

“DevOps” is a broad term which encompasses various disciplines like CI / CD, testing, monitoring and more. Donavan Brown’s classic post states: “DevOps is the union of people, process, and products to enable continuous delivery of value to our end users… You cannot buy DevOps and install it. DevOps is not just automation or infrastructure as code. DevOps is people following a process enabled by products to deliver value to our end users”. In this post, we take a non-opinionated look at what DevOps for Azure SQL looks like, by reviewing common concepts and providing some options for implementing DevOps for Azure SQL.
Personas
If you consider DevOps in a typical organization, several personas emerge:
- Security and Compliance – typically responsible to define security controls and patterns
- Central IT – responsible for defining environments (dev / pre-prod / prod) and acceptable infrastructure patterns (including networking)
- Operations – manages pipelines and software releases
- Development – implements line-of-business applications
All these personas have a role to play when it comes to DevOps for Azure SQL. For example, what we classically refer to as “DBA” or “Data Engineering” roles tend to span the Operations and Development personas mentioned above. In the sections below, you will see correlations of technology and process to these personas.
Database Lifecycle
Let’s quickly consider the lifecycle of a database:
- A database is created as a collection of schema objects (tables, views, indexes etc.) and programmability objects like stored procedures, functions etc.) It is possible to represent all of these as code which can then be version controlled and subjected to “operations” conceptually like any other application code
- In the past, it was common for database development to be done in a “connected” fashion where database management tools would be used to create database objects. The database itself would serve as the system of truth
- Over time, the availability of database design tools and / or object-relational mapping libraries have caused most of the database development to happen inside a development environment of some sort. Accompanying this has been the tighter integration of database development practices with “traditional” app dev practices – source control, automated testing, code reviews, release management etc. This is where most of this blog post will focus on.
- When talking about changes and releases to databases, it is important to also consider what makes database operations slightly different from “regular” application code: in addition to the “code” (schema and programmability objects), a database also has state in the form of data stored in it and as the data stored conforms to the schema of the database objects, any changes to those objects typically impacts data. This is what makes operations on a database more challenging than the usual.
- Lastly, the broader database lifecycle (out of scope for this blog post) encompasses critical activities like performance monitoring, iterative tuning of queries and much more. There’s excellent coverage of this broader view of Database Lifecycle Management in this series of community posts from Redgate.
Developer Experience
There are two common approaches when it comes to implementing changes in a database:
- Declarative or state-based approach: the developer specifies the end state of the database, and lets the tooling figure out how to incrementally update a given target database to bring it to that end state
- Imperative or migration-based approach: the developer (sometimes with help from some tooling) creates an incremental script (or set of scripts) which implements the change
State-based approach
SSDT, now integrated into Microsoft Visual Studio, is a popular tool of choice for most Microsoft SQL database developers. SSDT provides the full power of the regular Visual Studio Source Control features like editing code, git pull / push, View History, etc. and also provides a first-class “state-based” (or declarative) development experience on Microsoft Windows.
The build output (artifact) produced by SSDT is in the form of a DACPAC file. DACPACs are the preferred means of deployment in a state-based approach, and they can be used for both greenfield and incremental deployments of databases. The underlying framework on which SSDT is based upon is a library called DAC Framework (DACFx). While the DACPAC is a model of your database schema and code, DACFx implements very powerful “schema comparison” capability which allows the production of a “publish script” based on the difference between the state of the target database and the desired state (as defined in the DACPAC / model). SSDT also leverages and exposes this powerful schema comparison as graphical tool in the IDE.
DACPAC deployment is enabled by a set of libraries and tools shipped under the name “SQLPackage”. SQLPackage is technically the name of the main tool, which in turn is powered by DACFx. These tools and library are now available for Windows, Linux and macOS. DACFx is also available as a NuGet package (for .NET Framework and .NET Core) and allows interested developers to optionally write their own custom deployment tooling. See the Practical Considerations section of this post for examples of customizing DACFx.
