


On Monday, we shared that the future of Semantic Kernel will leverage OpenAI Assistants so you can take advantage of the ease-of-use they provide in creating agents and copilots.
In this blog post, we wanted to pick up where we left off and share an incremental update on our current progress while also diving into some of the scenarios we want to enable once we’ve launched the integration.
So without further ado… check out this recorded demo of us using assistants with Semantic Kernel! In the demo, you’ll see just how easy it’ll be to update an existing Semantic Kernel v1.0 project from a standard kernel to an assistant kernel.
As you likely saw from the video, we’re able to use the Semantic Kernel SDK to let users chat with an entire team of agents. This functionality has been highly influenced by the work pioneered by the Autogen team. With their framework, they’ve shown that multiple agents can be better than one.
For example, when you use a single assistant, you must give it all your plugins and memory so it can answer any request by a user. This, however, can be too much for a single assistant to handle. Plus, it becomes difficult to evaluate that a monolithic agent can actually work across such a large domain.

Instead, you can create individual assistants for each of your domains by giving them specialized plugins and memories. In the picture below, we show how you could have a single Project Manager agent that coordinates requests between the user and the rest of the team–in this case, a scientist, artist, and investigator.
We call this a hierarchical chat.
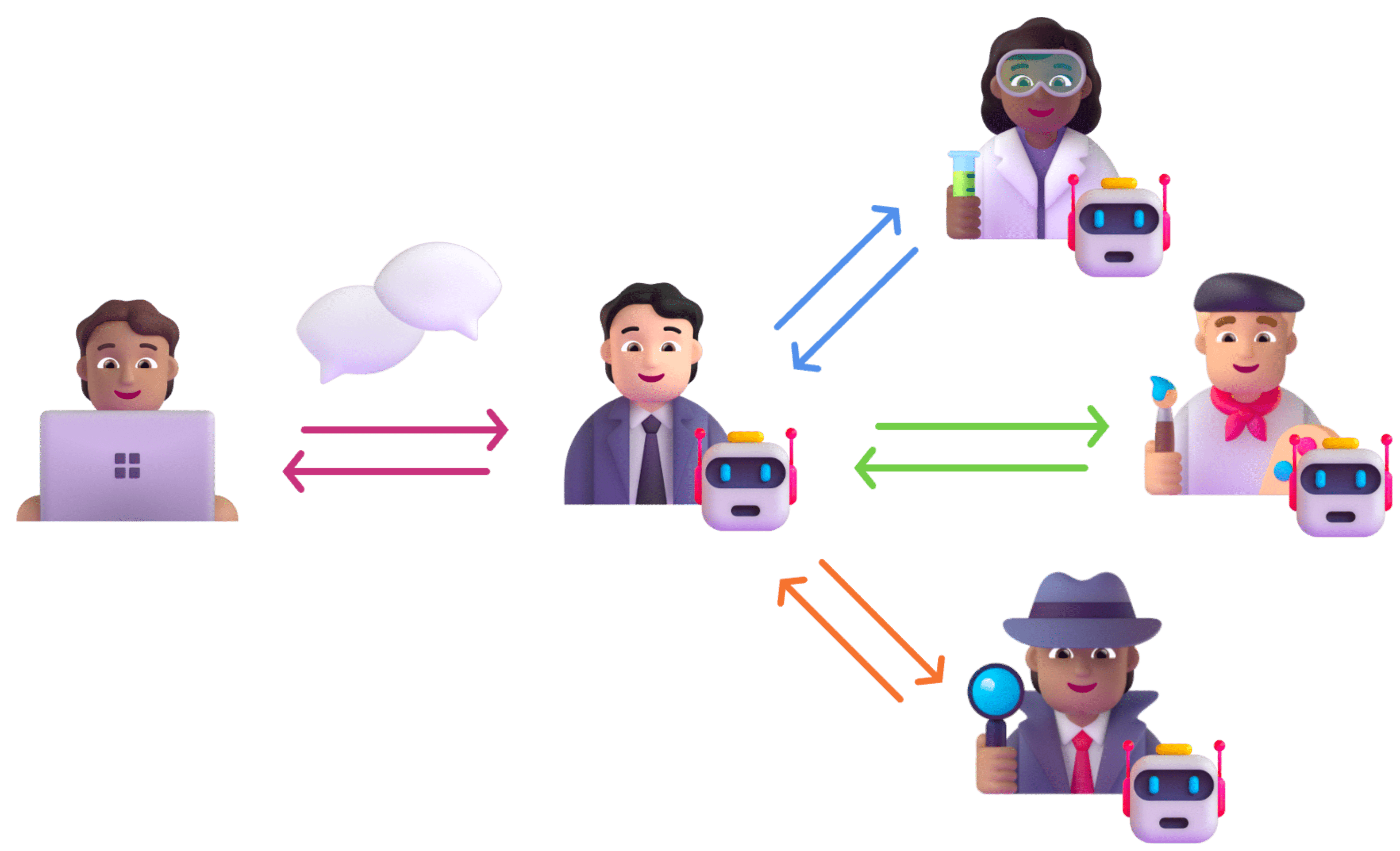
With plugins, we’ll make it extremely easy to model a hierarchical structure like this. The benefit of this approach is that the project manager agent can make parallel requests to multiple agents. For example, the product manager agent may want to simultaneously get scientific, artistic, and investigative insight to answer a user’s request.
