
The CorLife platform delivers clinical coaching via a mobile application to improve the wellbeing of the employees of our clients using clinically proven methods.
The mobile application integrates with wearable devices and smart scales from Garmin to collect biometric data from participants. Participants answer several questions about their medical history and behaviour as part of their onboarding journey.
The data collected from Garmin smart devices and a participant’s history is then used to build their wellbeing profile. The CorLife platform uses this profile to tailor coaching in the form of goals and activities for each participant. This coaching is delivered primarily through the CorLife mobile application supported by clinicians in the form of doctors, nutritionists and dieticians where required.
Technology overview
CorLife’s technology platform is built on Microsoft’s Azure Cloud platform. Wellbeing data from wearable devices is captured via Azure HTTP functions and Azure Event Hub and stored in Cosmos DB databases. The presentation layer comprises of a mobile app and internal portals developed using ReactJS.
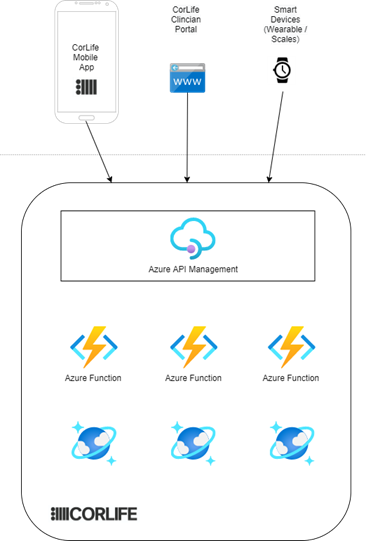
Objective
The question we were looking to answer is how we make use of the data in our Cosmos DB databases in the best possible way. There are several stakeholders that require some level of reporting from this data to help understand some of the following:
- How many participants have chosen goals and activities recommended by the mobile app?
- How many participants have successfully completed or failed goals and activities?
- What is the cumulative weight loss across the entire CorLife userbase or a specific client?
As a start-up, we do not want to create complicated, fragile and developer intensive processes to transform and query data from our Cosmos DB databases.
Giving our clinicians insight into customer data allows them to coach CorLife participants more effectively.
Options
We considered the following potential options; we discuss each of them below and explore the pros and cons of each:
- Using Power BI to query our Cosmos DB databases directly.
- Using Microsoft SQL Server’s JSON analysis capability.
- Using Azure Synapse Workspace and SQL on-demand via T-SQL views.
Option 1: Using Power BI to query Cosmos DB directly.
This option makes use of Power BI’s out of the box connector to talk to Cosmos DB. Further documentation on this approach can be found in this Microsoft article.
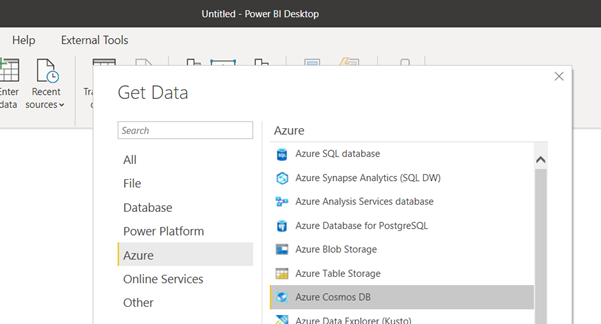
Pros
- Easy to get up and running with no additional cloud services required.
- The initial cost is low you just need Power BI licences.
Cons
- Querying Cosmos DB for analytical purposes is not optimal from a cost perspective.
- When used in the Import mode, Power BI will query your entire Cosmos DB every time it syncs. This means an additional load placed on your Cosmos DB databases.
- It is difficult to manage the JSON flattening when the hierarchy of the JSON gets more complex. The manual effort required in the data preparation stages is significant.
- Power BI transformations using the M Query language are difficult to place under source control. This has an impact on testability and add to CI/CD pipelines.
- Power BI does not support DirectQuery with Cosmos DB data sources. When using Power BI in the DirectQuery approach, any tables / graphs directly query the underlying data source. Whereas using the Import approach, Power BI queries a replica of the underlying data source(s). This means that, if you are visualising a simple graph with a handful of records almost all data from Cosmos DB is imported into Power BI using the Import approach.
