

The Azure SQL Database has two main ways to track changes with data (rows/DML) as well as table changes. One of those methods is Change Tracking with the other being Change Data Capture. Today’s post will be going into depth on Change Tracking.
Change Tracking and Change Data Capture
So, what’s the difference between the two? Change Data Capture provides historical change information while Change Tracking captures the fact that rows in a table were changed but doesn’t capture the data that was changed. Here is a quick look up table from the documentation:
| Feature | Change data capture | Change tracking |
|---|---|---|
| Tracked changes | ||
| DML changes | Yes | Yes |
| Tracked information | ||
| Historical data | Yes | No |
| Whether column was changed | Yes | Yes |
| DML type | Yes | Yes |
So why would I use Change Tracking over Change Data Capture? To start, if you don’t need to know about historical data and just want what has changed over a set time period, Change Tracking is for you. Seeing it tells you what has changed and not the actual data that has changed, storage and processing overhead is going to be much less. As for use cases, say you have a table that you have an ETL pipeline run every night to fill a data warehouse/lake house for analytics. Using Change Tracking, you can get the final version of all the rows that have changed in the past 24 hours and not pull the entire table over for a truncate/replace operation. This significantly reduces the amount of data moved as well as processing time.
Sample Data
Let’s take this ETL use case and see this Change Tracking in action. To start, create a new Azure SQL Database called CTDemo and use the AdventureWorksLT sample data. You can add this sample data in the Azure Portal when creating a new Azure SQL Database. It’s under the Additional Settings tab.
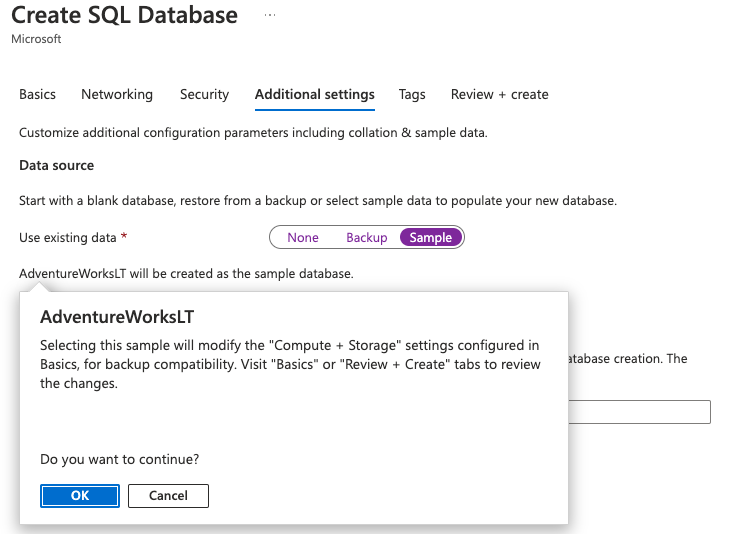
And once the database is up and running, I can use Azure Data Studio to quickly connect to it. Here I called my database CTDemo.

Now that we have connected to the database, we can take a quick look at the sample tables and the data in them.

Enable Change Tracking
The table we are interested in is the SalesLT.SalesOrderDetail table. Here we can turn on change tracking and create this sample ETL extract but only include the rows that have been modified (insert/update/delete).
Open a new query window and run the following SQL as the sqladmin user to enable Change Tracking:
ALTER DATABASE CTDemo
SET CHANGE_TRACKING = ON
(CHANGE_RETENTION = 2 DAYS, AUTO_CLEANUP = ON);
GO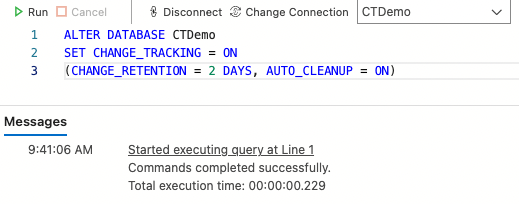
Two things to note here. First, the CHANGE_RETENTION parameter. This is used to tell Change Tracking how long to keep the changes around in the tracking tables. The AUTO_CLEANUP parameter is used to enable or disable the cleanup task that removes old change tracking information that is older than the CHANGE_RETENTION period.