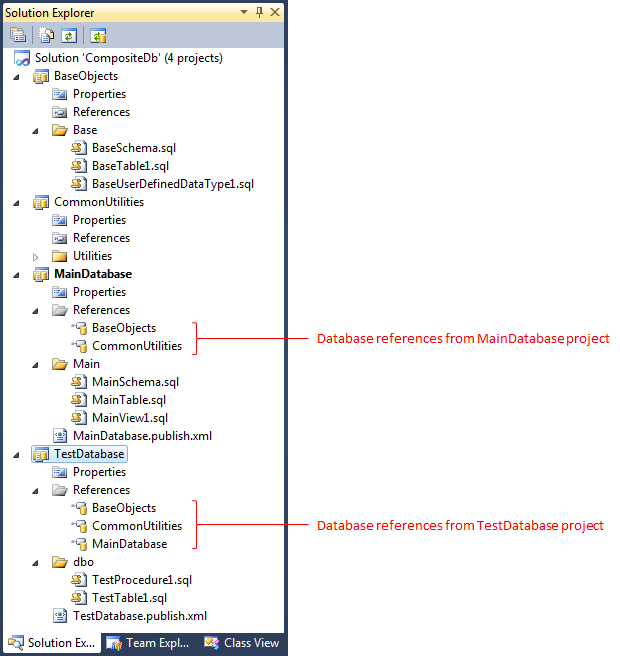
SSDT also allows code sharing and reuse through advanced features like Composite Projects where a large project can be composed almost entirely out of references to smaller, building block projects, each of which builds its own DACPAC:
Migration-based approach
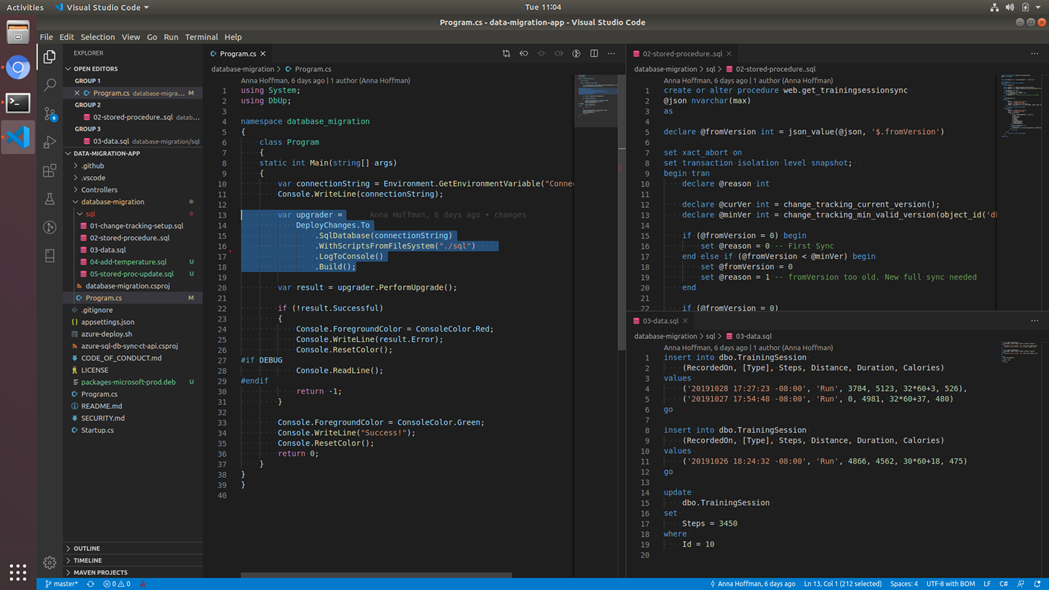
Instead of the state-based approach used by SSDT, some customers opt to use the migration-based approach with third-party tools like SQL Change Automation, DbUp, Flyway etc. These third-party tools are mentioned here on an “as-is” basis. Please review the capabilities, applicability, and accuracy of these before using them in your projects and workflows. A simple example of using DbUp for implementing database migrations using .NET Core (as a part of an application) is available in this repo. A screenshot of the development experience on Ubuntu using VSCode is shown below:
If you want to know more about the differences between state-based vs. migration-based approaches and tooling, the “DevOps for Databases” content within the PartsUnlimited lab exercises can be useful.
