

Akari’s cloud-native journey spanned 12 months, moving from servers to serverless for our core applications. In this article we’ll be talking about what we wish we did, development considerations for bootstrapping a project, ops and observability ups and downs, and how we optimize cost across our platform.
Introduction
When I joined Akari in July 2020 my role was to lead technology consultancy and application development. This core role has stayed the same, although now we have applications in production. It’s a constant journey of learning and improvement in how I manage the team and keep up to date with cloud and what is going on in the world of development, best practice, observability, and cloud platforms. Prior to Akari I was a technical consultant in the Microsoft cloud space, working with organizations of all sizes from scale-up to global enterprise architecting and building out cloud platforms and applications with a principal focus on the Microsoft Azure cloud platform. Within Akari we are as much a customer of Microsoft as we are an ISV and consultancy partner. Working with Microsoft over the past 12 months has been incredibly rewarding, and through inclusive product development led us onto the Microsoft for Startups AI for Good program in London, as well as working directly with cloud architects on the products and ideas. The two core products which we build are ‘AVA’ (Akari Virtual Assistant) and ‘ATS’ (Akari Translation Studio). Our growth and understanding of the solutions and how these are positioned within the market with a focus on inclusivity and accessibility led us to be awarded the Microsoft partner of the year award for global Diversity and Inclusion Changemaker.
AVA (Akari Virtual Assistant)
What is AVA?
AVA is a learning chatbot that lives in Microsoft Teams, designed to answer common questions on an organization’s productivity tools, training materials and accessibility content, as well as having the ability for administrators to load in FAQs through a management interface. The second core function of AVA is to ask a user (on a schedule) wellbeing questions for feedback on personal development, issues within the workplace or for general managerial feedback. This data is collected at an organizational level and reported back anonymously to the organization through the same portal. We initially built AVA in Microsoft Teams (or at least using the Bot Framework), which from an early stage led to some interesting architecture decisions ranging from feature availability to key considerations such as authentication and user experience. AVA is our core hero product and has been through the most iterations of architecture: even though the product at it’s core is cloud-native, the iterative design of AVA comes in part from customer feedback as well as internal experience and feedback.
