
Tahir Naveed walks through how to measure prompt response times with Microsoft Copilot Studio and explores considerations that factor into the overall performance of these requests.
Building custom copilots (GenAI chatbots) in Microsoft Copilot Studio is amazing. Especially with the new functionalities which were released in Microsoft Build 2024. What’s more amazing is when we can point the custom copilots to different kinds of external and internal data sources like public websites (external), Dataverse tables (internal), SharePoint etc.
Today we will be looking at how to check the response time of a prompt when you ask a copilot a question. For this we will be using Developer Tools (Network Tool to be exact) in Microsoft Edge browser to perform following three experiments:
Pre Req: Create a custom copilot with Copilot Studio and provided following data sources in the knowledge tab.
- Public website: www.cnbc.com
- Dataverse Table: Employee Information
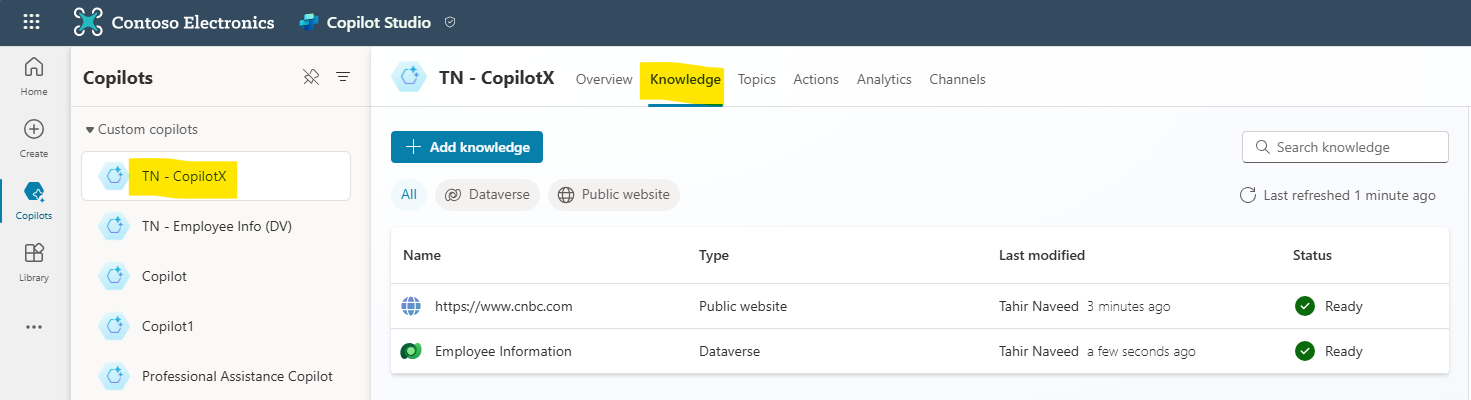
Test the copilot to make sure it is responding to the prompts by bringing data from the public website and Dataverse table.
In your copilot, go to Topics -> System -> Conversational boosting to see the developer view.
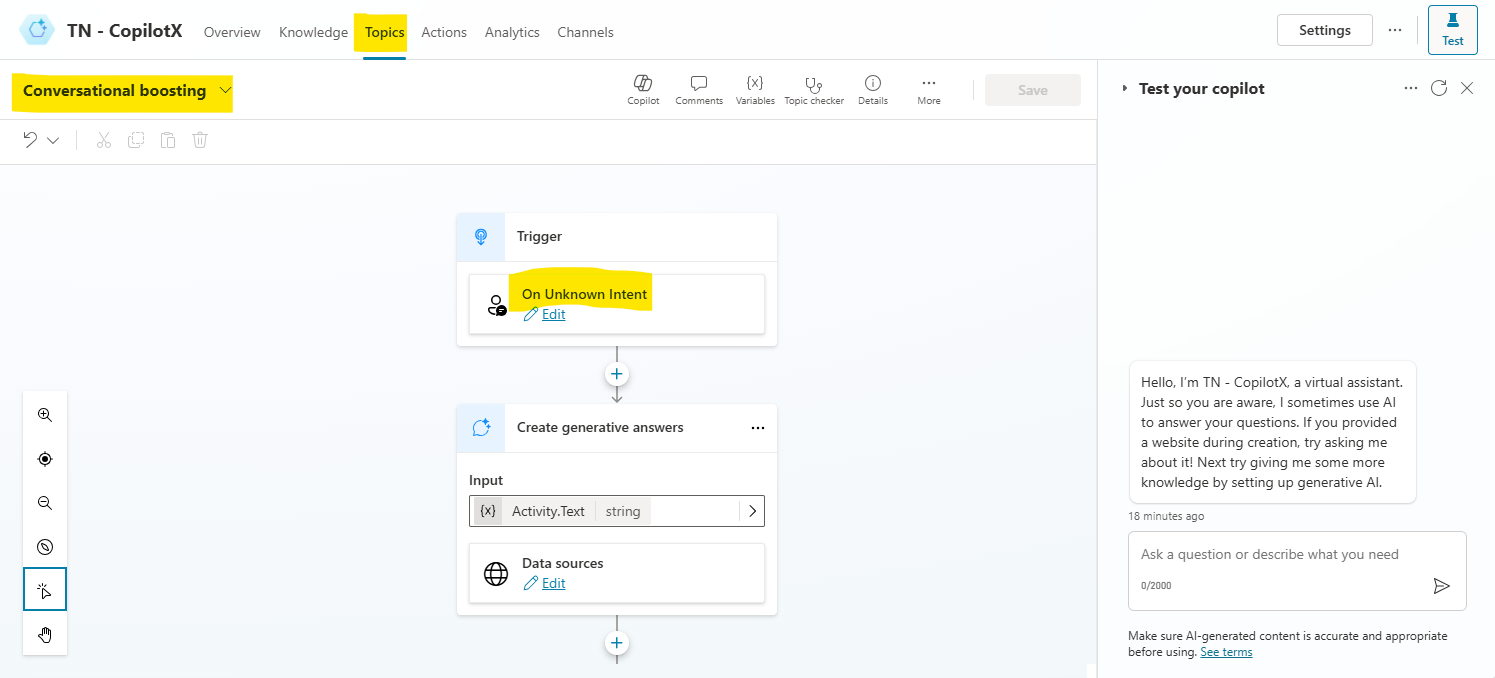
