
In previous posts I’ve talked about performance improvements that our team contributed to the Git community. At Microsoft, we’ve been pushing Git to its limits with the largest and busiest Git repositories on the planet, improving core Git as we go and sending these improvements back upstream. With Git 2.21.0 and later you can take advantage of a new sparse pack algorithm that we developed to dramatically improve the git push operation on large repos. For example, the Windows team saw a 7.7x performance boost once they enabled this new feature. In this post I want to explain the new sparse pack algorithm and why it improves performance.
If you want to try it yourself, the new algorithm is available in Git and Git for Windows versions 2.21.0 and later. We also shipped this algorithm in VFS for Git 1.0.19052.1 and later. If you want to skip the details and enable this on your machine, run the following config command:
git config --global pack.useSparse true
This enables the new “sparse” algorithm when constructing a pack in the underlying git pack-objects command during a push.
Let’s dig into the difference between the old and new algorithms. To follow the full details, you may want to brush up on some Git fundamentals, such as the basic Git objects: commit, tree, and blob.
What does git push do?
When you run git push from your client machine, Git shows something like this:
$ git push origin topic
Enumerating objects: 3670, done.
Counting objects: 100% (2369/2369), done.
Delta compression using up to 8 threads
Compressing objects: 100% (546/546), done.
Writing objects: 100% (1378/1378), 468.06 KiB | 7.67 MiB/s, done.
Total 1378 (delta 1109), reused 1096 (delta 832)
remote: Resolving deltas: 100% (1109/1109), completed with 312 local objects.
To https://server.info/fake.git
* [new branch] topic -> topic
That’s a lot of data to process. Today, I want to focus on the “Enumerating Objects” phase. Specifically, there is a computation that happens before any progress is output at all, and it can be very slow in a large repo.
In the Windows repo, “Enumerating objects” was taking up to 87% of the time to push even small changes. Instead of walking at least three million objects, we are now walking fewer than one thousand in most cases.
What does “Enumerating objects” mean?
When you create a new repo, the first push collects all objects and sends them in a single pack-file to the remote. This is essentially the same operation as a git clone, but in reverse. In the same way that later git fetch operations are usually faster than your first git clone, later pushes should be faster than your first push.
To save time, Git constructs a pack-file that contains the commit you are trying to push, as well as all commits, trees, and blobs (collectively, objects) that the server will need to understand that commit. It finds a set of commits, trees, and blobs such that every reachable object is either in the set or known to be on the server.
The old algorithm first walks and marks the objects that are known to be on the server, then walks the new objects, stopping at the marked objects. The new algorithm walks these objects at the same time.
To understand how it does that, let’s explore the frontiers of Git.
The Commit Frontier
When deciding which objects to send in a push, Git first determines a small, important set of commits called the frontier. Starting at the set of remote references and at the branch we are trying to push, Git walks the commit history until finding a set of commits that are reachable from both. Commits reachable from the remote refs are marked as uninteresting while the other commits are marked as interesting.
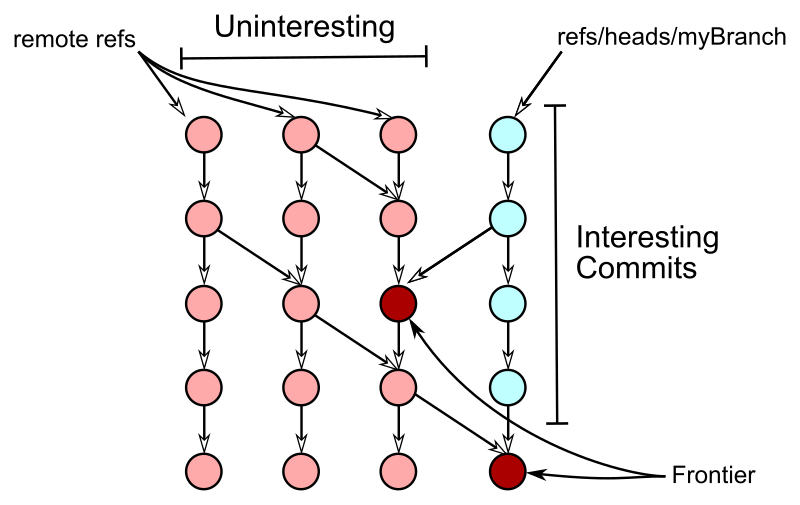
The uninteresting commits that are direct parents of interesting commits form the frontier. This frontier set is likely very small when pushing a single branch from a developer. This could grow if your branch contains many merge commits formed from git pull commands.
Since this frontier is much smaller than the full set of uninteresting commits, Git will ignore the rest of the uninteresting commits and focus on the frontier for the remainder of the command.
An important feature of the new algorithm is that we walk the uninteresting and interesting commits at the same time. At each step, we use the commit date as a heuristic for deciding which commit to explore next. This helps identify the frontier without walking the entire commit history, which is usually much larger than the full explored set.
The rest of the algorithm walks trees to find which trees and blobs are important to include in the push.
Old Algorithm
To determine which trees and blobs are interesting, the old algorithm first determined all uninteresting trees and blobs.
Starting at every uninteresting commit in the frontier, recursively walk from its root tree and mark all reachable trees and blobs as uninteresting. This walk skips trees that were already marked as uninteresting to avoid revisiting potentially large portions of the graph. Since Git objects form a Merkle tree, portions of the working directory that do not change between commits are stored as the same trees and blobs, with the same object hash. In the figure below, this is represented by a smaller set of trees walked from the second uninteresting commit. The “already uninteresting” connections are marked by arcs into the larger uninteresting set.

