoutSelectorTypeName
{
set
{
try
{
_layoutSelector = (ILayoutSelector)Activator.CreateInstance(Type.GetType(value));
}
catch (TargetInvocationException e)
{
Log.Instance.LogException(e, $"Failed to create a {value} instance.");
}
catch (ArgumentNullException e)
{
Log.Instance.LogException(e, $"Failed to find type {value}.");
}
}
}
// Other members here...
}This was resilient to errors, including the constructors of the input layouts throwing some exception (in that case the layout selector being null would instead gracefully be handled by the rest of the code in the control), and allowed developers to easily pass arbitrary selectors in XAML, like so:
<DataTemplate x:Key="AppLayout">
<local:AppPageLayout LayoutSelectorTypeName="MicrosoftStore.Controls.StandardPdpLayoutSelector" />
</DataTemplate>Now, what if we wanted to enable trimming? Our layout selectors (eg. StandardPdpLayoutSelector in this case) will be seen by the compiler as never being instantiated: there are no direct calls to their constructors anywhere in the codebase. This is because we’ve hardcoded the type name as a string, and are constructing an instance with Activator.CreateInstance (what’s worse, the non-generic overload, which gives the compiler no type information whatsoever).
As a result, when performing trimming, the compiler would just completely remove these types, causing that Type.GetType call to return null, and the layout selector instantiation to fail completely. What’s worse, this is all happening at runtime, so there’s no easy way to catch this in advance.
Furthermore, even ignoring this, the code above is particularly error prone. Each type name is just a hardcoded string that might contain some typos or might not be updated when the type is renamed or refactored. We want to find a solution that’s both less brittle and statically analyzable.
A first solution would be to just change PageLayout to directly accept an ILayoutSelector instance, and then instantiate the layout selector directly from XAML, like so:
<DataTemplate x:Key="AppLayout">
<local:AppPageLayout>
<local:AppPageLayout.LayoutSelector>
<controls:StandardPdpLayoutSelector/>
</local:AppPageLayout.LayoutSelector>
</local:AppPageLayout>
</DataTemplate>This is much better already: the type is directly referenced from XAML, there is no chance of typos, refactoring is covered (the XAML would be updated), and the compiler can now easily see this type being directly used. But we’re still not covering all the cases we were before. What if instantiating a layout selector threw an exception? This might be the case for special selectors that use other APIs to help select which layouts to use, such as getting more information about the current device.
To work around this, we can once again invert our previous logic, and introduce a factory interface:
public interface ILayoutSelectorFactory
{
ILayoutSelector CreateSelector();
}It’s critical for this interface to be non-generic, since we’ll need to use this in XAML.
Now, we can write a very small factory associated to each of our selector types. For instance:
public sealed class StandardPdpLayoutSelectorFactory : ILayoutSelectorFactory
{
public ILayoutSelector CreateSelector()
{
return new StandardPdpLayoutSelector();
}
}These factory instances simply act as very thin stubs for the constructors of the target type we want to instantiate. These are extremely small objects that are also only ever instantiated once in each control that uses them, so they’re essentially free and add no overhead whatsoever. Not to mention, they’re still much faster than going through an Activator.CreateInstance call anyway.
Now, we can update the definition of PageLayout to use this interface instead:
public abstract class PageLayout
{
private ILayoutSelector _layoutSelector;
public ILayoutSelectorFactory LayoutSelectorFactory
{
set
{
try
{
_layoutSelector = value.CreateSelector();
}
catch (Exception e)
{
Log.Instance.LogException(e, $"Failed to create a selector from {value}.");
}
}
}
// Other members here...
}With this, all callsites in XAML will look like this:
<DataTemplate x:Key="AppLayout">
<local:AppPageLayout>
<local:AppPageLayout.LayoutSelectorFactory>
<controls:StandardPdpLayoutSelectorFactory/>
</local:AppPageLayout.LayoutSelectorFactory>
</local:AppPageLayout>
</DataTemplate>And that’s it! This gives us all the benefits we’re looking for:
- It’s validated at build time so there’s no chances for typos or issues if code is refactored.
- It’s completely statically analyzable given all types are now directly referenced.
We can now enable trimming without worrying about this part of the codebase causing issues.
