
When it comes to innovation, we realized that the world’s most valuable resource is no longer oil, but data. One of the biggest challenges we’re having today is how to integrate disparate data sources from many different places. If you’re looking into how to work on Big Data Analytics solutions in Kubernetes, that’s where Big Data Clusters (BDC) comes in.
SQL Server Big Data Clusters (BDC) is a cloud-native, platform-agnostic, open data platform for analytics at any scale orchestrated by Kubernetes, it unites SQL Server with Apache Spark to deliver the best data analytics and machine learning experience.
Now, you are maybe thinking you misunderstood what you just read. No, let me be clear about that. With Big Data Clusters you run SQL Server in Kubernetes, along with Apache Spark, to get the best of both platforms. You’re not dreaming, and yes, this opens a huge universe of opportunities for developers. Read on!
SQL Server on Kubernetes. With Apache Spark. And more.
Kubernetes is the most popular open-source container orchestrator today in the community, it has gained traction incredibly quickly and keeps growing every day. Community makes it even greater with the help of the whole cloud-native ecosystem to resolve the challenges around security, compliance, networking, monitoring, and more whilst working with Kubernetes.
From those developers are working with Kubernetes for their various workloads built up in microservices-based architecture or better saying as of today as correctly-sized services-based architecture since some customers found it’s becoming more and more struggling to maintain overloaded microservices in the enterprise environment. How to consume big data from different data sources in effectively and efficiently is coming into question.
Your modern cloud-native application is not only up and running platform agnostically, take advantage of all-natural benefits from Kubernetes for its high availability, scalability, and full support from its ecosystem, but also packed with the capability to work on big data analytics and consume the machine learning models.
Developing applications with BDC
What’s in for a developer you may be asking to yourself. This post and the ones will follow, will answer this question. To start let’s focus on how to deploy your very first HelloWorld cloud-native application in BDC. We’ll begin with creating the BDC clusters and get access to it, then explore the key task such as the following in the same blog series:
- Develop and deploy the application: azdata utility provides to create an app skeleton to develop which facilitates meanwhile application deployment in BDC.