Next, enable the table to be tracked with Change Tracking:
ALTER TABLE [SalesLT].[SalesOrderDetail]
ENABLE CHANGE_TRACKING
WITH (TRACK_COLUMNS_UPDATED = ON)
GOThe parameter TRACK_COLUMNS_UPDATED is used to store extra information about which columns were updated to the internal change tracking table. This can be used later to help with ETL and query jobs to find the exact column with the changes but will add some storage overhead seeing we are keeping more information in the tracking tables.
When you enable Change Tracking on a table, it automatically creates a side table to store the changes with the naming format sys.change_tracking_tableID, with tableID being the ID of the table.
Change Tracking Version Numbers
To understand what change tracking is doing, we need to understand the version numbers it has and how it uses them as well as the side tables it creates.
As you just read, when you enable change tracking on a table, it creates a side table which contains the information on which rows have changed. There is also a system table called syscommittab that is created when DB is created regardless of if change tracking is on or not that is used. These are the tables that are used in conjunction with the version numbers to know what changes to keep and which changes to remove due to the retention period we set when enabling Change Tracking.
Along with these tables are the version numbers. To start, we have the current version number and the function to get this number, CHANGE_TRACKING_CURRENT_VERSION(). This number is associated with the last committed transaction on the table that is being tracked. You alter the data in the table via an insert, update, or delete, this number will increase by one. Next version number is the minimum valid version with the corresponding function CHANGE_TRACKING_MIN_VALID_VERSION(). This version number is the minimum number that we can use to get change tracking information from our tracked tables. Data in the tracking tables that have a number lower than the minimum valid version will have been removed by the cleanup jobs again based on your retention period.
As we use Change Tracking in practice in this post, these version numbers and how to use them will become clearer.
We can use the following SQL to query the Change Tracking DMV that contains information about which tables are enabled. This uses the object_name(object_id) function to take in the table ID that’s in the sys.change_tracking_tables and returns the table name to provide more information than just a number for the table.
select object_name(object_id) [table],* from sys.change_tracking_tables;
GO
Before we go any further, let’s explain what these columns are:
sys.change_tracking_tables Columns
| Column name | Description |
|---|---|
| object_id | the ID of the table |
| is_track_columns_updated_on | the current state of change tracking on a table with 1 being on and 0 being off |
| begin_version | Version of the database when change tracking started for the table. begin_version starts at 0, when a transaction is committed, it gets incremented by one – new tables get the current version number |
| cleanup_version | Version up to which cleanup might have removed change tracking information. |
| min_valid_version | Minimum valid version of change tracking information that is available for the table. |
Working with Change Tracking
Now that we have the background, time to use this in practice. Start with the following query to pull all the line items of order number 71784 from the SalesLT.SalesOrderDetail table:
select * from [SalesLT].[SalesOrderDetail]
where SalesOrderID = 71784
order by SalesOrderDetailID
GOThis oder has 43 lines to it. We can issue a update to this order by giving all the lines with a quantity greater than 8 a 10% discount with the following SQL:
update SalesLT.SalesOrderDetail
set UnitPriceDiscount = '0.10'
where SalesOrderID = 71784
and OrderQty > 8;
GOTen rows updated, now let’s look at the change tracking information for this table. Now with what we know about version numbers, we can look at the current version and expect to see 1. Why a 1? Because one transaction took place, the update we just performed:
select CHANGE_TRACKING_CURRENT_VERSION() 'Current Version';
GO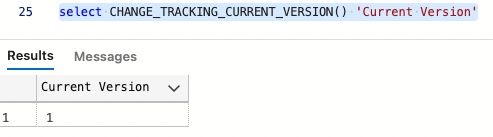
To look at the tracking information, we need to use the CHANGETABLE function. The function takes the following: CHANGES table_name , last_sync_version Which returns tracking information for all changes to the table you passed in that have occurred since the version that is specified by last_sync_version. If you pass in null, it will bring back all changes in the table from the retention period forward. If you pass in a later version number, you will get only a subset of changes.
