

Enixta was started with the idea of reducing the time taken by people when researching a product that they wanted to purchase online. Hence came Buysmaart, a B2C portal for consumers to make purchasing decisions. The vision of Buysmaart is to help people choose smartly from the wide range of products available and not just buy.
We took the same underlying technology and applied it to:
eCommerce companies (Smaartpulse): The product eliminates confusion in the mind of a consumer arising from thousands of puzzling customer reviews. It shortens the purchase decision cycle time of consumers by generating actionable insights for products by organizing tons of customer reviews.
Brands and Manufacturers (Smaartbrand): We help extracts insights from customer voices across multiple channels (eCommerce, social media, discussion forums, etc.). These insights add tremendous strategic & tactical value to product offerings, customer experience, market research focus, and SEO strategy.
Unique selling proposition of Enixta Technologies
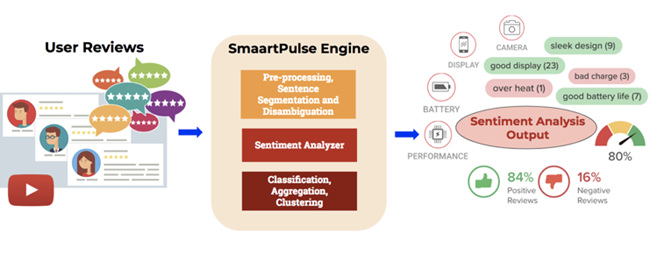
(Caption: converting user reviews with sentiment analysis)
Multi-Aspect Sentiment Analysis (Patent Applied): We extract information from user reviews converting data from millions of user reviews into numerical scores that indicate product quality. We extract highly accurate “aspect level sentiment scores” from reviews, placing a product in a multi-dimensional “aspect-space” rather than giving just an “overall rating”.
Comprehensive overview of products: We combine the sentiment scores (user feedback) with specification scores (manufacturer’s intent) – to provide a comprehensive product overview.
Aspect-Weighted Personalized Ranking (Patent Applied): We generate personalized ranking of products based on which aspect the user cares about more instead of just ranking products by “overall rating”. Different people have different needs and therefore, personalizing the search will surface only relevant products to enable fast and better buy decisions.
Why is it a good problem to solve?
User reviews have been a ubiquitous fixture ever since the advent of online commerce and user-generated content on the internet. They perform the very important function of informing consumers about the benefits/drawbacks of a product and help them decide whether (or not) to buy a product/service. However, the system of user reviews suffers from the following major drawback: Information overload: The volume of information available online has long surpassed the human mind’s capacity to process such information meaningfully.
Until now, methods to overcome this problem have centered around rating systems. While rating systems do provide a proxy for assessing the quality of a product at a snapshot, they have the following drawbacks:
- Lack of comprehensiveness: User ratings are merely a heuristic for product information, and they lack the richness, color, and depth of a complete user review.
- Lack of reliability: User ratings are more prone to manipulation than user-reviews since it is easier to submit a rating than to write an entire review, and it is easier for the end user to identify a fake review as against a fake rating.
What is the primary goal of Multi Aspect Sentiment Insights (MASI)?
A primary goal of the MASI is to identify the sentiments in individual statements of the document rather than just detecting the overall positive or negative sentiment of the subject. The existence of statements expressing sentiments is more reliable compared to the overall opinion of a document. The information in user reviews can easily be mined for insights by using the herein disclosed automated system, and these insights could be presented in an easily understandable graphical manner to the user – thereby allowing to instantly receive the full depth of knowledge and information about a product (as contained in its reviews), without having to manually process all the information.
What is the uniqueness of the problem?
People (customers, experts) don’t just write a review for an ENTITY (product, restaurant, university, movie, app, speech). They express opinions about different ASPECTS of the ENTITY. Aggregate rating does not capture the granular details of opinions expressed by the user . But in the review text, the user explicitly expresses opinions about different aspects independently. Hence, we need to extract which ASPECT the user likes and which s/he doesn’t, from the review blob. We need to go beyond the monolithic “overall rating” model of reviews.

(Caption: A sample of customer review)
Deep Dive of Enixta’s Technology
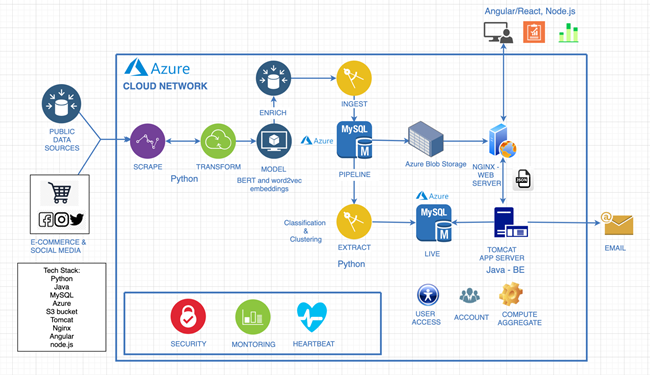
(Caption: Enixta’s high-level service architecture)
Data Scraping:
The first important step in Enixta Architecture is Scraping. We scrape data from more than 100 sources covering 100k+ skus carrying over 100M+ reviews. The data is collected from across the world in multiple languages from Social Media (Brand and Product chatter), eCommerce (Price, Reviews, Rating, Q&A), Expert reviews (Blogs) and Audio/Video Reviews. We tried writing the scraper in Java with Selenium but it was unable to handle scale. Hence, we started using Python which supports a good framework for Scraping. We use Scrapy framework for Crawling and Beautiful soup for parsing. URL requests modules are handled by urllib3. We use Facebook SDK, twitter API and YouTube API for social media webhooks.
