

It’s been 3 months since I first wrote about our efforts to scale Git to extremely large projects and teams with an effort we called “Git Virtual File System”. As a reminder, GVFS, together with a set of enhancements to Git, enables Git to scale to VERY large repos by virtualizing both the .git folder and the working directory. Rather than download the entire repo and checkout all the files, it dynamically downloads only the portions you need based on what you use.
A lot has happened and I wanted to give you an update. Three months ago, GVFS was still a dream. I don’t mean it didn’t exist – we had a concrete implementation, but rather, it was unproven. We had validated on some big repos but we hadn’t rolled it out to any meaningful number of engineers so we had only conviction that it was going to work. Now we have proof.
Today, I want to share our results. In addition, we’re announcing the next steps in our GVFS journey for customers, including expanded open sourcing to start taking contributions and improving how it works for us at Microsoft, as well as for partners and customers.
Windows is live on Git
Over the past 3 months, we have largely completed the rollout of Git/GVFS to the Windows team at Microsoft.
As a refresher, the Windows code base is approximately 3.5M files and, when checked in to a Git repo, results in a repo of about 300GB. Further, the Windows team is about 4,000 engineers and the engineering system produces 1,760 daily “lab builds” across 440 branches in addition to thousands of pull request validation builds. All 3 of the dimensions (file count, repo size and activity), independently, provide daunting scaling challenges and taken together they make it unbelievably challenging to create a great experience. Before the move to Git, in Source Depot, it was spread across 40+ depots and we had a tool to manage operations that spanned them.
As of my writing 3 months ago, we had all the code in one Git repo, a few hundred engineers using it and a small fraction (<10%) of the daily build load. Since then, we have rolled out in waves across the engineering team.
The first, and largest, jump happened on March 22nd when we rolled out to the Windows OneCore team of about 2,000 engineers. Those 2,000 engineers worked in Source Depot on Friday, went home for the weekend and came back Monday morning to a new experience based on Git. People on my team were holding their breath that whole weekend, praying we weren’t going be pummeled by a mob of angry engineers who showed up Monday unable to get any work done. In truth, the Windows team had done a great job preparing backup plans in case of mishap and, thankfully, we didn’t have to use any of them.
Much to my surprise, quite honestly, it went very smoothly and engineers were productive from day one. We had some issues, no doubt. For instance, Windows, because of the size of the team and the nature of the work, often has VERY large merges across branches (10,000’s of changes with 1,000’s of conflicts). We discovered that first week that our UI for pull requests and merge conflict resolution simply didn’t scale to changes that large. We had to scramble to virtualize lists and incrementally fetch data so the UI didn’t just hang. We had it resolved within a couple of days and overall, sentiment that week was much better than we expected.
One of the ways we measured our success was by doing surveys of the engineering team. The main question we asked was “How satisfied are you?” but, of course, we also mined a lot more detail. Two weeks into the rollout, our first survey resulted in:

I’m not going to jump up and down and celebrate those numbers, but for a team that had just had their whole life changed, had to learn a new way of working and were living through a transition that was very much a work in progress, I felt reasonably good about it. Yes, it’s only 251 survey responses out of 2,000 people but welcome to the world of trying to get people to respond to surveys. 🙂
Another way we measured success was to look at “engineering activity” to see if people were still getting their work done. For instance, we measured number of “checkins” to official branches. Of course, half the team was still on Source Depot and half had moved to Git so we looked at combined activity over time. In the chart below you can see the big drop in Source Depot checkins and the big jump in Git pull requests but overall the sum of the two stayed reasonable consistent. We felt that the data showed that the system was working and there were no major blockers.

On April 22nd, we onboarded the next wave of about 1,000 engineers. And then on May 12th we onboarded another 300-400. Each successive wave followed roughly the same pattern and we now have about 3,500 of the roughly 4,000 Windows engineers on Git. The remaining teams are currently working to deadlines and trying to figure out when is the best time to schedule their move, but I expect, in the next few months we’ll complete the full engineering team. The scale the system is operating at is really amazing. Let’s look at some numbers…
- There are over 250,000 reachable Git commits in the history for this repo, over the past 4 months.
- 8,421 pushes per day (on average)
- 2,500 pull requests, with 6,600 reviewers per work day (on average)
- 4,352 active topic branches
- 1,760 official builds per day
As you can see, it’s just a tremendous amount of activity over an immensely large codebase.