This last_sync_version will be critical if you have an ETL process that runs every 24 hours, but the retention period is 48 hours. The ETL process should be asking for the CHANGE_TRACKING_CURRENT_VERSION and storing that value for the next run so that all changes from that point on are seen. In our example, we are just starting out so we would pass in null to get the initial set of changes but store the value of CHANGE_TRACKING_CURRENT_VERSION for the next job. Say 4 transactions happen and we start our query again. Passing in 1 would get the changes from 1 and up with the CHANGE_TRACKING_CURRENT_VERSION now being 5. We store the value 5 and use it with the next query.
SELECT
*
FROM
CHANGETABLE(CHANGES SalesLT.SalesOrderDetail, null) as CT;
GO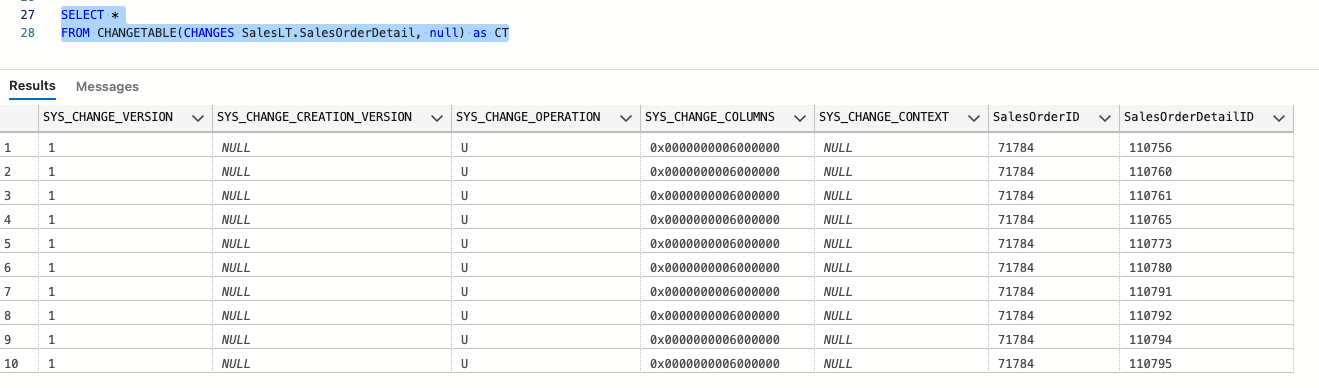
And the columns being the following:
| Column name | Description |
|---|---|
| SYS_CHANGE_VERSION | Version value that is associated with the last change to the row |
| SYS_CHANGE_CREATION_VERSION | Version values that are associated with the last insert operation. |
| SYS_CHANGE_OPERATION | Specifies the type of change: U = Update I = Insert D = Delete |
| SYS_CHANGE_COLUMNS | Lists the columns that have changed since the last_sync_version (the baseline). The column names are masked so use CHANGE_TRACKING_IS_COLUMN_IN_MASK to interpret it. |
| SYS_CHANGE_CONTEXT | Change context information that you can optionally specify by using the WITH clause as part of an INSERT, UPDATE, or DELETE statement. |
| <primary key column value> | The primary key values for the tracked table. These values uniquely identify each row in the user table. |
Now that we have our changes, we can create an ETL query that we might use to pull the changed rows and apply them into another database for reporting and analytics:
SELECT D.*
FROM SalesLT.SalesOrderDetail AS D
INNER JOIN CHANGETABLE(CHANGES SalesLT.SalesOrderDetail, 0) AS CT
ON D.SalesOrderID = CT.SalesOrderID
AND D.SalesOrderDetailID = CT.SalesOrderDetailID;
GO
Playing with Numbers
Now that we have an understanding on how change tracking initially works, let’s play with some version numbers. We can take a line of this order and give it a “extra special discount for good customers” of 100%. Now Line total is a computed column so when it updates with this discount or the previous update we did, the column will not trigger a change tracking event. Run the following SQL for our special discount. We are going to use the SYS_CHANGE_CONTEXT function to add some flavor:
declare @ct_context varbinary(128) = convert(varbinary(128), N'extra special discount for good customers');