Also worth mentioning how once again, making the code reflection-free not only solved our issues with trimming here, but also ended up making the code more resilient in general, which reduces the chances of bugs being introduced. This is something that’s extremely common with this type of refactoring, and a good reason why you should keep these principles in mind (especially for new code), even if you don’t plan to enable trimming in the short term.
Case study: data contract attributes factory
Just like you’d expect for an app that interacts with the web, the Store has a lot of code to deal with web requests and JSON responses.
One aspect of our architecture that required a lot of restructuring to make it trimmer friendly was creating the data models that wrapped the deserialized JSON responses from web requests. We call these response objects data contracts, and we then have our own data models wrapping each of these instances to layer additional functionality on top of them. The rest of our code, especially the one in the UI layer, only ever interacts with these data models, and never with the data contracts themselves.
To make a minimal example, you could imagine something like this:
public sealed record ProductContract(string Id, string Name, string Description); // Other properties...
public sealed class ProductModel
{
private readonly ProductContract _contract;
public ProductModel(ProductContract contract)
{
_contract = contract;
}
// Public properties here for the rest of the app...
}Now, this is particularly simple here, but there are some key aspects to consider:
- Many of our data models can be constructed from and/or wrap different contract types. That is, they may have multiple constructors, each receiving a different contract object as input, and then initializing the state of that data model. There is no specific contract that a data model has to respect: each model might only map to a single contract types, or several of them, depending on the specific case.
- The code doing web requests doesn’t directly interact with the contract types used to deserialize the JSON responses. These types are hidden away and considered an implementation detail, especially given that in many cases they’re not even known at build time, but only when the JSON responses are deserialized (since many responses are polymorphic). All that the code doing a request knows is what endpoint it wants to use, what parameters it wants to pass, and what data model
Tit wants to receive back as a response.
The architecture to handle this that the Store has been using since the start was (understandably) based on reflection. Specifically, there was a [DataContract] attribute that was used to annotate data models with their respective contract types. These attributes were then being retrieved at runtime and used to detect applicable constructors to lookup and invoke to create data model instances (again through reflection). It looked something like this:
[AttributeUsage(AttributeTargets.Class, AllowMultiple = true)]
public sealed class DataContractAttribute : Attribute
{
public DataContractAttribute(Type contractType)
{
ContractType = contractType;
}
public Type ContractType { get; }
}A data model, like the one mentioned in the example above, would then be annotated like so:
[DataContract(typeof(ProductContract))]
public sealed class ProductModel
{
public ProductModel(ProductContract contract)
{
// Initialization here...
}
// Rest of the logic here...
}If a data model had multiple constructors accepting different data contract types, it would then also be annotated with additional [DataContract] attributes to indicate that. Then at runtime, this was all being used as follows:
public static T? CreateDataModel<T>(object dataContract)
where T : class
{
// Parameter validation here... (omitted for brevity)
// If the data contract is already of type T, nothing else to do
if (dataContract is T model)
{
return model;
}
// Get all [DataContract] attributes on the data model type
object[] contractAttributes = typeof(T).GetCustomAttributes(typeof(DataContractAttribute), inherit: false);
// Get all data contract types from those retrieved attributes
IEnumerable<Type> contractTypes = contractAttributes.Select(static a => ((DataContractAttribute)a).ContractType);
// Loop through all declared contract types for the data model type
foreach (Type contractType in contractTypes)
{
// If the contract type is not of this type (nor assignable), skip it
if (!contractType.IsAssignableFrom(dataContract.GetType()))
{
continue;
}
// Locate constructor that accepts this contract type as parameter
ConstructorInfo constructor = typeof(T).GetConstructor(new[] { contractType })!;
return (T)constructor.Invoke(new[] { dataContract });
}
return null;
}With this method, each caller can just do a web request, get some object back representing the deserialized web response, and invoke this method to try to create a T data model instance. This works just fine, and for people that might have worked in similar applications before, a setup like this might look familiar. There is nothing inherently wrong with this, and in fact it’s just using reflection, a very powerful tool that’s a fundamental building block of .NET, to implement an API that makes things simpler for callers. It is also making code self-descriptive as each data model can declare what contracts it supports right over its own type definition.
