
Hey Python community! It’s been a while since we’ve last posted about this, but we’re excited to present new capabilities we’ve added to the VS Code Azure Machine Learning (AML) extension. From version 0.6.12 onwards we’ve introduced UI changes and ways to help you manage Datastores, Datasets, and Compute instances all from directly within your favourite editor!
We’re guessing many of you may be reading about Azure ML and the extension for the first time – don’t worry, we’re here to explain!
Azure ML is a machine learning service that provides a wide set of tools and resources for data scientists to build, train, and deploy models. The AML extension is a companion tool to the service which provides a guided experience to help create and manage resources from directly within VS Code. The extension aims to streamline tasks such as running experiments, creating compute targets, and managing environments, without requiring the context-switch from the editor to the browser. Extensions users are enabled to work across their workspaces and interact with their core AML assets via an easy-to-navigate tree view and single-click commands.
You can learn more about getting started with the Azure ML service here. If you’d like to experiment with the extension, you can install it here and read the getting started documentation here!
Datastore Integration
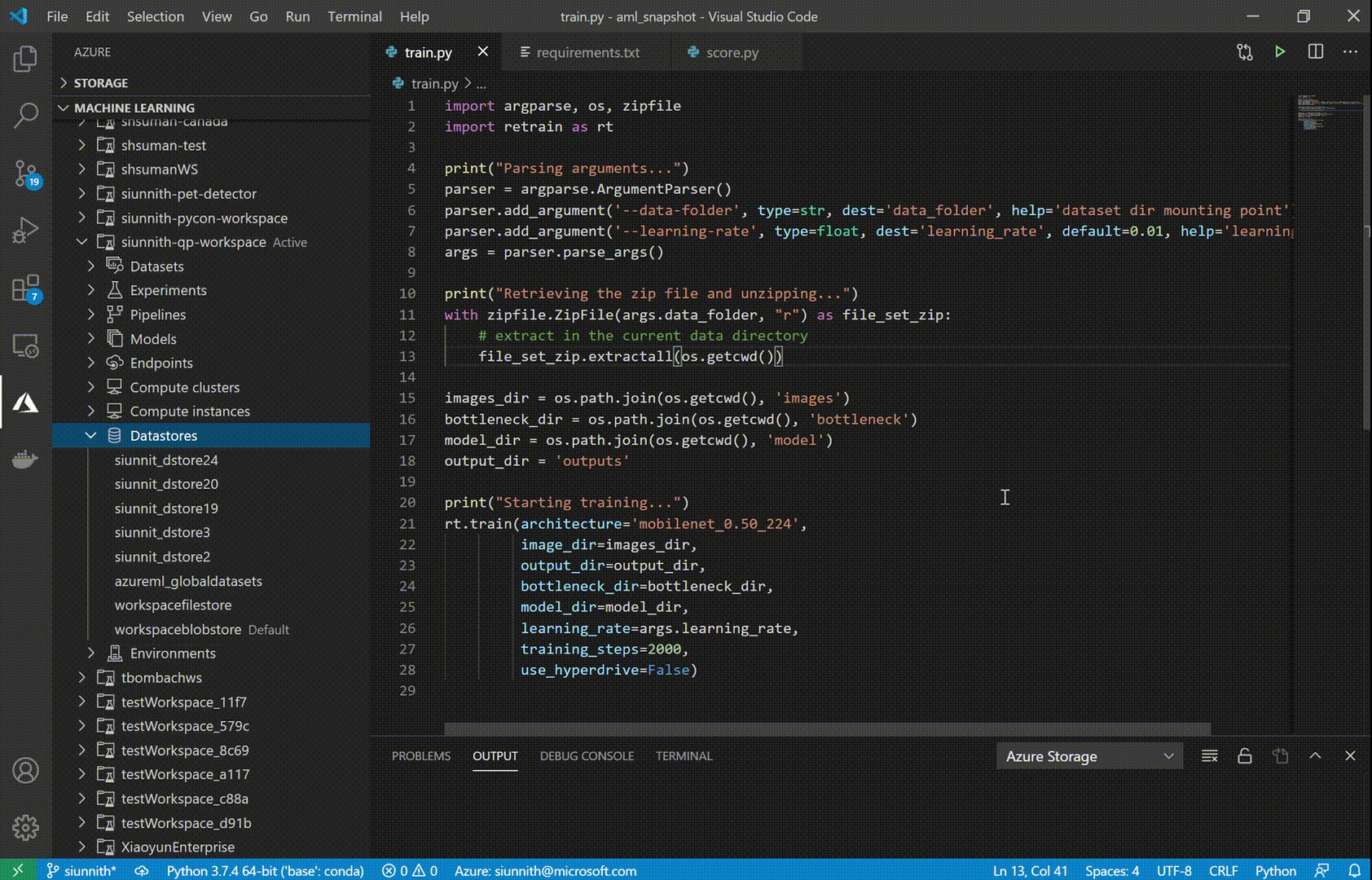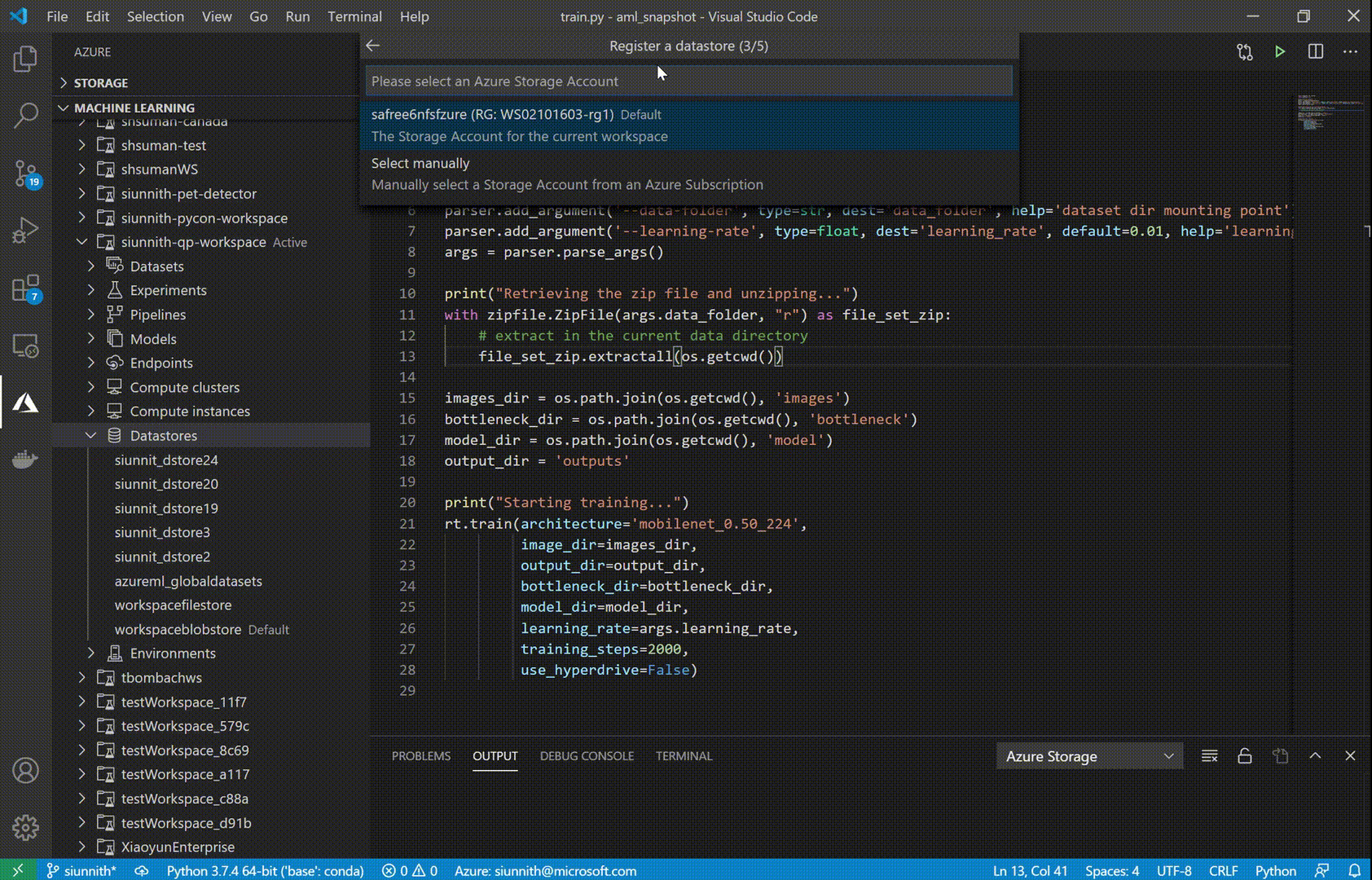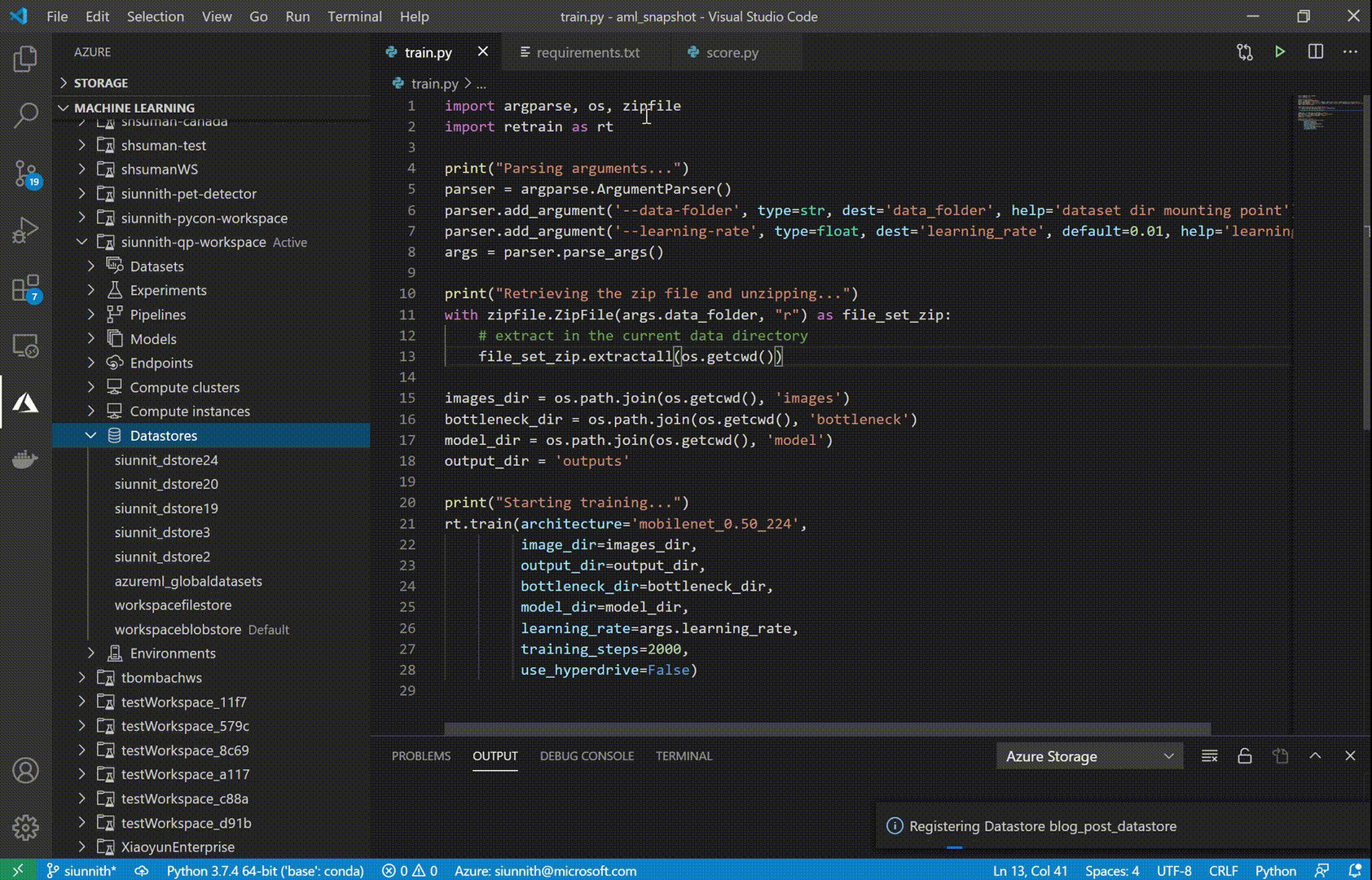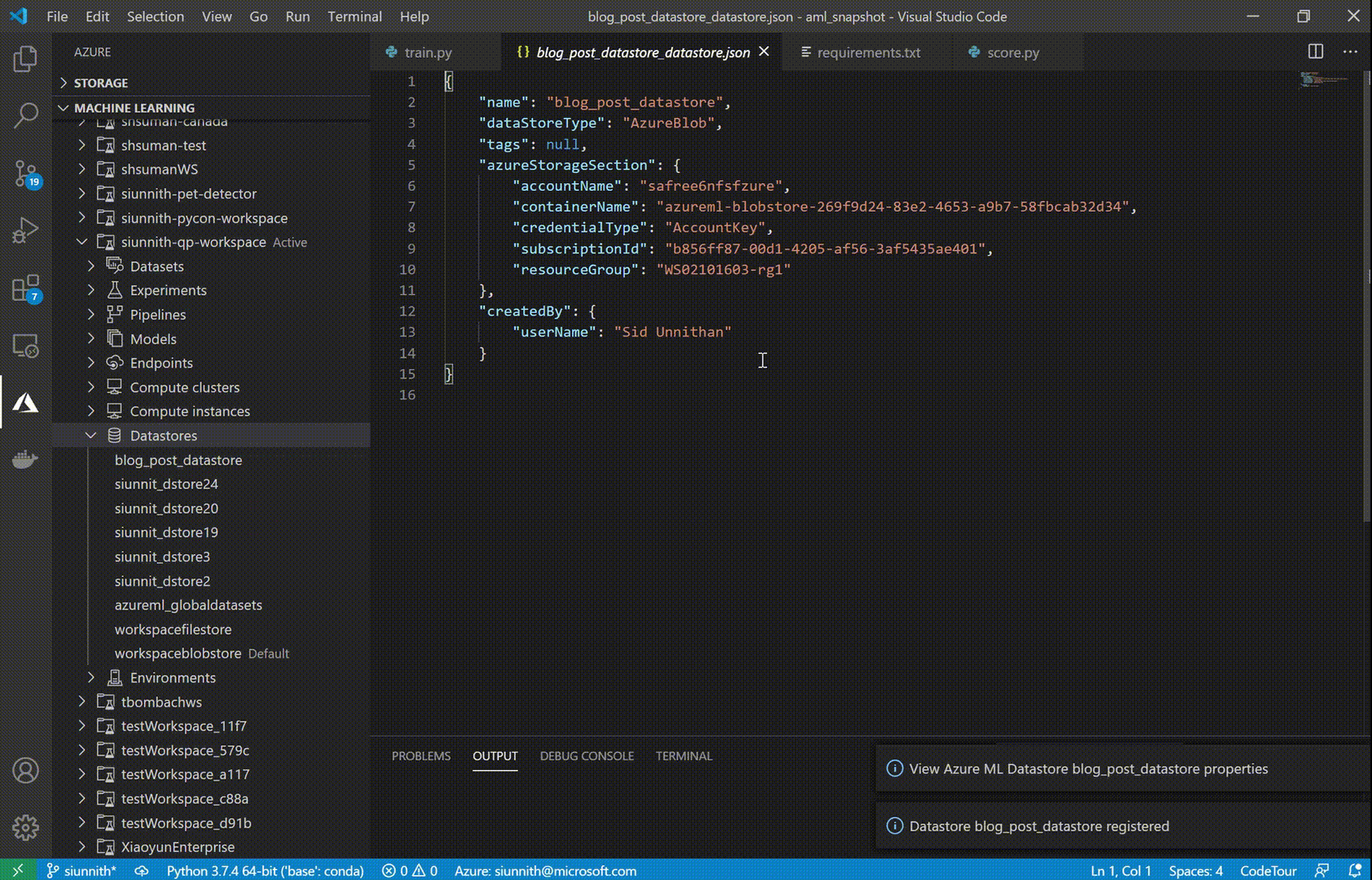
One of the new features we’ve released is support for Datastore registration Datastores are an AML resource that allow you to store connection information to Azure storage services. With Datastores, you no longer have to worry about writing custom storage connectors or hard-code your connection information as environment variables, config objects, or strings in your source.
The AML extension currently supports Azure Blob Storage and Azure File Share datastore types. To enable faster registrations, we’ve designed a set of streamlined input options, such as automatically retrieving your Account Key credentials to authenticate against your Azure storage account.
