
This post was written by guest blogger and Artificial Intelligence MVP Alibek Jakupov.
With increasing popularity of web reviews, there’s been an explosion of web authorship from individuals. These reviews may be classified as false reviews or Opinion Spam. Opinion Spam is inappropriate or fraudulent reviews. It can range from self-promotion of an unrelated website or blog to deliberate review fraud with a potential for monetary gain.
One risk of Opinion Spam is the reviews that falsely praise inferior products or criticize superior products, as they may affect a potential consumer’s actions. Therefore, companies are highly motivated to automatically detect and remove Opinion Spam. Other Natural Language Processing (NLP) tasks, like sentiment analysis or intent recognition, have received considerable computational attention. But, relatively little study has been conducted in detecting Opinion Spam using text classification techniques.
Some types of Opinion Spam are easily identified by a human reader. For example, advertisements, questions, or other non-opinion texts. These instances belong to Disruptive Opinion Spam—irrelevant statements that are evident to a reader and pose a minimal risk, since the user can always choose to ignore them. However, for more insidious types of fictitious texts, like Deceptive Opinion Spam, the task is non-trivial. These statements have been intentionally produced to sound authentic and mislead the reviewer. Deceptive Opinion Spam commonly takes the form of fake reviews (negative or positive). A malicious web user posts the reviews to hurt or inflate a company’s image. As these reviews have been deliberately written to deceive the reader, human reviewers are faring little better than a chance in detecting these deceptive statements. Thus, there’s a dire need to address this issue. Extracting text patterns from the fraudulent texts with meaningful substructures remains a challenge.
The problem is treated as a text classification task. In most cases, text classification systems consist of two parts: a feature extraction component and a classifier. The former allows you to generate features given a text sequence. The latter assigns class labels to this sequence, given a list of corresponding features. Commonly, such features include lexical and syntactic components. Total words, characters per word, and frequency of large and unique words refer to lexical features. Syntactic features are based on frequency of function words or phrases, like n-grams, bag-of-words (BOW), or Parts-Of-Speech (POS) tagging. There are also lexicon containment features. These features express the presence of a term from lexicon in the text as a binary value. Positive means “occurs”, and negative means “doesn’t occur”.
Although this approach is useful, it has some significant drawbacks. The training set’s quality is difficult to control, and building a reliable classifier requires a considerable number of high-quality labeled texts. Moreover, classification models based on the embeddings approach are affected by social or personal attitudes in the training data. The algorithm then draws incorrect conclusions. In certain cases, algorithm inferences may be perfect on the training set and non-generalizable for new cases. This scenario may represent serious challenges for Deceptive Opinion Spam detection.
To understand how lies are expressed in texts, we’ll investigate the usefulness of the other approaches. The Azure Text Analytics client library for Python will be used for the investigation. The library allows you to:
- Get various aspects of a sentiment. For example, neutrality or negativity.
- Analyze overall sentiment, which may not always be uniform. Some reviews are composed of both negative and positive aspects.
Prerequisites
- Python 2.7, or 3.5 or later
- Azure subscription and a Cognitive Services or Text Analytics resource. For more information, see the official documentation.
- Azure Text Analytics library for Python. Install the library using pip:
pip install azure-ai-textanalytics - OpenCV for data visualization. Similarly, install the package via pip:
pip install opencv-python - Dataset. For this experiment, we’re using the Ott Deceptive Opinion spam corpus—one of the first large-scale, publicly available datasets in this domain. It’s composed of 400 truthful and 400 gold-standard deceptive reviews, collected using Amazon Mechanical Turk. Download the CSV file from the Kaggle competition.
Introduction
Suppose we have a truthful and a deceptive review. Both reviews are of the same polarity (positive or negative), but one of them is deceptive. However, as most researchers claim, the deceptive reviews may have some underlying patterns that are visible to a machine but not to a human reviewer. In some cases, sentiments are exaggerated. For example, “I looooved the service, it was just BRILLIANT.” What if you could colorize the comments and evaluate the level of exaggeration visually? The following five steps accomplish this task.