We will focus on this special system topic as this gets triggered and when a prompt’s intention is not known– copilot searches across our provided data sources and then results from those data sources are used as context for the LLM to respond in a natural way. This is RAG (Retrieval Augmented Generation) pattern.
Experiment 1 – Prompt Response Time without GenAI
- Launch the Developer Tools (Ctrl+Shift+I) and then select the Network tool. Additionally Turn off the recording and clear the network log & filter by Fetch/XHR request to reduce the noise.
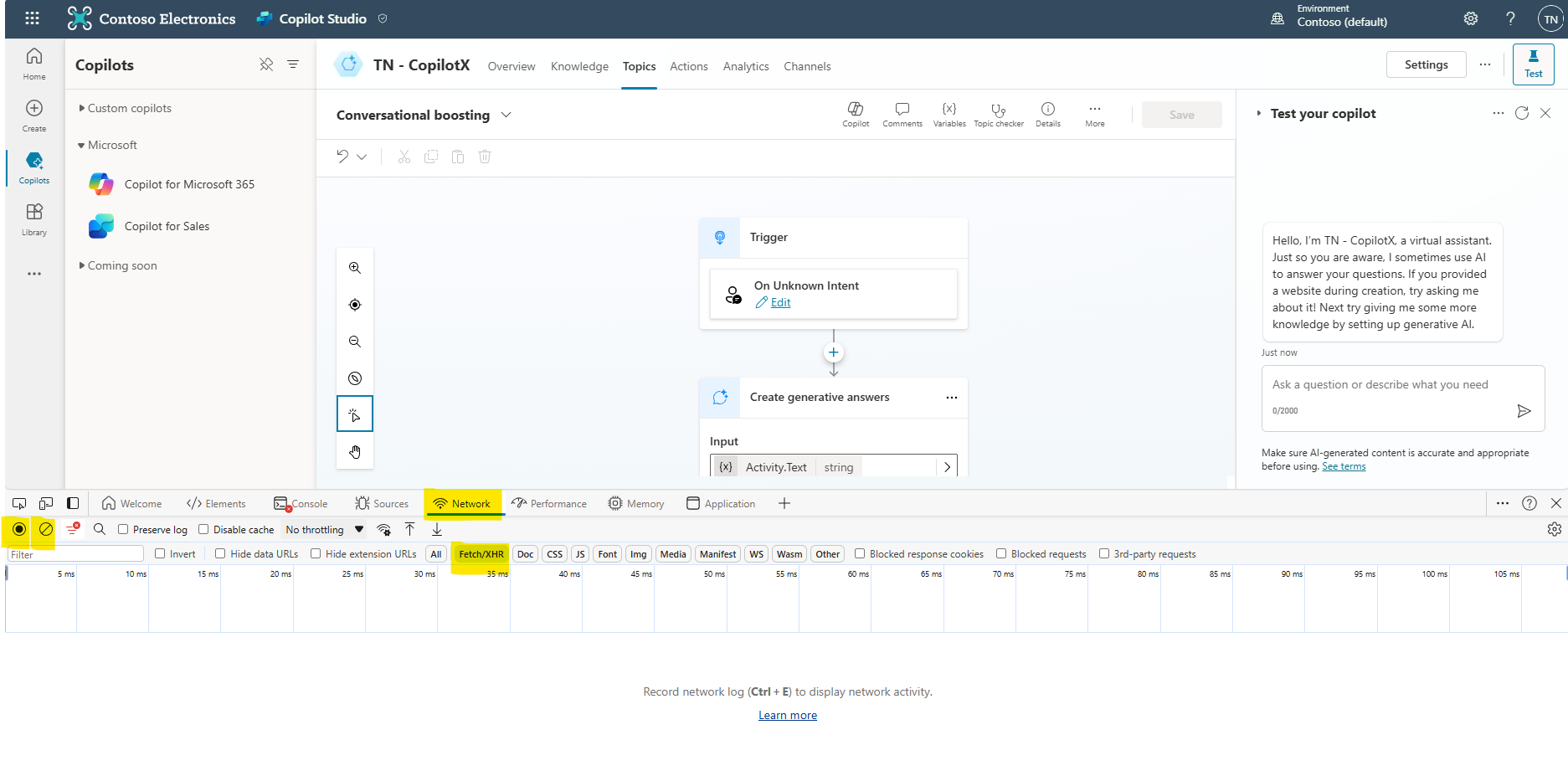
- Turn on the Record network log
 .
. - Prompt: Hi
