

Introduction
JSON (aka, JavaScript Object Notation), a standard text-based format for representing structured data based on JavaScript object syntax, is the default representation for the OData requests and responses payload, see OData JSON format here. It’s a very popular format and widely used in most scenarios. However, there are customers who want to build services following OData conventions and want to get OData payload using formats other than JSON, such as CSV (aka, Comma Separated Value) format, or YAML (aka, YAML Ain’t Markup Language) format, etc.
OData .NET libraries are designed to empower customers to customize/extend other payload formats besides JSON. There’s a post here mentioning a way to customize CSV format using an old version of OData APIs. In this post, I’d like to guide you through the steps about how to customize/extend OData payload serialization formats with ASP.NET Core OData 8.x version. I mainly use CSV to introduce the detail customization process, but you can follow the same pattern to implement any other payload format in your OData service, for example, YAML.
Let’s get started by overviewing the OData payload serialization/writing process within ASP.NET Core OData.
OData Payload Serialization Overview
Below is a simple picture describing the components used to serialize OData payload within ASP.NET Core OData 8.
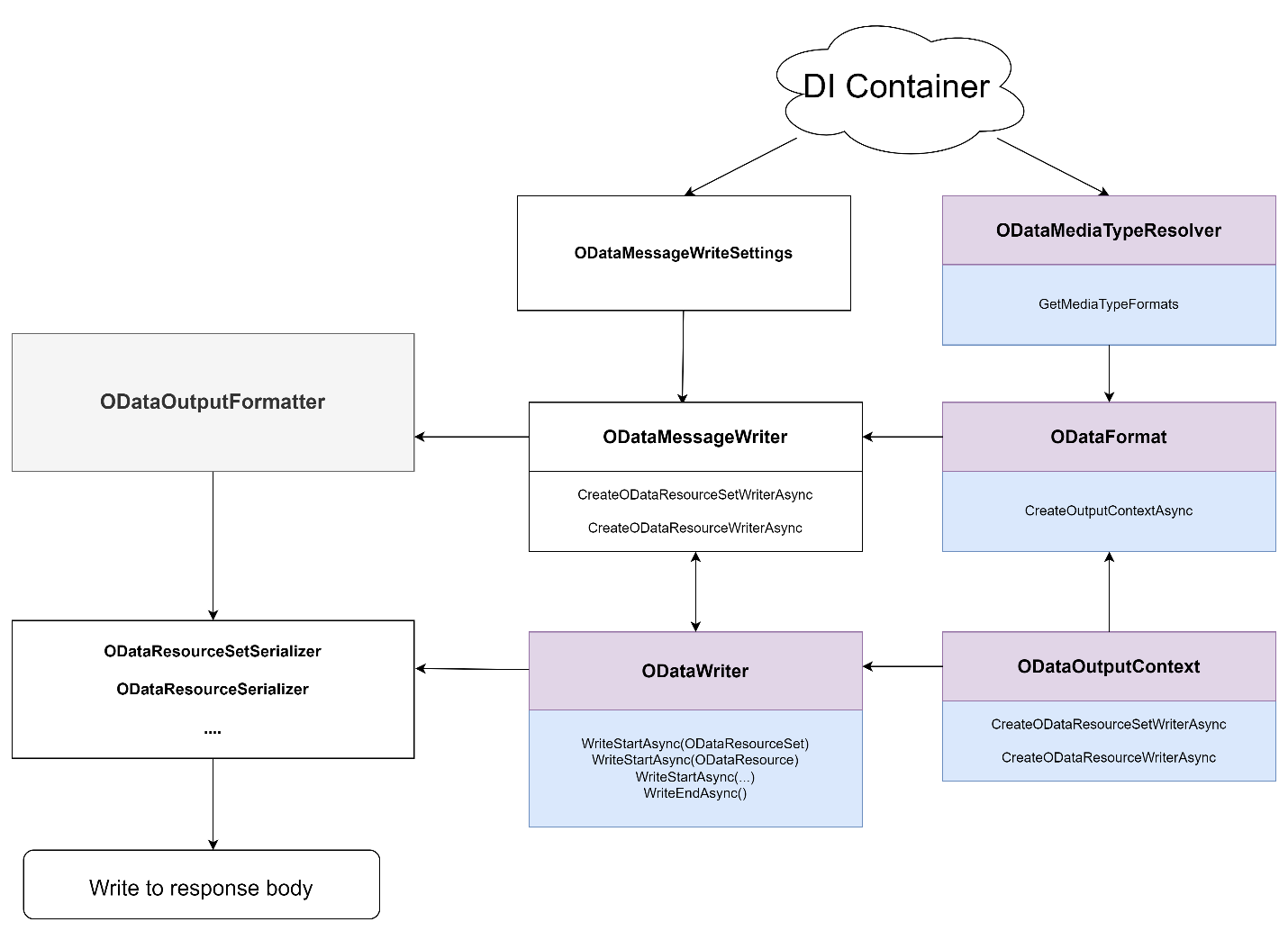
Where ODataOutputFormatter is the formatter to serialize the OData payload into the response body. It creates ODataMessageWriter using the ODataMessageWriterSettings from the service container and a response message. ODataMessageWriter would internally delegate ODataMediaTypeResolver from the service container also to figure out the proper payload format (aka, ODataFormat), which in turn creates the corresponding output context (aka, ODataOutputContext), finally, the output context creates the ODataWriter to perform output writing. The serializers, such as ODataResourceSerializer, use the ODataWriter to write the resources, properties, nested properties, etc.