- Run and test application: azdata utility provides commands to help you run and test the application in BDC.
- Consume application: You’ll be able to obtain an endpoint with azdata utility and a JWT access token and since Swagger is integrated, you’ll be able to test and run the application with Swagger UI or Postman.
- Monitor application: with Grafana integrated into BDC, you’ll be able to keep monitoring your applications with various metrics.
To wrap up, the whole process would look like the following diagram:
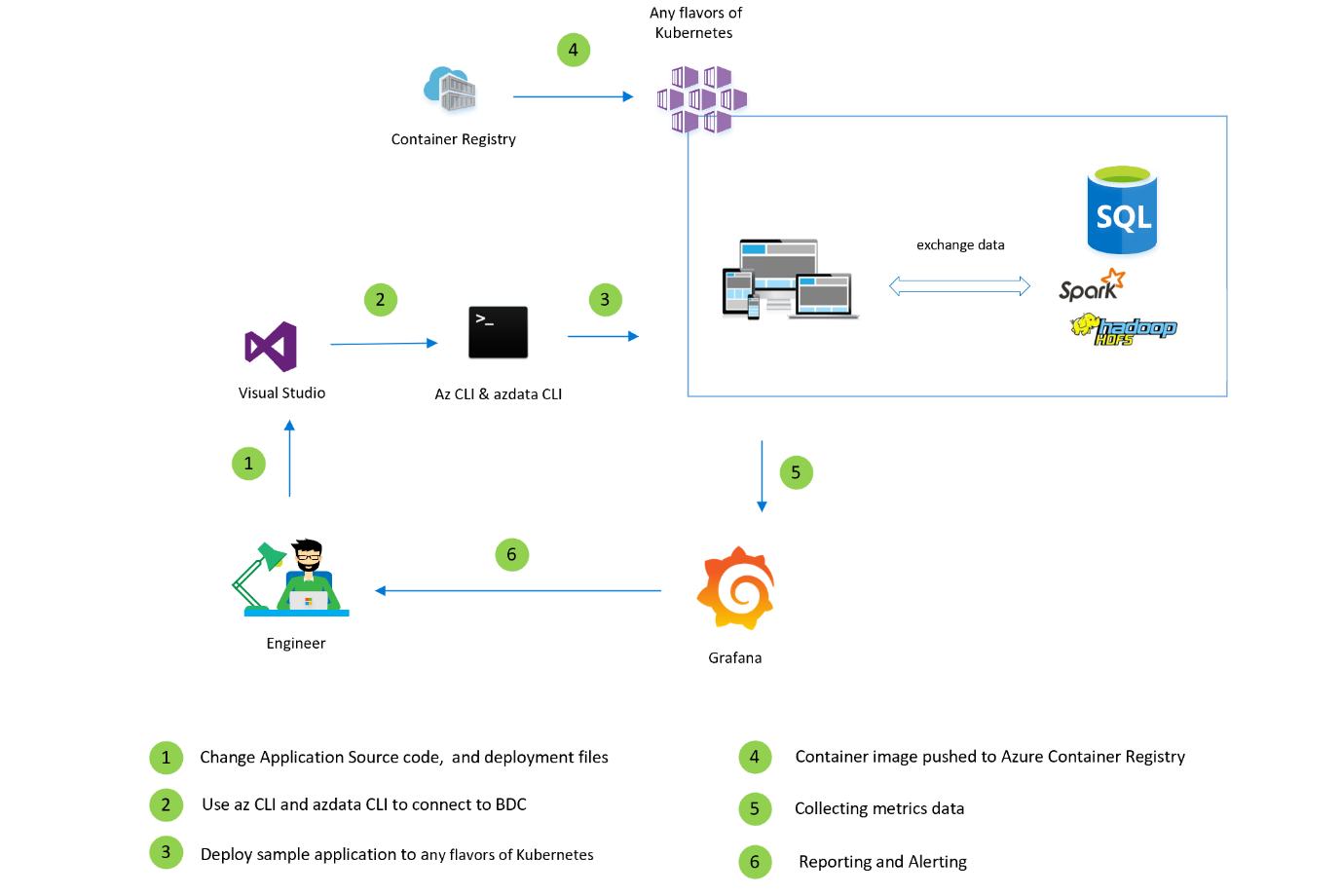
Deploy and connect to BDC cluster
There are a couple of ways to deploy BDC in your cluster, and you need to install SQL Server 2019 big data tools beforehand, you can check SQL Server documentation about how to get started with Big Data Clusters.
In this article, we’re going for Azure Kubernetes Service (AKS) as our preferable deployment platform. Once you get the cluster set up, the next step is to gain access to your cluster where you can use az aks get-credentials command as follows :
az aks get-credentials -n <the name of your AKS cluster where deployed your BDC> -g <your resource group>
Your output of the above command would be as follows:

Besides, you need to log in to the BDC controller endpoint and set your active azdata context to deploy or interact with BDC. Here azdata context defines your privilege and access control settings, which means your access level and permission on a specific namespace in your current cluster. To know more about authentication and authorization of BDC, please check this documentation.
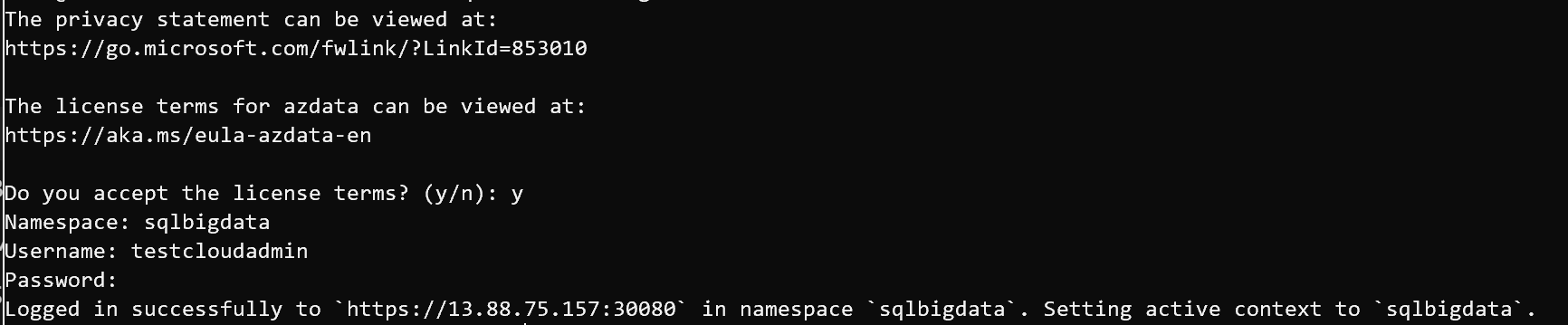
There are two ways to log in, you need to use azdata login command, the following is an example of login interactively where you need to fill your namespace name which is the name of your BDC cluster this time, in addition to the username and password when you created you BDC :
azdata login
Your output of the above command would be as follows:
Alternatively, to log in non-interactively you can specify the authentication such as Basic or Active Directory (AD) with an explicit principal method and the controller endpoint, the command would look as follows :
azdata login --auth basic --username <your BDC username> --endpoint https://<ip or domain name>:30080
Please check here to know how to use basic or Active Directory authentication to log in.
Next Steps
Next article we’ll walk through how to develop and deploy Apps to SQL Server Big Data Clusters (BDC). Let’s stay tuned!
0 comments