

Over the years, customers have asked us for help in designing applications around specific scenarios they were trying to achieve. In some cases, these centered around implementing certain patterns using a JSON-based NoSQL database. Some of these patterns are very common in the NoSQL world, but not well understood by those new to NoSQL databases. Other patterns were very specific to the Cosmos DB service itself in demonstrating how to leverage specific capabilities to solve difficult architectural challenges.

We’ve been capturing these patterns and sharing them with customers individually. We felt now was a good time to publish some of these more broadly to make more discoverable by users. The result is Azure Cosmos DB Design Patterns. A repository on GitHub that includes a wide variety of samples that show how to implement specific patterns that will allow you to solve design-related challenges when using Azure Cosmos DB for your solutions.
To help share these, we’ve created a blog post series on each of them. Each post will focus on a specific design pattern with a corresponding sample application that’s featured in this repository. We hope you enjoy and find this series useful.
Here’s a list of the previous posts in this series:
Azure Cosmos DB design pattern: Distributed Counter

This post delves into the Distributed Counter design pattern. The Distributed Counter NoSQL design pattern is a strategy used to manage counters in distributed database systems, particularly in NoSQL databases where traditional atomic operations might not scale well in high-traffic scenarios. This pattern is useful when you need to count events, like page views or likes, at a scale where a single database entry can’t handle the load due to frequent read and write operations. Here’s a breakdown of its key aspects:
- Distributed Counting: Instead of relying on a single counter, the pattern distributes the counter’s value across multiple records or documents in the database. This distribution reduces the load on any single entry, thereby enhancing performance and scalability.
- Sharding or Partitioning: The counter is divided (or sharded) into several smaller counters. These shards can be distributed across different nodes or databases. Each shard can be updated independently, which allows for concurrent updates without causing a bottleneck at a single point.
- Aggregation: To get the total count, the system sums up the values from all the shards. This aggregation can be done on-demand or periodically, depending on the system’s requirements and the acceptable staleness of the data.
- Conflict Resolution: In distributed systems, especially with eventual consistency models, updates to different shards might lead to conflicts. The pattern includes mechanisms to handle these conflicts, ensuring that the final count remains accurate. This might involve techniques like versioning or using timestamps.
- Load Balancing: The pattern often includes strategies to evenly distribute traffic and updates across all shards. This can be achieved through random allocation or more sophisticated load-balancing techniques, depending on the application’s requirements.
- Partial Updates: In some implementations, partial updates (like HTTP PATCH) are used to modify a specific shard without the need to read and write the entire document, enhancing efficiency.
- Atomic Transactions: Ensuring that updates to a shard are atomic is crucial to prevent data corruption or inaccuracies. Each increment or decrement operation must be complete and isolated.
- Scalability and Performance Optimization: The primary goal of this pattern is to optimize for high throughput and scalability. By distributing the counter, the system can handle a much larger number of updates than a single counter could.
The Scenario:
Think of the distributed counter like a team of cashiers in a busy store. Instead of one cashier handling all customers, leading to long lines, you have several cashiers spread out, each serving a few customers swiftly. In the world of databases, the distributed counter does something similar. It spreads out the task of counting – like tracking inventory on an e-commerce site or likes on a social media post – across multiple points, preventing any one point from getting overwhelmed. This means faster updates and accurate, real-time numbers, all without causing a virtual traffic jam. It’s a smart, efficient way to keep things running smoothly, especially when a lot is happening at once.
Imagine an e-commerce platform experiencing heavy traffic, where it’s crucial to maintain an up-to-date inventory of a popular item for both customers and backend systems. In such a setting with high parallel user activity, constantly modifying a single data record for inventory leads to substantial data access conflicts.
The usual method of addressing these conflicts is through optimistic concurrency control. However, this approach might result in occasional inaccuracies in reflecting the most current inventory status. It is vital for the system to enable swift updates to the inventory count while ensuring that the displayed count is extremely precise and reflects real-time changes.