- As the size of the data in your Cosmos DB databases increases, so will the load on Cosmos DB when Power BI conducts its daily synchronisation process.
- RU/s are used to read data, this will impact total costs and compete for compute resources with your transactional workloads.
- For time series analysis, you will need to maintain your data in Cosmos DB transactional store for longer periods.
Option 2: SQL Server JSON analysis capability
This option can be summarised below:
- This solution involves transporting the JSON document from Cosmos into a relational table of a Microsoft SQL Server database. The JSON is stored as plain text in a NVARCHAR column.
- A table is created for every Cosmos DB container.
- All tables are identical and contain a column for the primary key (id) and another which contains the unprocessed JSON (Body).
- The ID column maps to the built-in Cosmos DB “id” column.
- The Body column stores the raw JSON text from Cosmos DB.
- Simple T-SQL views can then be created to flatten the JSON in the Body column and present it as tabular records.
Pros
- You can exploit the full power of T-SQL and its ability to handle JSON.
- You are incrementally copying over modified records from Cosmos DB via the Cosmos DB change feed.
- The additional load on your Cosmos DB databases is small because the Cosmos DB change feed only adds newly added rows.
- Performance, the data is stored in a column format, the most optimal option for analytics.
Cons
- Cosmos DB change feed does not notify on physical deletes. Therefore, any record that gets hard deleted in Cosmos DB should also be deleted in the Microsoft SQL Server table.
- Additional code needs to be written and maintained using the Cosmos DB change feed API to keep both data stores in sync. E.g. a custom Azure HTTP trigger which does the incremental copying using the change feed and Azure Data Factory pipeline to schedule the invocation of the pipeline at regular intervals.
Option 3: Using Azure Synapse Workspace and Cosmos DB Analytical store
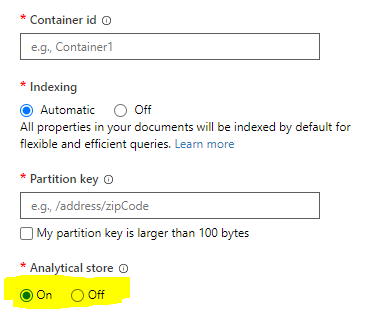
This solution requires two components:
- This solution requires you to enable Analytical Store Link on your Cosmos DB container(s)
- Use the on-demand SQL pool of Azure Synapse Workspace to connect to the Analytical Store.
We have also been in contact with the team at Microsoft who are developing Analytical Store link.
Pros
- Has all the benefits of MSSQL and its native JSON processing capabilities.
- You get automatic synchronisation between your Cosmos DB data and Analytical Store.
- The cost of this solution is smaller cost when compared to RU/s been used for analytics.
- For time series analysis, you will need to maintain your data in Cosmos DB for longer periods. With Analytical Store, you can keep your hot data for a small period and retain the data in Analytical Store, this is also significantly cheaper.
- Performance, the data is stored in a column format, the most optimal option for analytics.
Cons
- Enabling Analytical Store on your Cosmos DB containers can only be done at the time of Container creation. If you already have data in existing Cosmos DB databases, you will need to migrate data from them to newly created containers with the “Analytical Store” option enabled. Analytical store for existing containers will be released in Q2 / Q3 2021.
- If you need “real time” querying of your data is this a valid option?
Further exploration of Azure Synapse Workspace
We wanted to investigate using the Analytical Store option further and as a starting point we need to look at the data structures we might see in our Cosmos DB database.
NOSQL data structures
In this example we present a simplified representation of the data from one of the Cosmos DB containers
{
FirstName: "John",
LastName: "Doe",
Email: "john.doe@coll.com",
QuestionAnswers: [
{
questionid: "STARCHCONSUMPTION",
response: "1"
},
{
questionid: "PROTEINCONSUMPTION",
response: "2"
},
]
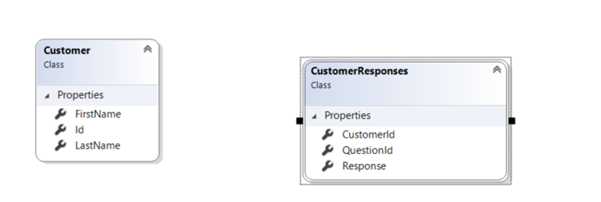
}The JSON in the above example demonstrates the end user’s responses to a questionnaire which is expected to be answered by every user. We want to be able to run SQL queries on the data from the example above and produce the table below in Power BI.
