

Today we’re excited to welcome Jarre Nejatyab as a guest blog to highlight a technical deep dive on orchestrating AI Agents with Semantic Kernel Plugins.
In the rapidly evolving world of Large Language Models (LLMs), orchestrating specialized AI agents has become crucial for building sophisticated cognitive architectures capable of complex reasoning and task execution. While powerful, coordinating multiple agents—each with unique capabilities and data access—presents significant engineering challenges. Microsoft’s Semantic Kernel (SK) offers a robust framework for managing this complexity through its intuitive plugin system. This blog post provides a technical deep dive into leveraging SK plugins for effective agent orchestration, illustrated with practical implementation patterns.
The Challenge of Agent Orchestration
Modern AI applications often transcend the capabilities of a single LLM. They increasingly rely on ensembles of specialized agents working in concert. For instance, a query might require input from an agent accessing internal policy documents, another searching the public web, and a third querying a private database. The core challenge lies in:
- Dynamically selecting the right agent(s) for a given task.
- Managing context and data flow between agents.
- Synthesizing potentially conflicting outputs into a coherent final response.
- Maintaining modularity and observability as the system scales.
Semantic Kernel Plugins
Semantic Kernel’s plugin architecture provides a structured solution. Plugins act as standardized wrappers around agent capabilities, enabling the kernel (the central orchestrator) to discover, invoke, and manage them effectively. Key benefits include:
- Modular Agent Integration: Encapsulate each agent’s logic within a dedicated plugin.
- Declarative Invocation: Define agent capabilities with clear descriptions, allowing the kernel’s LLM to dynamically choose the appropriate tool(s) based on the user query and context.
- Unified Interface: Standardize communication, simplifying interactions between the orchestrator and diverse agents.
- Centralized Monitoring: Track resource usage (like tokens) and execution flow across all agents.
- Simplified Result Aggregation: Provide hooks to combine outputs from multiple agents into a cohesive final response.
Architecture Overview
Let’s examine a conceptual architecture for an orchestration system using SK plugins:
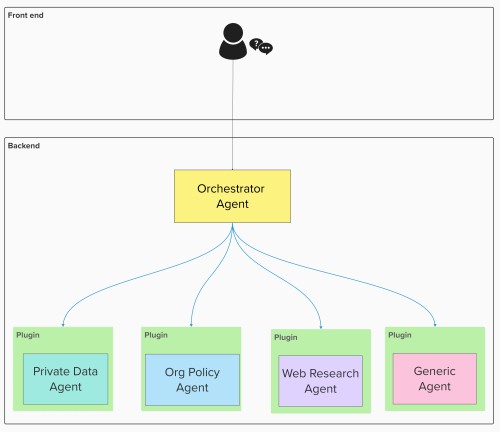
This architecture features:
- A central Orchestrator Agent, powered by Semantic Kernel, receiving user queries.
- Multiple Specialized Agent Plugins, each exposing the capabilities of a specific agent (e.g., Web Search, Org Policy Lookup, Private Data Query).
- A Plugin Registration mechanism making agent capabilities discoverable by the kernel.
- Result Aggregation logic within the orchestrator to synthesize a final answer. The kernel uses the descriptions provided within each plugin (via decorators like
@kernel_function) to determine which plugin(s) are relevant to the user’s query, enabling dynamic and context-aware agent invocation.
Implementation Example
Consider this simplified Python implementation of an orchestrator agent using the Semantic Kernel SDK:
class OrchestratorAgent:
async def invoke(self, message: ChatMessage, context: Context) -> ChatResponseMessage:
# 1. Set up the system prompt guiding the LLM orchestrator
self._history.add_system_message(self.system_prompt)
self._history.add_user_message(message.user_query)
# 2. Initialize specialized agent plugins
org_policy_agent_plugin = OrgPolicyAgentInvokingPlugin(kernel=self._kernel, message=message)
web_search_agent_plugin = WebSearchAgentInvokingPlugin(kernel=self._kernel, message=message)
private_data_agent_plugin = PrivateDataAgentInvokingPlugin(kernel=self._kernel, message=message)
generic_agent_plugin = GenericAgentInvokingPlugin(kernel=self._kernel, message=message) # Fallback agent
# 3. Register plugins with the kernel, providing descriptive names
self._kernel.add_plugin(org_policy_agent_plugin, plugin_name="ORG_POLICY_AGENT")
self._kernel.add_plugin(web_search_agent_plugin, plugin_name="WEB_SEARCH_AGENT")
self._kernel.add_plugin(private_data_agent_plugin, plugin_name="PRIVATE_DATA_AGENT")
self._kernel.add_plugin(generic_agent_plugin, plugin_name="GENERIC_LLM_AGENT")