Sample Implementation:
In a distributed counter solution, a group of distributed counter items are used to keep track of the number. By having the solution distribute the counter across multiple items, update operations can be performed on a random item without causing contention. Even more, the solution can calculate the total of all counters at any time using an aggregation of the values from each individual counter.
This implementation showcases a C#/.NET application divided into three projects:
Counter Class Library:
This is the core of the application, implementing a distributed counter pattern through two services. The first service, DistributedCounterManagementService, manages the counter and handles the tasks of splitting or merging as required. The second service, DistributedCounterOperationalService, is responsible for updating counters in high-traffic situations. It selects a random counter for updates using partial document updates (HTTP PATCH), ensuring that transactions are atomic and free from conflicts.
Visualizer Web Application:
This component is a Blazor web application that serves as the user interface for the counters. It features real-time graphical charts that demonstrate the performance of the counters. The application regularly polls data from the DistributedCounterManagementService to visualize this data in the charts.
Consumers Console Application:
This component simulates a high-traffic environment to test the distributed counters. It creates multiple concurrent threads, each rapidly updating the distributed counters. This simulation uses the DistributedCounterOperationalService for making the updates, thereby testing the system’s capability to handle high loads and frequent updates.
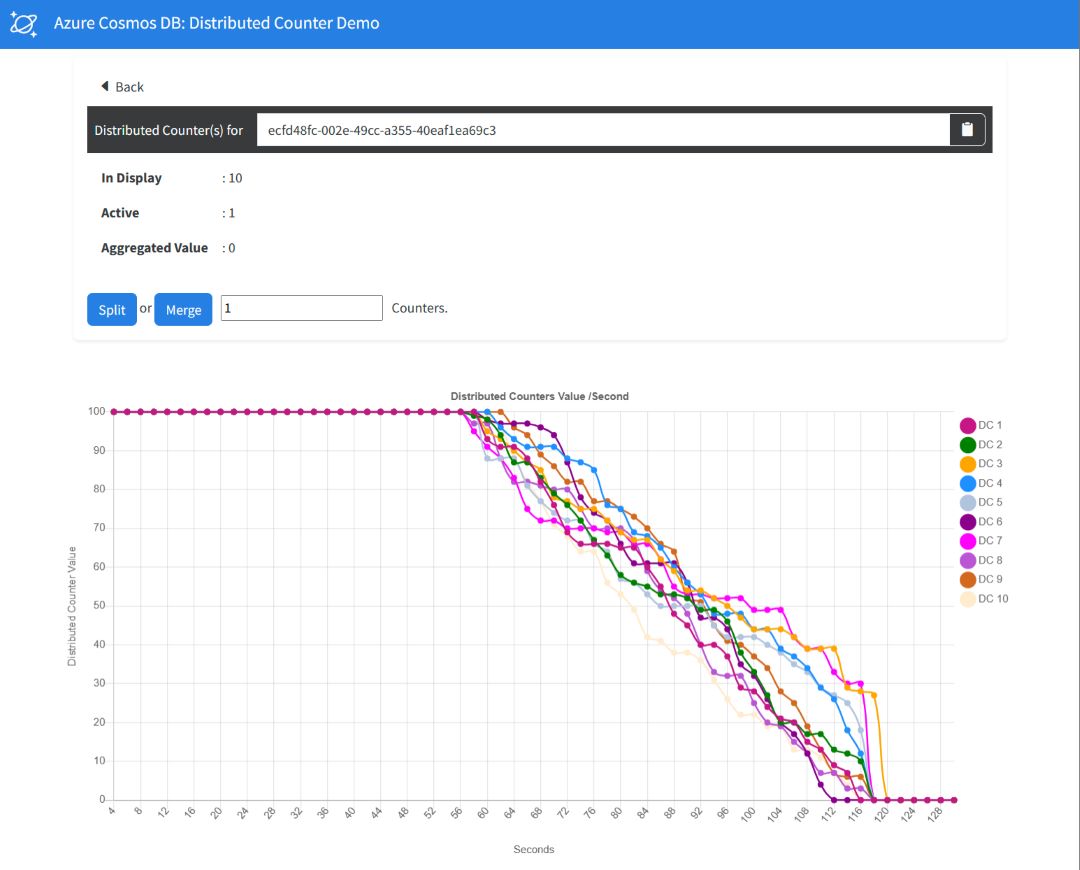
The sample implementation of the distributed counter design pattern using a C#/.NET application is an effective solution for the challenges faced by an e-commerce platform in high-traffic scenarios. The Counter class library efficiently manages the distributed counters, ensuring that updates are atomic and conflict-free, a crucial aspect in maintaining real-time, accurate inventory counts. The Visualizer web application provides a real-time graphical view of the counter performance, aiding in quick decision-making and monitoring. Lastly, the Consumers console application, by simulating a high-traffic environment, validates the robustness and scalability of the solution under demanding conditions, ensuring that the platform can maintain precise inventory counts even during peak traffic periods. This implementation not only enhances performance but also optimizes resource utilization, making it an ideal solution for the described scenario.
Why It Matters:
Here’s a brief breakdown of why the distributed counter data access pattern matters:
- Scalability: It allows for scaling across multiple nodes, handling high traffic efficiently.
- Performance Enhancement: Reduces bottlenecks by distributing the count operation, leading to faster response times.
- Conflict Avoidance: Minimizes data conflicts in a distributed database environment, crucial for accuracy and consistency.
- Real-Time Updates: Facilitates real-time data updates, essential for applications requiring up-to-the-millisecond accuracy.
- Resource Optimization: Balances the load across multiple counters, optimizing resource utilization.
- Flexibility: Adaptable to various scenarios, such as e-commerce inventory tracking or social media interactions.
The Distributed Counter design pattern is essential for managing numeric data in NoSQL databases, especially in distributed systems. It is great for keeping accurate and scalable counts across different nodes, ensuring consistency and high availability. This pattern uses atomic operations and optimized data structures to minimize conflicts and improve update speeds. It’s particularly useful for dynamic, high-velocity data like social media or system metrics, making it a key tool for developers in handling counts in modern, distributed applications.
Getting Started with Azure Cosmos DB Design Patterns
You take a look at the sample code by visiting the distributed counter example on GitHub. You can also try this out for yourself by visiting the Azure Cosmos DB Design Patterns GitHub repo and cloning or forking it. Then run locally or from Code Spaces in GitHub. If you are new to Azure Cosmos DB, we got you covered with a free Azure Cosmos DB account for 30 days, no credit card required. If you want more time, you can extend the free period. You can even upgrade too.
Sign up for your free Azure Cosmos DB account at aka.ms/trycosmosdb.
About Azure Cosmos DB
Azure Cosmos DB is a fully managed and serverless distributed database for modern app development, with SLA-backed speed and availability, automatic and instant scalability, and support for open-source PostgreSQL, MongoDB, and Apache Cassandra. Try Azure Cosmos DB for free here. To stay in the loop on Azure Cosmos DB updates, follow us on Twitter, YouTube, and LinkedIn.
0 comments