ODataMediaTypeResolver, ODataFormat, ODataOutputContext, and ODataWriter are key components that we should implement by ourselves to customize the payload format. I will use a sample application in the following sections to share a demo about how to customize them to get the CSV format payload.
Prerequisites
Let’s start to create an ASP.NET Core Web API application named ‘ODataCustomizePayloadFormat’ with Microsoft.AspNetCore.OData (version-8.0.12) installed. You can follow up on my previous posts to build the project.
Within this application, I have two types of entities:
- Book: only contains primitive type properties
- Customer: contains properties of primitive, enum, complex type and collection of them
I have the corresponding controllers for both entity types and keep them as simple as possible, for example:
public class BooksController : ControllerBase
{
private static IList<Book> _books = GetBooks();
[HttpGet]
[EnableQuery]
public IActionResult Get()
{
return Ok(_books);
}
[HttpGet]
[EnableQuery]
public Book Get(int key)
{
Book b = _books.FirstOrDefault(c => c.Id == key);
return b;
}
// ......
}
I’m omitting other codes (such as Edm model builder, etc) from the post. Please refer to the sample here for details.
Implement CSV Format
In order to support the CSV format, we need to create the following four classes derived from the classes listed in the above overview section, respectively.
public class CsvMediaTypeResolver : ODataMediaTypeResolverThis class is used to build a mapping between the media type and an OData format. For example, it builds a mapping between text/csv media type and CsvFormat.public class CsvFormat : ODataFormatThis class is used to create the output context for writing and the input context for reading. In this post, I only cover the writing context.public class CsvOutputContext : ODataOutputContextThis class is used to create the CsvWriter, it acts as a bridge between ODataMessageWriter and the specific OData writer.public class CsvWriter : ODataWriterThis class is used to perform the ‘real’ writing process.
Let’s implement them one by one in detail.
CsvMediaTypeResolver
OData media type resolving is designed to get an ODataFormat based on the request metadata, such as Content-Type header, Accept header, etc. The resolving process depends on an ODataMediaTypeResolver which is registered as a service in the dependency injection service container. OData reader and writer would first call the GetMediaTypeFormats method as below from this service to get a list of supported ODataMediaTypeFormat based on the given ODataPayloadKind, then resolve media type information from request message to get the best matched ODataFormat.
public class ODataMediaTypeResolver
{
public virtual IEnumerable<ODataMediaTypeFormat> GetMediaTypeFormats(ODataPayloadKind payloadKind)
{ ......}
}
The default implementation of ODataMediaTypeResolver would return JSON format for data requests and XML format for metadata requests. To make media type resolver understand text/csv media type and return the corresponding CsvFormat, we can derive from ODataMediaTypeResolver and override GetMediaTypeFormats to inject our own behavior. Here’s the sample implementation:
public class CsvMediaTypeResolver : ODataMediaTypeResolver
{
private readonly ODataMediaTypeFormat[] _mediaTypeFormats =
{
new ODataMediaTypeFormat(new ODataMediaType("text", "csv"), new CsvFormat()),
};
public override IEnumerable<ODataMediaTypeFormat> GetMediaTypeFormats(ODataPayloadKind payloadKind)
{
if (payloadKind == ODataPayloadKind.Resource || payloadKind == ODataPayloadKind.ResourceSet)
{
return _mediaTypeFormats.Concat(base.GetMediaTypeFormats(payloadKind));
}
return base.GetMediaTypeFormats(payloadKind);
}
}
Where, I have a private field to hold a mapping between media type text/csv and an instance of CsvFormat, which is inserted into the list of ODataMediaTypeFormat in the overridden method GetMediaTypeFormats.
We should register the new media type resolver into the service container. I will share it in the following section.