# Configure the kernel to automatically invoke functions based on the prompt and plugin descriptions
# execution_settings = ... # Configure execution settings, e.g., FunctionChoiceBehavior.Auto()
# 4. Invoke the kernel. The underlying LLM uses the prompt and function descriptions
# to decide which plugin functions to call (sequentially or in parallel).
results = []
# Assuming self._sk_agent uses the configured kernel and execution settings
async for content in self._sk_agent.invoke(self._history): # Potentially involves multiple plugin calls
results.append(content)
# 5. Aggregate results from all potentially invoked plugins
# (Plugins should track their own invocation status and results)
agent_invoking_plugins = [
org_policy_agent_plugin,
web_search_agent_plugin,
private_data_agent_plugin,
generic_agent_plugin
] # List of all potential plugins
# 6. Calculate total token usage across invoked plugins
# (Requires plugins to expose usage data)
total_prompt_tokens = sum(plugin.token_usage.prompt_token for plugin in agent_invoking_plugins if plugin.was_invoked) # Example: Check if invoked
total_completion_tokens = sum(plugin.token_usage.completion_token for plugin in agent_invoking_plugins if plugin.was_invoked)
# 7. Compile search results/citations from invoked plugins
# (Requires plugins to expose relevant results)
search_result = SearchResult(docs=[], citations=[])
for plugin in agent_invoking_plugins:
if plugin.was_invoked: # Example: Check if invoked
search_result.docs.extend(plugin.search_result.docs)
search_result.citations.extend(plugin.search_result.citations)
# 8. Return the consolidated response (likely the final LLM synthesis from step 4)
final_content = results[-1].content if results else "Could not generate a response."
return ChatResponseMessage(
content=final_content,
search_result=search_result,
token_usage=TokenUsage(
prompt_token=total_prompt_tokens,
completion_token=total_completion_tokens,
),
)
# Note: Requires AgentInvokingPlugin base class to define/manage
# token_usage, search_result, was_invoked attributes, etc.
This example highlights how plugins are registered and how the kernel orchestrates their execution, followed by result aggregation. (Note: Error handling and detailed state management are omitted for brevity).
Anatomy of an Agent Plugin: WebSearchAgentInvokingPlugin
Let’s examine the WebSearchAgentInvokingPlugin more closely.
# Assumes AgentInvokingPlugin base class handles kernel, message, runtime, etc.
class WebSearchAgentInvokingPlugin(AgentInvokingPlugin):
@kernel_function(
name="invoke_web_search_agent",
description="""WebSearch plugin. Use this to answer questions requiring current, public information, such as:
- General knowledge questions or facts (e.g., 'What is the capital of France?')
- Current events, market data, or industry trends (e.g., 'Latest stock price for MSFT?')
- Technical information likely found online (e.g., 'How to configure a Flask server?')
- Information published in academic papers or public industry reports.""",
)
async def invoke_web_search_agent(
self,
query: Annotated[str, "The specific question or topic to search the web for. Should be self-contained."],
):
"""Invokes the external Web Search Agent."""
# self.was_invoked = True # Mark as invoked
message_body = self.create_message_body(query) # Prepare agent-specific message
recipient = AgentId(WEBSEARCH_AGENT, str(self.message.metadata.session_id)) # Target agent
# Send message via runtime and await response
result = await self.runtime.send_message(message=message_body, recipient=recipient)
# Process result, update internal state (token usage, search results), and return
processed_response = self.proccess_and_create_response(result)
# self.token_usage = ... # Update token usage based on result
# self.search_result = ... # Update search results based on result
return processed_response # Return processed data, often just a summary string for the orchestrator LLM
Key aspects enabling orchestration:
1. Clear Domain Boundaries via @kernel_function
The description parameter in @kernel_function is crucial. The orchestrator LLM uses this natural language description to understand when to use this specific plugin. A well-crafted description significantly improves the accuracy of dynamic function calling.
2. Informative Parameter Signatures with Annotated
Type hints (str) and Annotated descriptions ("The specific question...") provide further context to the LLM, helping it formulate the correct input (query) for the function based on the overall user request.
3. Encapsulated Agent Communication Logic
The plugin abstracts the details of interacting with the specific agent (creating messages, identifying recipients, handling runtime communication). The orchestrator only needs to know about the high-level invoke_web_search_agent function.
4. Standardized Result Processing
The proccess_and_create_response method (part of the base class or implemented here) normalizes the agent’s raw output into a format the orchestrator expects. It also updates shared state like token counts and extracted citations, essential for the final aggregation step.
Hierarchical Plugin Structure
Semantic Kernel supports organizing plugins hierarchically, which can mirror complex agent interactions:
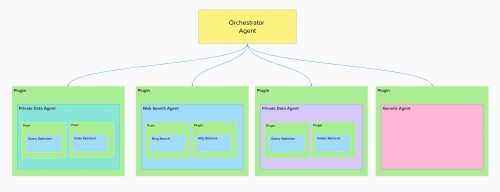
An AgentInvokingPlugin might internally use other, more granular plugins (e.g., a BingSearchPlugin or an HttpRequestPlugin). This allows for composition and reuse of lower-level functionalities within the agent abstraction.