AVA plan and MVP
We initially began developing AVA by looking at what was available across all of the major cloud platforms at the time, we chose the Bot Framework SDK as there were readily available templates to get kick started with bots and deployment into various channels such as Microsoft Teams or Slack. This leads into the first lesson, something I would go back and tell myself: know what you want to build, or more especially, know what you want your minimum viable product to be. We had a very strong view on what we wanted AVA to be within the organization as it was designed at a senior level (on a train from London to Glasgow no less). But we didn’t have a defined view of what a proof of concept should look like or what an initial bootstrap build would look like. We went straight into product development from initial builds to where we ended up at the end of 2019. We started immediately with the Bot Framework Virtual Assistant as this gave the most cohesive template for what we wanted to connect to as well as the core feature set we wanted from AVA.
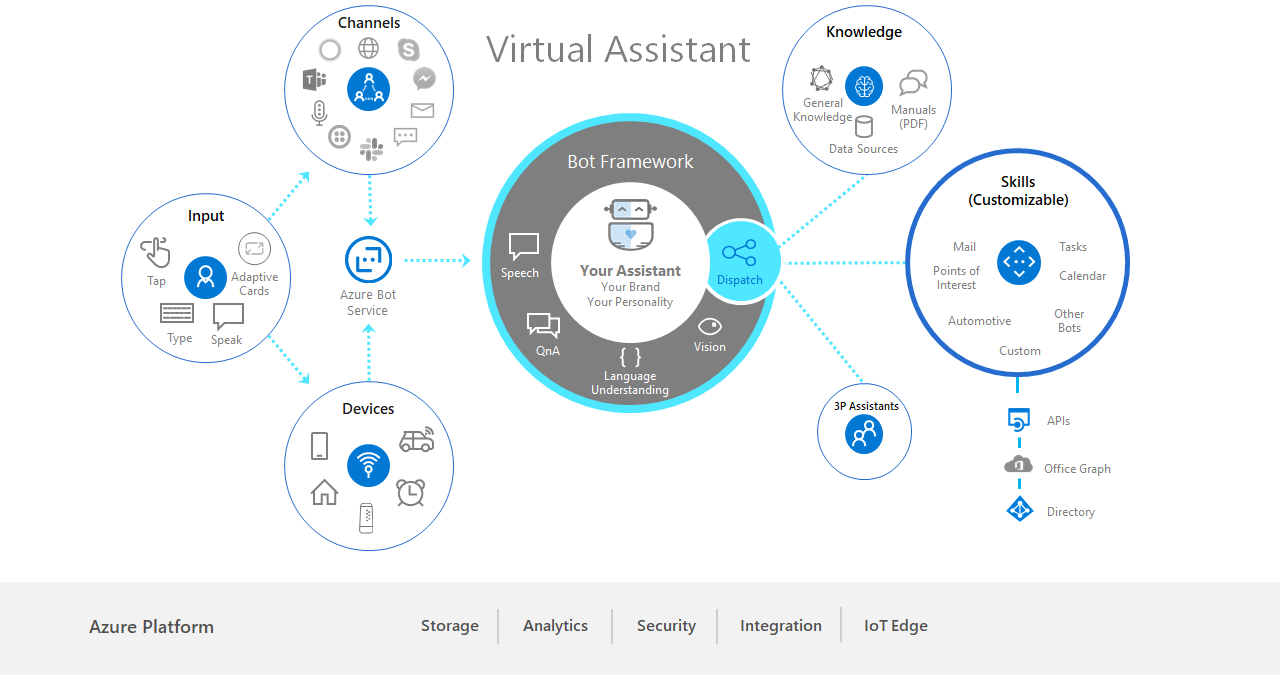
The virtual assistant template built on the Bot Framework provides a brilliant bootstrap for any bot project, I would recommend it when developing a custom bot that you want to operate on a skills-based model or connect to common channels out of the box. It’s worth noting as well that the Bot Framework can be deployed anywhere, your local machine for testing, on servers/VMs and any cloud platform which can run .NET Core or TypeScript.
MVP architecture
Our initial plan for AVA was to provide a learning chatbot friend, which could answer questions, reassure its user and carry out useful tasks. AVA today isn’t too far from this but the initial plan led to an incredibly complex architecture. We built AVA on the ‘skills’ model to provide a modular approach to development, with each skill effectively operating as a standalone bot that the core bot would hand-off too. We built the first version of AVA in .NET Core and ran the core services on Azure App Service. The initial architecture looked something like the below, this is the original architecture diagram I created when we hit version ‘one’ of AVA:
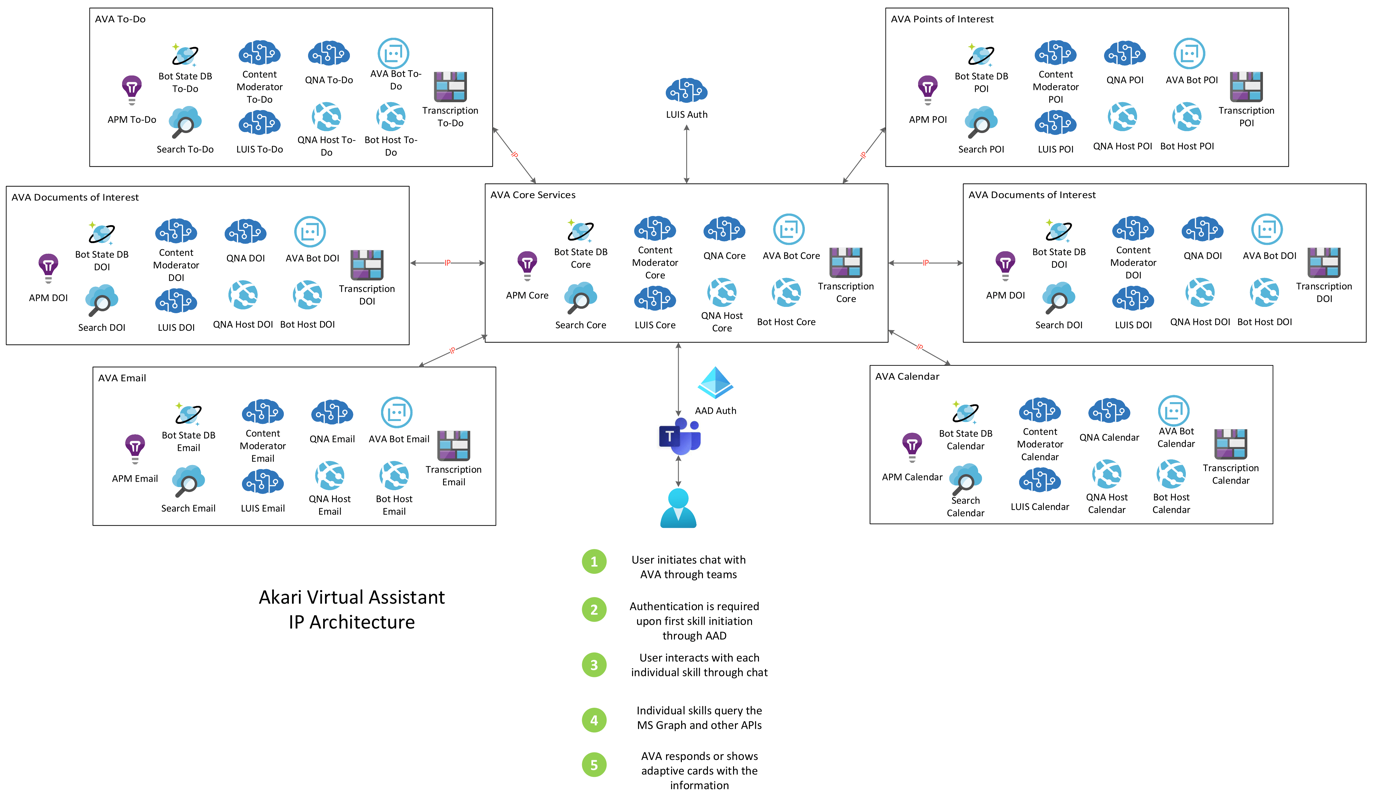
As you can see that’s a lot of resource sprawl, which with modern management tools and thorough tagging isn’t a large issue, as we could pull down or redeploy an environment fairly quickly using templates. But the cost of the above platform spiked and could be unpredictable depending on load and skills deployed within the platform. As we evolved our development methodologies and began looking deeper into DevOps/CI-CD, we quickly realised that with careful planning and monitoring across the stack we could consolidate nearly all of the resources above. Before we got to this stage though we had to