
Yesterday, we completed our sprint 60 deployment. With it comes two new features: Exporting test plans as HTML documents and a permission to control who can create new work item tags. You can read more about the new features on the service release notes here: http://www.visualstudio.com/news/2014-feb-10-vso.
As you may know, since ~Oct, we’ve had a run of “bad” deployments that caused unacceptable down time. Due to this we made a number of changes. One was to move our deployments to weekends to reduce the number of people that any unexpected interruptions affect. This was the second deployment to happen over a weekend and thankfully went very smoothly. Sprint 59’s weekend deployment did not go well though and we had a good number of people working all day Saturday and Sunday to get the service back to health. While the weekend deployment had the desired effect – it reduced the impact on customers, it confirmed for us the heavy toll it takes on the team.
In fact, we moved sprint 60’s deployment to this weekend (it was supposed to be last weekend) because we didn’t want to risk having to ask the team to miss the Super Bowl (which, I might add, the Seattle Seahawks dominated). Thankfully this one went smoothly and the number of people who had to work the weekend was comparatively small. However, it’s clear weekend deployments aren’t really going to be sustainable – in the sense of keeping a talented group of people willing to work 7 days a week. Next sprint we are going to try doing the deployment on a weekday evening. I ‘m well aware that no time is a good time for an outage. In fact, I even got some customer emails when 59’s weekend deployment experienced issues, but there are less bad times than others. For context, here’s a graph of activity on our service, starting from Sun morning.
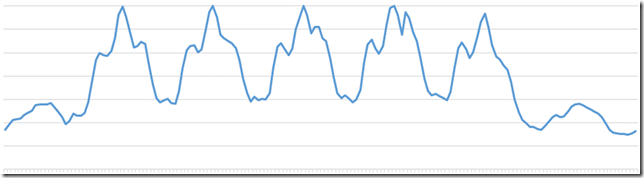
In the end, the most important this is getting to the point where every deployment is a “non-event” (meaning no one even notices it happens because it is so seamless) – both for our customers and our employees. Time shifting the deployment isn’t a fix, it’s a mitigation and while it’s a wise precaution to take, the effect on the team is profound enough that we have to be very careful how much we rely on it.
In that light, we have done a lot of technical work in the past few months to “get back on top” of deployments. It became clear that the scale of the service had outgrown the engineering processes and resiliency we had built in and it was time to do more. Among other things we…
- Doubled down on root cause analysis and post-deployment retrospectives
- Fed all engineering process learning (both from deployment retrospectives and elsewhere) into an engineering system backlog in order to concretely track progress and to help prioritize. From there we farmed work out into feature team backlogs.
- Made significant changes to our pre-deployment testing and scale validation to make it “more like production”. While it will never be fully like production, it is helping catch more issues than before.
- Accelerated work to enable multiple instances for VS Online. In fact, you don’t know it, but we deployed the first “additional instance” a couple of weeks ago. Ultimately, this will allow us to run fractions of our production load on independent clusters that can be upgraded separately. This way we will not have to subject the entire customer base to the upgrade at the same time. The instance we set up a couple of weeks ago, we have affectionately called “ring 0” or (Scale Unit 0 – SU0) and it will be where all production deployments happen first. SU0 is in the Azure San Antonio data center and SU1 (the instance we’ve been using for a few years) is in the Azure Chicago data center. Ring 0 will be an instance where we only put accounts who “volunteer” for the risk of additional volatility – mine will be there
 . Once deployments are validated on ring 0, they will incrementally roll out across other instances. Eventually we will add the ability for you to choose which instance your account is on and this will give you the ability to locate your account in your region.
. Once deployments are validated on ring 0, they will incrementally roll out across other instances. Eventually we will add the ability for you to choose which instance your account is on and this will give you the ability to locate your account in your region. - Worked to further decouple services to enable more independent deployment of individual services (TFS, Build, Cloud load, analytics, etc). There’s more work to do here but we are making progress.
- Implemented a new “lock manager” to better enforce some global service policies/best practices that we saw often being validated based on our root cause analysis. I hope to write a whole post on this one at some point and maybe even share the code.
- And much more…
I’d like to think that the smooth deployment this weekend was a reflection of the work we’ve been doing but I’d like to see 3 or 4 smooth ones in a row before I’m willing to give too much credit. We’ll continue to work hard on it. I don’t expect to be at a new “plateau” of service stability and excellent for another few months but we’re definitely on the ascent.
Thanks for your patience and understanding as we continue to work to produce the best developer services on the planet. As always, if you see things we can do better, please let us know.
Brian
0 comments
Be the first to start the discussion.