


Ramakrishna Thanniru, Engineering, Optum / United Health Group
Pete Tian, Sr Cloud Solution Architect, Microsoft
Migrating an on-prem system to the public cloud can be a daunting task. While many companies have successfully made the transition, some have struggled with unexpected issues. One common problem is the sudden decrease in transaction speed, which can lead to system crashes and frustrating downtime. The Ops team may find themselves scratching their heads when faced with messages such as “timeout exceptions” or “HTTP 504 Gateway Timeout” in the logs, unsure of how to address these issues.
As part of UHG/Optum’s digital transformation in Azure cloud, we have witnessed these challenges firsthand. Over the past few years, we have helped several key workloads by simply making a few modifications to the application code, specifically in the connection pools. These changes have successfully removed bottlenecks in the data chain and dramatically improved the overall performance of the online business platforms.
In this article, we will share these modifications and explain how they can help address common connection-related issues.
What is a connection pool?
Connection pooling refers to reusage of existing pre-established connections to make HTTP requests, rather than creating a new connection for each service request, be it a connection of accessing remote REST API endpoint, or a backend database instance. Connection pooling can help to improve the performance of an application by reducing the overhead of establishing new connections, particularly for applications that make many HTTP requests concurrently.
Connection pools have implementation in various programming languages and frameworks, including Java/Spring, C#/.NET, JavaScript and Python etc.
First and foremost, connection pools should be used whenever and wherever the implementation is available in the framework you choose for your business applications. Our benchmarking exercise comparing load and stress testing of applications with and without connection pools shows that applications using connection pools gain tremendous performance optimization in service requests average response time. In certain cases, the transaction speed is 5 times faster, especially when applications are deployed in multi-cloud or hybrid cloud, or noisy environments.
Use connection pool to solve cross-cloud issues.
During the modernization effort of a clinical product called Utilization Management in the Cloud, the test team encountered intermittent 5-second delays during preproduction load testing of a microservice. These delays occurred when the concurrent user count reached 1000, leaving the team puzzled. By examining this case study in more detail, we can explore how implementing certain strategies may help address common issues related to network latency and timeouts.
The situation at hand involved a crucial integration between a Clinical Guideline Service (Service within Utilization Management Product) hosted in Azure and a service located in AWS, which had been acquired by UHG. This integration was pivotal in automating medical utilization decisions.
Guidelines is designed as a NodeJS webserver (A) running on an Azure Kubernetes Service cluster and utilizing a standard load balancer with multiple outbound public IPs and its dependent API, which was hosted in AWS was served through a network load balancer with cross-zone load balancing enabled and two backend nodes, each routing to a distinct ALB. The NLB hostname resolved to two public IP addresses.
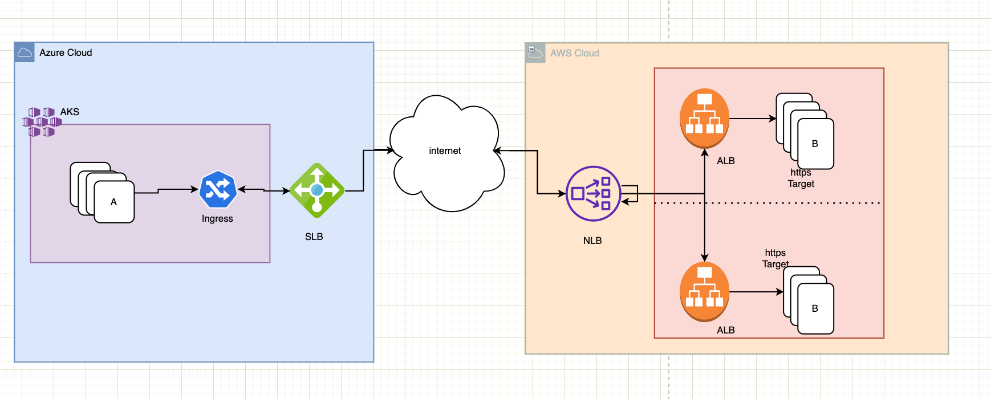
When a load test was conducted on NodeJS webserver, which involved making numerous outbound connections to the NLB endpoint that had two public IP addresses, it led to multiple connection timeouts and response times that were much higher than the agreed service level agreements (SLAs).
Below are the results of this test