But, this does have some considerable drawbacks:
- There’s no build-time validation that a data model type effectively exposes a constructor matching the contract that it declared via its attributes. It’s easy to just forget to add a contructor and then have code trying to look it up via reflection later on just fail and crash.
- There is also no build-time validation that each constructor has a matching attribute: it’s more than possible to just forget to add an attribute, causing that data model to fail to be created. If you’re wondering “Why have the attributes in the first place, instead of just going through all constructors directly?”, that is certainly possible, but doing so could introduce other problems, in case a data model needed to expose additional constructors that are meant to be called manually elsewhere. Having the attributes instead guarantees that only those meant to be used for automatic deserialization will be looked up.
- The elephant in the room here is the fact that as far as the compiler is concerned, none of those constructors are ever referenced. As a result, trying to enable trimming here would (and did) cause the compiler to just remove all those methods entirely, and then the code to fail to run because those constructors it was trying to look up via reflection were now nowhere to be seen.
There are multiple ways to work around this, and one is to manually give some hints to the compiler to tell it to preserve additional metadata and code here. For instance, you might look at the .NET Native troubleshooting guide and the MissingMetadataException troubleshooting tools for types and methods and come up with something like this:
<!-- Directives in Default.rd.xml -->
<Directives xmlns="http://schemas.microsoft.com/netfx/2013/01/metadata">
<Application>
<Type Name="MicrosoftStore.DataModels.DataContractAttribute">
<AttributeImplies Activate="Required Public" />
</Type>
</Application>
</Directives>Such a directive would inform the compiler to preserve the public constructors for all types annotated with this [DataContractAttribute], which would avoid having the app crash. But, even this still has several drawbacks:
- We haven’t solved the issue of code being brittle and error prone.
- We still suffer the same performance issues as before (this reflection-based approach is very slow, even using some caching to avoid retrieving attributes and constructors multiple times).
- …We have just blocked trimming here, we haven’t actually fixed the issue. That is, while this might prevent the crashes we would’ve experienced otherwise, it’s more of a workaround and not an actual solution. With directives like this, the compiler will be forced to preserve more metadata and code than what’s actually needed, meaning it won’t give us the results we’re looking for.
- This approach introduces another problem too: if we start accumulating directives like this for the whole codebase, we’re now introducing yet another possible failure point, where it needs to be manually kept in sync with changes in the rest of the code to avoid causing crashes at runtime. What’s worse, we not only won’t have any kind of build-time checks to help us here, but this is something that cannot even be detected in normal Debug builds as trimming is not generally used there. This makes bugs especially difficult to spot.
Let’s take a step back. As we said, the current solution is fine on its own, but it’s not what you’d want to write if you were building a system like this from scratch, with support for trimming in mind. This is what we meant by trimming requiring a shift in mindset when writing code: can we rethink the way this code is structured to make this code statically analyzable and no longer rely on reflection?
One thing immediately comes to mind here when looking at the code: like many libraries that heavily rely on reflection, the control flow here has each type self-describing its contract through attributes, and then there is a centralized piece of logic elsewhere that reads these annotations and performs logic to create instances of these data model types.
What if we turned this upside down and instead made each type be responsible for its own instantiation logic, with the rest of the code only delegating to these helpers in each contract type?
This kind of change is exactly what we ended up doing in the Microsoft Store. Instead of using attributes and the code we just showed, we introduced this interface to clearly define a “data contract”:
public interface IDataModel<TSelf>
where TSelf : class
{
TSelf? Create(object dataContract);
public static class Factory
{
public static TSelf? Create(object dataContract);
}
}Enter IDataModel<TSelf>. This interface is the new contract that each data model will implement, and it will expose a single API (the Create method) to allow each data model to provide the logic to create an instance of that type directly from there. This is an example of the dependency chain inversion that is often very beneficial for trimming: since we now have the logic be implemented at the leaf nodes of our class diagram, there is no need to use reflection to introspect into these types from a central place later on to try to figure out what to do.
This is how the data model showed earlier looks like using this new interface:
public sealed class ProductModel : IDataModel<ProductModel>
{
private SomeDataModel(ProductContract dataContract)
{
// Initialization here...
}
ProductModel IDataModel<ProductModel>.Create(object dataContract)
{
return dataContract switch
{
ProductContract productContract => new(productContract),
// As many other supported contracts as we need here...