- Captured Network traffic
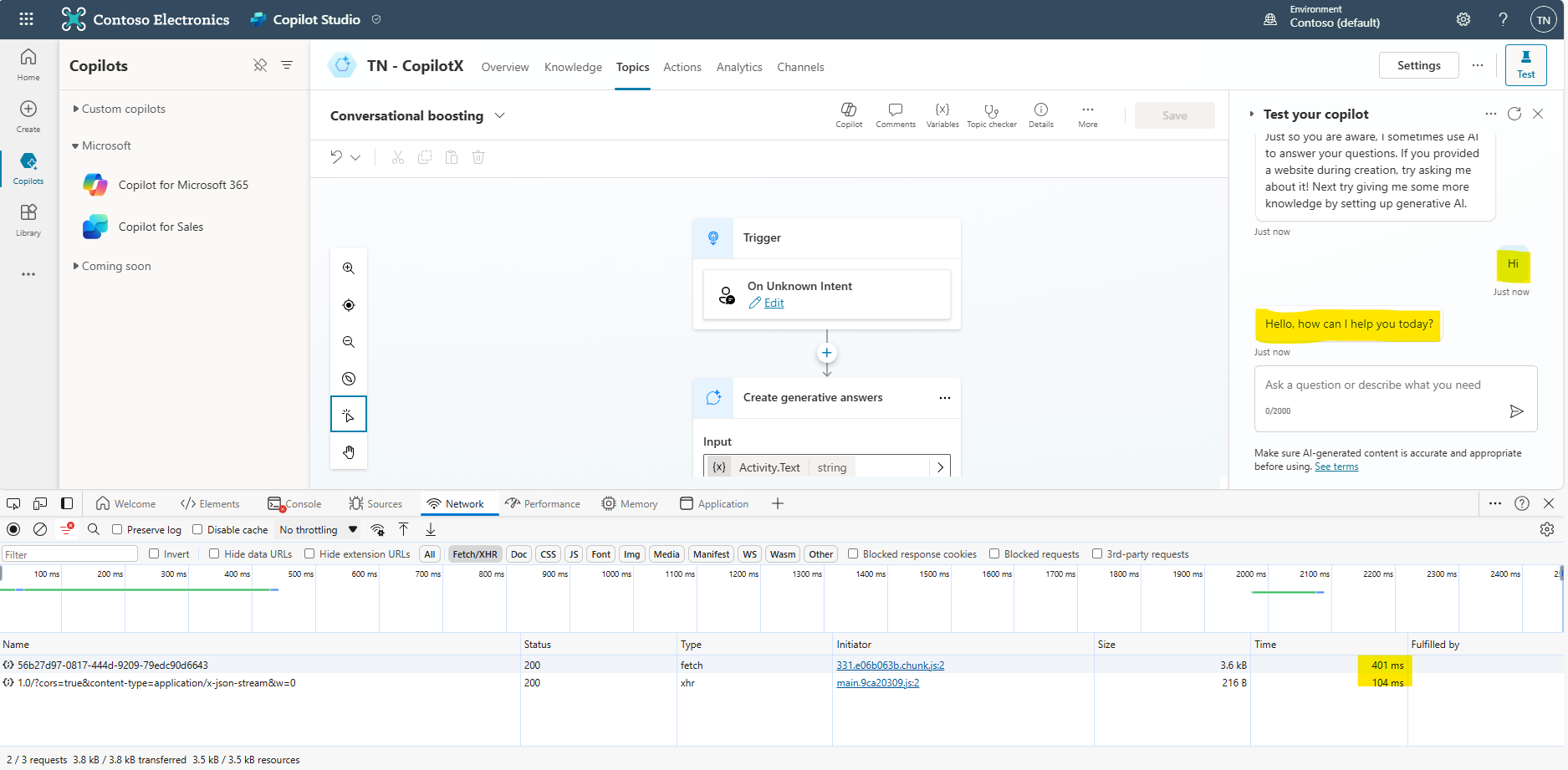
You will see one main request (and some supporting requests) and their combined response time is going to be around half a second (401+104 ms = 505 ms). This is because the copilot got the intention perfectly and triggered the Greetings topic which responded without using the GenAI functionality. Prompt response within half a second is very great.
Experiment 2 – Prompt Response Time with GenAI & Public Websites
- Edit the Data source in Create generative answers action and select cnbc.com & save the topic.
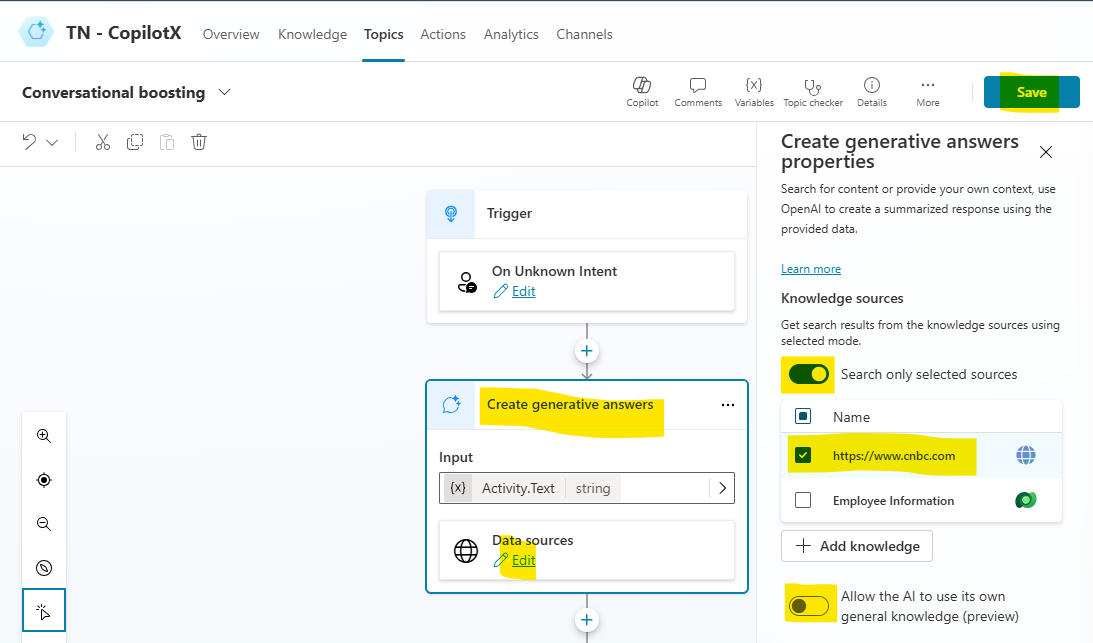
- Turn on the Record network log
 .