The Power of Plugin-Based Orchestration
This SK plugin approach yields significant advantages:
1. Dynamic & Context-Aware Agent Selection
The kernel’s LLM acts as the intelligent router, using function descriptions and conversation history to select the most relevant agent(s) for each turn or sub-task. The system_prompt guides this selection process:
# Example system prompt snippet for the orchestrator LLM
system_prompt = """You are an AI assistant orchestrating specialized agents. Analyze the user query.
Based on the query and the descriptions of available tools (plugins), select the most appropriate tool(s).
Available tools:
- ORG_POLICY_AGENT: Use for questions about internal company policies and procedures.
- WEB_SEARCH_AGENT: Use for current events, public facts, and general web knowledge.
- PRIVATE_DATA_AGENT: Use for queries requiring access to internal databases (e.g., sales figures, user data).
- GENERIC_LLM_AGENT: Use as a fallback for general conversation or if no other tool is suitable.
Invoke the chosen tool(s). If multiple tools are needed, plan their execution. Synthesize their outputs into a final, comprehensive response.
"""
2. Flexible Execution Flows (Parallel/Sequential)
SK supports different function calling modes. You can configure the kernel to:
- Invoke multiple plugins in parallel if their tasks are independent.
- Chain plugin calls sequentially if one agent’s output is needed as input for another.
- Allow the LLM to automatically decide the best execution strategy.
3. Unified Resource Monitoring
By having plugins report their token usage and execution time back to the orchestrator, you gain centralized visibility into costs and performance bottlenecks across the entire multi-agent system.
Implementation Patterns
1. Base Class for Agent Invocation Plugins
Create a base class to handle common logic like kernel/message storage, runtime access, state tracking (invocation status, token usage, results), and result processing.
from semantic_kernel.kernel_pugin import KernelPlugin
# ... other imports ...
class AgentInvokingPlugin(KernelPlugin):
def __init__(self, kernel, message, runtime):
self.kernel = kernel
self.message = message
self.runtime = runtime # Agent communication runtime
self.token_usage = TokenUsage(prompt_token=0, completion_token=0)
self.search_result = SearchResult(docs=[], citations=[])
self.was_invoked = False
# Potentially add abstract methods for processing results, etc.
def create_message_body(self, query: str) -> dict:
# Standardize message creation
pass
def proccess_and_create_response(self, agent_result: dict) -> str:
# Standardize response processing, update state (tokens, results)
# Returns a string summary suitable for the orchestrator LLM
pass
def get_summary(self) -> str:
# Return a summary of results if invoked
pass
# ... other common methods ...
2. Descriptive Plugin and Function Naming
Use clear, descriptive names for plugin registration (plugin_name="WEB_SEARCH_AGENT") and kernel functions (@kernel_function(name="invoke_web_search_agent", ...)). This aids both the LLM’s understanding and human debugging.
3. Explicit Function Choice Configuration
Leverage FunctionChoiceBehavior (or similar mechanisms in the specific SK SDK version) to control how the LLM selects and executes functions (e.g., Auto for dynamic selection, Required to force a specific function call).
Best Practices for Agent Orchestration with SK Plugins
- Rich Function Descriptions: Write detailed, unambiguous descriptions for
@kernel_function. This is paramount for accurate dynamic routing. - Clear System Prompts: Guide the orchestrator LLM on the overall goal, available tools, and how to choose between them.
- Standardized Inputs/Outputs: Design plugin functions to accept simple inputs (like strings) where possible and return standardized, predictable outputs (or update state predictably).
- Robust Error Handling: Implement try/except blocks within plugin functions and report errors clearly back to the orchestrator.
- Comprehensive Telemetry: Log key events (plugin invocation, agent requests/responses, errors, timings) for monitoring and debugging. Use correlation IDs.
- State Management: Carefully manage shared state (like conversation history) passed to plugins and how plugins update aggregated results (tokens, citations).
- Observability First: Design plugins with logging and metrics in mind from the outset. Track token usage per plugin/agent.
- Agent Contract Testing: Implement tests for each plugin, mocking the underlying agent, to ensure it adheres to its expected interface and behavior.
- Idempotency Considerations: If agents might be retried, consider designing their actions to be idempotent where possible.
- Circuit Breakers: Implement resilience patterns like circuit breakers for calls to external agents that might be unreliable or slow.
Conclusion
Semantic Kernel plugins offer a powerful and structured approach to the complex challenge of AI agent orchestration. By encapsulating agent capabilities within a standardized plugin framework, developers can build sophisticated multi-agent systems that benefit from:
- Modularity: Easier development, testing, and maintenance.
- Dynamic Routing: Intelligent, context-aware selection of specialized agents.
- Scalability: A clear pattern for adding new agent capabilities.
- Observability: Centralized monitoring of performance and resource consumption.
As AI applications increasingly rely on collaborative ensembles of specialized agents, mastering plugin-based orchestration frameworks like Semantic Kernel will be essential for building the next generation of intelligent, capable, and maintainable systems.
References:
This blog post targets software engineers familiar with LLM concepts and agent-based architectures. Code examples are illustrative and simplified; production systems require more extensive error handling, configuration, and state management.
0 comments