with CHANGE_TRACKING_CONTEXT (@ct_context)
update SalesLT.SalesOrderDetail
set UnitPriceDiscount = '1.00'
where SalesOrderDetailID = 110762;
GOLook at the change tracking table again. First, let’s pass in null:
SELECT *
FROM CHANGETABLE(CHANGES SalesLT.SalesOrderDetail, null) as CT;
GO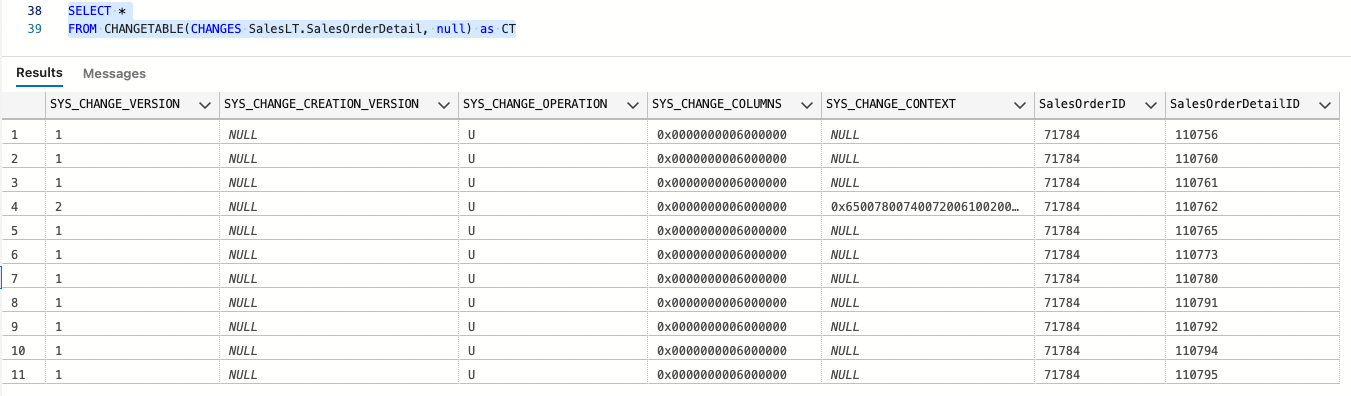
We see 11 rows: the 10 rows from our first update and the one from our last update. You can see the new row has a SYS_CHANGE_VERSION of 2.
Limit the results
Back to that ETL process use case. If the process was run with 0 or null, it would again get the initial 10 updates and the new update but that’s not what we want, we want only the new changes. If the process took and stored the CHANGE_TRACKING_CURRENT_VERSION which was 1, it would now pass it into the query, and we would see the following:

That’s a little better. You could imagine a table with thousands of changes a day and getting just the changes from the last ETL process again will help with ETL size and processing time. If you looked at the SYS_CHANGE_CONTEXT column, you do see it needs to be converted into a varchar. Use the following SQL for that:
SELECT convert(varchar(128),sys_change_context) sys_change_context_text, *
FROM CHANGETABLE(CHANGES SalesLT.SalesOrderDetail, 1) as CT;
GO
And our ETL pipe query would then use the CHANGE_TRACKING_CURRENT_VERSION and run the following query:
SELECT D.*
FROM SalesLT.SalesOrderDetail AS D
INNER JOIN CHANGETABLE(CHANGES SalesLT.SalesOrderDetail, 1) AS CT
ON D.SalesOrderID = CT.SalesOrderID
AND D.SalesOrderDetailID = CT.SalesOrderDetailID;
GO
And as expected, we only see the details for that single row update. How about inserts and deletes? We can run some of those now and see what we get. Starting with an insert, we can insert a line into our SalesLT.SalesOrderDetail table:
insert into SalesLT.SalesOrderDetail (SalesOrderID, OrderQty, ProductID, UnitPrice, UnitPriceDiscount)
values (71784, 100, 999, '343.6496', '0.50');
GOAnd view the order with the following SQL:
select * from [SalesLT].[SalesOrderDetail]
where SalesOrderID = 71784
and ProductID = 999;
GO
The CHANGE_TRACKING_CURRENT_VERSION was 2 before this transaction happened so we use that in our query of the change tracking table. Remember the flow would be:
- use stored value
- get changes
- get current value
- and store it for the next query
SELECT *
FROM CHANGETABLE(CHANGES SalesLT.SalesOrderDetail, 2) as CT;
GO
And our ETL query would show this inserted row as well:
SELECT D.*
FROM SalesLT.SalesOrderDetail AS D
INNER JOIN CHANGETABLE(CHANGES SalesLT.SalesOrderDetail, 2) AS CT
ON D.SalesOrderID = CT.SalesOrderID
AND D.SalesOrderDetailID = CT.SalesOrderDetailID;