GVFS performance at scale
If you look at those satisfaction survey numbers, you’ll see there are people who aren’t happy yet. We have lots of data on why and there are many reasons – from tooling that didn’t support Git yet to frustration at having to learn something new. But, the top issue is performance, and I want to drill into that. We knew when we rolled out Git that lots of our performance work wasn’t done yet and we also learned some new things along the way. We track the performance of some of the key Git operations. Here is data collected by telemetry systems for the ~3,500 engineers using GVFS.
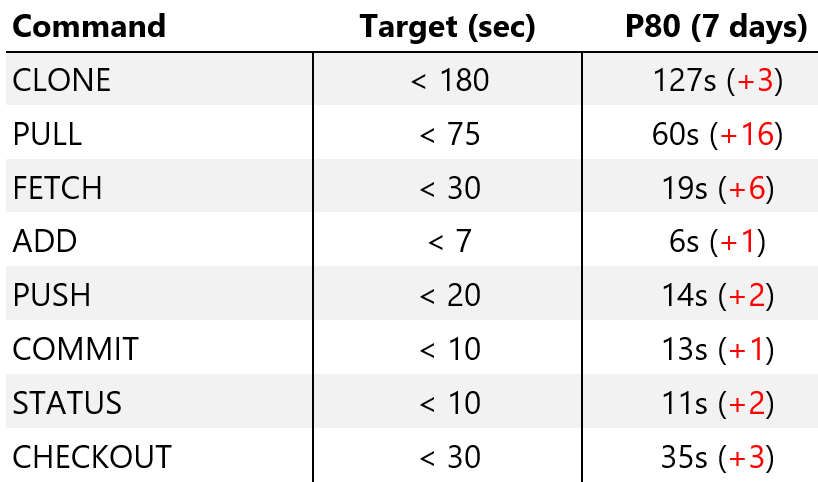
You see the “goal” (which was designed to be a worst case, the system isn’t usable if it’s slower than this value, not a “this is where we want to be” value). You also see the 80th percentile result for the past 7 days and the delta from the previous 7 days (you’ll notice everything is getting slower – more on that in a minute).
For context, if we tried this with “vanilla Git”, before we started our work, many of the commands would take 30 minutes up to hours and a few would never complete. The fact that most of them are less than 20 seconds is a huge step but it still sucks if you have to wait 10-15 seconds for everything. When we first rolled it out, the results were much better. That’s been one of our key learnings. If you read my post that introduced GVFS, you’ll see I talked about how we did work in Git and GVFS to change many operations from being proportional to the number of files in the repo to instead be proportional to the number of files “read”. It turns out that, over time, engineers crawl across the code base and touch more and more stuff leading to a problem we call “over hydration”. Basically, you end up with a bunch of files that were touched at some point but aren’t really used any longer and certainly never modified. This leads to a gradual degradation in performance. Individuals can “clean up” their enlistment but that’s a hassle and people don’t, so the system gets slower and slower.
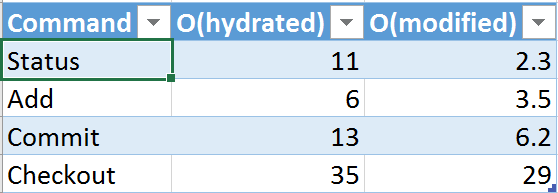
That led us to embark upon another round of performance improvements we call “O(modified)” which changes the proportionality of many key commands to instead be proportional to the number of files I’ve modified (meaning I have current, uncommitted edits on). We are rolling these changes out to the org over the next week so I don’t have broad statistical data on the results yet but we do have good results from some early pilot users.
I don’t have all the data but I’ve picked a few examples from the table above and copied the performance results into the column called “O(hydrated)”. I’ve added another column called O(modified) with the results for the same commands using the performance enhancements we are rolling out next week. All the numbers are in seconds. As you can see we are getting performance improvements across the board – some are small, some are ~2X and status is almost 5X faster. We’re very optimistic these improvements are going to move the needle on perf perception. I’m still not fully satisfied (I won’t be until Status is under 1 second), but it’s fantastic progress.
Another key performance area that I didn’t talk about in my last post is distributed teams. Windows has engineers scattered all over the globe – the US, Europe, the Middle East, India, China, etc. Pulling large amounts of data across very long distances, often over less than ideal bandwidth is a big problem. To tackle this problem, we invested in building a Git proxy solution for GVFS that allows us to cache Git data “at the edge”. We have also used proxies to offload very high volume traffic (like build servers) from the main Visual Studio Team Services service to avoid compromising end user’s experiences during peak loads. Overall, we have 20 Git proxies (which, BTW, we’ve just incorporated into the existing Team Foundation Server Proxy) scattered around the world.