_ => null
};
}
// Rest of the logic here...
}With this approach, the Create is explicitly implemented to only ever be visible when accessed through the interface, since that’s the only case where it’s meant to be invoked.
The implementation is stateless (this will be important later) and only does type checks on the input and forwards the downcast object to the right constructor. This ensures that the compiler can “see” a reference to each constructor being invoked, which means it will be able to preserve it automatically (but not its reflection metadata). This gives us both functionality with trimming enabled, as well as reduced binary size, as only the actual code that needs to run is kept.
Now, these Create methods from each data model have to be invoked from somewhere, but on what instance? We’re trying to create some T object, so we have no T to invoke this interface method upon. To solve this, here’s the implementation of that static Create method in the nested IDataModel<TSelf>.Factory class:
public static class Factory
{
private static readonly TSelf _dummy = (TSelf)RuntimeHelpers.GetUninitializedObject(typeof(TSelf));
public static TSelf? Create(object dataContract)
{
// If the data contract is already of the requested type, just return it
if (dataContract is TSelf dataModel)
{
return dataModel;
}
// If the the model type is an IDataModel<T>, try to create a model through its API
if (_dummy is IDataModel<TSelf> factory)
{
return factory.Create(dataContract);
}
return null;
}
}Here, we’re relying on the RuntimeHelpers.GetUnitializedObject API, which is a special method that will create a dummy instance of a given type, without running a constructor at all (which means the type doesn’t even need to have a parameterless constructor at all). This API is also recognized by .NET Native and will work with trimming enabled as well. What we’re doing is using it to create a cached dummy instance of some TSelf type, and then using that to call the Create factory method if that object implements IDataModel<TSelf>.
This gives us extra flexibility because it means we can check support for this interface at runtime, without needing to have the self constraint on the generic type parameter bubble up to all callers. That is, this both makes our public API surface simpler, and allows using this code for other types as well, such as when trying to deserialize some web response as eg. a simple IDictionary<string, string> object.
With this, callers can now be rewritten as follows:
object response = await GetSomeWebResponseAsync();
// Before
DataModel model = DataSources.CreateDataModel<DataModel>(response);
// After
DataModel model = IDataModel<DataModel>.Factory.Create(response);Same functionality for callers, but completely reflection-free and statically analyzable! 🎊
This new version is also completely allocation free (and much faster), as we’re no longer using those reflection APIs. Making all of this faster and reducing allocations wasn’t even the main goal here, but it’s just a nice side effect that comes often with code refactorings that are meant to remove reflection and make the code more trimming-friendly.
Picking your battles: when not trimming is ok
As we just showed, there are cases where not using reflection might not be possible, and where it might make more sense to just give some hints to the compiler and sacrifice binary size a bit. This is the case for our JSON serialization in the Store. Currently, we’re using Newtonsoft.Json, which is completely reflection-based.
We want to stress that this is not inherently bad: this is a great library that is incredibly powerful and easy to use, and there’s nothing wrong with it. Moreover, trimming has only been a real concern in the .NET world in recent years, and reflection has been a fundamental building block for .NET applications since day 1, so it makes perfect sense for this to use reflection. It has also been written way before Roslyn source generators existed.
While we start investigating eventually moving to System.Text.Json and the new source generator powered serializers in the Store in the future, we still need to get this to work with trimming today. This is a good example when it’s completely fine to just give up on trimming, and to just use some directives to inform the compiler about what we need to do. We can still enable trimming in the entirety of our application package, and just preserve reflection metadata specifically for the data contract types we need to deserialize from web requests.
That is, we can just add something like this to our runtime directives:
<!-- Directives in Default.rd.xml -->
<Directives xmlns="http://schemas.microsoft.com/netfx/2013/01/metadata">
<Application>
<Assembly Name="MicrosoftStore.DataContracts" Dynamic="Required Public"/>
</Application>
</Directives>This will preserve all metadata and logic for public members of all types in our data contract assembly. That means that when Newtonsoft.Json tries to introspect them to setup its deserializers, it will work as expected as if trimming wasn’t enabled – because it just wouldn’t be, specifically for those types. This is a good compromise between functionality and binary size: being able to still trim everything else in the whole package we can still get all the advantages that trimming brings, while only giving up on a few KBs for the types in this assembly.