Dataset Integration
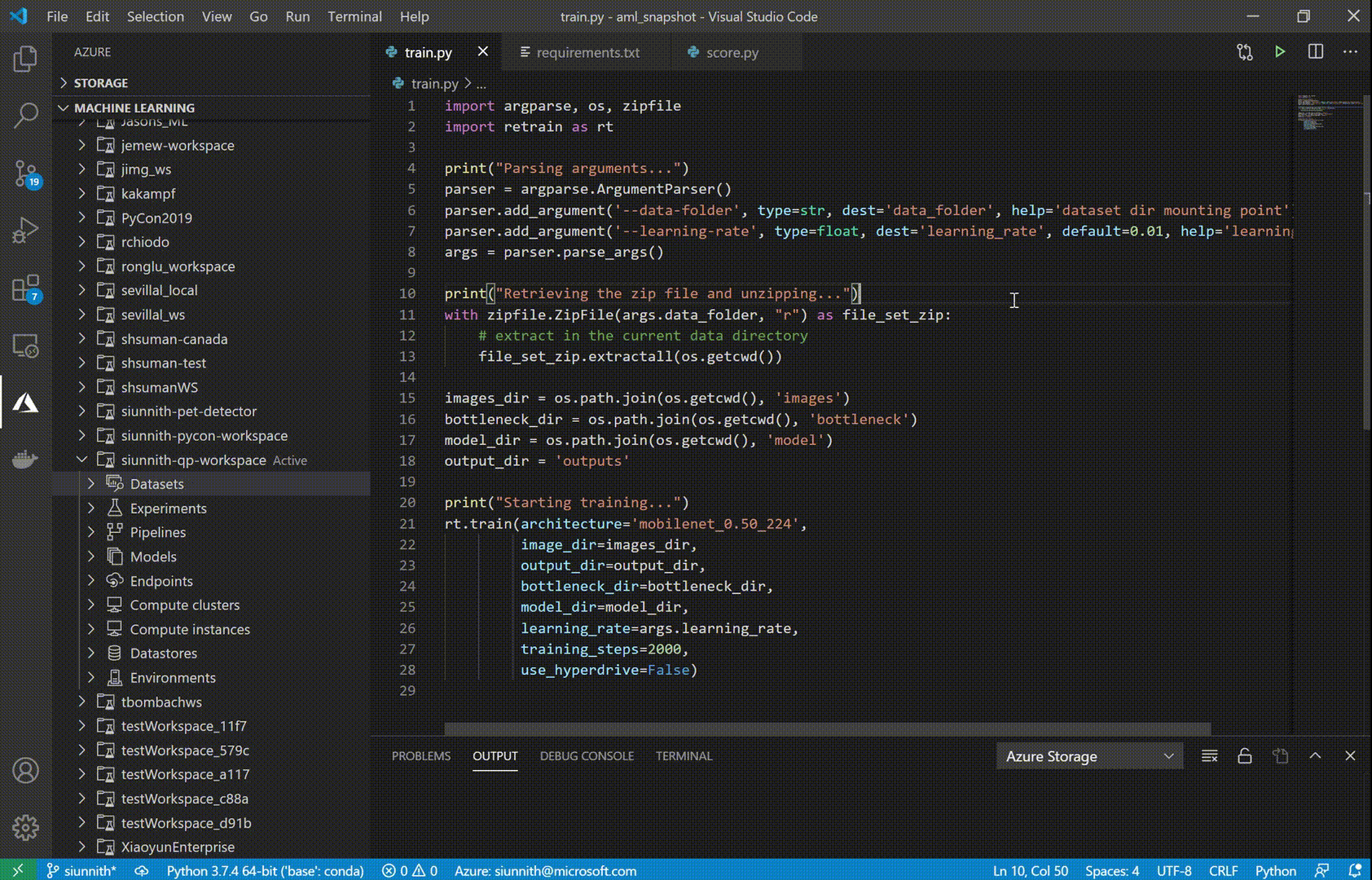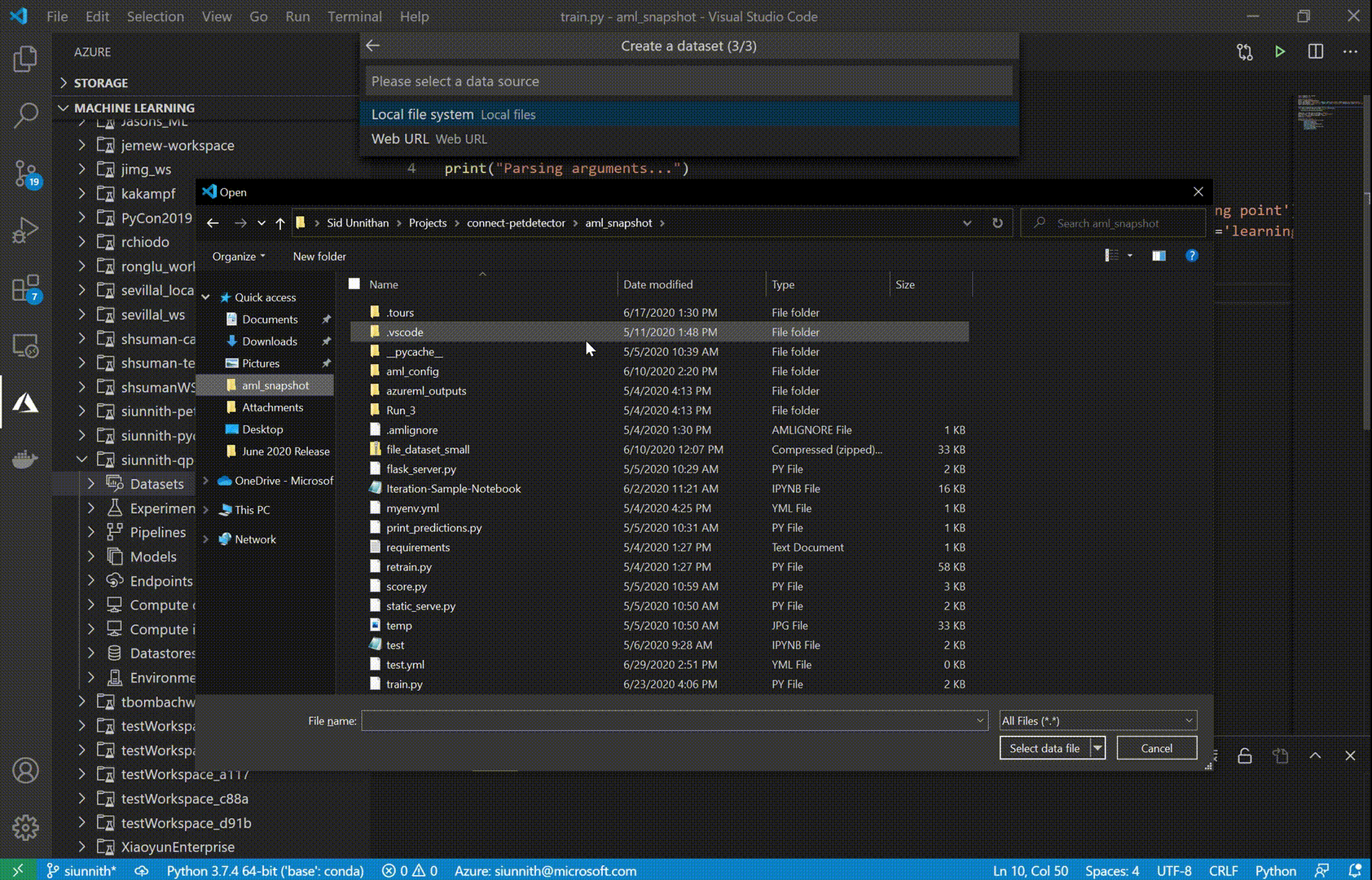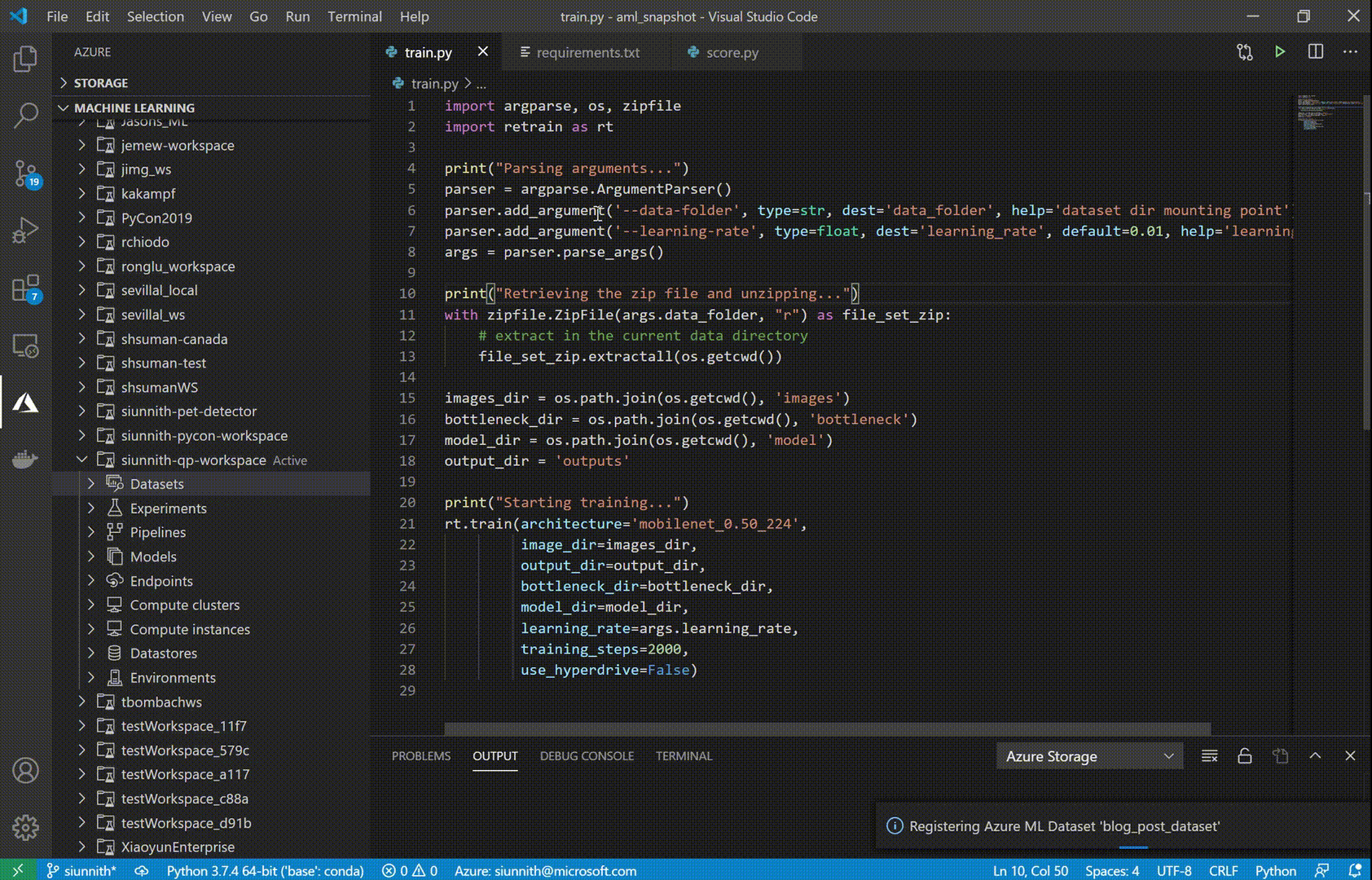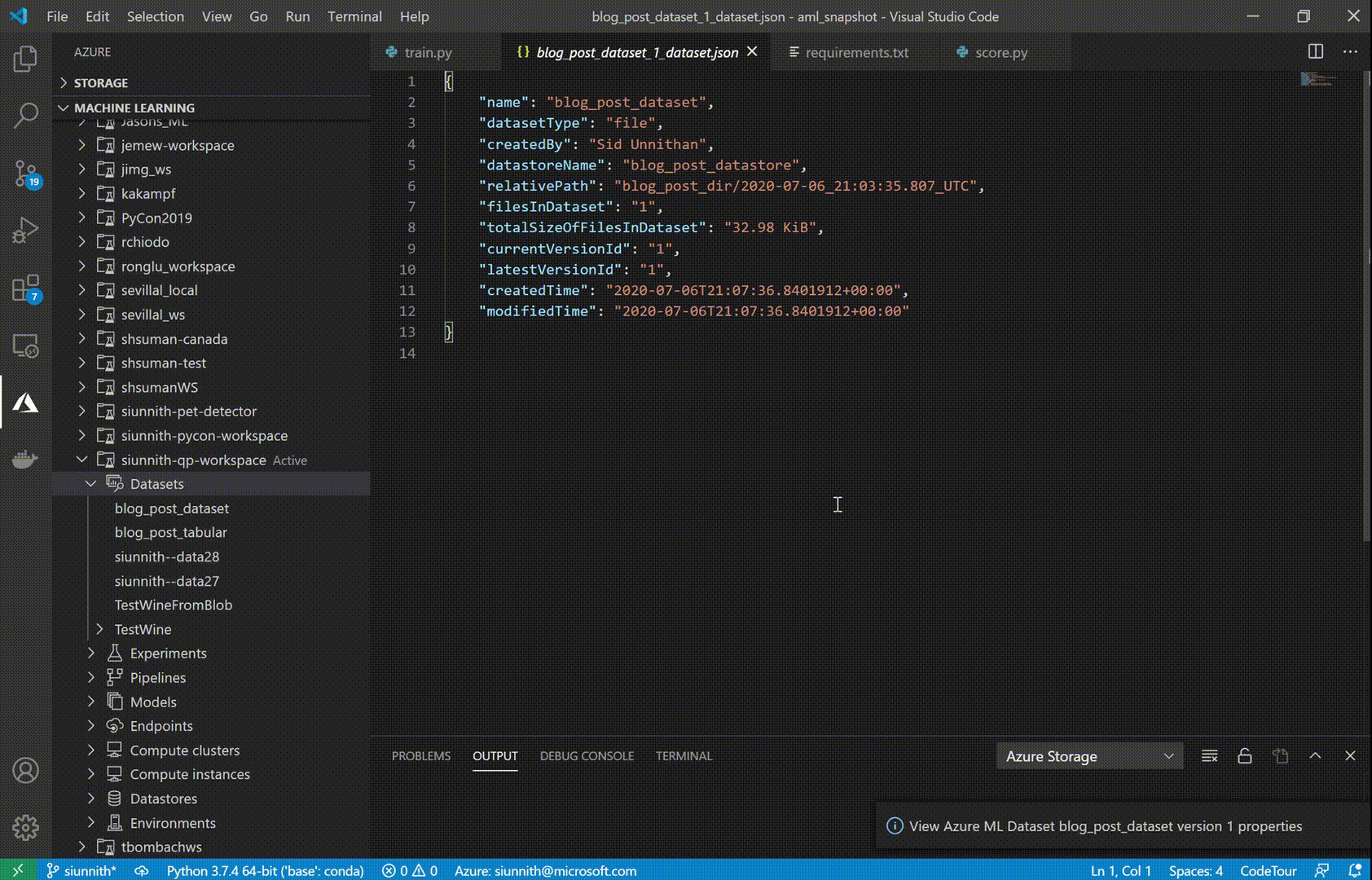
The AML extension now supports creating both Tabular and File datasets. Datasets can be used to define a consumable object from data in your datastore, local file system, or a remote location; these objects can then be used during experimentation and training tasks.