Step 1: Create helper functions
First, import all the required packages:
import os
import cv2
import numpy as np
import pandas as pd
from math import ceil
from azure.core.credentials import AzureKeyCredential
from azure.ai.textanalytics import TextAnalyticsClientNext, create helpers that allow you to rapidly get a needed subset of Ott Corpus:
def read_ott():
"""
Either we run it from main or from inside the folder, thus the relative path changes
"""
try:
ott_path = '../local_datasets/deceptive-opinion.csv'
ott_deceptive = pd.read_csv(ott_path, encoding='utf-8', sep=',', engine='python')
except FileNotFoundError:
ott_path = './local_datasets/deceptive-opinion.csv'
ott_deceptive = pd.read_csv(ott_path, encoding='utf-8', sep=",", engine='python')
return ott_deceptive
def get_ott_negative():
ott_dataframe = read_ott()
ott_dataframe_negative = ott_dataframe[ott_dataframe['polarity'] == 'negative']
return ott_dataframe_negative
def get_ott_positive():
ott_dataframe = read_ott()
ott_dataframe_negative = ott_dataframe[ott_dataframe['polarity'] == 'positive']
return ott_dataframe_negative
def get_ott_negative_deceptive():
ott_dataframe_negative = get_ott_negative()
ott_dataframe_negative_deceptive = ott_dataframe_negative[ott_dataframe_negative['deceptive'] == 'deceptive']
return ott_dataframe_negative_deceptive
def get_ott_positive_deceptive():
ott_dataframe_positive = get_ott_positive()
ott_dataframe_positive_truthful = ott_dataframe_positive[ott_dataframe_positive['deceptive'] == 'deceptive']
return ott_dataframe_positive_truthfulStep 2: Create sentiment analyzer
Text Analytics is a cloud-based service that provides advanced NLP over raw text. It includes the following main functions:
- Sentiment Analysis
- Named Entity Recognition
- Linked Entity Recognition
- Personally Identifiable Information (PII) Entity Recognition
- Language Detection
- Key Phrase Extraction
- Multiple Analysis
- Healthcare Entities Analysis
A document is a single unit to be analyzed by the predictive models in the Text Analytics service. The input for each operation is passed as a list of documents and each document can be passed as a string in the list.
For this experiment, we only need the Sentiment Analysis subservice. The subservice looks at its input text and determines whether its sentiment is positive, negative, neutral, or mixed. Its response includes per-sentence sentiment analysis and confidence scores.
Let’s create a helper function, which returns three sentiment aspects of an input string:
import os
from azure.core.credentials import AzureKeyCredential
from azure.ai.textanalytics import TextAnalyticsClient
api_key = os.getenv('API_KEY')
endpoint = os.getenv('ENDPOINT')
credential = AzureKeyCredential(api_key)
text_analytics_client = TextAnalyticsClient(endpoint, credential)
def get_overall_sentiment(phrase):
documents = [phrase]
response = text_analytics_client.analyze_sentiment(documents, language='en')
result = response[0]
if result.is_error:
raise ValueError(
"Sentiment analysis of document failed with code '{}' and message '{}'".format(result.error.code,
result.error.message))
positive = result.confidence_scores.positive
neutral = result.confidence_scores.neutral
negative = result.confidence_scores.negative
return positive, neutral, negativeWe need these values to represent each review as a pixel. For example, blue is neutral, red is negative, and green is positive. These pixels must be combined into a single image. Therefore, depending on the sentiment, we’ll be able to colorize the corpus in a BGR (blue, green, red) format. The acronym isn’t RGB because we’re using OpenCV.
Step 3: Colorize comments
For this step, we’ll create some helper functions to convert our sentiments into pixel format:
def phrase_to_pixel(phrase, show_status=False):
blue, green, red = sentiment_to_opencv(get_overall_sentiment(phrase))
if show_status:
print("processed")
return "{} {} {}".format(blue, green, red)
def sentiment_to_opencv(overall_sentiment):
positive, neutral, negative = overall_sentiment
blue = ceil(neutral*255)
green = ceil(positive*255)
red = ceil(negative * 255)
return blue, green, red
def generate_image(reviews_bgr, image_name):
if len(reviews_bgr) != 400:
return False
image = np.zeros((20, 20, 3), dtype=np.uint8)
counter = 0
for i in range(20):
for j in range(20):
image[i][j] = reviews_bgr[counter]
counter += 1
return cv2.imwrite(image_name, image)Here, we first convert the sentiment to a BGR format. We then generate an image out of these values.
Step 4: Compare the patterns
Now, we have all the elements to run our first experiment.