plan out what AVA was to be, it could update your to-dos, send emails, show you information on entities within a database, or answer FAQ queries. We effectively had our first version or pilot product and customer testing taking place. It was around this time that we were accepted into the AI for Good program, which would ultimately steer how we built AVA moving forward. I had a fantastic 1-1 with the CTO of UK Startups within Microsoft, and very quickly got to the bottom of why AVA seemed to be ‘bloated’: it was because we wanted this assistant to truly be an assistant. This brings me straight back to what I said previously: know what you want to build. When looking at the Teams App Store (which was our primary channel for deployment), the apps were all designed to do one thing well, much like the apps on your phone. From an incredibly short period of internal consultation and assistance from the AI for Good program, we made the decision to slim down AVA and focus on some key areas around the value of the data being collected. Across a couple of hackathons we developed a pipeline model for extracting chatbot messages into meaningful content.
As the initial plan for AVA was to provide an inclusive and accessible solution, part of this was the data aspect. We knew (to some extent) what the chatbot experience would be but not the value that the collected data would provide. The initial data pipeline made use of Azure Data Factory and carried out the following
- Pulled all data from the transcription blob storage (we anonymized all chat data but gathered transcripts of each interaction, including system messages).
- Filtered the data based on user message type and excluded system messages.
- Deposited the output JSON files into a new blob container.
- Azure Search indexed this container for reporting and Cognitive Search.
This allowed us to identify chosen trigger words or phrases that may identify a group of users requiring assistance based on sentiment or opinion. At this stage of development we put this on the backlog whilst we dealt with the sprawling architecture.
The second lesson which I would tell myself back when starting all of this is: don’t be too concerned about retrying or rebuilding. The architecture above was stable if costly, and did provide us with an active platform. However, monitoring was difficult due to the separation of resources, and any updates were very carefully planned as code and feature updates effectively knocked the platform out for a period of time. This was in part due to our architecture. We started work on consolidating AVA on the following principles:
- App Services should live on the same App Service Plan unless there is a critical or feature-based reason not to.
- All data services should be consolidated into one key highly available resource such as multi-region Cosmos DB.