The issue with this algorithm is clear: if your repo has thousands of paths and you only changed a few files, then the uninteresting set is much larger than the interesting set. In large repos, there could easily be hundreds of thousands of paths. In the Windows OS repo, there are more than three million paths.
To fix the performance, we need to make this process more like the commit frontier calculation: we need to walk interesting and uninteresting trees at the same time to avoid walking too many uninteresting objects!
New Algorithm
The new algorithm uses paths as our heuristic to help find the “tree frontier” between the interesting and uninteresting objects. To illustrate this, let’s consider a very simple example.
Imagine we have a large codebase whose folder structure starts with folders A1 and A2. In each of those folders is a pair of folders B1 and B2, and so on along the Latin alphabet. Imagine that we have interesting content in each of these folders.
As you are doing your work, you create a topic branch containing one commit, and that commit adds a new file at A2/B2/C2/MyFile.txt. You want to push this change, and thinking about the simple diff between your commit and its parent you need to send one commit, four trees, and one blob. Here is a figure describing the diff:
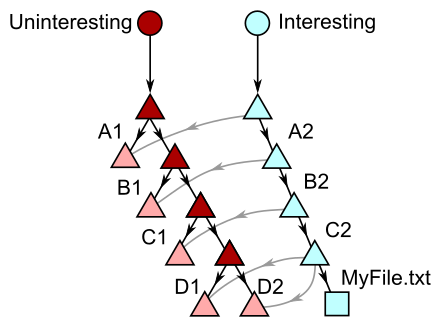
As you walk down your change, you can ignore all of the trees along paths A1, A2/B1, A2/B2/C1, A2/B2/C2/D1, and A2/B2/C2/D2 since you don’t change any objects in those paths.
The old algorithm is recursive: it takes a tree and runs the algorithm on all subtrees. This doesn’t help us in the example above, as we will need to walk all 226 paths (approximately 67 million paths). This is an extreme example, but it demonstrates the inefficiency.
The new algorithm uses the paths to reduce the scope of the tree walk. It is also recursive, but it takes a set of trees. As we start the algorithm, the set of trees contains the root trees for the uninteresting and the interesting commits.
As we examine trees in the set, we mark all blobs in an uninteresting tree as uninteresting.
It is more complicated to handle the subtrees. We create a collection of tree sets, each associated with a path name. When we examine a tree, we read each subtree as a (path, tree) pair. We place the subtree in the set corresponding to that path. If the original tree is uninteresting, we mark the subtree as uninteresting.
After we create the collection of tree sets, we recursively explore each set. The trick is that we do not need to explore a set that contains only uninteresting trees or only interesting trees.
This process is visualized in the figure below.
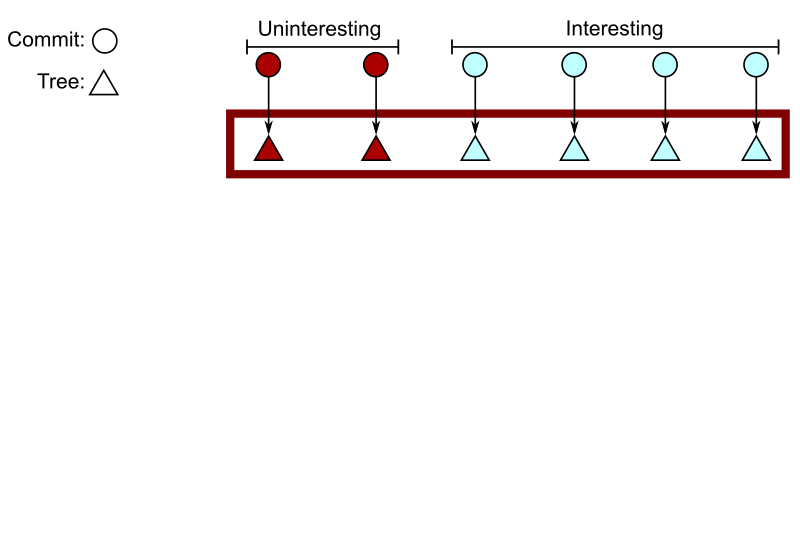
In this specific example our root trees contain three paths that point to trees: A, B, and C. None of the interesting trees change any files in A, so all of those trees are uninteresting and we can stop exploring. The uninteresting trees do not contain the path C (this must be a new path introduced by the interesting commits) so we can stop exploring that path. The trees at the path B are both uninteresting and interesting, so we recursively explore that set.
Inside the trees at B, we have subtrees with names F and G. Both sets have interesting and uninteresting paths, so we recurse into each set. This continues into B/F and B/G. The B/F set will not recurse into B/F/M or B/F/N and the B/G set will not recurse into B/G/X but not B/G/Y.
Keep in mind that in each set of trees, we are marking blobs as uninteresting, too. They are just not depicted in the figure.
If you want a more interactive description of this algorithm, John Briggs talked about this algorithm as part of his talk at Git Merge 2019. You can watch the whole video below, or jump to his description of the push algorithm.
When you use this algorithm as a developer doing normal topic work, this algorithm successfully focuses the tree walk to paths that you actually changed. In most cases, that set is much smaller than the set of paths in your working directory, which is how git push can get so much faster.
If you want to get into the code, you can inspect the patches to Git directly. The meat of the algorithm is implemented in this commit, and includes some concrete performance numbers.
0 comments