To give you an idea of the effect, let me give an example. The Windows Team Services account is located in an Azure data center on the west coast of the US. Above you saw that the 80th percentile for Clone for a Windows engineer is 127 seconds. Since a high percentage of our Windows engineers are in Redmond, that number is dominated by them. We ran a test from our North Carolina office (which is both further away and has a much lower bandwidth network). A clone from North Carolina with no proxy server took almost 25 minutes. With a proxy configured and up to date, it took 70 seconds (faster than Redmond because the Redmond team doesn’t use a proxy and they have to go hundreds of miles over the internet to the Azure data center). 70 seconds vs almost 25 minutes is an almost 95% improvement. We see similar improvements when GVFS “faults in” files as they are accessed.
Overall Git with GVFS is completely usable at crazy large scale and the results are proving that our engineers are effective. At the same time, we have a lot of work to do to get the performance to the point that our engineers are “happy” with it. The O(modified) work rolling out next week will be a big step but we have months of additional performance work still on the backlog before we can say we’re done.
To learn more about the details of the technical challenges we’ve faced in scaling Git and getting good performance, check out the series of articles that Saeed Noursalehi is writing on scaling Git and GVFS. It’s fascinating to read.
Trying GVFS yourself
GVFS is an open source project and you are welcome to try it out. All you need to do is download and install it, create a Visual Studio Team Services account with a Git repo in it and you are ready to go. Since we initially published GVFS, we’ve made some good progress. Some of the key changes include:
- We’ve started doing regular updates to the published code base – moving towards “development in the open”. As of now, all our latest changes (including the new O(modified) work) are published to the public repo and we will be updating it regularly.
- When we first published, we were not ready to start taking external contributions. With this milestone today, we are now, officially ready to start. We feel like enough of the basic infrastructure is in place that people can start picking it up and moving it forward with us. We welcome anyone who wants to pitch in and help.
- GVFS relies on a Windows filesystem driver we call GVFlt. Until now, the drop of that driver that we made available was unsigned (because it was very much a work in progress). That clearly creates some friction in trying it out. Today, we released a signed version of GVFlt that will eliminate that friction (for instance, you no longer need to disable BitLocker to install it). Although we have a signed GVFlt driver, that’s not the long term delivery method. We expect this functionality to be incorporated into a future shipping version of Windows and we are still working through those details.
- Starting with our talk at Git Merge, we’ve begun engaging with the broader Git community on the problem of scaling Git and GVFS, in particular. We’ve had some great conversations with other large tech companies (like Google and Facebook) who have similar scaling challenges and we are sharing our experiences and approaches. We have also worked with several of the popular Git clients to make sure they work well with GVFS. These include:
- Atlassian SourceTree – SourceTree was the first tool to validate with GVFS and have already released an update with a few changes to make it work well.
- Tower – The Tower Git team is excited to add GVFS support and they are already working on include GVFS in the Windows version of their app. It will be available as a free update in the near future.
- Visual Studio – Of course, it would be good for our own Visual Studio Git integration to work well with GVFS too. We are including GVFS support in VS 2017.3 and the first preview with the necessary support will be available in early June.
- Git for Windows – As part of our effort to scale Git, we have also made a bunch of contributions to Git for Windows (the Git command line) and that includes support for GVFS. Right now, we still have a private fork of Git for Windows but, over time, we are working to get all of those changes contributed back to the mainline.
Summary
We’re continuing to push hard on scaling Git to large teams and code bases at Microsoft. A lot has happened in the 3 months since we first talked about the effort. We’ve…
- Successfully rolled it out to 3,500 Windows engineers
- Made some significant performance improvements and introduced Git proxies
- Updated the open source projects with the latest code and opened it for contributions
- Provided a signed GVFlt driver to make trying it out easier
- Worked with the community to begin to build support into popular tools – like SourceTree, Tower, Visual Studio, etc.
- Published some articles with more insights into the technical approach we are taking to scale Git and GVFS.
This is an exciting transition for Microsoft and a challenging project for my team and the Windows team. I’m elated at the progress we’ve made and humbled by the work that remains. If you too find there are times where you need to work with very large codebases and, yet you really you really want to move to Git, I encourage you to give GVFS a try. For now, Visual Studio Team Services is the only backend implementation that supports the GVFS protocol enhancements. We will add support in a future release of Team Foundation Server if we see enough interest and we have talked to other Git services who have some interest in adding support in the future.
Thanks and enjoy.
Brian
I could not find how to make it work on linux, so, that’s unfortunately not going to help any of my work.
thank you good post really like. agario pvp