- AI and cognitive services should be consolidated as much as the platform will allow, for example all LUIS apps on one resource.
Over the course of two to three weeks we carefully unpicked and built out the new platform for AVA. We noticed an immediate cost difference, and through application insights we were gaining much better performance over cost for the platform we were using in production.
An aside to the final architecture would be that at this stage we strongly considered using using containers for building out the skills and core components of the bot. With a fair amount of research we decided against it as we didn’t need the portability of containers for the stack we were using; now if we were deploying AVA across clouds or using Azure Container Instances or Fargate that may have been a different story. The model for building out a scalable bot with its central services and skills would work well with a microservices architecture or deployment onto Kubernetes for independent scale of services and skills. We ultimately decided against this as with our development skillset and platform methodology we did not require the portability of containers, and for the most part Azure App Services required significantly less maintenance.
Moving into 2020
Now AVA as a whole wasn’t a major part of our servers to serverless journey, but it’s by far where we’ve made the most changes and learned how to manage an application at variable scale. As mentioned in the AVA overview section, AVA is a learning chatbot which can answer questions and provide users will wellbeing questions for actionable feedback at an organization level. Moving into 2020 this is our focus for development. The platform will only grow as customer organizations are onboarded and we gather feedback and metrics.
The two key parts of AVA are the bot and the management portal. The management portal is a React frontend authenticated with Azure Active Directory. This will allow us to directly integrate through AppSource as an entry point for customers rather than manually loading the bot as we were doing previously. The management portal is a standalone component with a web and API tier. The API tier is serverless through Azure Functions and allows for communication with the chatbot, as well as access to data primarily stored within Cosmos DB (our preferred database from day one due to performance). The chatbot component of AVA at its core hasn’t changed too much, even though it was fully rebuilt. The key framework is .NET Core through the Bot Framework, which allows for the immediate integration with Teams and use of features such as adaptive dialog and adaptive cards for displaying data within the chatbot/Teams interface. The core bot operates on an App Service that communicates separately to the Function App. This architecture will allow us to directly onboard customers via Microsoft AppSource rather than operate a manual or bespoke process for billing and onboarding.
ATS (Akari Translation Studio)
What is ATS?
Akari Translation Studio is a web application designed to make translating documents easier at scale. Where an organization might have bespoke software or a third party that translates documents, ATS was designed to break this barrier down by using custom language models built on top of the Microsoft Translate API to allow an end user to upload multiple documents and receive multi-language outputs quickly. These documents can then be scanned or corrected (where need be) in much less time by a professional or in-house translator. Alongside a web interface, ATS provides an API to carry out upload, translate and document management.
ATS plan and MVP
ATS was architected and built at the same time we were dedicating the majority of internal resource to AVA. As ATS is a completely different application to AVA it had its own architectural considerations and challenges. Our plan with ATS was a web interface in which a user could upload a document, choose a source and destination language pair and run the translation. The document would then be presented to the user for download. Authentication at this stage would be via a library and we had a plan to integrate Azure Active Directory at a later stage. The key difficultly with ATS was the requirement to handle documents and data at scale. This provided a unique challenge in that .docx files are not easy to handle without an Office install within your platform or a specific library designed to handle documents. After a period of research we picked a library and began development of the application. We were immediately constrained via the document handling as the most mature libraries at the time required .NET Framework over .NET Core, which led us down the path of deploying ATS onto IaaS VMs within Azure. At early stages of development this allowed us to quickly redeploy development and production environments based on templates and created a quick way for us to setup a mature CI/CD pipeline (Azure DevOps at the time).
