

Another day, another update from the Semantic Kernel team on OpenAI Assistants! For this article, we wanted to dive into assistant instructions, the key element in the Assistant API that allows you to give assistants their own persona.
With the existing OpenAI API, instructions are typically static. You define them once for an assistant, and then they’re reused whenever an assistant answers a thread. You can, however, override the instruction every time you create a new run of a thread.
 A screenshot of the OpenAI API docs for creating a new run of a thread.
A screenshot of the OpenAI API docs for creating a new run of a thread.
We’ve taken advantage of this request parameter to make it possible for you as a developer to templatize your instructions. This lets you predictably inject additional information to your assistant whenever it runs a thread. For example, you may want to develop a Product Expert assistant that can answer questions about a piece of inventory using injected product data.
Creating a product expert assistant: before and after
With the existing Assistant’s API, you could 1) create an assistant per product, 2) upload the relevant files, and 3) use the retrieval tool to get product information. This would be very time consuming, so alternatively, you could also define a function that lets the expert retrieve details about a product via function calling. In both cases, however, you need to spend tokens (and time) so the LLM can retrieve data first before generating messages.
We call this Dynamic RAG.

Dynamic RAG has its time and place, especially when you have a lot of data and it’s unclear what should be included in the context window.
If, however, you already know what data you need, you could templatize this request and require it for every use of the assistant. This lets you save tokens, speed up responses, and make your assistants more deterministic.
For example, if you know the ID of a product before chatting with an assistant, you could use that information in a template to automatically retrieve all product information so you don’t need to rely on the models to retrieve it for you. Below is an example of what the Product Expert template could look like.
You are a helpful assistant that provides answers about {{getProductName productId}}.
If you receive any questions that are about a different product, politely decline to answer them.
These are the full details of the product.
{{json (getProductDetails productId)}}We call this templated RAG and where Semantic Kernel can uniquely help.
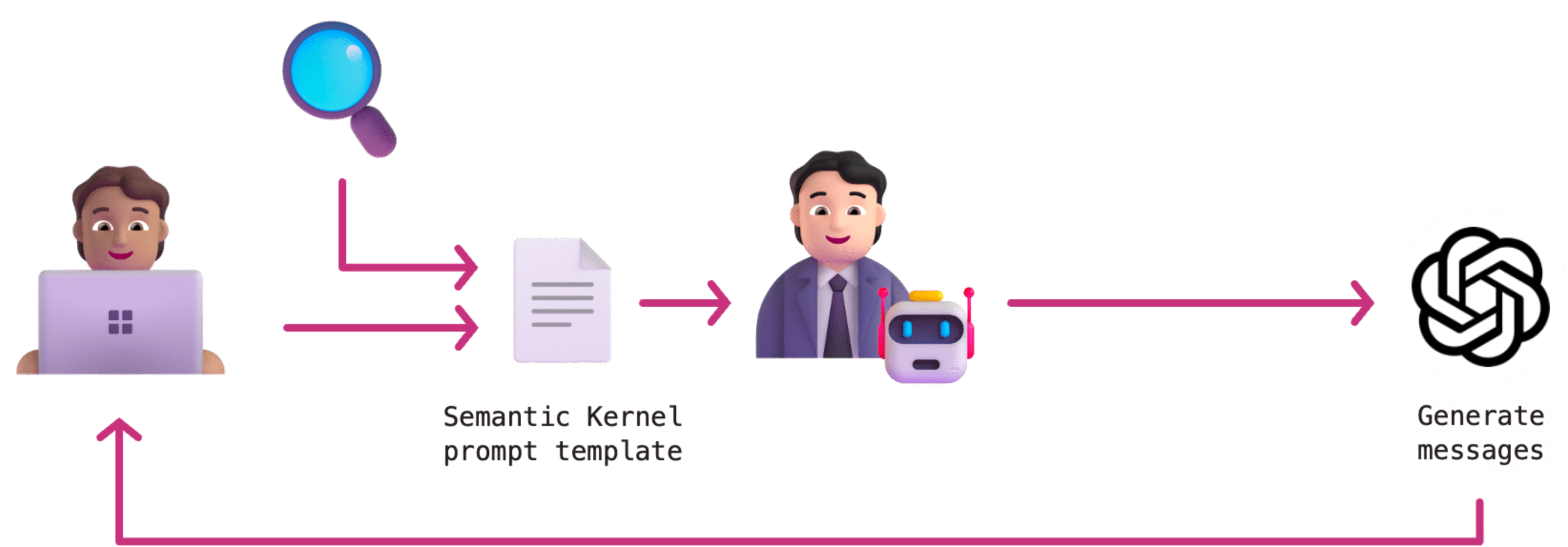
Notice how with a template, we can instantly call the API without waiting for OpenAI to tell us to do so. The Assistant can then use this information to instantly create messages (or have better context to call the next required functions).
Semantic Kernel makes this possible because it has template support out-of-the-box. Today, we offer Handlebars and if you want to add your own (e.g., Liquid or Jinja2) you can author your own prompt template factory. Not only can you templatize API calls, but you can also add requests to other models (including local and non-OpenAI models), requests to vector databases, and more!
Watch us use templated prompts with assistants.
To see how templates and assistants intersect, we recommend watching the latest demo video we created. In the video, we show the initial value of assistant instructions before demonstrating how you’ll soon be able to templatize them with Semantic Kernel.
Take a look at our prototype
If you’re excited to see the sample code, you can look at our very early prototype in our v1 proposal repo. It still has some polishing to go through, so don’t be surprised if it’s a bit buggy at first. The team is now refining the implementation so we can bring it into the main branch of Semantic Kernel.
Once it’s in, I’ll share another blog post that walks through how to use the SDK in more detail.
Have feedback?
We’ve already gotten great feedback on our proposal to integrate assistants into our SDK. If you have additional thoughts, consider sharing them with us there!
Amazing work team! I can’t wait to try Assistants