
In Visual Studio 2019 version 16.2 we improved the codegen of several standard library functions. Guided by your feedback on Developer Community (Inlining std::lldiv and Improved codegen for std::fmin, std::fmax, std::round, std::trunc) we focused on the variants of standard division (std::div, std::ldiv, std::lldiv) and std::isnan.
Originally function calls to the standard library, rather than inline assembly instructions, were generated upon each invocation of variations of std::div and std::isnan, regardless of the compiler optimization flags passed. Since these standard library function definitions live inside of the runtime, their definitions are opaque to the compiler and therefore not candidates for inlining and optimization. Furthermore, the function overhead of calling both std::div and std::isnan is greater than the actual cost of these operations. On most platforms, std::div can be computed in a single instruction that returns both quotient and remainder while std::isnan requires only a comparison and condition flag check. Inlining these calls would remove both function call overhead and allow optimizations to kick in since the compiler has the additional context of the calling function.
To support inline assembly code generation we added a number of different functions as compiler intrinsics (also known as builtins) for std::isnan, std::div, and friends. Registering an intrinsic effectively “teaches” the meaning of that function to the compiler and results in greater control over the code generated. We went with a codegen solution rather than a library change to avoid altering library headers.
Optimizing std::div and Friends
The MSVC compiler has pre-existing support for optimizing bare division and remainder operations. Therefore, to feed calls to std::div into this existing compiler infrastructure, we recognize std::div as a compiler intrinsic and then transform the inputs of our recognized call into the canonical format the compiler is expecting for division and remainder operations.
Optimizing std::isnan
Replacing calls to std::isnan was the more complicated of the two categories of functions we targeted due to the conflicting requirements of the C and C++ standards. According to the C standard, isnan and the function it wraps, fpclassify, are required to be implemented as macros, while C++ requires both operations to be implemented as function overloads. Below is a diagram of the call structure in C++ vs C, with functions that are required to be implemented as function overloads inside bolded blue boxes, functions that are required to be implemented as macros in dashed purple boxes, and those without a requirement in green.
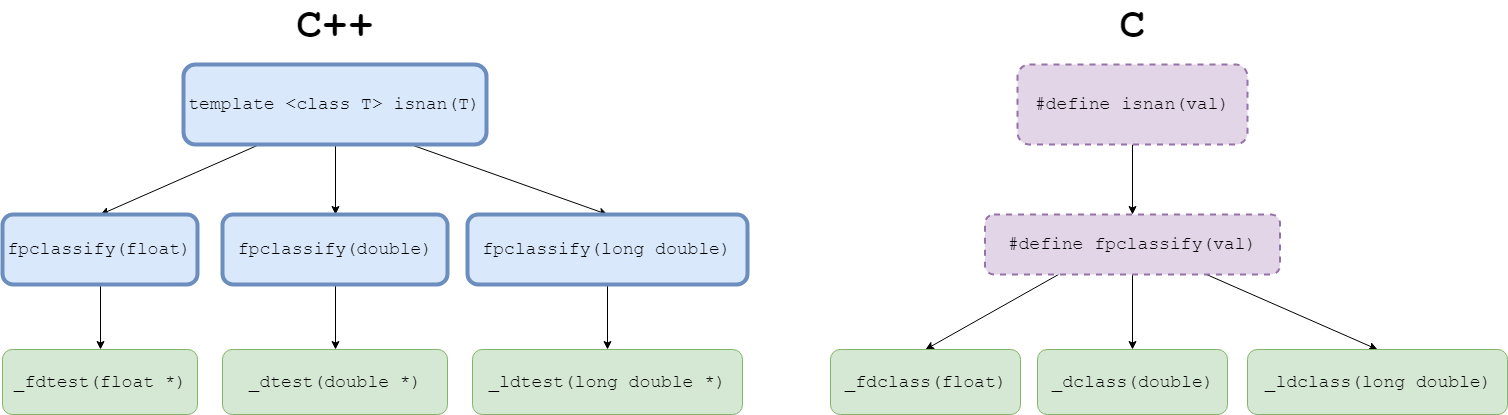
To get a unified solution for C and C++ code, we had to bypass both std::isnan and std::fpclassify to look at the functions std::fpclassify wraps. We chose the green functions to register as compiler intrinsics since they lack any implementation requirements. Additionally, since each overload in either standard accomplishes the same task, we can transform instances of one standard’s intrinsics (we chose the C++ standard) into instances of our added C intrinsics. The table below demonstrates the results of the unification process that reduces the intrinsics we operate on after the initial pass from six to three.