. - Prompt: What is the latest news on S&P 500?
- Captured Network traffic
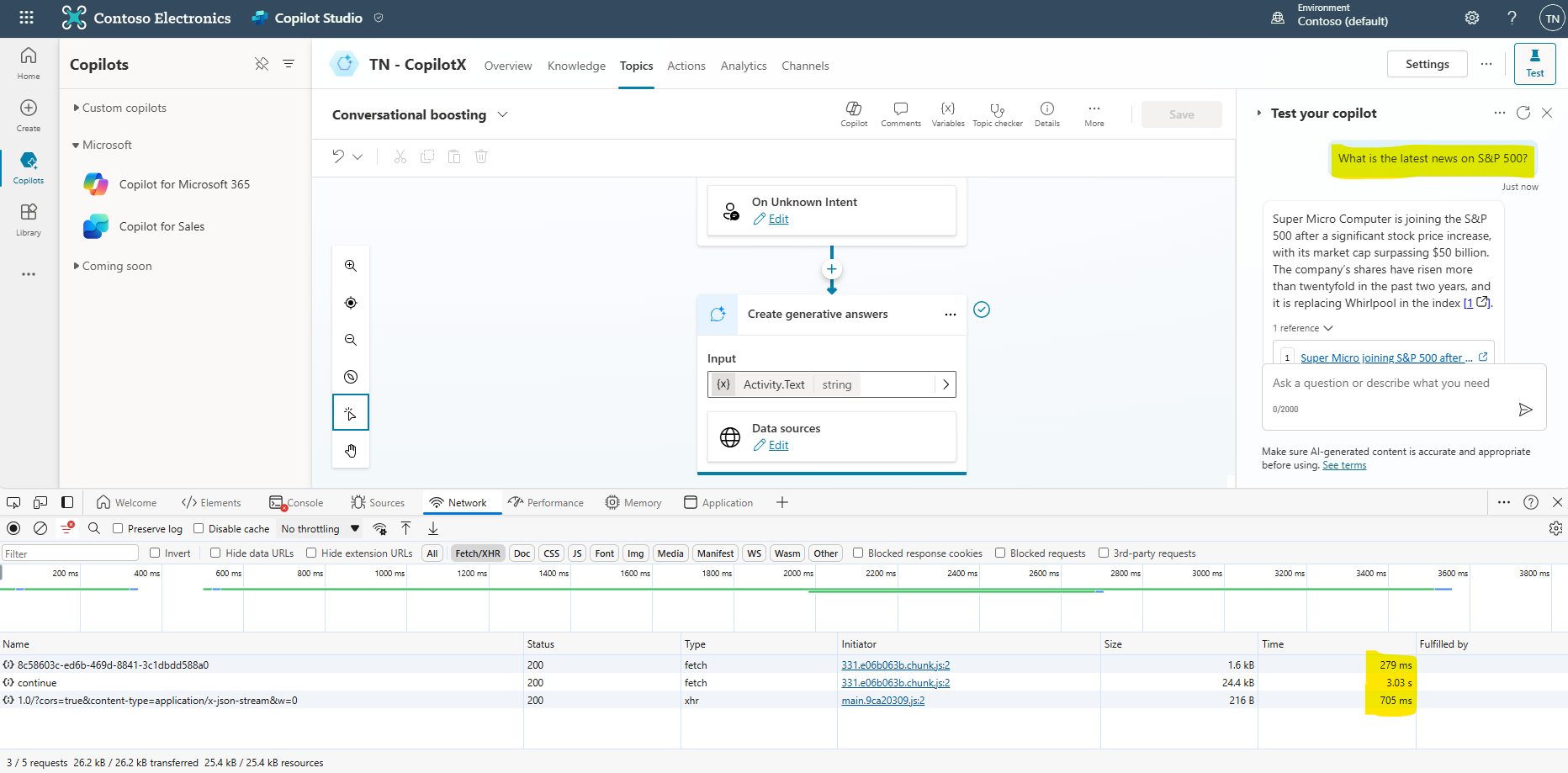
With the prompt that goes to the external data sources you will notice a slight delay in the response (3.03 s + 0.279 s + 0.705 s = 4.014 sec). This is due to the fact that when intent is not found in the custom topics, then Conversational boosting topic is triggered which has translated the prompt into search for cnbc.com (request1) and then results were combined with the prompt to send it to the LLM (request2) which caused a slight delay in the final response. Having said that, this prompt used GenAI with all the data from the website and still managed to respond within 4sec, which is super fast for this scenario.