MVP architecture
The core architecture for ATS was a web frontend built on React with a .NET Framework API running the backend for authentication, account management, translations, and document management. Inadvertently we had developed a system perfect for microservices with the constraint of framework and tooling. As the platform was built on virtual machines the architecture looked incredibly standard from a cloud perspective:
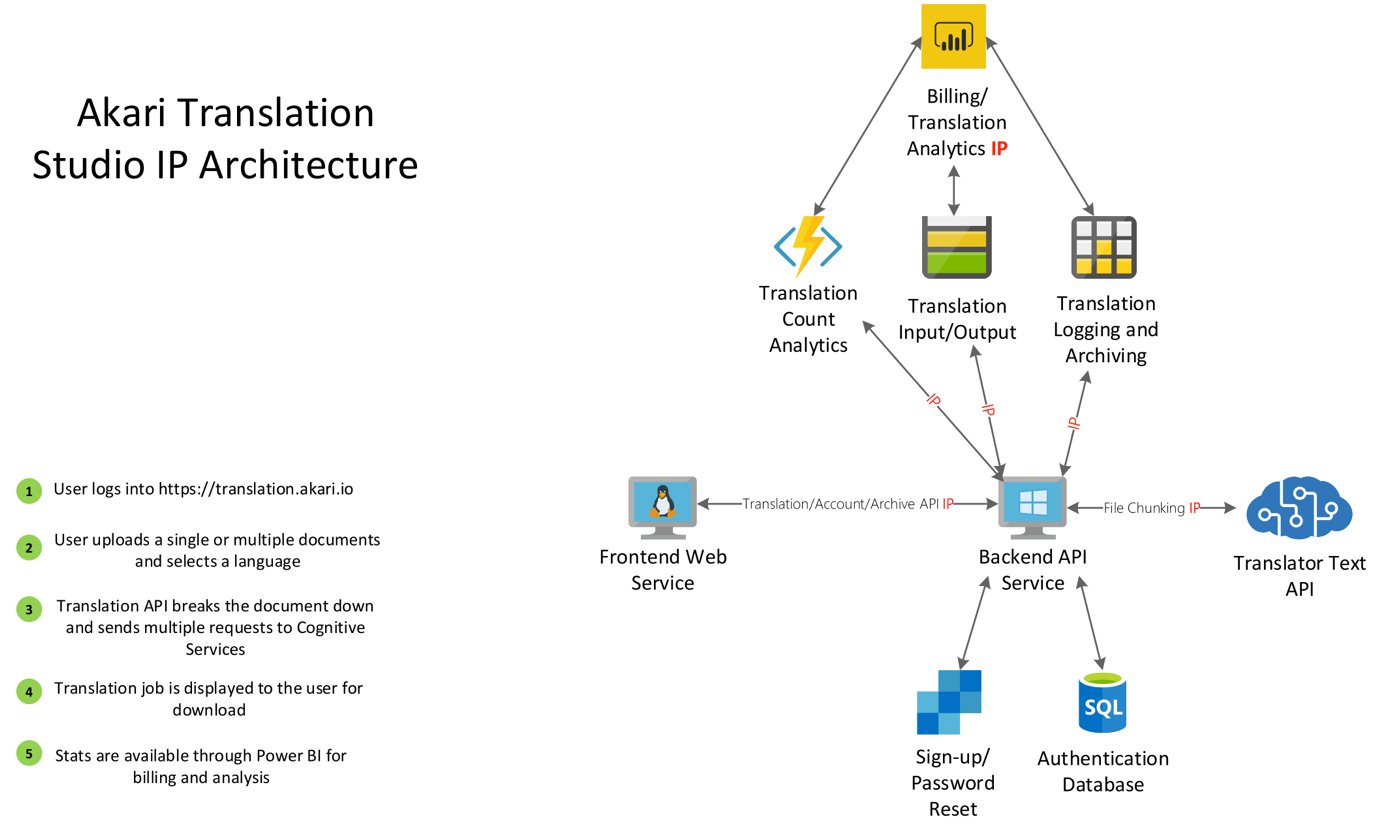
The initial MVP build was a NodeJS server operating the frontend, this allowed us to run the service at a very small scale for performance and cost in the early stages of development. The backend API server was more traditional, running IIS and connecting to Azure SQL for authentication and token management. Emails for sign up and password reset were operated through SendGrid, and the translation API was directly available through the API server connecting to Azure Cognitive Services. The above architecture did not carry a large cost and the key consideration at this stage was how to keep the platform highly available. The key lesson from ATS is: do not be afraid to start basic. It’s incredibly easy to get caught up in the current trends and releases within the development world, the architecture above got us off the ground quickly and cost effectively.
As ATS was further developed the Function App for translation analytics was developed, which allowed a user or organization to see the number of characters they had translated, which was the key billing metric at the time. Alongside table storage for archiving this data for internal billing reports, translation documents were stored within a blob container. The key developed component of the application was how we were able to strip chunks out of a .docx file for translating asynchronously.
