

Latest update – 06 November 2024
Vector Support is now available as Public Preview! Read the announcement here: Public Preview of Native Vector Support in Azure SQL Database! Access to full documentation here: Vector functions.
Vectors and Embeddings
Vector databases are gaining quite a lot of interest lately. Using text embeddings and vector operations makes extremely easy to find similar “things”. Things can be articles, photos, products…everything. As one can easily imagine, this ability is great to easily implement suggestions in applications. From providing suggestions on similar articles or other products that may be of interest, to quickly finding and grouping similar items, the applications are many.
A great article to understand how embeddings work, is the following: Introducing text and code embeddings.
Reading the mentioned articles, you can learn that “embeddings are numerical representations of concepts converted to number sequences, which make it easy for computers to understand the relationships between those concepts.”

More specifically, embeddings are vectors…hence the great interest for vector databases.
But are vector databases really needed? At the end of the day a vector is just a list of numbers and finding if two vectors represent similar object is as easy as calculating the distance between the vectors. One of the most common and useful distance metric is the cosine distance and, even better, the related cosine similarity
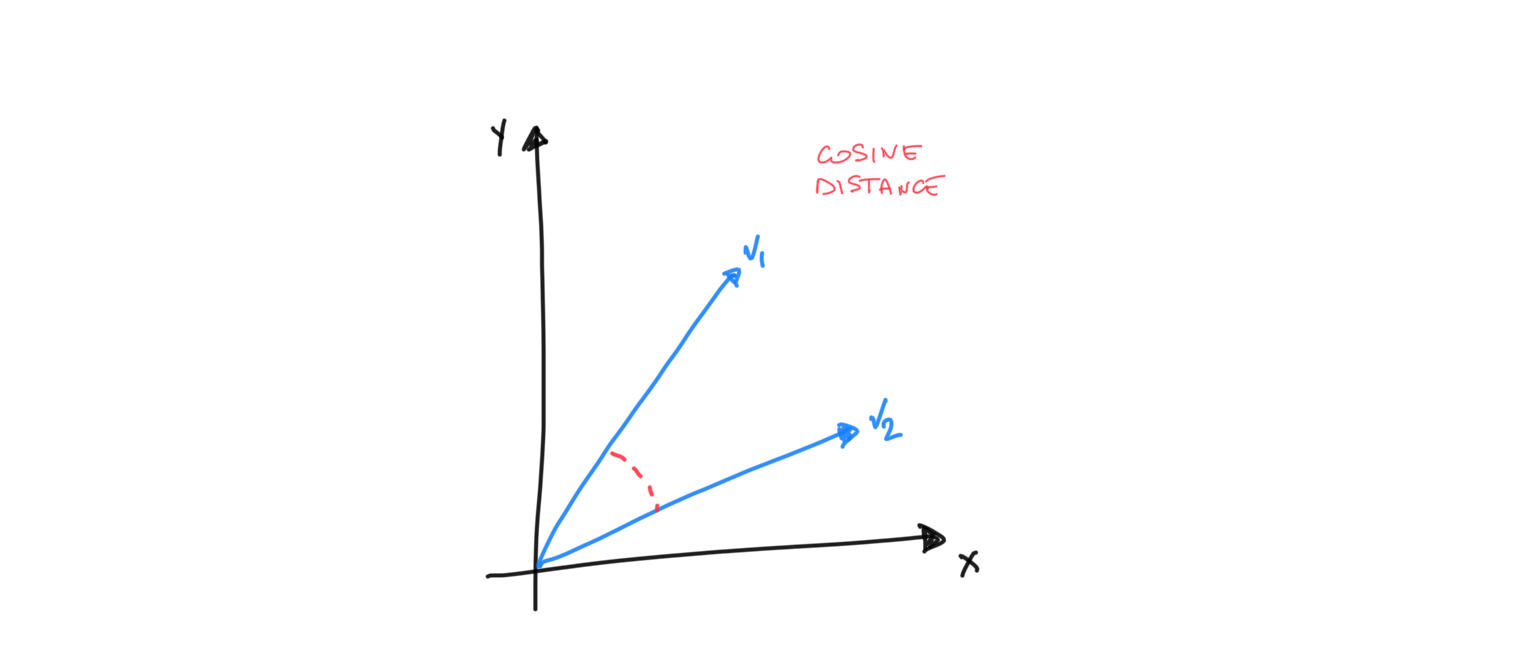
The real complex part is calculating the embeddings, but thanks to Azure OpenAI, everyone has an easily accessible REST service that can used to get the embeddings using pre-trained ML models. In this article we will use OpenAI to generate vectors for doing similarity search and then use Azure SQL database to store and search for similar vectors.