Experiment 3 – Prompt Response Time with GenAI & Dataverse Table
- Edit the Data source in Create generative answers action and select cnbc.com & save the topic.
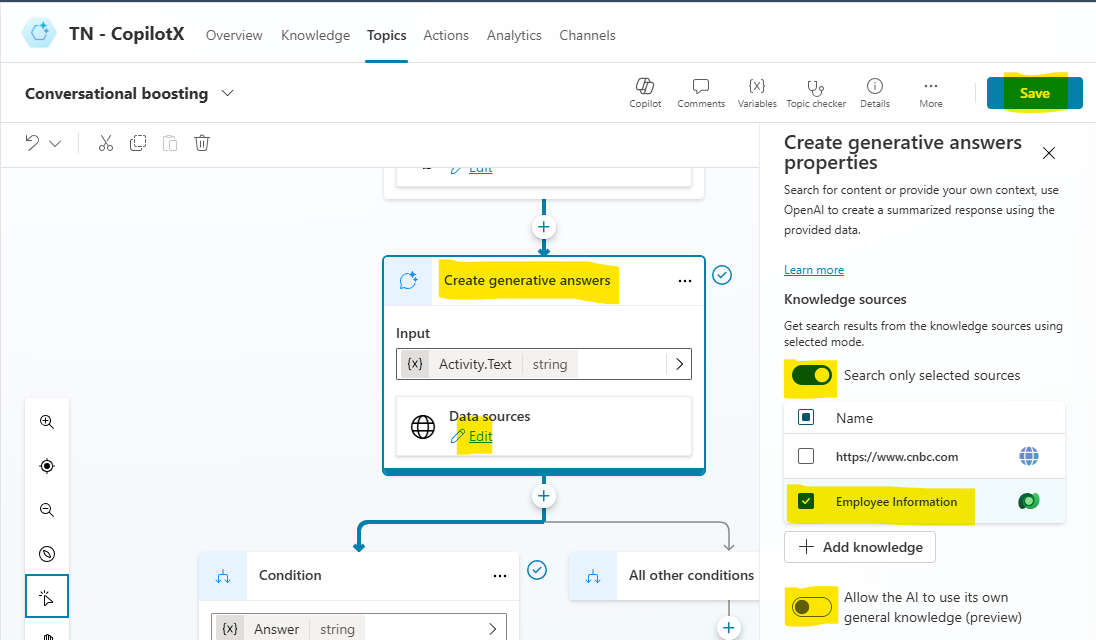
- Turn on the Record network log
 .
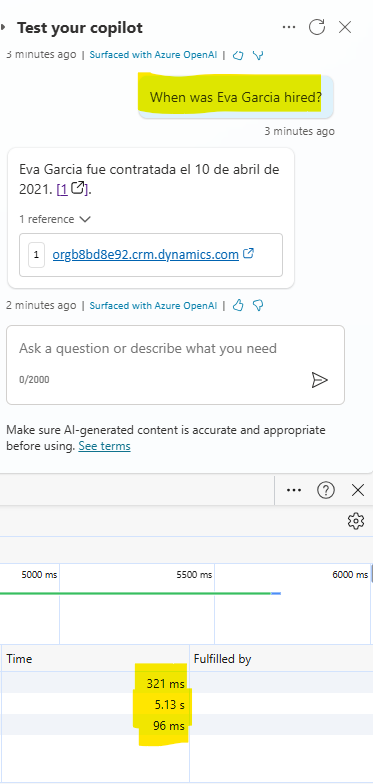
. - Prompt: What is the job title, department and Hire Date of Eva Garcia?