First, apply the sentiment analyzer on the filtered reviews. For example, deceptive and positive only:
def run_deceptive_positive():
positive_deceptive = get_ott_positive_deceptive()
positive_deceptive['sentiment'] = positive_deceptive['text'].apply(lambda x: phrase_to_pixel(x, show_status=True))
positive_deceptive.to_csv('local_datasets/deceptive_positive_colored.csv', index=False)We save the dataset locally to manipulate the results, without having to rerun the sentiment analysis, which takes some time. We can now visualize the comments:
def get_ott_positive_deceptive_colored():
try:
path = '../local_datasets/deceptive_positive_colored.csv'
ott_positive_deceptive_colored = pd.read_csv(path, encoding='utf-8', sep=',', engine='python')
except FileNotFoundError:
path = './local_datasets/deceptive_positive_colored.csv'
ott_positive_deceptive_colored = pd.read_csv(path, encoding='utf-8', sep=",", engine='python')
return ott_positive_deceptive_colored
def colorize_deceptive_positive():
ott_positive_deceptive_colored = get_ott_positive_deceptive_colored()
ott_positive_deceptive_colored['sentiment'] = ott_positive_deceptive_colored['sentiment'].apply(
lambda x: x.split(' '))
generate_image(ott_positive_deceptive_colored['sentiment'], 'artifacts/deceptive_positive.png')Repeat the procedure for the other subsets (truthful and positive, deceptive and negative, and so on) to compare the results. Here’s what you should have:
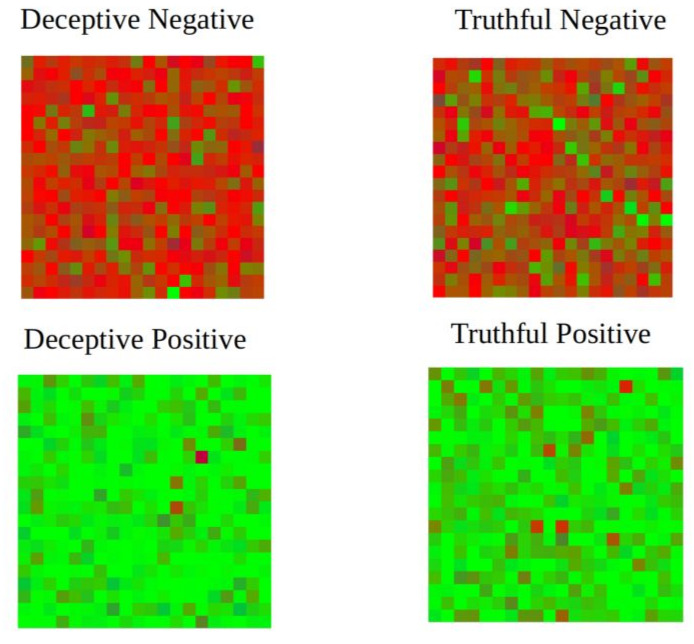
As you may notice from the four pictures above, negative deceptive reviews are brighter, with fewer green spots. These characteristics prove there’s some exaggeration in fake comments. The same pattern may be observed in positive reviews. The colors are much more “juicy”, with fewer red spots. We can literally see how certain services are being falsely flattered. On the other hand, truthful reviews tend to be more realistic.
Step 5: Get the color of deception
The goal of this step is to get a uniform color that accurately represents the deception. To do so, we’ll average all the pixels into one single color by splitting each pixel into three channels. The channels are merged after finding the average of all the pixels:
def mix_colors(reviews_bgr, image_name):
average_blue = 0
average_green = 0
average_red = 0
for blue, green, red in reviews_bgr:
average_blue += int(blue)
average_green += int(green)
average_red += int(red)
average_blue = ceil(average_blue/len(reviews_bgr))
average_green = ceil(average_green / len(reviews_bgr))
average_red = ceil(average_red / len(reviews_bgr))
image = np.zeros((150, 150, 3), dtype=np.uint8)
image[:] = (average_blue, average_green, average_red)
return cv2.imwrite(image_name, image)
def colorize_deceptive_positive_average():
ott_positive_deceptive_colored = get_ott_positive_deceptive_colored()
ott_positive_deceptive_colored['sentiment'] = ott_positive_deceptive_colored['sentiment'].apply(
lambda x: x.split(' '))
mix_colors(ott_positive_deceptive_colored['sentiment'], 'artifacts/deceptive_positive_average.png')After combining all the functions together, we have the following start script:
if __name__ == '__main__':
run_deceptive_positive()
colorize_deceptive_positive()
colorize_deceptive_positive_average()You need to repeat the same procedure for truthful and negative reviews, to finally obtain the following result:
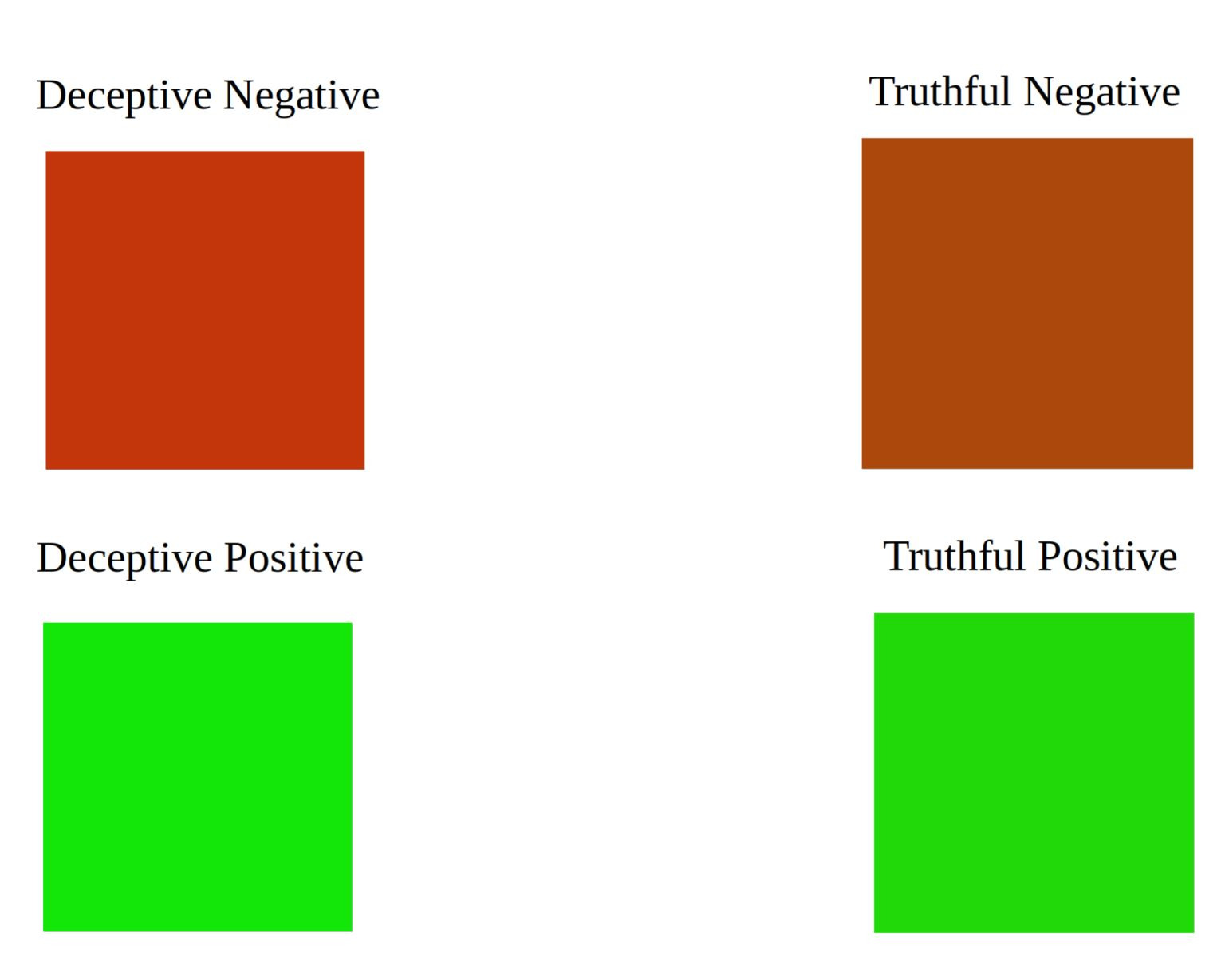
As you may have noticed, truthful negative reviews aren’t as red as deceptive ones. And even fake positive reviews are greener than the truthful comments.
Conclusion
In this blog post, we utilized the sentiment analysis approach to detect the common patterns underlying deceptive reviews. For a better understanding, we applied the opinion mining facility of the Text Analytics API. This tactic allowed you to get different sentiment aspects of input text, such as positive, negative, and neutral polarities. As seen above, the differences in colors between deceptive and truthful reviews are evident. The differences allow us to claim that we can evaluate the extent of exaggeration by visualizing the sentiments. The accompanying code is available on GitHub in the ajakupov/ColorizeComments repository. Feel free to download and test it.
0 comments