Code Analysis
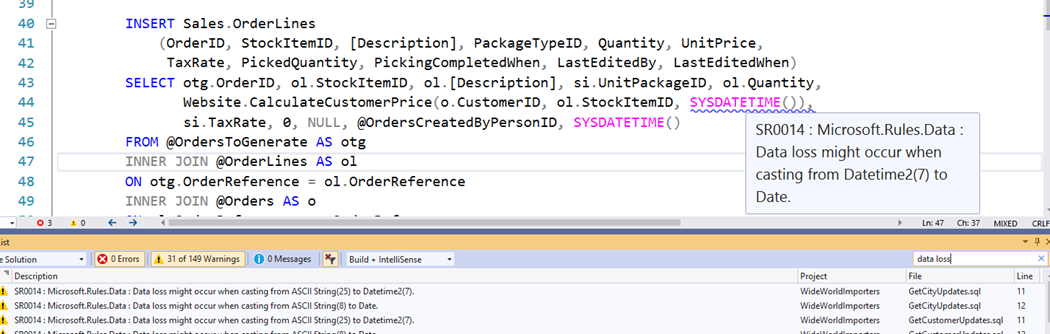
SSDT also ships with built-in Code Analysis capabilities which can be used to detect common anti-patterns in T-SQL code. In addition to the built-in rules, there are some open-source projects (listed in the Practical Considerations section of this post) which provide additional code analysis rules. There is a comprehensive Extensibility model provided by SSDT to add your own custom rules. While most rules are flagged as warnings, the SSDT project can optionally be set to cause the build to fail if specific (or any) rules are flagged during project build. Having Code Analysis built-in to the project greatly helps avoid common errors from creeping into production environments. Code Analysis surfaces warnings / errors which generally pin-point the source of the issue, making it easy for the developer to fix the issue:
Third party tools like SQL Code Guard provide similar code quality features for migration-based projects. There are some open-source command-line SQL code analyzers like sqlcheck as well, which can be integrated into CI pipelines to drive code quality.
Unit Tests
Unit Testing is another common requirement which can be accomplished by using Unit Tests within the Database project as shown here, or by using third-party tools like tSQLt.
DevOps Tooling
There are multiple options for this. Azure DevOps (Azure DevOps) provides an integrated solution through the entire software lifecycle: Planning, Development, Deployment and Operations. GitHub Enterprise is also very popular with customers. There are many other options which support integrated planning, development, delivery, and operations functionality.
Software Process
Development teams can define, track, and lay out work with Kanban boards, backlogs, custom dashboards and reporting capabilities using Azure Boards. Azure Boards fully supports common process models like Scrum, Agile or CMMI, and allows customization as needed. Azure DevOps also supports multiple projects, multiple teams within an organization, and multiple organizations can exist as needed. Usually, the overall Azure DevOps organization is managed by Central IT.
Code workflows
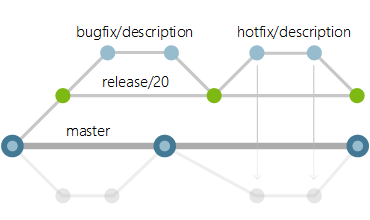
Development teams should follow appropriate Git branching strategy – as an example refer to this article. Use feature, release, and hotfix branches to independently track ongoing work. Port changes back to master from these branches.
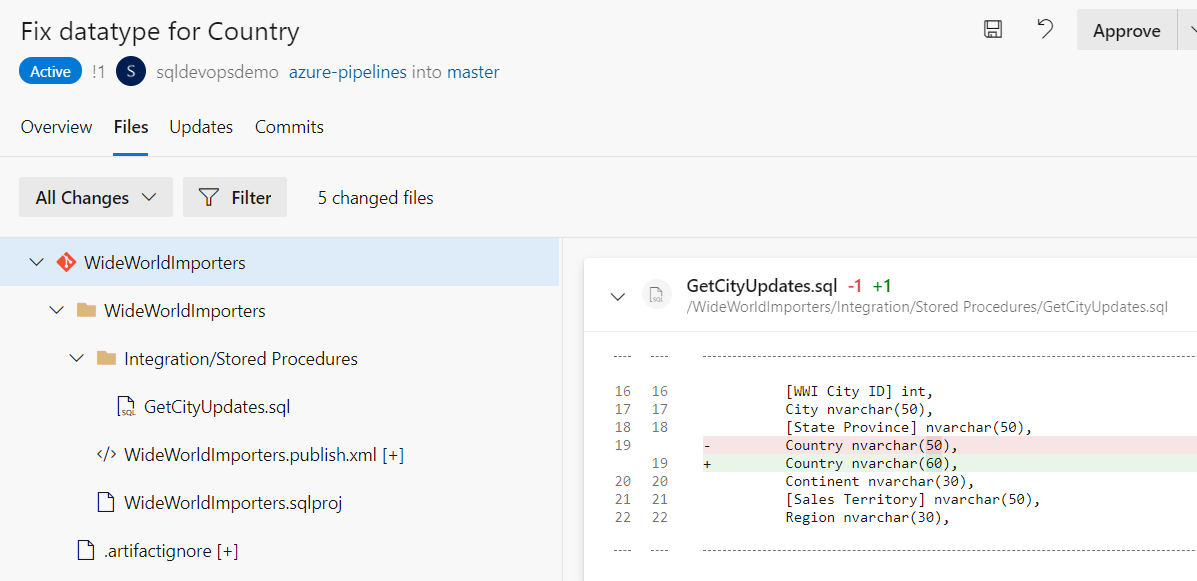
Azure DevOps provides version control and code collaboration workflows which should be very familiar to most developers. Here is a screenshot of a Pull Request for a database schema change, in Azure DevOps:
Creating Azure SQL resources
Typically, Central IT will create the Azure SQL resources (server, database, elastic pool, managed instance etc.) ahead of time or as a distinct separate step in a DevOps pipeline. A good way to do this is to use an ARM template, because it allows great control over the deployment and allows the implementation to comply with Security and Compliance standards that are defined by the Security teams. For example, security requirements might dictate that the Azure SQL DB Logical Server only allow connections over a private endpoint using Private Link.