In this article we’ll build a sample solution to find Wikipedia articles that are related to any topic we may be interested in. As usual all the code is available in GitHub:
https://github.com/Azure-Samples/azure-sql-db-openai
The pre-calculated embeddings, both for the title and the body, of a selection of Wikipedia articles, is made available by OpenAI here:
https://cdn.openai.com/API/examples/data/vector_database_wikipedia_articles_embedded.zip
Vectors in Azure SQL database
Vectors can be efficiently stored in Azure SQL database by columnstore indexes. There is no specific data type available to store a vector in Azure SQL database, but we can use some human ingenuity to realize that a vector is just a list of numbers. As a result, we can store a vector in a table very easily by creating a column to contain vector data. One row per vector element. We can then use a columnstore index to efficiently store and search for vectors.
Using this Wikipedia article as starting point, you can see that there are two vectors, one to store title embeddings and one to store article embeddings:

The vectors can be more efficiently stored into a table like this:
CREATE TABLE [dbo].[wikipedia_articles_embeddings_titles_vector]
(
[article_id] [int] NOT NULL,
[vector_value_id] [int] NOT NULL,
[vector_value] [float] NOT NULL
)
GOOn that table we can create a column store index to efficiently store and search for vectors. Then it is just a matter of calculating the distance between vectors to find the closest. Thanks to the internal optimization of the columnstore (that uses SIMD AVX-512 instructions to speed up vector operations) the distance calculation is extremely fast.
The most common distance is the cosine similarity, which can be calculated quite easily in SQL.
Calculating cosine similarity
Cosine similarity can be calculated in SQL using the following formula, given two vectors a and b:
SELECT
SUM(a.value * b.value) / (
SQRT(SUM(a.value * a.value)) * SQRT(SUM(b.value * b.value))
) AS cosine_similarity
FROM
vectors_valuesReally easy. What is now left to do is to query the Azure OpenAI REST service so that, given any text, we can get the vector representation of that text. Then we can use that vector to calculate the cosine distance against all the wikipedia articles stored in the database and take only the closest ones which will return the article most likely connect to the topic we are interested in.