Always think about where it makes sense to invest time when annotating a library for trimming: it may end up you’ll save most of the binary size without reaching 100% coverage, while reducing the time needed to implement the feature by quite a lot. Just like when optimizing code, always remember to take a step back and consider the bigger picture. 💡
Contributing back to open source
Since being more open and contributing back into open source is something we deeply care about, we took this opportunity to apply the things we learned here to improve code from the OSS projects we were using.
For instance, one of the things that broke when we first enabled trimming in our internal builds (we knew there would’ve been small issues to iron out) were the toast notifications. These are displayed by the Store in several cases, such as when the recently announced Restore Apps feature is triggered, to inform users that apps are being automatically installed on their new device.
To display these toast notifications, we’re using the ToastContentBuilder APIs from the Windows Community Toolkit. Turns out, those APIs were internally heavily relying on reflection. As a result, when we enabled trimming and started testing Store builds in more scenarios, this is how our notifications started showing up:
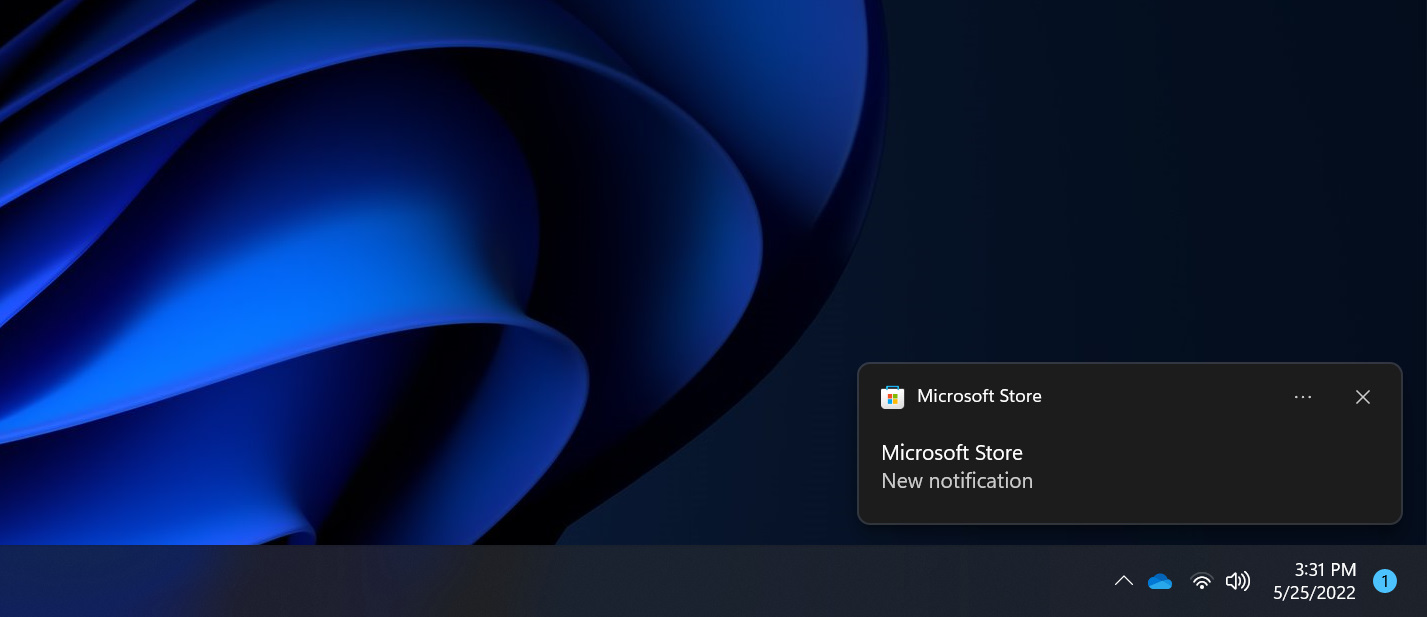
…Oops! 🙈
This notification would normally have a meaningful title, a description, and an image. Due to trimming though, reflection metadata had been stripped from the ToastContentBuilder APIs containing the information on all the components we wanted to display. This caused the serialization logic to just generate a blank XML document to register the notification, causing it to only show up with the app title and some default text.