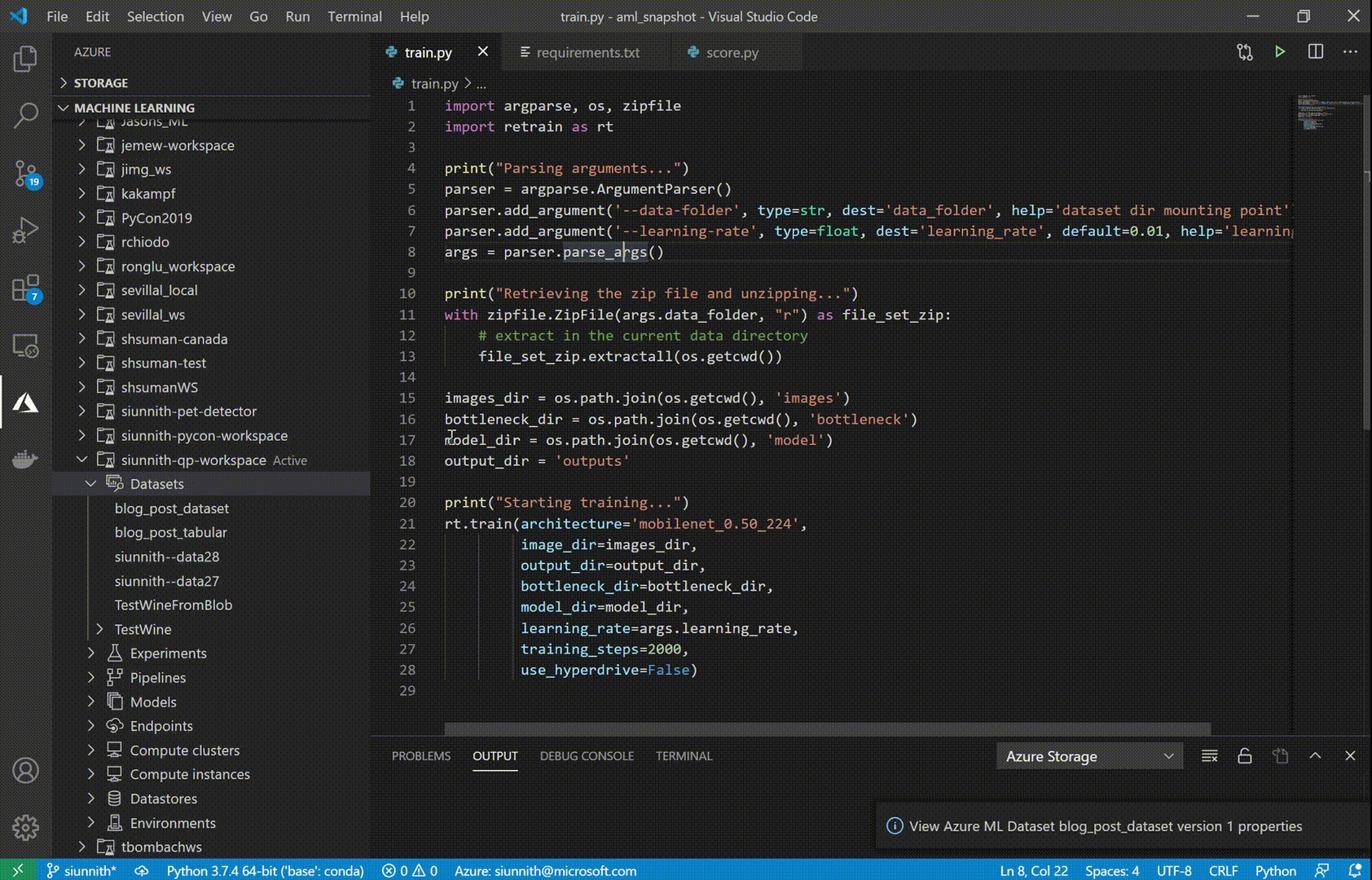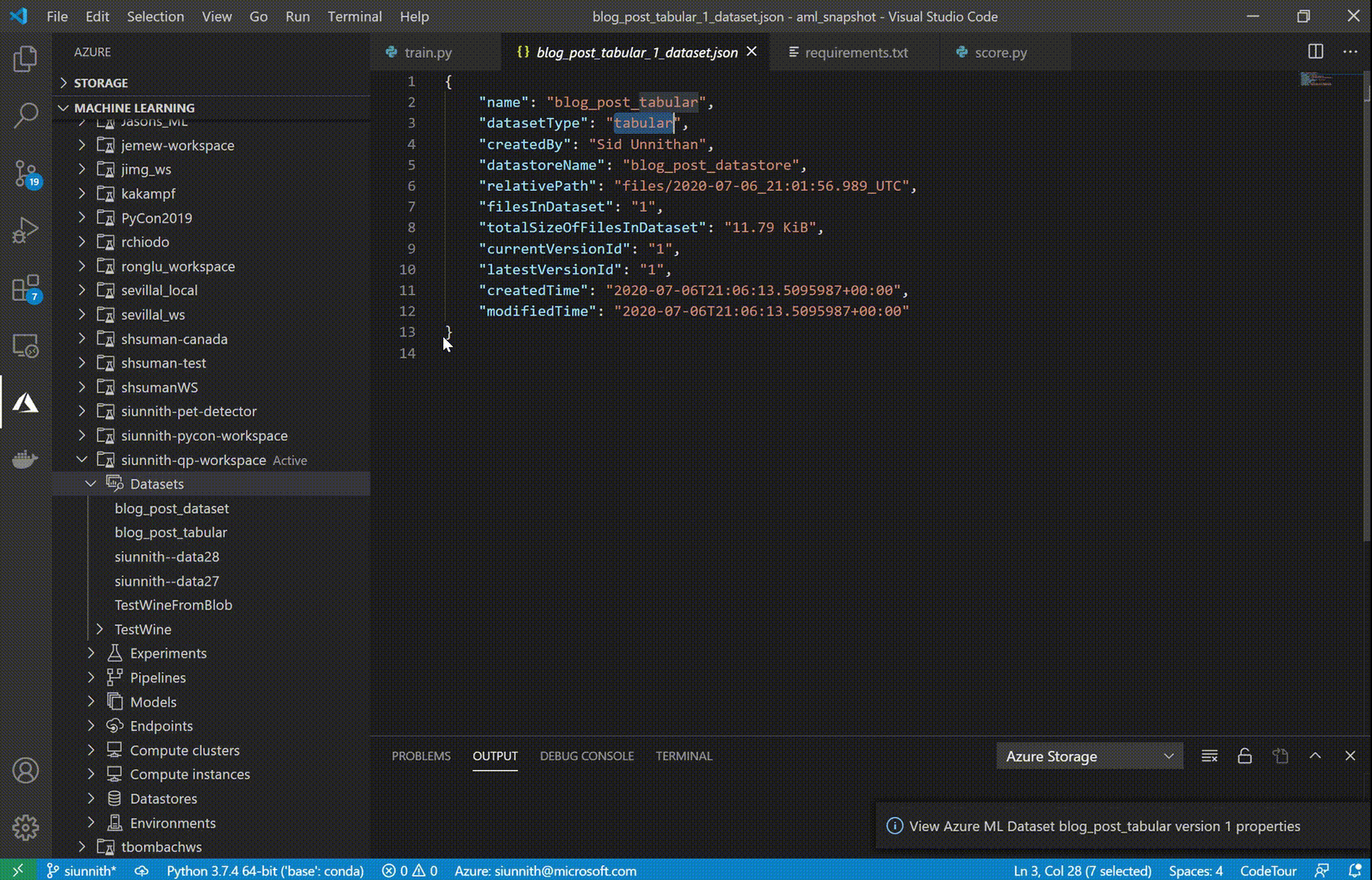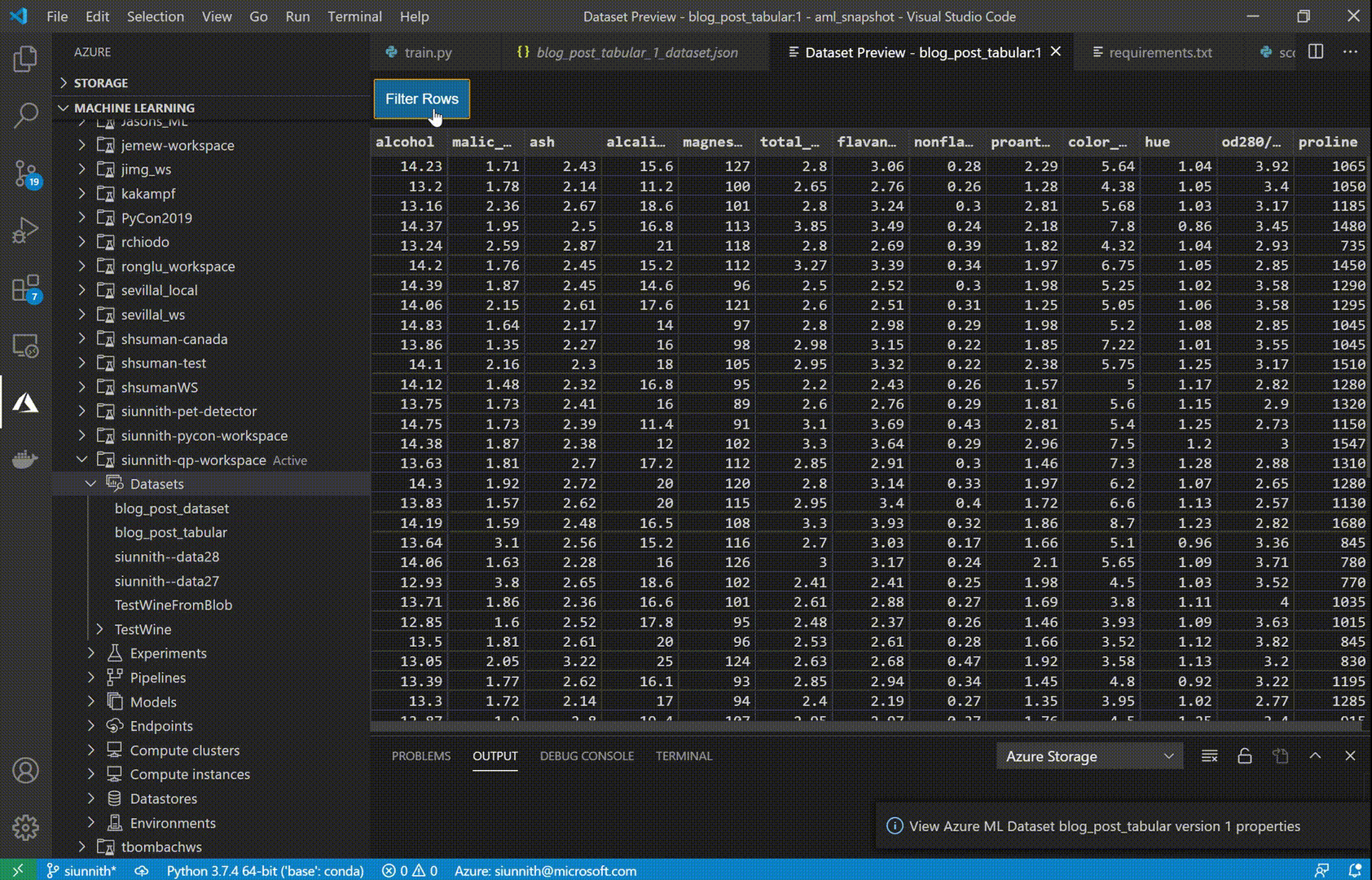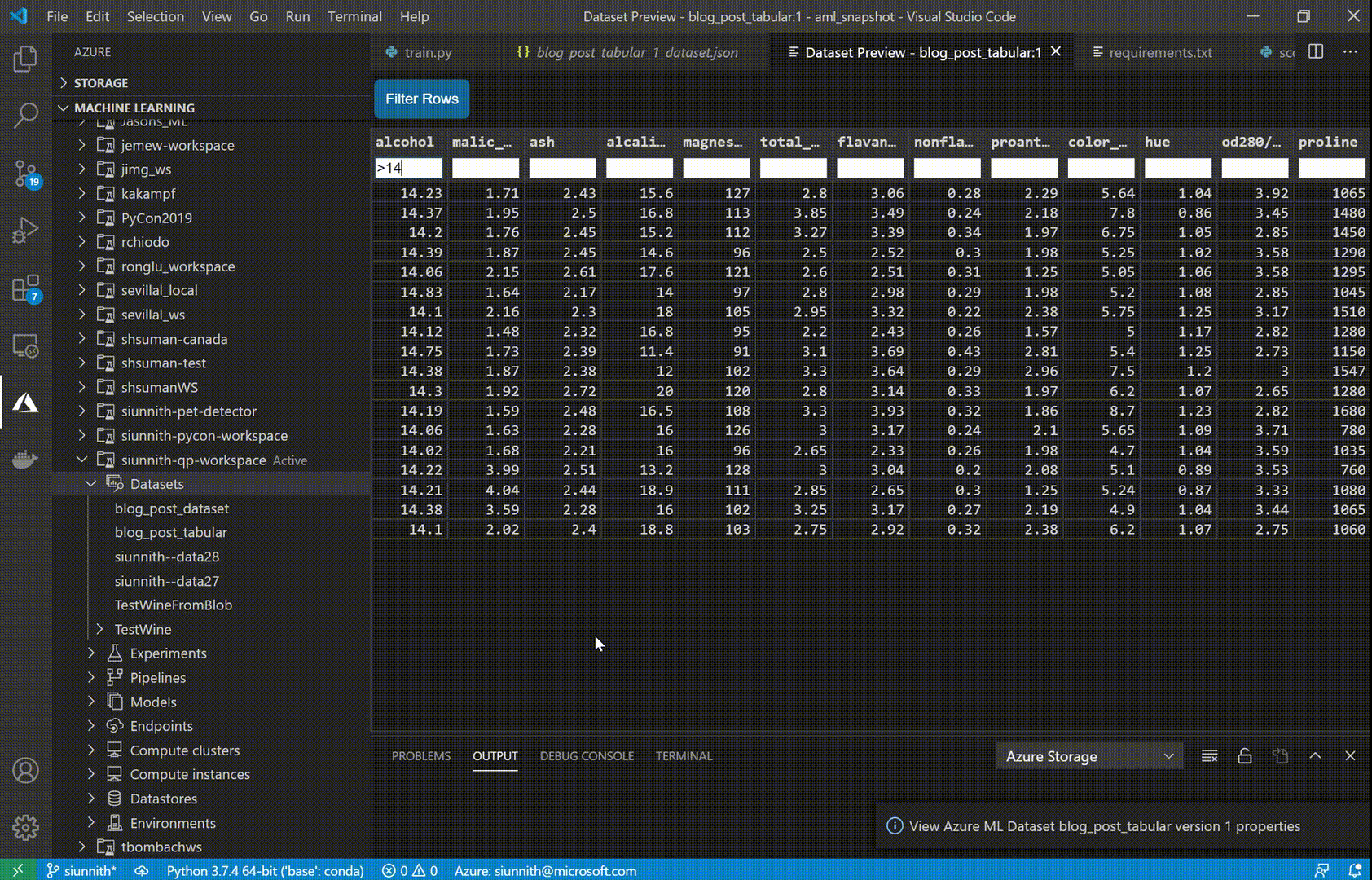
Once you’ve created a Tabular dataset, you can use the extension to preview the first 50 rows of your data. Dataset previews currently support filtering through simple expressions (e.g. search directly for “str” in a string column, or use “> X” in a numeric column).
In previous releases of the AML extension, we added support to help you train your models in Azure through Experiments. Experiments are made up of your training script, the compute target to run on, and the environment in which you want to run (i.e. what Python packages should be installed). With datasets being introduced, we’ve made it easy for you to use these datasets in your experiment without having to write extra AML SDK code. Right before submitting your experiment, you’re shown a configuration