| Function | Intrinsic function | Intrinsic After Unification |
_fdtest |
IV__FDTEST |
IV__FDCLASS |
_dtest |
IV__DTEST |
IV__DCLASS |
_ldtest |
IV__LDTEST |
IV__LDCLASS |
_fdclass |
IV__FDCLASS |
IV__FDCLASS |
_dclass |
IV__DCLASS |
IV__DCLASS |
_ldclass |
IV__LDCLASS |
IV__LDCLASS |
Back to std::isnan. The reasoning behind adding six new compiler intrinsics was to improve the code generation for std::isnan. However, referencing the diagram from before, while we’ve transformed the functions that std::fpclassify calls into, that hasn’t actually changed any of the codegen for std::isnan. In the _dclass case for example, we’ve recognized all _dclass calls as intrinsics, but as we’re not changing the code generated for _dclass, the code emitted is still the same call to _dclass that we started out with.
The last step required to recognize std::isnan as an intrinsic and therefore enable more efficient code generation involves pattern matching. Checking if a float/double/etc. is a NaN looks something like this:
isnan(double x) {
return FP_NAN == IV__DCLASS(x);
}
Where FP_NAN is a constant defined in both C and C++ standards. Now that it’s easy to identify calls to _dclass and friends, the optimizer was extended to recognize the above pattern (a call to one of the three unified intrinsics followed by a comparison to the FP_NAN constant) and transform it into the new std::isnan intrinsic, IV_ISNAN.
Results
To better illustrate the codegen differences, below are samples of the different x64 code generation for both std::isnan and std::div.
std::isnan(double)
| Reference | With Intrinsics |
lea rcx, QWORD PTR _X$[rsp]
|
ucomisd xmm0, xmm0
|
std::div(long, long)
| Reference | With Intrinsics |
mov edx, ebx
|
mov eax, esi
|
How much does effectively inlining these calls impact performance? When benchmarked by calling each operation on every member of a 1×109 element array with unknown inputs, the following improvements can be observed:
| std::isnan(double) | Reference | With Intrinsics | % Improvement |
| Avg (s) | 4.03 | 1.25 | 69% |
| Std Dev (s) | 0.05 | 0.04 |
| std::div(long, long) | Reference | With Intrinsics | % Improvement |
| Avg (s) | 6.52 | 6.06 | 7% |
| Std Dev (s) | 0.11 | 0.04 |
You can view the benchmark source here on Compiler Explorer. Each benchmark was run six times on an Intel Xeon CPU v3 @3.50GHz, with the first warm-up run thrown out.
Conclusion
The aforementioned optimizations will be enabled transparently with an upgrade to the 16.3 toolset in codebases compiled under /O2. Otherwise, make sure you’re explicitly using /Oi to enable intrinsic support.
The C++ team is already looking ahead at improving the performance of standard library functions in future releases, with a similar optimization for std::fma targeting the 16.4 release. As always, we welcome your feedback and feature requests for further codegen improvements. If you see cases of inefficient code generation, please reach out via the comments below or by opening an issue on Developer Community.
Isn’t there a typo in the benchmark for std::isnan? 4.03 compared to 1.25 is not 69%.
(4.03 – 1.25) / 4.03 * 100% = 68.98 %
Yes, of course, but I thought the general understanding of “faster in %” in computer benchmarking is that it is just another expression for the speed up factor. The speed up factor is (value slow / value fast) for a measuring unit where values decrease with higher execution speed (for instance, seconds or CPU ticks). This factor expressed in percentage is (factor – 1) * 100%. In this case it is 4.03/1.25 = 3.224 = 222.4%. In general, I would expect that to “double the speed” is equivalent to “make it 100% faster”. Is this wrong?
Using std::isnan with VS2019 16.2, an x64 /O2 build shows significant performance improvement of about 69% on my machine when compared with VS2017 16.9.14, confirming the performance improvement advertised above. I like this very much.
Though, I did observe a smaller performance improvement for _isnanf in VS2019 16.2, std::isnan is significantly more performant that _isnanf (I expected them to be more similar). Perhaps this is still a work in progress, because in the conclusion it states that optimizations are available in the 16.3. toolset, not 16.2.
https://stackoverflow.com/questions/26052640/why-does-gcc-implement-isnan-more-efficiently-for-c-cmath-than-c-math-h
from 2014, just about 5 years ago, talks about this very thing.