![]()
In this table, the custom JSON was flattened twice. First to produce a Customers table and a second time to produce a 1-many child table – CustomerResponses . 1 Participant has 1-many responses to questions.
Solution overview
- Use Cosmos DB analytical storage to create a copy of transactional data
- Use Azure Synapse SQL on-demand to flatten JSON
- Visualize data using Power BI to build reports
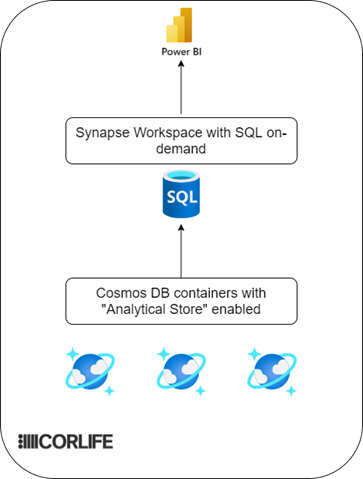
Flattening JSON
Once, the Customer document is linked with SQL on-demand pool in Azure Synapse, we can harness the power of T-SQL to produce 2 tables which are semantically related as shown.
CREATE VIEW vCustomers AS
SELECT
p.id,
p.firstname,
p.lastnamefrom OPENROWSET('CosmosDB', N'account=youraccount;database=yourcosmosdb;region=yourregion;key=******',
customers)
WITH(
id VARCHAR(100),
firstname VARCHAR(150),
lastname VARCHAR(150))
AS pFlattening the Customer Question responses
In this view we are reading the QuestionAnswers element of the Customer JSON and then using the CROSS APPLY SQL transformation to mimic an INNER JOIN thereby producing a tabular 1-many set of rows.
CREATE VIEW vQuestionresponses AS
SELECT
p.id,
JSON_VALUE(q.[value],'$.questionid') AS questionid,
JSON_VALUE(q.[value],'$.response') AS response
FROM
OPENROWSET (
'CosmosDB', N'account=yourdbaccountname;database=yourdbname;region=yourregion;key=******',
customers )
WITH(
id VARCHAR(100),
answers VARCHAR(MAX) '$.QuestionAnswers' ) AS p
CROSS_APPLY OPENJSON(p.answers) AS qModelling the data in Power BI
Power BI visualisations can become more intelligent if the underlying data has relationships. The relationships between various entities need to be created.
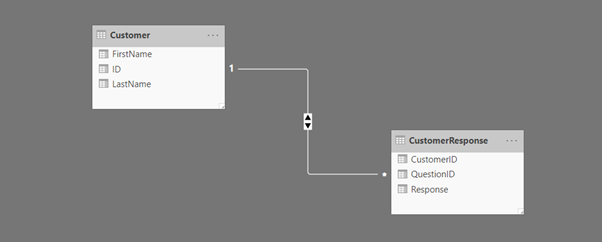
Summary
We have been exploring the technical options available to us if we want to query data from our Cosmos DB databases.
Based on our experience over the last six months, Cosmos DB Analytical Store link is a very promising development primarily because it provides some powerful features that can reduce the time spent transforming and updating data from Cosmos DB. This reduces the need to write code to do this ourselves allowing the team to focus on higher value tasks. The only unknown currently is concerning the cost of using this technology. Does the initial cost work for a start-up at the outset and more importantly over time is the use of the Cosmos DB Analytical Store with larger data volumes still cost effective?
Reference
1. JSON Path expressions in SQL Server
2. MSSQL – Bridging between between NoSQL and SQL Worlds
4. Power BI — Differences between Import and DirectQuery modes
Really great guide for using the Cosmos DB. Thanks Ravi! Also agree with you about these articles JSON Path expressions in SQL Server page Power BI — Differences between Import and DirectQuery modes, very powerful guides
Cool article. But I prefer the alternative to the Cosmos DB program – Fluix. We have recently implemented Fluix – https://fluix.io/industry-construction in our office, and have already noted the advantages of working with it. Also, this software has a very convenient ability to create annotations while working with drawings. Our company is engaged in construction, so this is especially important for us. Now our team sees every bit of information and every change made to the file, and this greatly simplifies the workflow.