
Introduction
In VS2013 (download here), we have introduced a new calling convention known as ‘Vector Calling Convention’ but before we go on and introduce the new calling convention let us take a look at the lay of the land today.
There are multiple calling conventions that exist today, especially on x86 platform. The x64 platform has however been slightly blessed with only one convention. The following calling conventions are supported by the Visual C/C++ compiler (_cdecl, _clrcall, _stdcall, _fastcall and others) on x86. _cdecl is the default calling convention for C/C++ programs on x86. However x64 just uses the _fastcall calling convention.
The types __m64, __m128 and __m256 define the SIMD data types that fit into the 64-bit mmx registers, the 128-bit xmm registers, and the 256-bit ymm registers, respectively. The Microsoft compiler has partial support for these types today.
Let us take a look at an example to understand what this (i.e. partial support) really means:
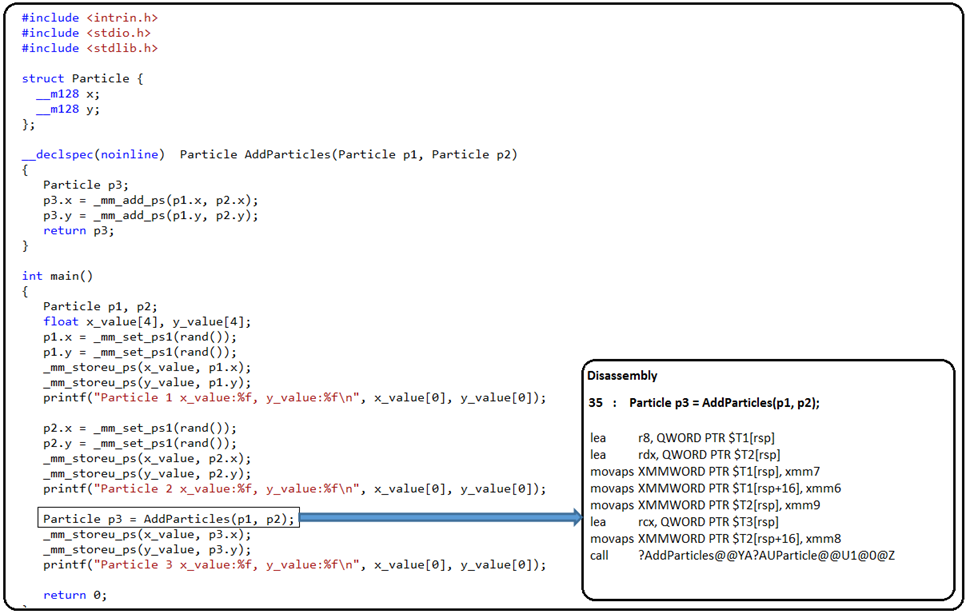 Figure 1: arguments are passed by reference implicitly on x64.
Figure 1: arguments are passed by reference implicitly on x64.
Today on AMD64 target, passed by value vector arguments (such as __m128/__m256/) must be turned into a passed by address of a temporary buffer (i.e. $T1, $T2, $T3 in the figure above) allocated in caller’s local stack as shown in the figure above. We have been receiving increasing concerns about this inefficiency in past years, especially from game, graphic, video/audio, and codec domains. A concrete example is MS XNA library in which passing vector arguments is a common pattern in many APIs of XNAMath library. The inefficiency will be intensified on upcoming AVX2/AVX-512 and future processors with wider vector registers.
On X86, the convention is a little more advanced in which first 3 passed by value vector arguments will be passed in XMM0:XMM2 register. However, 4th or beyond vector argument is not allowed and will cause C2719 error. Developers today are forced to manually turn it into passed by reference argument to get around the limitation on X86.
How to make use of Vector Calling Convention?
The new calling convention focuses on utilizing vector registers for passing vector type arguments. With Vector Calling Convention the design consideration was to avoid creating a totally different convention and be compatible with existing convention for integer and floating point arguments. This design consideration was further extended to avoid changing the stack layout or dealing with padding and alignment. Please note, the vector calling convention is only supported for native amd64/x86 targets and further it does not apply to MSIL (/clr) target.