As an alternative to using ARM templates, if you use a T-SQL command to create a new Azure SQL DB then the T-SQL script must loop and check for completion of the database creation. See the Practical Considerations section of this post for an example of this. Note that certain resources, like Azure SQL DB Logical Server cannot be created via T-SQL. Use ARM templates or equivalent PowerShell / Azure CLI commands for that.
Build and Release pipelines
Development teams can also automate testing and practice continuous integration in the cloud with Azure Pipelines, create automatic workflows from idea to production with GitHub Actions, and even bring their Jenkins workloads to the Azure.
Azure DevOps also provides Build and Release pipelines which can be used to implement a typical CI/CD workflow. Typically, the Build pipeline will produce a DACPAC artifact. Please refer to the Practical Considerations section of this post for a note on how to efficiently do this in Azure DevOps. You can also use the built-in deployment task to deploy to Azure SQL DB as part of the same pipeline. More information and source code for that task is available here. We can implement the entire pipeline using YAML which can then be stored and versioned as part of a repo. Here is a sample Azure DevOps pipeline:
pr:
- master
pool:
vmImage: 'windows-latest'
variables:
- group: 'Secrets'
- name: solution
value: '**/*.sln'
- name: buildPlatform
value: 'Any CPU'
- name: buildConfiguration
value: 'Release'
steps:
- task: VSBuild@1
inputs:
solution: '$(solution)'
platform: '$(buildPlatform)'
configuration: '$(buildConfiguration)'
- task: PublishPipelineArtifact@1
displayName: 'Publish DACPAC as artifact for current run'
inputs:
targetPath: $(Build.SourcesDirectory)
artifactName: 'sqlproj_artifacts_$(System.JobAttempt)'
condition: always()
- task: SqlAzureDacpacDeployment@1
displayName: 'Deploy Azure SQL DB'
inputs:
azureSubscription: '$(azureSubscription)'
ServerName: '$(azureSqlServerName)'
DatabaseName: '$(azureSqlDBName)'
SqlUsername: '$(azureSqlUser)'
SqlPassword: '$(azureSqlPassword)'
DacpacFile: '$(System.DefaultWorkingDirectory)/WideWorldImporters/bin/Release/WideWorldImporters.dacpac'
PublishProfile: '$(System.DefaultWorkingDirectory)/WideWorldImporters/WideWorldImporters.publish.xml'
DeleteFirewallRule: false
For those who prefer to work with GitHub Actions, there is a deploy Azure SQL Database Action which allows the user to deploy either a DACPAC or a SQL script to an Azure SQL DB. An example of how to use this with migration-based SQL script approach is in this sample project.
Other Tooling Options
In addition to the above first-party tools, customers also have a choice of third-party solutions like Redgate’s SQL Change Automation from Red-Gate, Octopus Deploy and many others to choose from. Some customers have hybrid solutions leveraging (for example) GitHub Enterprise for source code control, Azure DevOps Pipelines for CI and CD and a third-party solution for Release Management.