After several attempts at troubleshooting by Optum, Azure, and AWS engineers, a network trace dump was taken simultaneously from both the Azure Kubernetes Service (AKS) pods and the AWS Network Load Balancer (NLB)/Application Load Balancer (ALB). The trace revealed that multiple client resets occurred during the three-way TCP handshakes, which helped to explain the connection timeouts that were observed during the load test.
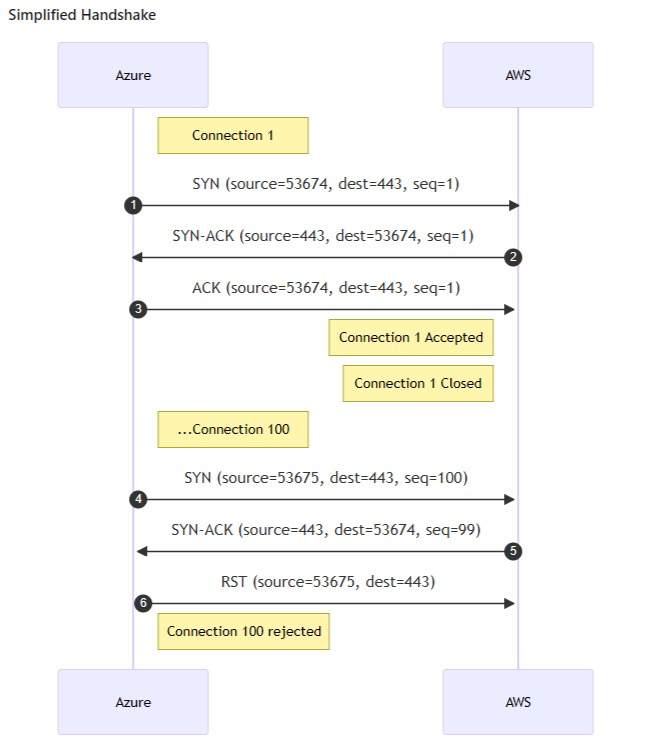
It was evident from the traces that client resets (RST), as outlined in the above picture, were due to differing ephemeral port reuse behaviors on the Azure and AWS network infrastructure. Both cloud providers are conforming to RFC 6056 for port reuse but, as per our analysis, differing in their port reuse timers, and hence the problem.
In order to resolve the connection timeouts issue, several potential solutions were discussed on the client-side. One option was to introduce a NAT gateway for outbound connectivity with AKS, which would allow for greater control over the reuse of ports with a timer but would not completely eliminate it. Another solution that was discussed involved setting up private connectivity between AWS and Azure, such as Site-to-Site VPN, which would eliminate the need for SNAT in the environment and remove the use of ephemeral port SNAT behavior. These solutions may eliminate the issues but need considerable redesign of the infrastructure and time.
In an effort to find a short-term solution, we began investigating code-level options to establish longer-lasting TCP connections and implement retry mechanisms. However, it’s important to note that these practices should always be implemented as best practice and refined according to their throughput requirements for any application. As a result of our efforts, we achieved tremendous performance improvements shown in the following outcomes. This is with Keep Alive enabled.

Avoid connection pool starvation
HTTP connection pooling is often managed automatically by software development frameworks, with a default maximum size of concurrent threads ranging from 20 to 40. This default size is usually sufficient for most developers in dev and QA environments, and tuning is not typically required. However, when stress testing or serving thousands of concurrent users in a production environment, the system may experience intermittent timeouts or hesitation. This is a typical symptom of connection pool starvation, which can occur when the number of available connections is insufficient to meet the demand from the client applications. In such cases, connection pool tuning can help to address the issue and improve system performance.
Create your own keep-alive strategy, or not
In TCP connections, the keep-alive mechanism is used to maintain an open connection between the client and server, even when there is no data being transmitted. It is commonly used in connection pool implementation to avoid the overhead of opening and closing a new connection for each request, which can negatively impact performance.
By using a keep-alive strategy, the client and server can maintain a persistent connection to reduce latency for subsequent requests. However, it’s important to carefully configure the keep-alive parameters to avoid excessive resource usage, particularly in high traffic environments.
Here’s a code sample frequently used by Java developers for the purpose of implementing their own keep-alive strategy.
// Set keep-alive strategy
builder.setKeepAliveStrategy((response, context) -> {
String header = response.getFirstHeader("Keep-Alive").getValue();
if (header == null) {
header = response.getFirstHeader("Connection").getValue();
}
if (header != null && header.equalsIgnoreCase("keep-alive")) {
return 30 * 1000; // keep the connection alive for 30 seconds
}
return -1; // close the connection otherwise
});However, it is noticed that some developers simply copy and paste this code without considering whether it’s necessary for their specific use case.
It’s important to note that unless there’s a pre-defined protocol between the client and server that includes specific keywords in the HTTP header, adding this code won’t provide any benefits. In fact, as shown in the code block, checking each key value pair in the HTTP header introduces extra overhead and causes delays, particularly in production environments with high concurrent user traffics. It’s essential to carefully consider the trade-offs before implementing such an advanced code.
Conclusion
When network bottlenecks occur in your web application deployed in the cloud, it is typical for support engineers to resort to the quick fix of scaling up the service by adding more CPUs and memory. However, this approach is akin to providing expensive Bourbons to patients with kidney stone problems and is ultimately ineffective. Another common but short-sighted solution is to simply ask for more budget to acquire fiber-optic connections.
Rather than throwing more money at the problem, it is important for the development team to conduct code reviews and examine the system configurations to leverage the full potential of network programming features offered by modern frameworks.
0 comments