CsvFormat
As mentioned above, we need an ODataFormat in the CsvMeiaTypeResolver to create the output context for writing and the input context for reading. ODataFormat is defined as an abstract class as below, so we should implement it.
public abstract class ODataFormat
{}
Below is the CsvFormat implementation:
public class CsvFormat : ODataFormat
{
public override Task<ODataOutputContext> CreateOutputContextAsync(
ODataMessageInfo messageInfo, ODataMessageWriterSettings messageWriterSettings)
{
return Task.FromResult<ODataOutputContext>(
new CsvOutputContext(this, messageWriterSettings, messageInfo));
}
// ……
// We don't need other overrides for writing, just throw NotImplementedException and omit them here…
}
In this post, we only need to implement the CreateOutputContextAsync method in CsvFormat to return a CsvOutputContext. For other overrides, let’s simply throw NotImplementedException exceptions since we don’t use them.
CsvOutputContext
As mentioned, output context acts as a bridge between ODataMessageWriter and the specific ODataWriter. ODataOutputContext is also defined as an abstract class, so we should implement it by ourselves. Here’s the CsvOutputContext implementation:
public class CsvOutputContext : ODataOutputContext
{
private Stream stream;
public CsvOutputContext(ODataFormat format, ODataMessageWriterSettings settings, ODataMessageInfo messageInfo)
: base(format, messageInfo, settings)
{
stream = messageInfo.MessageStream;
Writer = new StreamWriter(stream);
}
public TextWriter Writer { get; private set; }
public override Task<ODataWriter> CreateODataResourceSetWriterAsync(IEdmEntitySetBase entitySet, IEdmStructuredType resourceType)
=> Task.FromResult<ODataWriter>(new CsvWriter(this, resourceType));
public override Task<ODataWriter> CreateODataResourceWriterAsync(IEdmNavigationSource navigationSource, IEdmStructuredType resourceType)
=> Task.FromResult<ODataWriter>(new CsvWriter(this, resourceType));
public void Flush() => stream.Flush();
protected override void Dispose(bool disposing)
{
// ...... Omits the disposing codes
}
}
The implementation is simple. In the constructor, I create a StreamWriter to wrap the writing stream. Within the class, we only override the needed methods to create a writer for a resource set and a single resource. Be noted, to dispose the stream and the writer in the Dispose(bool) is important otherwise the content may be truncated, or no content is return at all. Thanks sifernan@microsoft.com
CsvWriter
CsvOutputContext is responsible for returning the OData writer to finish the ‘real’ writing operations. CsvWriter is such a class used to finish the CSV format writing. It is a class derived from abstract class ODataWriter, typically we should override the following four virtual methods to finish the resource set or resource writing:
public class CsvWriter : ODataWriter
{
public override Task WriteStartAsync(ODataResourceSet resourceSet)
{ }
public override Task WriteStartAsync(ODataResource resource)
{ }
public override Task WriteStartAsync(ODataNestedResourceInfo nestedResourceInfo)
{ }
public override Task WriteEndAsync()
{ }
}
Be noted, I use WriteEndAsync in the above class for consistency. Actually, I override the abstract method WriteEnd() in my sample, not the WriteEndAsync(), since WriteEndAsync() in the base class calls WriteEnd() directly.
It could be a little bit hard to understand the writing flow, for example, which method is called first, which is next, etc. Let me use the following example to illustrate it.
Supposed I want to write and get the below-left payload, I need a couple of OData objects (for example, ODataResoruceSet, ODataResource, etc) to call WriteStartAsync method. In the below-right picture, I list all OData objects related. The top level is an ODataResourceSet, it’s a collection of ODataResource, each ODataResource contains properties, and may contain a collection of ODataNestedResourceInfo.