Querying OpenAI
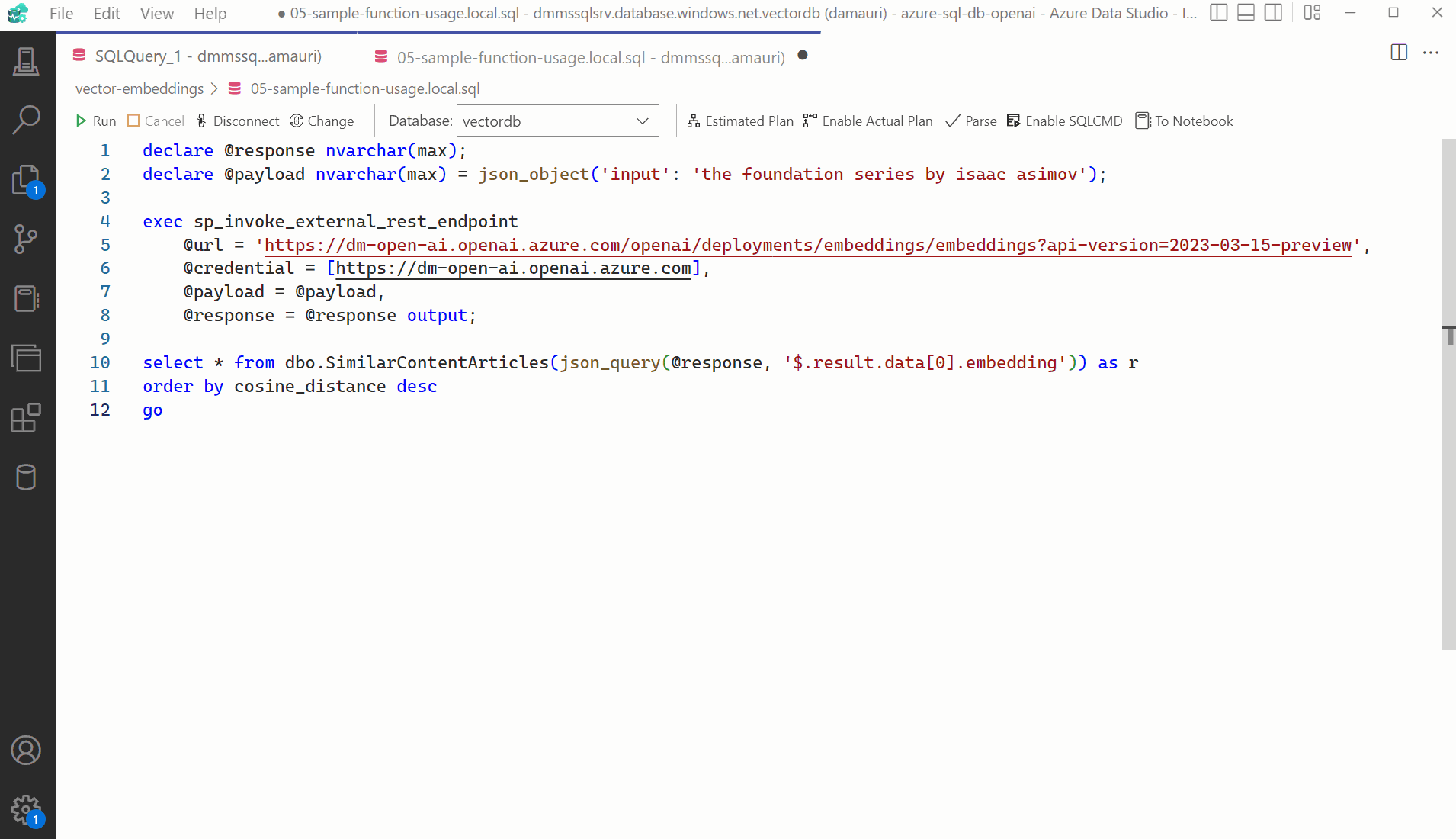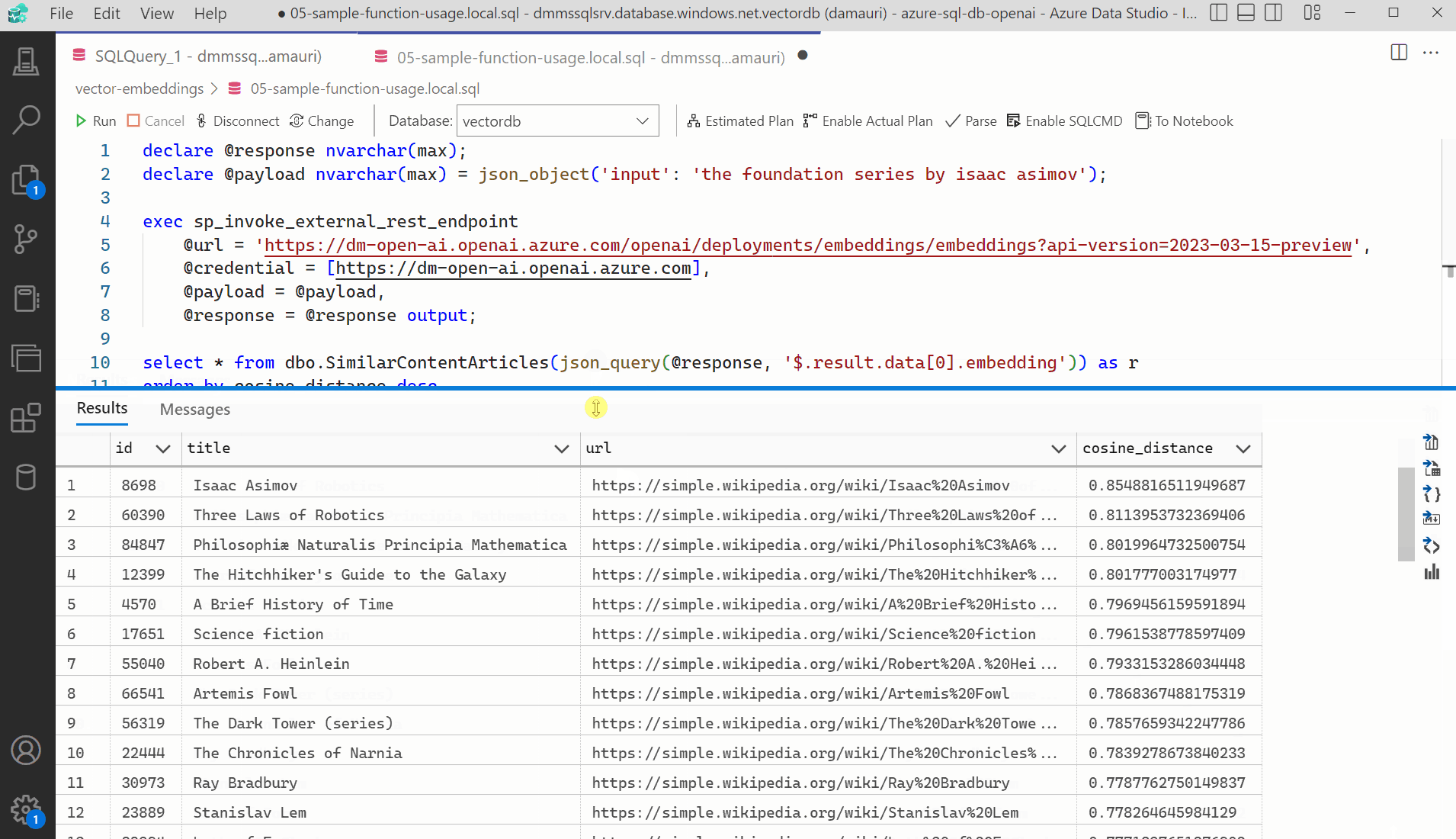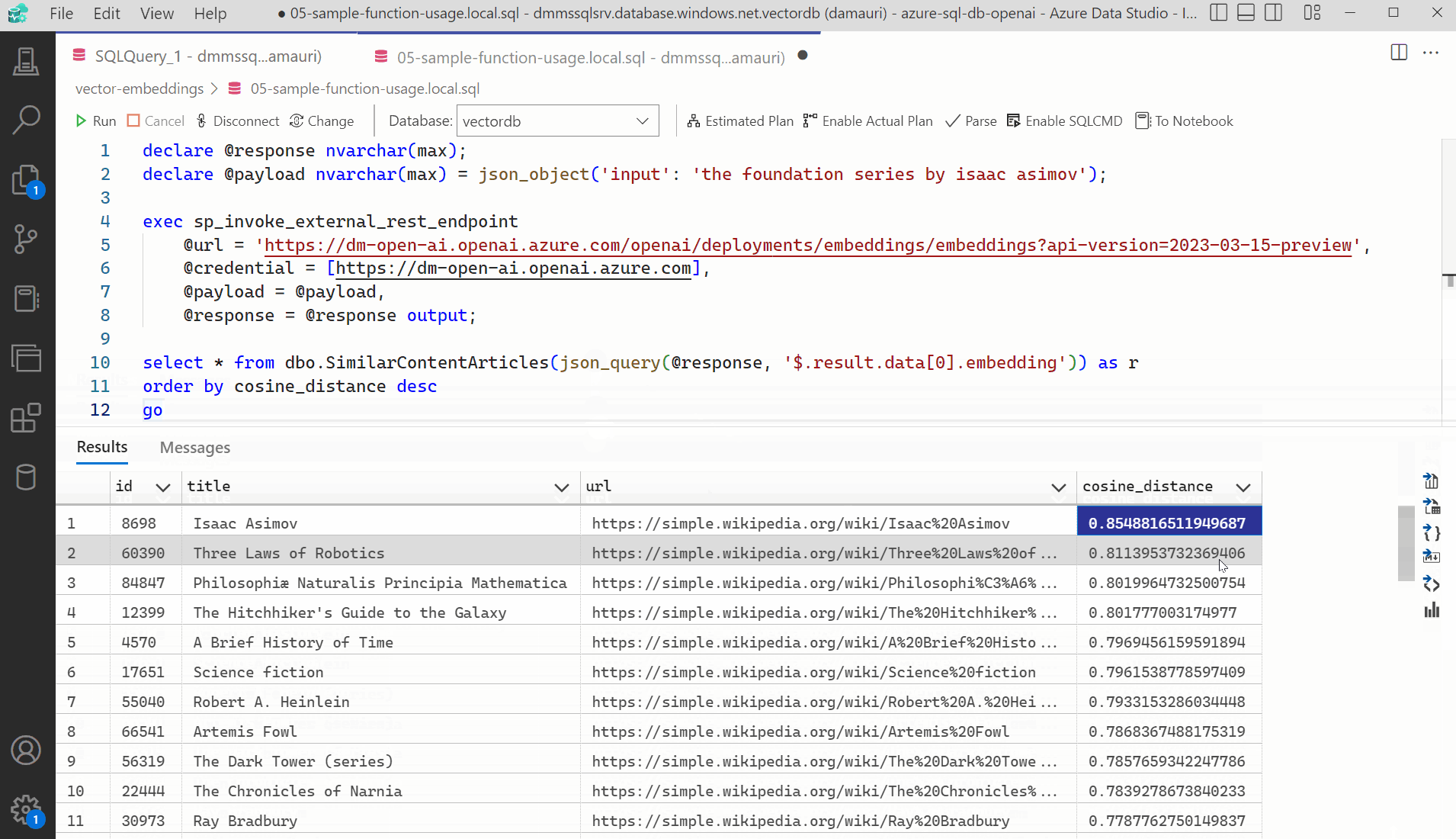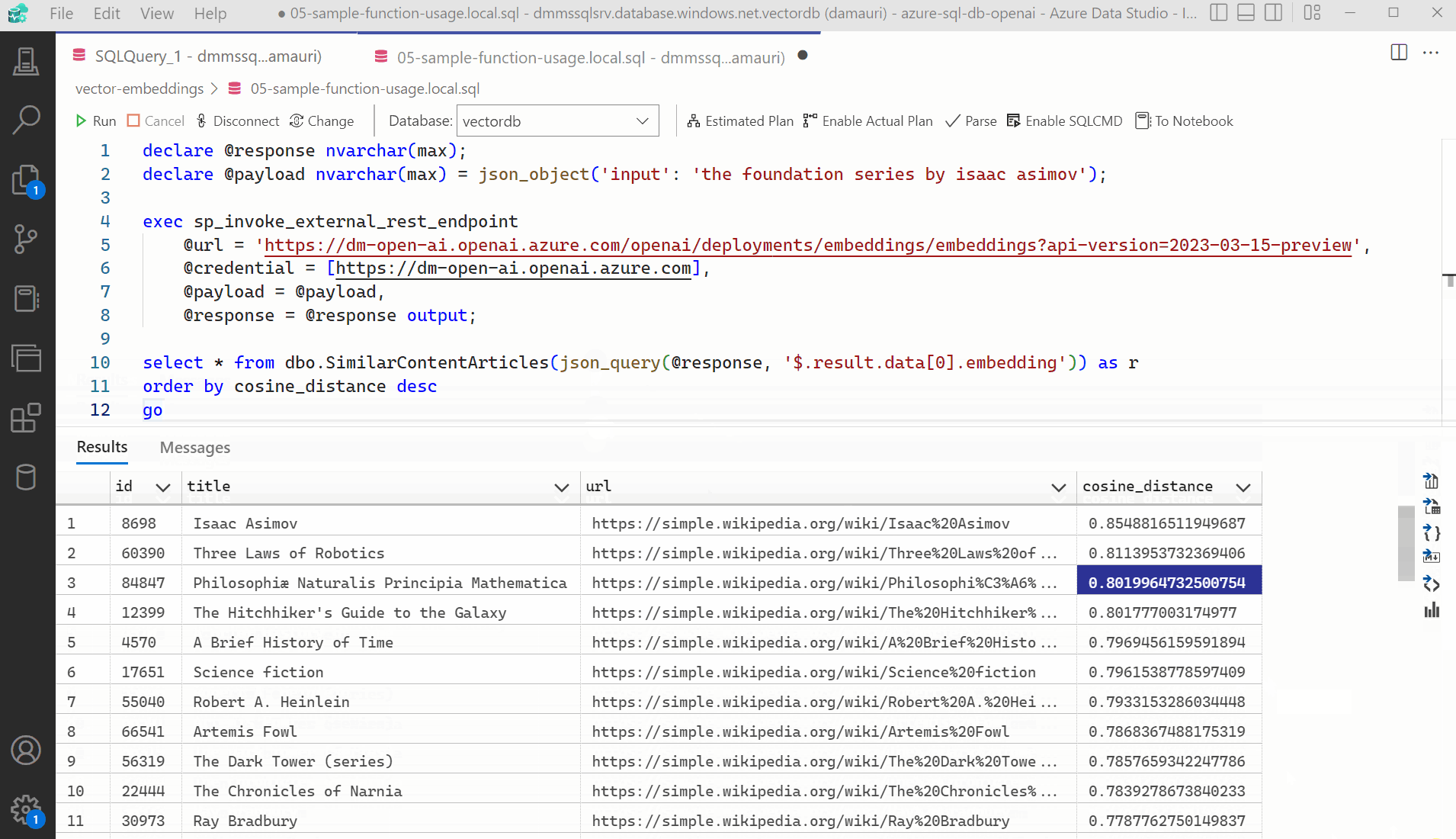
Create an Azure OpenAI resource via the Azure portal. For this specific sample you have to deploy an Embedding model using the text-embedding-ada-002 model, the same used for the Wikipedia articles source we are using in this sample. Once that is done, you need to get the API KEY and the URL of the deployed model (read the Embeddings REST API documentation) and then you can use sp_invoke_external_rest_endpoint to call the REST API from Azure SQL database.
declare @retval int, @response nvarchar(max);
declare @payload nvarchar(max) = json_object('input': 'Isaac Asimov');
exec @retval = sp_invoke_external_rest_endpoint
@url = 'https://<your-app-name>.openai.azure.com/openai/deployments/<deployment-id>/embeddings?api-version=2023-03-15-preview',
@method = 'POST',
@headers = '{"api-key":"<your api key>"}',