The new calling convention can be triggered in the following two ways:
-
_vectorcall: Use the new _vectorcall keyword to control the calling convention of specific functions. For example, take a look in the figure 2 below:


Figure 2: ‘__vectorcall’ denotes the use of Vector Calling Convention
- The other way vector calling convention can be used is if the /Gv compiler switch is specified. Using the /Gv compiler option causes each function in the module to compile as vectorcall unless the function is declared with a conflicting attribute, or the name of the function is main.
In addition to SIMD data types, Vector Calling Convention can also be used for Homogeneous Vector Aggregate data-type (HVA) and Homogeneous Float Aggregate data-type (HFA). An HVA/HFA data-type is a composite type where all of fundamental data types of members that compose the type are the same and are of Vector or Floating Point data type. (__m128, __m256, float/double). An HVA/HFA data type can have at most four members. Some examples of what constitutes an HVA/HFA data type are listed below.
 Figure 3: HVA/HFA examples
Figure 3: HVA/HFA examples
For both architectures (x86 and amd64), HVA/HFA arguments will be passed by value in vector registers if the unallocated volatile vector registers (XMM0:XMM5/YMM0:YMM5) is sufficient to hold the entire aggregate set. They will be otherwise passed via reference the same way as the existing convention. The return value of type HVA/HFA is returned via XMM0(/YMM0): XMM3(/YMM3), one register per element.
Vector Calling Convention /Disasm
Now that we understand a little about what Vector Calling Convention is really about. Let us take look at the disassembly with the use of Vector Calling Convention in the figure given below.
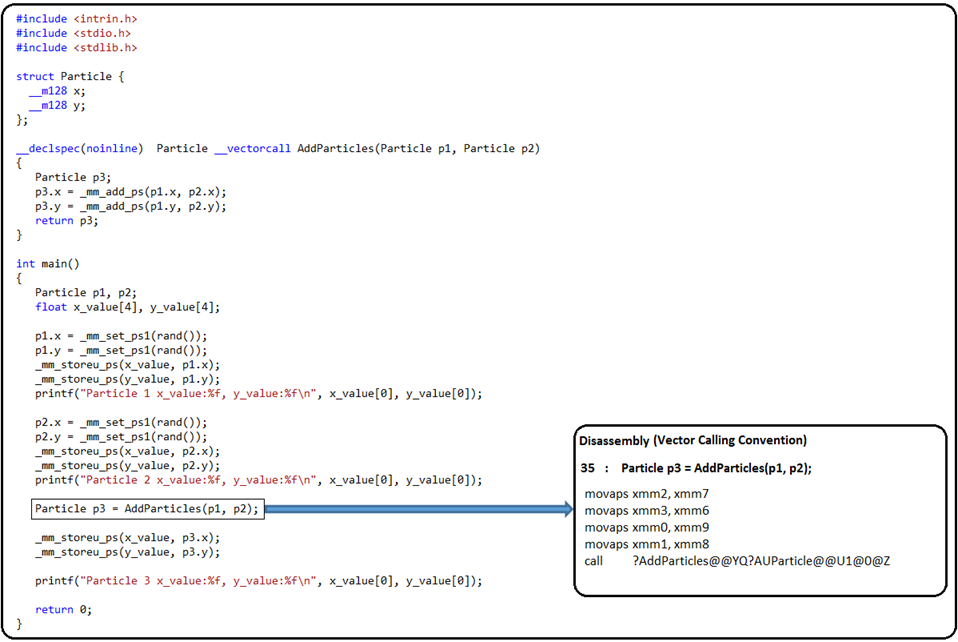
As you can see the ‘Disassembly’ generated as a result of using ‘Vector Calling Convention’ is simplified. The number of instructions with and without vector calling convention are displayed below.
 In addition to the number of instructions saved, there is also the stack allocation (96 bytes, allocation of $T1, $T2 and $T3) saved by using vector calling convention which adds to the general goodness resulting in performance gains.
In addition to the number of instructions saved, there is also the stack allocation (96 bytes, allocation of $T1, $T2 and $T3) saved by using vector calling convention which adds to the general goodness resulting in performance gains.
Wrap Up
This blog should provide you an introduction to what Vector Calling Convention is all about. As you can observe, there is a lot of goodness in using this convention if you perform a lot of vector calculations in your code especially on the x64 platform. One quick way for validating the performance gain by using Vector Calling Convention for vector code without changing the source code is by using the /Gv compiler switch. At this point you should have everything you need to get started! Additionally, if you would like us to blog about some other compiler technology please let us know we are always interested in learning from your feedback.
0 comments