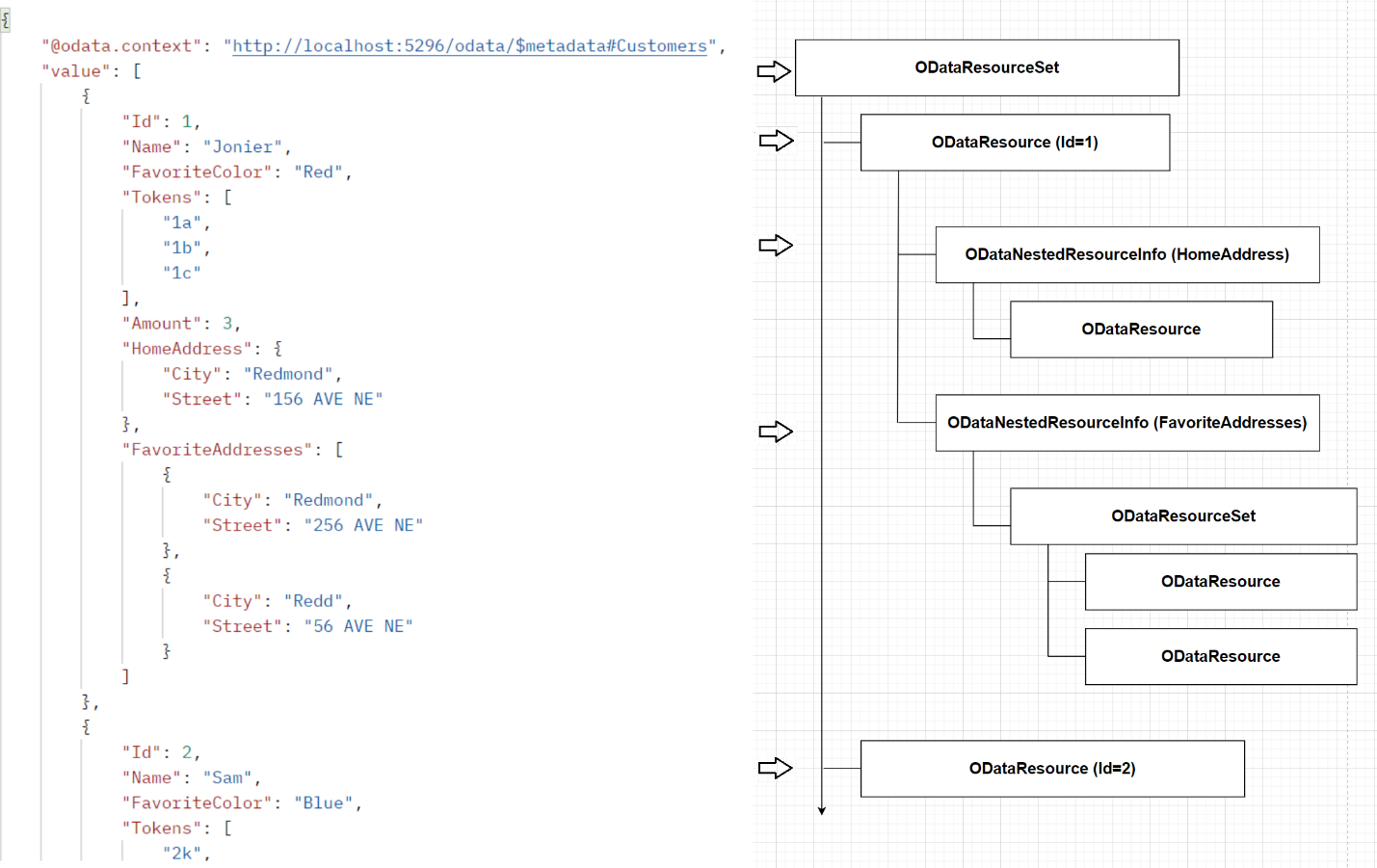
Here’s the simplified writing process for the above OData payload:

Where you can see that for each OData object, a WriteStartAsync is called first, then a WriteEndAsync is called at the end. We can embed more writing processes within it, and each writing process also starts calling WriteStartAsync, ends calling WriteEndAsync.
The implementation of CsvWriter depends on your requirement. You can refer to this post for a simple scenario, or you can refer to my implementation here for a little bit complex scenario, in which I have codes to write the nested properties.
Register CSV format
In the old version, we must register the CsvMediaTypeResolver on MessageWriterSettings. With ASP.NET Core OData 8.x version, it’s easy to inject the CsvMediaTypeResolver into the service container through dependency injection as below.
builder.Services.AddControllers().
AddOData(opt =>
opt.EnableQueryFeatures()
.AddRouteComponents("odata", EdmModelBuilder.GetEdmModel(),
service => service.AddSingleton<ODataMediaTypeResolver>(sp => new CsvMediaTypeResolver())));
Besides, we should let the existing OData formatter understand the new “text/csv” media type. We can achieve it using following codes:
builder.Services.AddControllers(opt =>
{
var odataFormatter = opt.OutputFormatters.OfType<ODataOutputFormatter>().First();
odataFormatter.SupportedMediaTypes.Add("text/csv");
});
Test
We finished all implementations. Let’s run and test it.