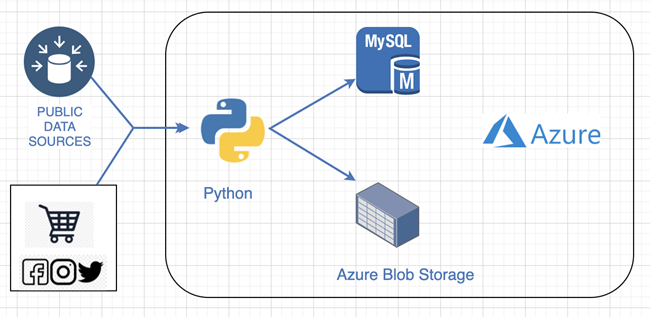
(Caption: Enixta’s data ingest process)
Training a Model:
The second most important step is training the MODEL. Scale is very crucial. We process around 4.5M reviews every day. We use spaCy and NLTK libraries for NLP modeling. BERT AND word2vec frameworks for word embeddings. Then we implement Hierarchical Density-Based Spatial Clustering of Applications with Noise for clustering, Hugging Face transformer for classification and our patented Multi aspect sentiment algorithm for generating sentiments.
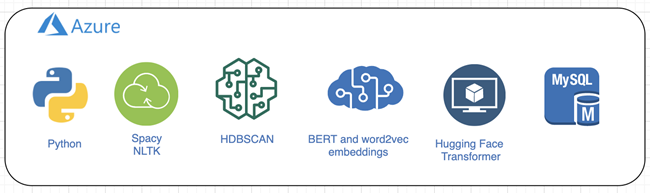
(Caption: Enixta’s machine learning process)
Our patented Multi aspect sentiment algorithm comprises of the following stages: Pre-processing (clean-up & embeddings), Extracting/Analyzing of reviews using sentiment engine, Aggregating/Annotating the output of sentiment engine analysis, and displaying the annotated output in a tree-map visualization.
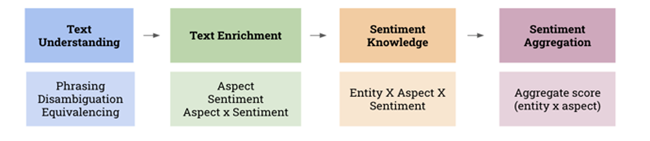
(Caption: Sentiment Analysis for Reviews – Thematic Flow)
The machine learning approaches for sentiment analysis on user reviews further comprises the steps of:
Step 1: Pre-processing of Reviews
Pre-processing of data is often a less appreciated part, but it is very important for the later stages.
-
Removal of duplicate reviews, e.g., remove multiple reviews which have the same review text and review id and belong to the same product.
-
Carrying out language identification to filter out the statements / sentiments which are not written in English.
-
Training a supervised classifier using Naive Bayes algorithm for sentence boundary detection and split the review to its individual sentences.
-
Tokenizing of the sentences to remove non-English characters, separate punctuation characters from words etc. Spelling correction of misspelled words is done.
Step 2: Extracting/Analyzing of reviews using sentiment engine
This step converts the unstructured data of reviews into structured data that can be used for the visualization. The machine learning techniques are used to do sentiment analysis of the user reviews.
Step 3: Aggregating/Annotating the output of sentiment engine analysis
At the beginning of this step, the generated list of reviews for each product that are grouped by sentiment polarity and attribute type.
Step 4: Displaying the annotated output in a tree-map visualization
The data thus annotated, is now ready to be displayed on a tree map visualization (see working examples as shown below.
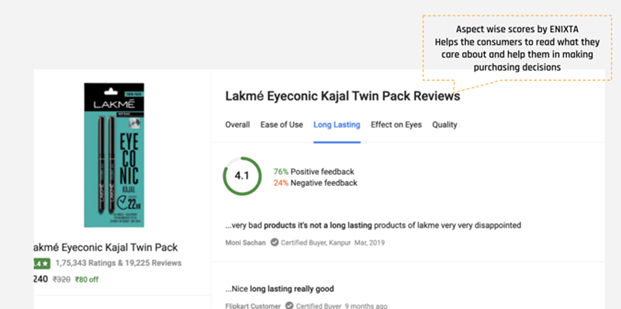
(Caption: Cosmetics example)
There are over thousands of reviews for each cosmetics product across various eCommerce websites. Each Cosmetics product can be considered as being composed of the following 4 attributes (A1 to A4) – Long Lasting, Ease of Use Effect on Eyes, Quality and Value for Money. The product reviews may describe one or more of the above attributes and may have a positive or negative polarity associated with it. Next each review is processed by the sentiment analysis algorithm which detects the said attributes per review and the associated polarity with those attributes. The final data set – with reviews grouped under attribute/polarity type is displayed as a tree map visualization. As a result, the entire information of the reviews is available in a single tree map that can be easily interpreted by users.