@payload = @payload,
@response = @response output;The response is a vector of 1536 elements in JSON format. Vector values can be easily extracted using the following T-SQL code:
select [key] as value_id, [value] from openjson(@response, '$.result.data[0].embedding')Source code
If you are interested in trying this amazing capability by yourself, you can find the source code here:
https://github.com/Azure-Samples/azure-sql-db-openai
Conclusion
The provided sample is not optimized. For example, the square of the vectors: SUM(a.value * a.value) could be pre-calculated and stored in a table for even better efficiency and performance. The sample is purposely simple to make it easier to understand the concept. Even if the sample is also not optimized for performance, it is still quite fast. On an eight vCore Azure SQL database, the query takes only half of a second to return the fifty most similar articles. The cosine distance is calculated on 25,000 articles, for a total of 38 million vector values. Pretty cool, fast and useful!
This is great stuff. While SQL Server may not be optimized for vector embeddings, I do think it has some advantages:
1) SQL Server has been around for 25+ years, it is GA unlike these very new vector databases and provides a ton of additional features - IDE, security
2) You are probably already using SQL Server or some form of SQL queries...extend this out to your existing infrastructure
3) Using relational features mixed with vectors allows you to do things like add security or state easily (which you probably already have)
4) As with the columnstore index optimization, Microsoft...
Very interesting post.
When i look to the explain plan we can see that SQL Server use all the data 38M rows and aggregate them before filtering. With such a small volume of data (2500 articles x 1536 vector size) it is easily manageable even for my laptop. But if the data scale (let's say 1M article x 1536 vs = 1.5B rows in the embeddings content it we be hard to manage many queries coming from many clients.
There is a lack of specialized vector index to reduce the impact in sql server. And I hope we will see such indexes...
This is incredible. I was able to implement this code and it runs fast even on a local Azure SQL Dev database.