The challenge with this approach, however, is that the user must wait for the product manager to relay any information it receives from its team.
Because of this, we’re also in the process of implementing a solution that allows all agents to speak on the same thread. This is very similar to what Autogen does today. By sharing a thread, all assistants instantly have awareness of what was said elsewhere, and the sub-assistants can directly communicate with the user.
We call this a joint chat.
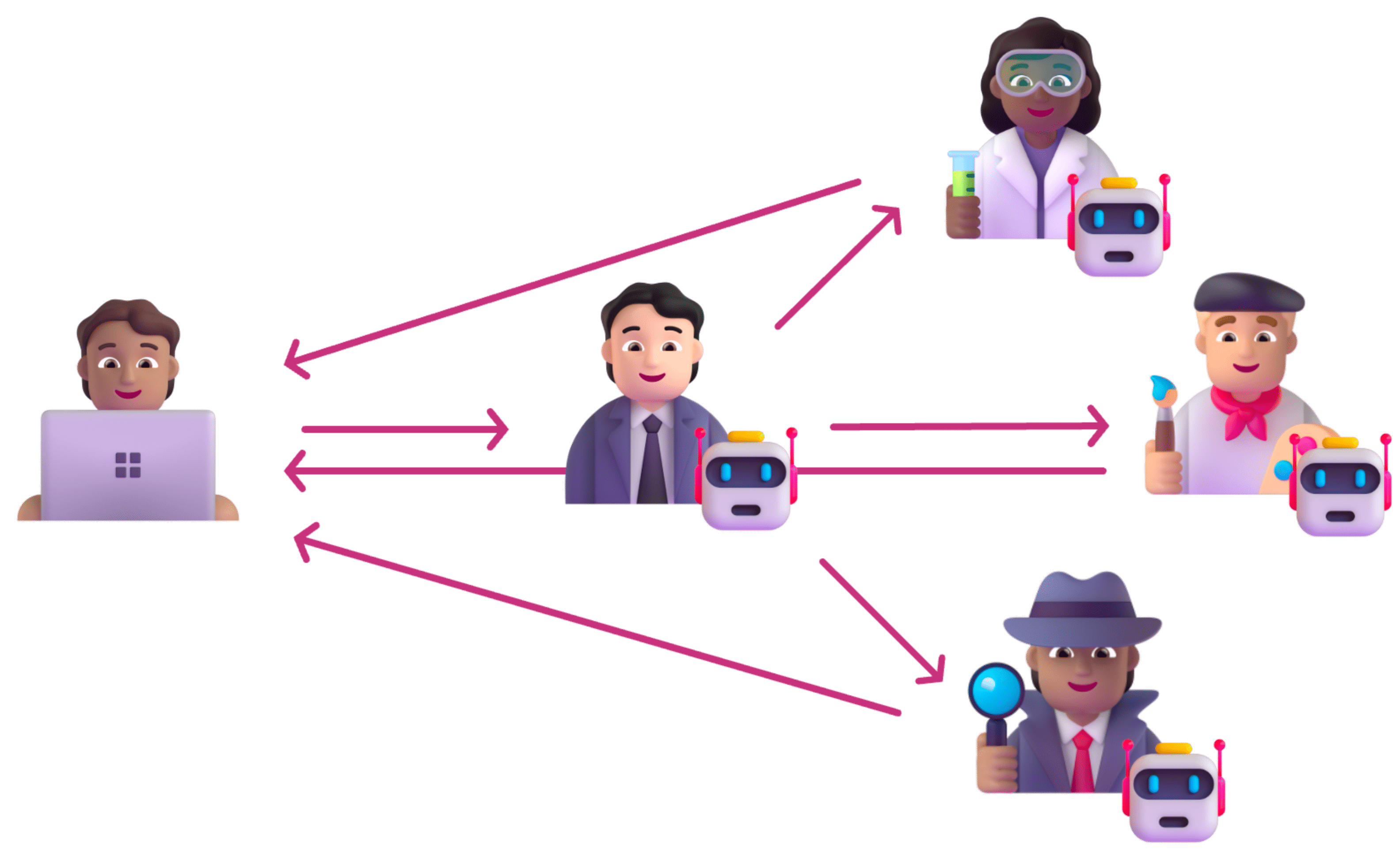
This is just like a live Teams meeting. You can have faster collaboration, but each person can only speak one at a time–therefore its more difficult to parallelize than hierarchical chat.
The pros and cons of the two approaches mirror how people collaborate in businesses as well. For highly distributed tasks, having an org hierarchy is helpful (you wouldn’t want an entire company on the same Teams call!) while other tasks are best hammered out over a meeting.
As research in this space grows, the choice of which method to choose (and when) will become more clear, but in the meantime, the Semantic Kernel team believes that both will have an important part to play in orchestrating agents, so we want to make sure both routes are extremely easy to create with our SDK.
Take a look at our prototype
If you’re excited to see the sample code, you can look at our very early prototype in our v1 proposal repo. It still has some polishing to go through, so don’t be surprised if it’s a bit buggy at first. The team is now refining the implementation so we can bring it into the main branch of Semantic Kernel.
Once it’s in, I’ll share another blog post that walks through how to use the SDK in more detail!
Have feedback?
We’ve already gotten great feedback on our proposal to integrate assistants into our SDK. If you have additional thoughts, consider sharing them with us there!
0 comments