First, we send the “GET http://localhost:5296/odata/books” request without any other header settings. You can get the default JSON-formatted OData payload as:

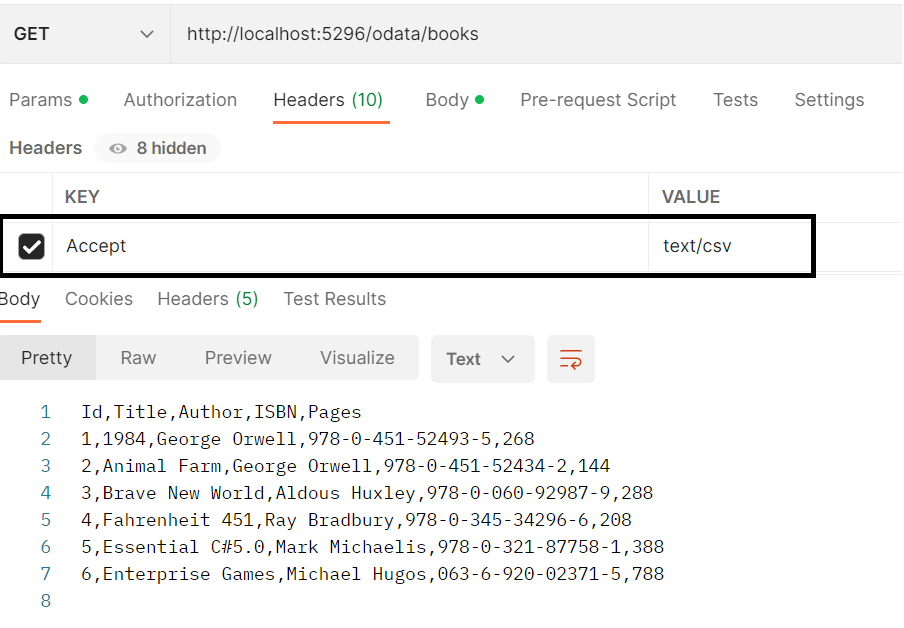
Resend the request “GET http://localhost:5296/odata/books” again with request header Accept=text/csv, we can get the OData CSV-formatted response payload as:
It also works with the OData query options such as:
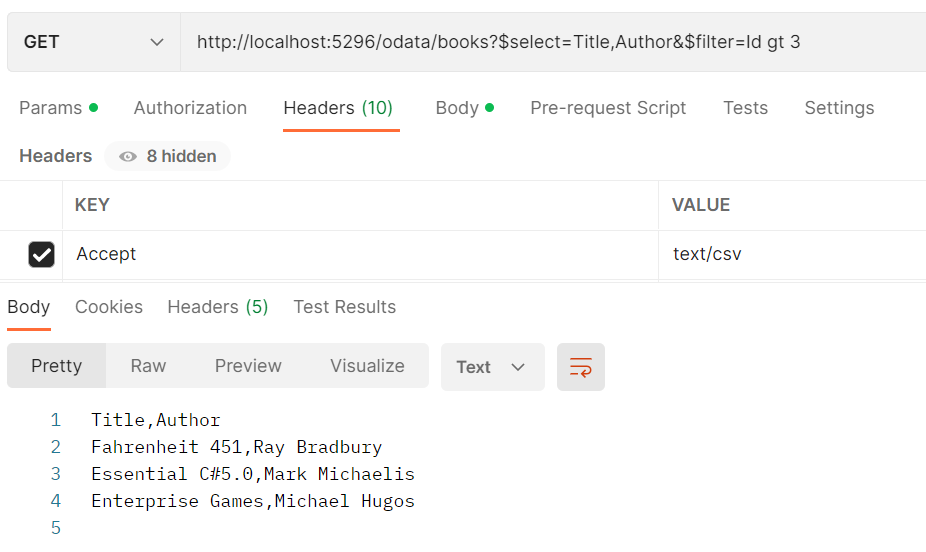
My CsvWriter implementation supports writing the nested resource (complex or collection of the complex). For simplicity, I write the nested single-value resource as “{propertyName=PropertyValue,…}”, and collection-valued nested resource as “[{nested resource},{…},…]”. You can change it to get any format for the nested resource.
Send the request “GET http://localhost:5296/odata/customers” with request header “Accept=text/csv”, we can get a little complex CSV-formatted OData payload.