file with a reference to your datasets. In the file you just need to input the script parameter and attach mechanism to use for a File dataset, or the named input you’d like to use for a Tabular dataset.

Compute Instance Integration
AML compute instances are managed VMs that you can configure and use for your ML experimentation. With the VS Code extension creating and managing these compute instances has never been easier! You can view all your workspace’s compute instances and start/stop/restart them through commands in the tree. With a small number of clicks, you can create an SSH-enabled compute instance and then follow our in-editor documentation to easily connect to it via the VS Code Remote SSH extension.
UI Changes
Something we’ve been hearing for a long time is how the extension UI differs from the Azure ML Studio. In the previous GIFs you may have already noticed the highly consistent design in the extension tree view. We’ve updated each node with Studio-equivalent icons and have renamed/reordered them where appropriate.
Feedback
As mentioned throughout the blog post, many of the newly released features are in their preliminary phases and we’re actively working to support a broader set of scenarios that are consistent with the Azure ML Studio and SDK experiences. Here are some of the scenarios we’re working on:
- Connecting a Notebook in VS Code directly to a compute instance.
- Debugging failed experiment runs and pipeline steps using containers and AML environments.
- Creating datasets from an existing blob or file-based datastore.
- Using AML environments when deploying an endpoint.
If there’s anything that you would like us to prioritize, please feel free to let us know on Github!
If you’re an existing user of the extension and would like to provide feedback, please feel free to do so via our survey.
0 comments