Close to the end of 2019 the library that we were using announced .NET Core support and we immediately began a redesign of ATS to a serverless model. The entire API was rewritten into a serverless model hosted on Azure Functions. Each action that ATS could carry out, including password resets, account management, uploads/downloads, translations, and interface actions. was driven by an individual function. This made making changes to ATS incredibly easy, whereas previously when the API was updated a CI/CD pipeline would effectively redeploy the entire application onto the server and run a cleanup job, which could cause performance issues in production.
The frontend application was updated heavily with material design components and placeholders added for future functionality. The frontend is now hosted on an App Service Plan for low maintenance whilst the backend operates on premium functions to ease cold-start performance.
Ops and observability
We monitor applications at Akari through a couple of different methods. We decided to research and choose an observability platform early as well as define runbooks for operations and incidents so we could evolve these as the applications grew. Even though this was a slight additional cost early on in the development lifecycle, it has helped us immensely and I do believe that without correct monitoring tooling the applications and platform would not be where they are today. By choosing to monitor applications early in the development and production lifecycle we have a wealth of data, from code to platform issues, which we have learned from. It has allowed us to optimize the platform. Outside of the data we gather from the applications, having good observability saves a significant amount of time for troubleshooting and maintenance when new releases are deployed. The key lesson here is: pick a platform for monitoring and stick with it. If you’re of an appropriate scale, do the same with an overall ops tool for incident management. It is a day one cost depending on the vendor, but when you have your first production incident you will be thankful for it. There are a wealth of tools out there in the cloud world and the majority have a fantastic set of integrations. We use two at Akari: Datadog and Application Insights.
Application insights was a direct choice as it integrates out of the box with the Bot Framework and it is incredibly straightforward to pull in bot metrics and telemetry to the platform as well as analyze code-level metrics and spans. All of these metrics and errors are then integrated into Datadog for metric alerting and data gathering. We additionally use Datadog to monitor synthetics, API health and are looking to use APM in the future. At present we plan to run both due to the integration of Application Insights within Azure Functions. Being able to see direct execution metrics is incredibly powerful and we can alert on p50-p99 latency and error rates across the applications. As we grow our platforms and scale our applications out I envision our monitoring stack for ATS and AVA to be Application Insights > Datadog > Ops Platform (Microsoft Teams is doing this job just fine for ChatOps and specific alerts).
Cost and optimization
Cost optimization is key for any cloud deployment and as a startup it was a consideration we had mid-way through the development lifecycle. Principally due to the initial complex architecture of AVA we saw costs grow quickly due to testing and production releases of the platform, as well as lack of resource consolidation, which was a lesson learned.
As we only utilize Microsoft Azure for our deployments, monitoring cost is straightforward and we can make use of Azure Cost Management. This allows us to see cost growth based on a strict set of tags that we apply to each resource and resource group. We have a split production/development subscription set per product with tagging per tier alongside other metadata fitting into this. A lesson from day one is: monitor costs and set budgets. This might sound immediately obvious, but it is very easy to get carried away and deploy all sorts of tests, demos, and pilots within a cloud environment. Now this is also why cloud is so powerful, being able to create and destroy environments when appropriate and needed allows for strict management of dev/test costs and an open level of experimentation. The key considerations around cost we had were:
- If production, how much can we possibly optimize without adversely affecting performance?
- Do we really need a 24/7 development environment, can these be created as and when?
- How does our product pricing model fit around our cloud costs?
- How can we safely enable developers to create resources without spend issues?
Through careful management and monitoring of costs the above considerations are met. Cost monitoring is something that will not go away, although tools such as Cost Management make alerting and active monitoring significantly easier. With more services moving to a reserved model for cloud consumption outside of traditional compute services it will be interesting to see where this goes in the future.
Summary
When starting at Akari it was the first time I had ever run a team for a production platform that customers were actually going to be using. We’ve learned a lot of lessons along the way regarding cost, architecture, and general best practice. All are valuable lessons to take forward as we develop products and improve and iterate on our product stack. Not being afraid to try new architectures, rebuild and restart, and put in platforms for ops early all helped to build out the platform and certainly got us to where we are today.
In relation to pros and cons of serverless that is another article or debate, serverless for us is now a first consideration before we write any code. There are significant cost and operational benefits for a new organization or start-up to pick a cloud platform and move directly into the cloud-native space, over the past few years this certainly has been the direction of the industry with even large enterprise organizations moving towards the same model.
0 comments