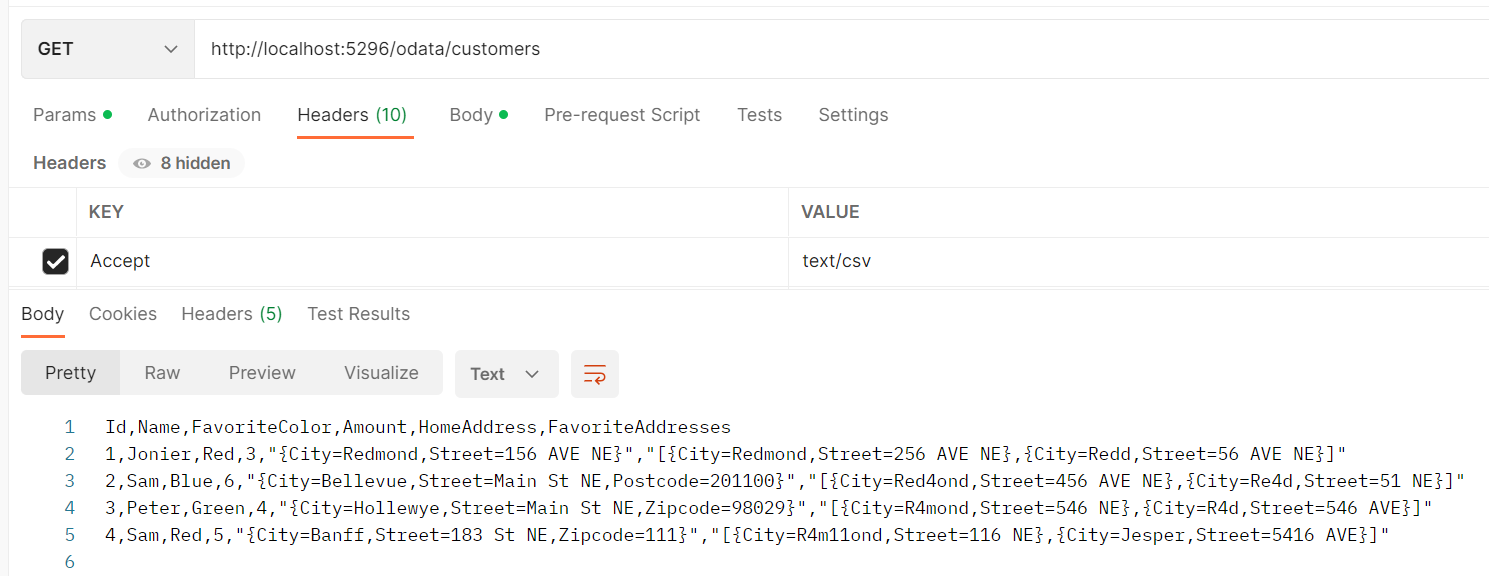
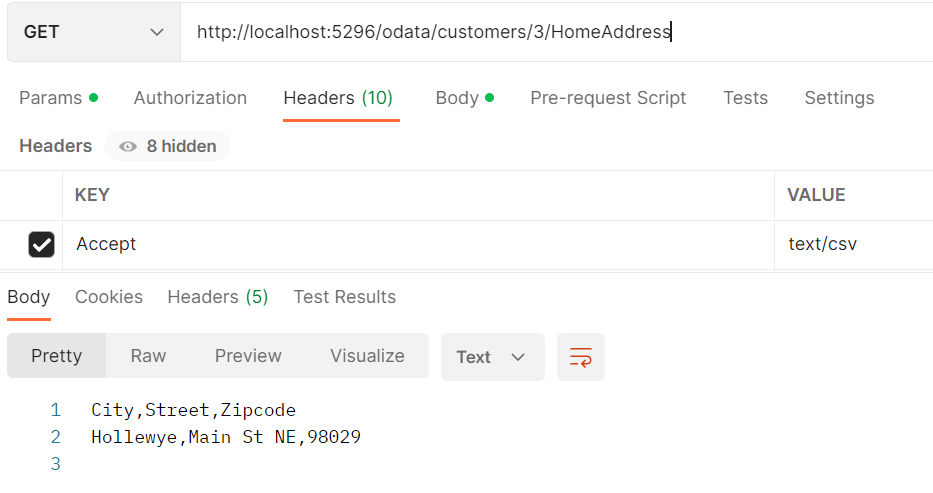
It also supports querying the simple property and writing it as a CSV.
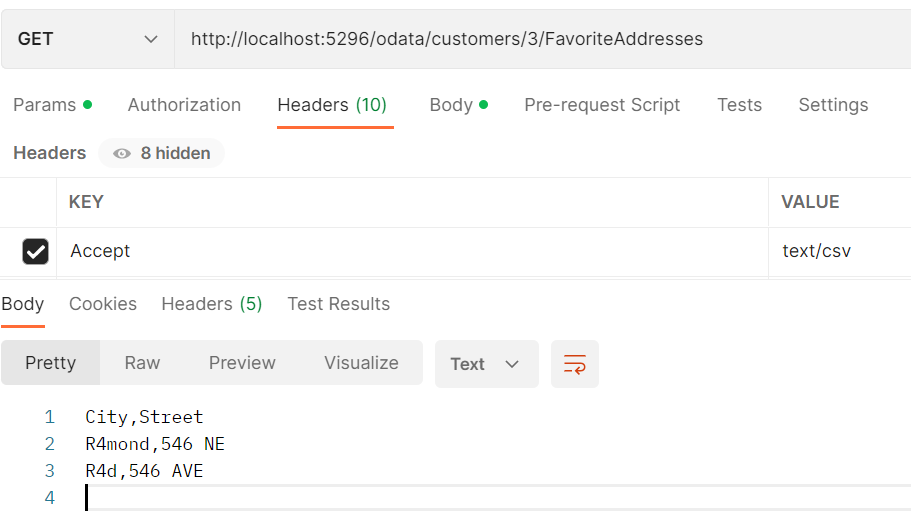
Again, we can also query the CSV-formatted collection complex property such as:
Yaml format
It’s easy to repeat the same process to customize the OData serialization payload to another format, for example, YAML. What we need is:
- a YamlWriter, which writes the resource, resource set as YAML format.