- Captured Network traffic
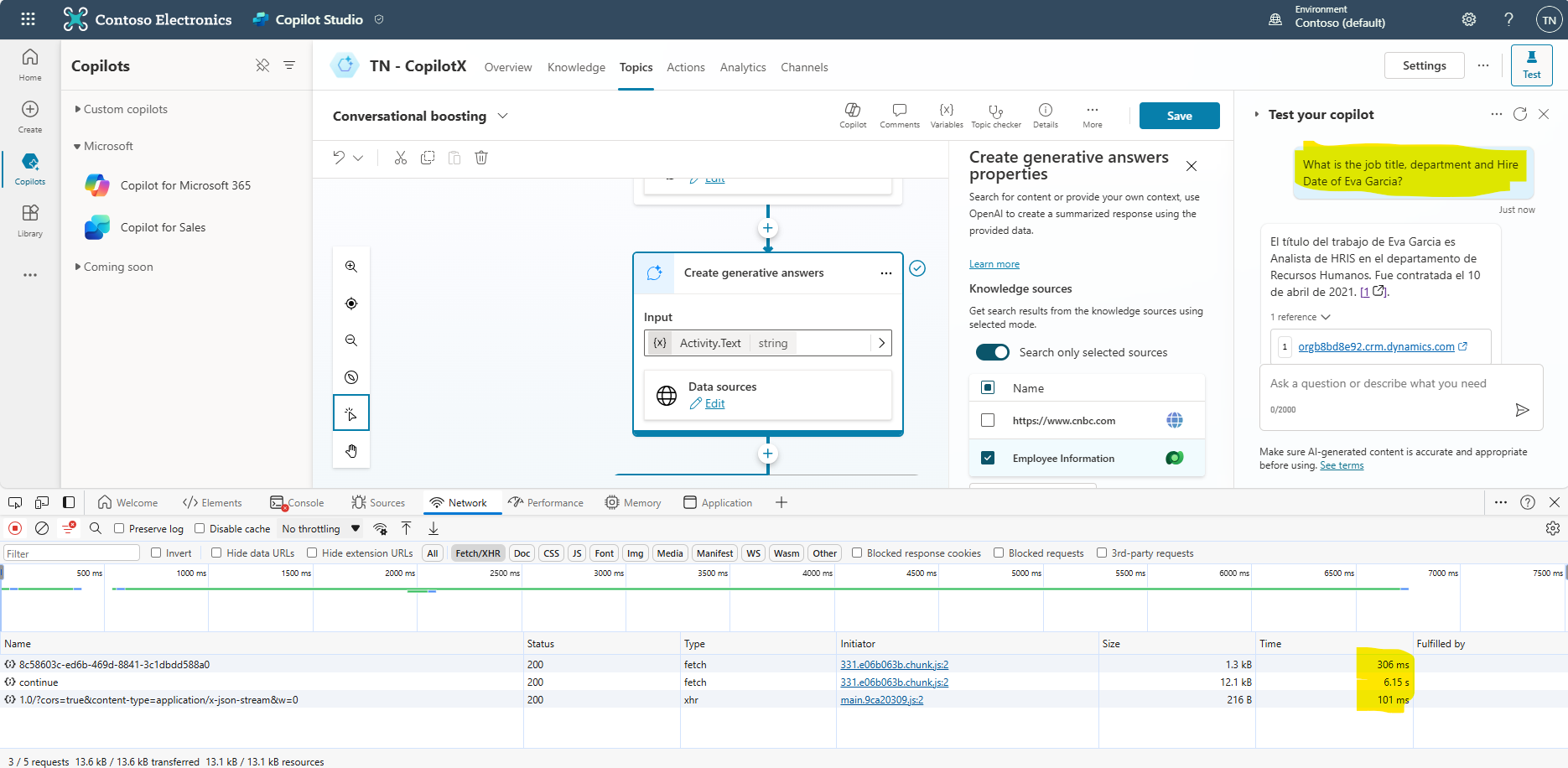
With the prompt that goes to the Dataverse table, you will again notice a delay in the response (0.3 s + 6.15 s + 0.1 s = 6.55 sec). This is again due to following the RAG pattern that when intent is not found in the custom topics, the Conversational boosting topic is triggered which has translated the prompt into search for Employee Information Dataverse table (request1) and then results were combined with the prompt to send it to the LLM (request2) which caused a delay in the final response. Having said that this prompt used GenAI with the structured data from the Dataverse table and still managed to respond in around 6.55 seconds, which is not ideal, but can be improved by tweaking the prompts (Prompt Engineering).
For example, for prompt: When was Eva Garcia hired? I see 15% improvement (5.5 sec) in the response from the same table:
Conclusion:
The custom copilots created via Copilot Studio are using GPT 3.5 Turbo LLM as of now. And as we saw that the prompt response time depends on the following things:
- Usage of the GenAI feature.
- Type of data source.
- Complexity of the prompt.
Our only option for now is to engineer our prompts and/or create topics intelligently as part of the best practice. Going forward, new versions of LLMs will become available and result in a better experience and improved response times.
0 comments