We could fix this by manually preserving directives for this assembly as showed earlier:
<!-- Directives in Default.rd.xml -->
<Directives xmlns="http://schemas.microsoft.com/netfx/2013/01/metadata">
<Application>
<Assembly Name="Microsoft.Toolkit.Uwp.Notifications" Dynamic="Required Public"/>
</Application>
</Directives>Similarly to the data contract types mentioned above, this directive informs the compiler to preserve all metadata information for all public types in the whole Microsoft.Toolkit.Uwp.Notifications assembly. This does fix the issue, but we decided to also contribute back to the Toolkit to refactor those APIs to stop using reflection entirely. This would allow consumers to not have to deal with this at all, and it would also save some more binary size given the compiler would then be able to delete even more code when compiling the application.
If you’re interested in seeing the kind of changes involved, you can see the PR here.
Binary size difference in the Microsoft Store
Now that it’s clear what kind of changes are required in order to make a codebase trimming-friendly, you might be wondering how much size all of this actually saves. Was all this effort worth it?
Here’s a size comparison for two builds of the Microsoft Store, with the only difference being that one has trimming enabled as well:
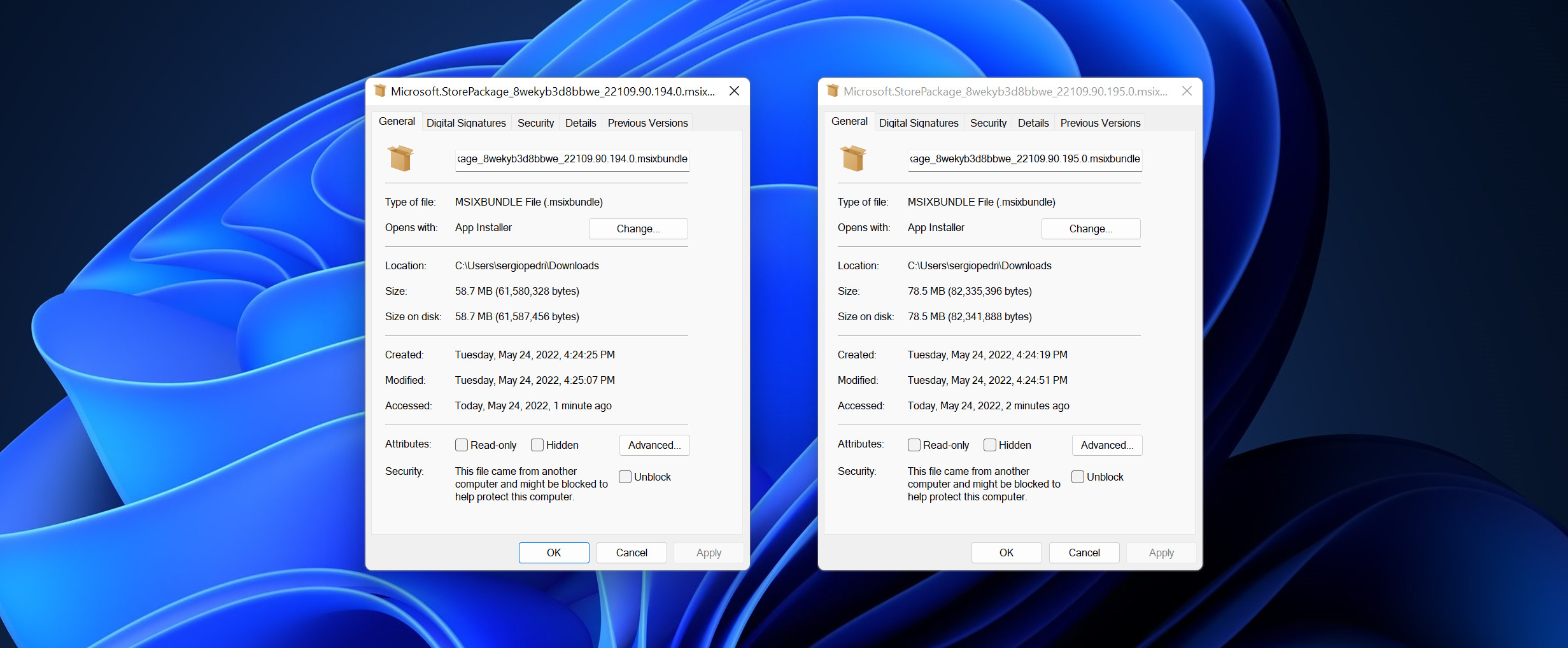
You can see that the app package with trimming enabled (on the left) is 25% smaller! 🎉
This means the compiler could literally delete one quarter of our entire binary thanks to this. The package in the screenshot includes both the x86, x64, and the brand new native Arm64 binaries for the Microsoft Store. It being more compact not only means startup is faster as there’s less to load from disk, but updates are faster too as there’s less to download, as well as steady state performance in some scenarios.
