
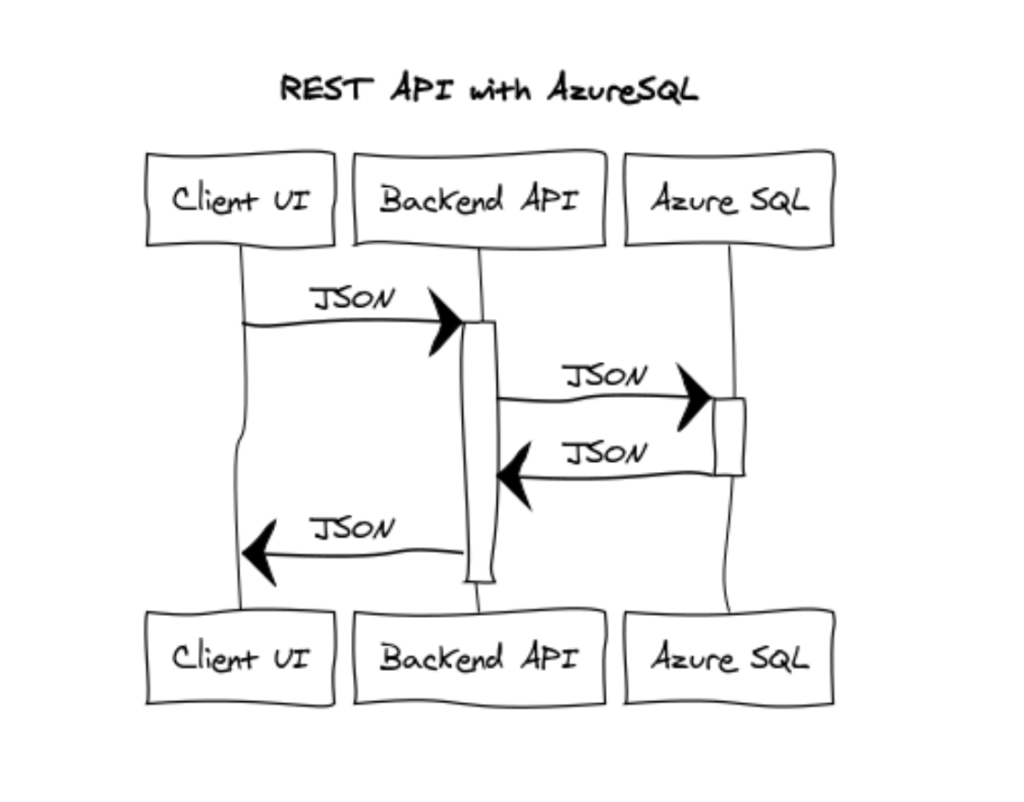
Azure SQL has native JSON support which is a key factor to simplify a lot — and make developer-friendly — the interaction between the database and any service that needs to handle data in even the most exotic way.
As depicted in the image above, JSON can be passed as-is and with just one line of code can be sent to Azure SQL where it can processed and returned in a JSON format. I’m using Python in this sample but really, no matter which language you are using for your project, the workflow is the same. And the result is that, as a developer, you won’t see any recordset or anything that resemble a tabular structure in any way. Just JSON, that can easily be serialized and de-serialized into an object for maximum convenience and easiness of development. Or just kept as a JSON document if you prefer.
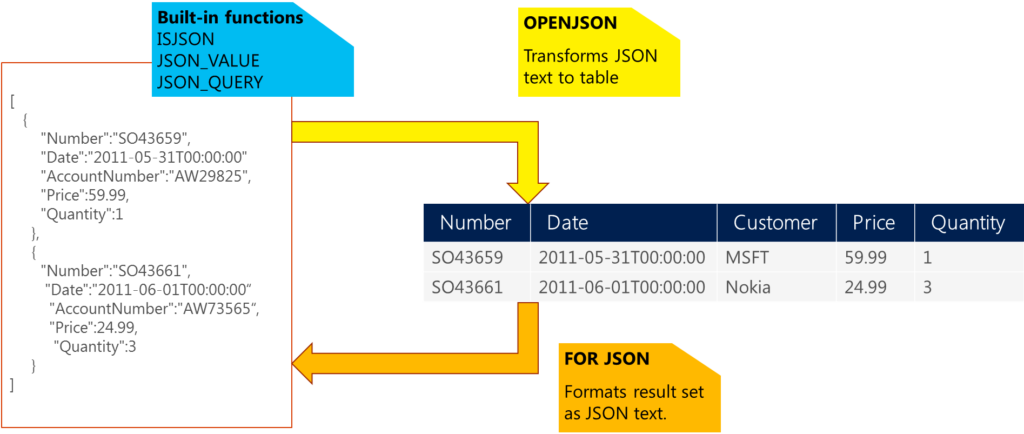
All the heavy lifting, in fact, is done by Azure SQL for you thanks to functions like JSON_VALUE and FOR JSON.
To make things even easier, Python has an amazing framework named Flask that make the creation of REST API pretty simple. But there’s even more. Flask has an extension on its own to make that process even easier. You just have to create your class with a method for each verb you wan to support. Impressive, really. Here’s the two libraries you have to use:
You can find a full explanation along with the source code (hosted on GitHub) and al the details to deploy the solution in Azure. You’ll be able to create and deploy your API in less than 5 minutes!
Building REST API with Python, Flask and Azure SQL
Why I should use a Relational Database at all?
Interesting question. Answer is…easy. Yeah, you didn’t expect that right? Here it is: if you need to store JSON as is, with no or really minimal need to query data stored therein and no need to make complex partial updates to the stored documents, then a document database could be a great choice. If you need anything else, like ability to execute non-trivial queries on data, process aggregates, have transaction consistency, fine-grained security and the need to validate ingested data against a schema, then a relational database should be your choice.
If you’re thinking that you don’t need a schema (and this is the main reason why you’re choosing a NoSQL database), since something like a “schema-less” is a better choice as it will give your much more flexibility and freedom, well….go and read this:
The entire schema-less idea is like a Leprechaun. No, it won’t give you the gold at the end of the rainbow: it just doesn’t exists!
By using Azure SQL you have even more reasons why you should use it: it is a modern, scalable, (post-)relational database, where you can find an amazing number of features that you’ll need to find somewhere else otherwise. This would mean to use many different data management solution (Document, Graph, Key-Value store)…and then having to deal with one of the most difficult problem to solve. Data Integration. If it is absolutely true that Naming Things and Cache Invalidation are the two hardest problem in Computer Science:
There are only two hard things in Computer Science: cache invalidation and naming things (Phil Karlton)
I would easily say that Data Integration comes third. You want to avoid it if possible. And Azure SQL has many features to help you on that. And no, you don’t have to worry about scalability. It scales pretty well. Up to 100TB and hundreds of thousands (at least) of transaction per seconds. Read more here:
10 Reasons why Azure SQL is the Best Database for Developers
One last note
Let me do the math for you here. 10 thousands transaction, let’s say inserts, per second are 864 million rows per day. If you have a very small payload, say 100 bytes only, it will mean 80GB per day or 28 TB year. You can easily handle this load with an Azure SQL Hyperscale 8vCores. Probably way less cores than your desktop or laptop.
0 comments