- a YamlOutputContext, which returns the instance of YamlWriter
- a YamlFormat, which returns YamlOutputContext
- a mapping within the media type resolver as:
private readonly ODataMediaTypeFormat[] _mediaTypeFormats =
{
new ODataMediaTypeFormat(new ODataMediaType("text", "csv"), new CsvFormat()),
new ODataMediaTypeFormat(new ODataMediaType("application", "yaml"), YamlFormat()),
};
- Finally, we must let ODataOutputFormatter understand the “application/yaml” media type.
builder.Services.AddControllers(opt =>
{
var odataFormatter = opt.OutputFormatters.OfType<ODataOutputFormatter>().First();
odataFormatter.SupportedMediaTypes.Add("text/csv");
odataFormatter.SupportedMediaTypes.Add("application/yaml");
});
You can find detailed YAML format implementation from my sample here.
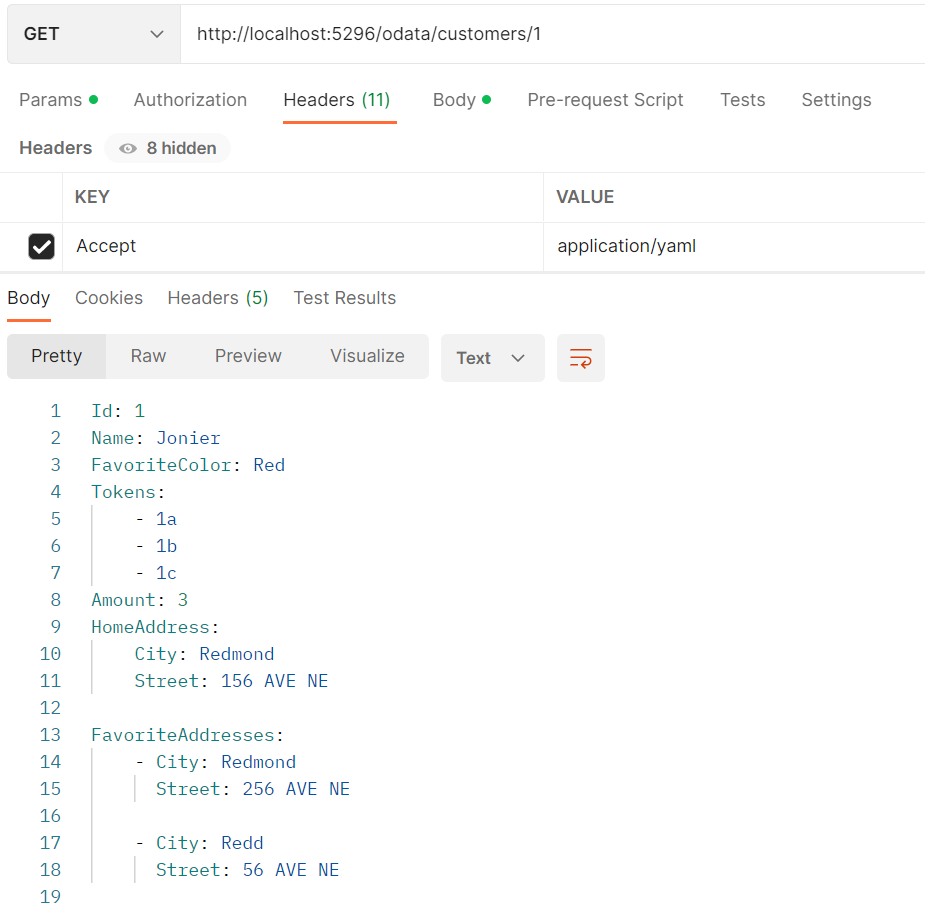
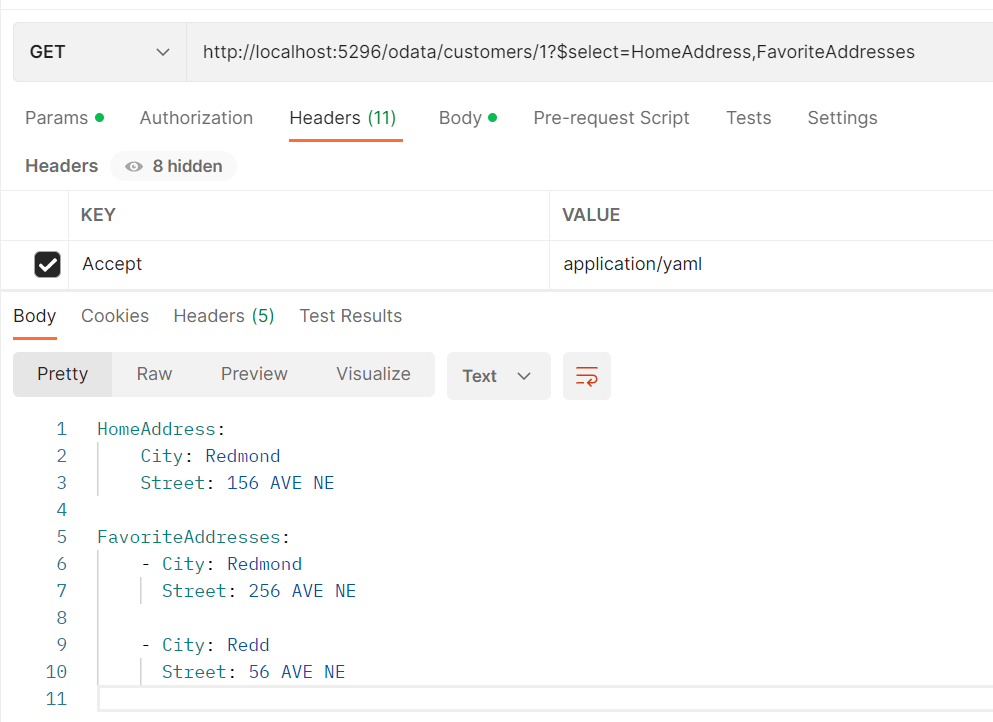
Ok. Once we finish the YAML implementation, let’s send the request “GET http://localhost:5296/odata/customers/1” with the request header “Accept=application/yaml“, so we can get a YAML-formatted OData payload.
Of course, it supports all scenarios mentioned in CSV. For example, It supports the query options:
Finally, Let’s use an example to put three formats together as a summary.
| GET http://localhost:5296/odata/books/2?$select=Title,Author | ||
| Accept=application/json;odata.metadata=none | Accept=text/csv | Accept=application/yaml |
{
"Title": "Animal Farm",
"Author": "George Orwell"
}
|
Title,Author Animal Farm,George Orwell |
Title: Animal Farm Author: George Orwell |
Summary
This post went through the steps to customize OData payload serialization as CSV, and YAML format within ASP.NET Core OData 8.x. Hope the contents and implementations in this post can give you an idea/direction to implement your own payload format customization. Please do not hesitate to leave your comments below or let me know your thoughts through saxu@microsoft.com. Thanks.
I uploaded the whole project to this repository.
