

In the previous part of the serverless architecture post for the Contoso Claim processing application, we built two components.
- Claim processing front end components where the text extraction logic from license plates resides. The front end component is designed using the optical character recognition capabilities of Azure Cognitive Services Vision API.
- The claim processing backend services is designed using the Azure Functions consumption plan.
In this iteration, we will make the architecture more sustainable by using Edge computing. Edge computing is a paradigm that brings the compute, storage, and intelligence right down to the edge device where the data is created. We will move the compute required for text extraction down to the devices.
This approach will help us:
- Accomplish the computing power needed to extract the license plate information from the images on the mobile device itself.
- Eliminate the need to have the images of the license plates transferred over the wire from the device to the Azure Cognitive Services APIs and back.
Explanation:
Azure’s Computer Vision API includes Optical Character Recognition (OCR) capabilities that extract printed or handwritten text from images, making this the ideal choice for extracting images from license plates.
The service is serverless and hence compute is used based on the number of calls to the service with the image as the parameter. While this is a green design already, let us try to stretch this principle more.
Today, all mobile devices come with excellent onboard specifications around RAM, multi-core processors. Text extraction from images is a CPU intensive process and we will be able to leverage the processing power already available on cell phones.
OCR Extraction engine on Mobile devices
The key decision-making criteria we need is the technology or SDK that will help us apply OCR directly on cell phones. To this effect, one popular SDK is Tesseract. Tesseract is an enterprise grade open source engine for extracting text from images. It supports multiple languages and hence the solution can be scaled in future by Contoso to recognize license plate information in languages other than English.
An existing open source project called OpenALPR extracts the license plate information from images and even video streams. This project has been built on Tesseract SDK and can be used as an accelerator to build a solution for Contoso. While the focus of this article is not about the SDK itself, it will be useful to know that a customization for the Android ecosystem exists already and can be readily leveraged. OpenALPR for Android
Sustainable Edge Architecture for Claim Processing Front End Components
Below is the re-designed view of the text processing component. We will use the Tesseract SDK to build a custom license plate extraction component and deploy it as an app on the claim processor’s devices. This can also be deployed to the organization play store and hence can get updates and new features easily.
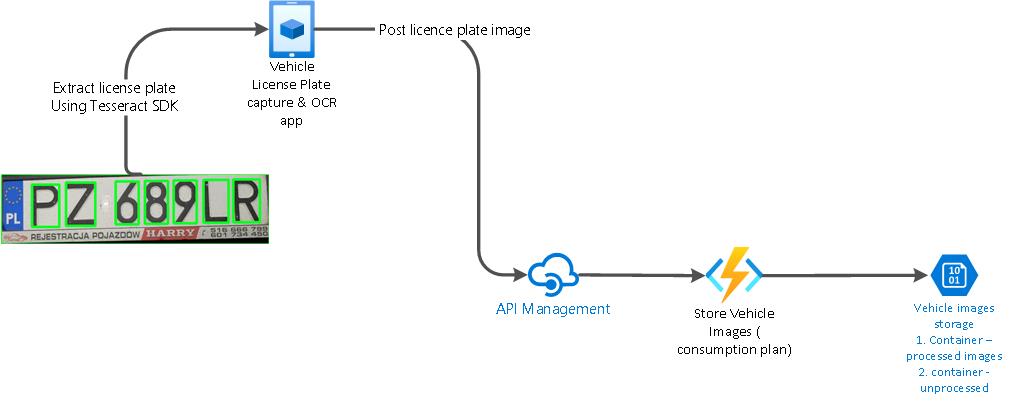
As you can see, the key carbon saving is through us not needing to use Azure Cognitive Services to do the image crunching and text extraction. While this may be a serverless component, there is still some server in the cloud using a lot of CPU processing cycles. By using computing power already vested within the mobile devices that we have today, we are now able to do this processing at the edge itself .
The second major carbon saving delves around not having to send MB of data over the wire to the cloud and back. This saves on network bandwidth tremendously. In Alex Bitiukov’s article on Network optimization for Sustainable software Engineering, we learn that independent research has shown that the network fabric used to connect cloud services to the end consumer can account for as much as 60% of the power drawn by the data center hosting the service and the application. In this case, we strive to use less power in the overall architecture by having the workload processed closer to the user. This is the design pattern of sustainable software engineering called Edge Computing.
Scaling the OCR Component to Desktops
The APLR code is available for mobile devices and can be extended to desktops as well .The OCR extraction libraries are available for the Windows, OS X, and Linux operating systems. This extensibility allows us to offload more processing power to the user’s desktop and enables the sustainability goal of using pre-provisioned compute like Surface devices and Macbooks. Server footprint is reduced, and network bandwidth is saved by moving these processes to the edge .
0 comments