GO
What if I were to delete this row I just inserted? And what if my current version was still at 1? What happens? Seeing it’s another transaction, does passing in 2 show the insert and passing in 3 show the delete? Let’s take a look.
Delete the row using the SalesOrderDetailID. For my query, its 113407:
delete from SalesLT.SalesOrderDetail
where SalesOrderDetailID = 113407;So what happens when I pass in the previous query using the 2 as the last_sync_value?

It shows the row as deleted as it should. Even though this row was created in a previous transaction, it no longer exists so for data consistency, it is marked as deleted no matter how many updates it might of had or when it was inserted. And passing in 3 gives the same results as above with the row marked as deleted. Very nice feature indeed!
Clean Up
Let’s change the change retention period see what happens:
ALTER DATABASE CTDemo SET CHANGE_TRACKING (CHANGE_RETENTION = 1 MINUTES);
GOThe change tracking auto-cleanup job run about every 30 minutes so we can force the job after we wait one minute for the rows to expire with the following SQL:
CHECKPOINT 1
GO
exec sys.sp_flush_CT_internal_table_on_demand
GO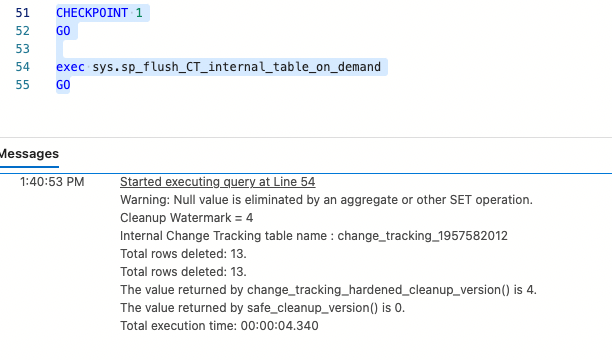
Passing in no parameters for sys.sp_flush_CT_internal_table_on_demand will clean up all side tables for all change tracking enabled tables, the syscommittab system table, and will also update the invalid and hardened cleanup versions. You can also pass in a table name to cleanup just that tables’s side table. In the above image, we see all 13 rows have been cleaned up from our side table and if you were to issue the query to get all changes from a side table with the CHANGETABLE function, you would get 0 rows:
SELECT *
FROM CHANGETABLE(CHANGES SalesLT.SalesOrderDetail, 0) as CTSummary
Change Tracking is a very powerful feature of the Azure SQL Database. We can use it for many use cases to extract just the rows that have changed over a set amount of time with very little overhead on the database. You can read more about Change Tracking in the documentation here. There are a few key concepts to remember; one is the version numbers are incremented by transactions. Two, remember to get and store the current version number if you are pulling for say an ETL process. That is the number you will need for the next job so that you get just the changes from that version number forward. And three, the retention period will flush the changes from all the change tracked tables so be sure to set an appropriate time that works with your process that is pulling the changes from the database.
0 comments