Practical Considerations
SSDT: Open-source Code Analysis tools
These projects are maintained by the community and are mentioned here on an “as-is” basis. Please review the capabilities, applicability, and accuracy of these before using them in your projects and workflows:
SSDT: Specify Azure SQL DB Service Objective
Depending on your CI process, you may need to specify the Service Objective (SLO) as part of the Deployment settings / publish profile. If the target database does not exist, then DACFx will create a database with the default SLO (which is currently “General Purpose Gen 5, 2 vCore”) database. We can override this default SLO and have DACFx create the target database with (for example) a Hyperscale 16 vCore SLO by the adding the following lines to the XML publish profile file:
<DatabaseEdition>Hyperscale</DatabaseEdition> <DatabaseServiceObjective>HS_Gen5_16</DatabaseServiceObjective>
While the above will create the database with the correct SLO (which controls the resource limits / compute size for each DB), note that these settings are ignored if the database already exists. In other words, the target database will not be modified to a new SLO if the publish profile is changed to specify the new SLO. Instead, you should script the SLO change using T-SQL or use an ARM template to specify the new SLO before deploying the DACPAC. A reference for the various SLO names for the vCore model is here and the list for the older DTU model is here.
Self-hosted Azure DevOps agent
Previously, we described how certain scenarios may enforce specific infrastructure and security patterns when deploying Azure SQL DB. For example, security requirements might dictate that the Azure SQL server only allow connections over a private endpoint using Private Link. In such a case it may be necessary to deploy a self-hosted Azure DevOps agent (typically inside a VM deployed by Central IT) directly connected to the Azure Virtual Network corresponding to the Azure SQL DB private endpoint. In such cases all that you will need on the self-hosted agent is the SQLPackage tools.
Creating a new Azure SQL DB through T-SQL
If you choose to create the Azure SQL DB as part of your pipeline by executing T-SQL scripts, keep in mind that the CREATE DATABASE T-SQL statement runs as an asynchronous operation for Azure SQL DB. So, it is necessary to query the status of the operation before proceeding. Here is a sample script showing you how to do that:
PRINT N'Creating $(DatabaseName)...'
GO
CREATE DATABASE [$(DatabaseName)] COLLATE SQL_Latin1_General_CP1_CI_AS
GO
DECLARE @job_state INT = 0;
DECLARE @index INT = 0;
DECLARE @EscapedDBNameLiteral sysname = N'$(DatabaseName)'
WAITFOR DELAY '00:00:05';
WHILE (@index < 60)
BEGIN
SET @job_state = ISNULL( (SELECT SUM (result) FROM (
SELECT TOP 1 [state] AS result
FROM sys.dm_operation_status WHERE resource_type = 0
AND operation = 'CREATE DATABASE' AND major_resource_id = @EscapedDBNameLiteral AND [state] = 2
ORDER BY start_time DESC
) r), -1);
SET @index = @index + 1;
IF @job_state = 0 /* pending */ OR @job_state = 1 /* in progress */ OR @job_state = -1 /* job not found */ OR (SELECT [state] FROM sys.databases WHERE name = @EscapedDBNameLiteral) <> 0
WAITFOR DELAY '00:00:05';
ELSE
BREAK;
END
GO
Customizing DACFx using contributors
Sometimes you may want to override the default behavior and scripts generated by DACFx. For example, you may want to leverage online operations when altering a table, something that is not enabled in DACFx. To do this, DACFx provides a rich extensibility mechanism called Contributors. Examples of these are available here. A community presentation about this topic is also available here.
Conclusion
DevOps is a broad term with multiple technology and process options at hand. There are many options to implement DevOps for Azure SQL – as an example, SSDT or other tools to perform state-based or migration-based development and release. You can also select from solutions like GitHub Actions or Azure DevOps pipelines (or even a combination thereof). Use what is most appropriate and efficient for your scenario. In upcoming posts, we will show you more examples of these approaches and tools in action. Stay tuned!
thanks, great intro and overview, just what I needed to quickly get up to speed in SQL Server project + Azure DevOps
If you would like to be able to build a SSDT project without having to depend on Windows, you can use this project: https://github.com/jmezach/MSBuild.Sdk.SqlProj
🙂 Thanks for the shout out Erik.
Thanks, Erik, for the great tip! I just tried it out on Ubuntu and .NET Core 3.1 – it worked like a charm!
Great article Arvind. Looking forward to the rest of the series.