Granularity of ASPECTs:
We extract and aggregate ASPECT level Sentiment (aka Smaartpulse) scores from any collection of reviews. Aspects depend on product category (e.g., mobile phones, TV, cars, etc.) or entity type (e.g., movies, restaurants, vacation, Gaming apps, etc.)
-
E.g., Aspects for Phones: Display, Battery, Camera, Performance
-
E.g., Aspects for Laptop: Battery, Storage, Performance, Display
-
E.g., Aspects for Restaurants: Ambience, Food quality, Service, etc.
We can literally “place” an entity in its “multi-aspect-sentiment space”. Accuracy is 89% on coarse grain and 82% on fine grain reading.
Challenges in Mining Sentiment from Reviews:
A Review is a “mixture-of-opinions”: Contains more than one opinion in a review. It has multiple sentences, and a sentence can carry multiple opinions too.
An Opinion has precise structure: We assume that each opinion follows a precise structure – Opinion = entity X aspects X sentiment.
Language has Word Sense Ambiguity: This means that the same word can mean different things. e.g., Apple, Resolution, Flash, charge, etc.
Language has Paraphrasing: A same meaning can be communicated using different phrases or sentences. e.g., Battery is Good, Good Battery, etc.
Data Storage:
We use MYSQL 8.0. Our system data carries two different types. The first type of data is the Pipeline. This contains post processed and transformed raw data of around 100K+ skus and 100M reviews. The data is manipulated every hour and sized around 250GB. The 2nd data type is live data. It is processed and aggregated data and is ready to be consumed by the users. Its state is mostly static and synched from Pipeline every hour. critical product and brand data are cached to provide seamless fast service. The database is designed to scale easily by implementing Sharding. We use Azure telemetry for database monitoring. Our solution is a multi-cloud solution where we use both Azure Blob Storage or S3 Buckets for Content Delivery Network (CDN).
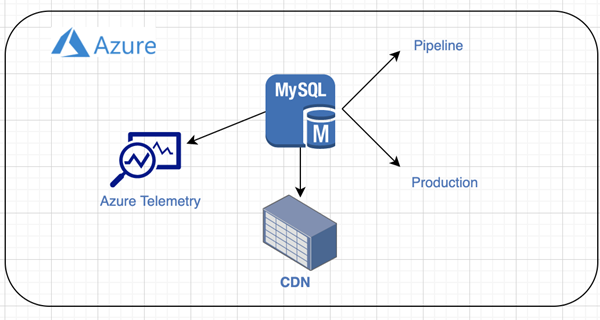
(Caption: Storage services Enixta uses)
SaaS Platform
Our backend uses Java for Rest APIs and Tomcat 9 for Web Server. User interface is rendered using Angular/React and charts are powered using anychart libraries (sample screenshot shown below of the Enixta’s SaaS platform).
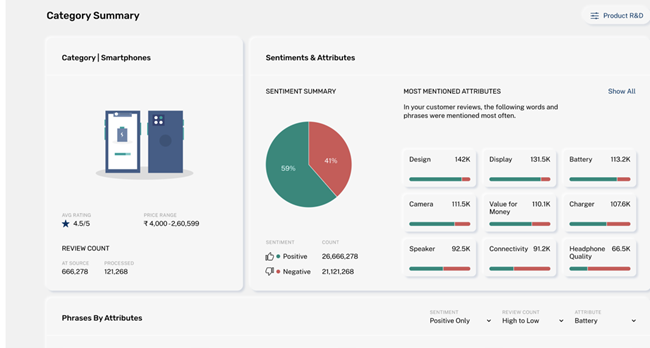
(Caption: Sample of Enixta’s sentiment analysis report from SaaS solution)
Enixta’s SaaS solution Smaartpulse is designed for eCommerce companies and Smaartbrand for Brands and Manufacturers that are available on the Microsoft Marketplace.
Conclusion:
Multi Aspect sentiment insights saves time for consumers, resolves information overload, and enhances user experience. Enixta technology is built using open source and home grown tools to make sure we are not tied to a particular cloud platform. Currently, The system can process product data from more than 200 categories spanning 100+ sources from multiple languages and can process 4.5M reviews per day. We have the ability to scale to 100M reviews per day if the need arises by mere sharding.
We are proud to say that we don’t have to carry any legacy data or system. We maintain everything up to date from Versions of the development tool to the database, everything runs on latest and the greatest.
0 comments