Hello. I am trying to use a custom serializer since when using a dynamic dataset the odata serializer is not able to get the _properties from the class - for some reason the serializer is not registering the service - (this is code in program.cs to register serializer)
var model = new EdmModel(); //new ODataConventionModelBuilder();
// Define a dynamic entity set
var entityType = new EdmEntityType("myservice.Models", "DynamicEntityType");
model.AddElement(entityType);
//define the custom OData serializer for dynamic entities
builder.Services.AddSingleton(sp => new CustomODataSerializerProvider((IServiceScopeFactory)sp));
// Configure the OData route
builder.Services.AddControllers().AddOData(
options => options.EnableQueryFeatures(maxTopValue: null).AddRouteComponents(
routePrefix: "",
...
Do you mind filing an issue using this content at: https://github.com/OData/AspNetCoreOData/issues/new/choose
Thank you. I have done that.
Have any way to make this work in all endpoints?
I don’t know how can I do it at part of ‘AddRouteComponents’.
What do you mean? Would you please share more details about your requirement?
I need to specify EdmModels to register the new output format at ‘EdmModelBuilder.GetEdmModel()’.
builder.Services.AddControllers(). AddOData(opt => opt.EnableQueryFeatures() .AddRouteComponents("odata", EdmModelBuilder.GetEdmModel(), service => service.AddSingleton(sp => new CsvMediaTypeResolver())));The JSON output format we don’t need to specify the EdmModel, so my question is if have a way to use this output format to already existing models?
Per example in models assigned with ‘[EnableQuery]’.
a little bit confusing from your sentences. JSON output formatter don’t need specify the Edm model? You mean the System.Text.JSON (or Newtonsoft.JSON), right? If yes, I think those outputs are normal JSON data, OData JSON output formatter outputs OData payload, it contains ‘model validation’, extra control metadata, etc.
Would you please share more details or your requirements using a simple repro and share the link? Or I am open to having a remote chat to understand your requirement better?