Final thoughts
We’ve seen what trimming is, the pitfalls it has and the kind of work it can require to enable it without issues. It was certainly not straightforward to enable in the Store, and while working on this we certainly went through a good amount of crashes, blank pages, and all sorts of invalid states. It was challenging but also lots of fun, and we do feel the improvements it brought were worth the effort!
We have very recently pushed a new version of the Microsoft Store with trimming enabled to Windows Insider users, and we are looking forwards to everyone being able to try this out along with all the other new improvements we have been working on! ✨
While this experiment was successful, we feel like this is a good example of just how tricky it can be to enable trimming on an existing, large codebase that hasn’t been written with support for this in mind, which is why we wrote this blog post.
As mentioned in our Microsoft Build talk on Windows applications performance, it’s important to always keep performance and trimming in mind when writing new code. We recommend using these two concepts as guiding principles when developing, as doing so will save you so much time down the line if you decide to go back and enable trimming, and even without considering that it will still likely force you to write code that is more resilient and less error prone, as the examples above showed.
Adoption tips
If you’re thinking about enabling trimming in a published application, here’s a few additional key points to summarize the pros and cons of enabling it, and good practices you can follow to help minimize risks:
- Trimming brings great benefits for both publishers and users alike, but it’s not risk-free. To prevent bad surprises, you should consider doing additional testing and adopting your release pipeline to it.
- Consider releasing your application to a small group of users before rolling it out to 100% of your target market (eg. going from employees only, to beta testers, to insider users only, etc.).
- Automated UI testing can help avoid regressions, as these tests would be using the actual final build artifacts in the same conditions as the end users. It might not always be possible to specifically test for trimming with just local unit tests, due to different build/run configurations.
- Consider performing extensive manual testing as well, especially in areas that might have undergone extensive refactoring to make them trimmer-friendly, to ensure the changes were effective in solving trimming issues.
Additional resources
If you’re interested in learning more on how trimming and runtime directives work on .NET Native in particular, you can also refer to these blog posts from the .NET Native team on the topic. They contain additional information on how the .NET Native toolchain performs trimming, and examples of common scenarios that might cause issues, and how to fix them:
- .NET Native introduction
- Dynamic features in static code
- Help! I hit a MissingMetadataException!
- Making your library great
Additionally, .NET 6 also has built-in support for trimming (see docs here), meaning it not only supports it for self-contained builds, but also ships with a brand new analyzer and set of annotations (some of which we’ve shown earlier in this post) that greatly help identifying code paths that might be trimming-unfriendly and potentially cause issues.
For more on this, and especially for library authors that want to ensure their packages will allow consumers to confidently enable trimming in their applications, we highly recommend reading the docs on this here from the .NET team. They come bundled with lots of useful information, code samples and useful tips to help you enable trimming in your own code! 🚀
Happy coding! 💻
.NET Native being now in maintenance mode, what’s your plan going forward? Will the Microsoft Store eventually be migrated to WinUI & .Net?
BTW, the one thing I’m missing in .NET Native is ARM64EC support, which .Net has no plans to adopt anyway.
The Microsoft Store is already running on WinUI and .NET as a UWP app.
All of the wisdom in this blog post can be applied to any kind of code trimmer.
In the section about refactoring string literals, I believe you have a typo in the new code.
Shouldn’t that be sku.AvailableForPurchase? Granted, if this were a real code change, the complier would obviously catch this, so point taken.
Whoops, yup that was indeed a typo, fixed! Thanks 😄