

Let’s say you have a text file with one billion rows. Each row represents a measurement from various weather stations. You must write a Java program which reads the file, calculates the min, mean, and max temperature value per weather station, and displays the results sorted alphabetically by station. How fast do you think you could process this file? Welcome to the One Billion Row Challenge (1BRC).
The 1 billion row challenge
The beginning of 2024 got the Java community very excited. On the first of January, Gunnar Morling (Java Champion) announced on his blog the One Billion Row Challenge (1BRC). The idea was to write a Java program for retrieving temperature measurement values from a text file and calculating the min, mean, and max temperature per weather station. The file had 1,000,000,000 rows and the program should print out the values per station, alphabetically ordered.
The goal of the 1BRC challenge was to create the fastest implementation.
Immediatelly, hundreds of Java developers got into the challenge using different tricks and techniques to optimize their code: using low level Java APIs, virtual threads, the new Vector API or optimizing the Garbage Collector. I decided to enter the challenge using GitHub Copilot Chat for IntelliJ IDEA to learn about Copilot and see how much it could help me in a fairly niche performance optimization task.
GitHub Copilot Chat
GitHub Copilot Chat is a chat interface that lets you ask and receive answers to coding-related questions directly within a supported IDE (VS Code, JetBrains IDEs, Visual Studio). Copilot Chat can help you with a variety of coding-related tasks, like offering you code suggestions; providing natural language descriptions of a piece of code’s functionality and purpose; generating unit tests for your code; and proposing fixes for bugs in your code.
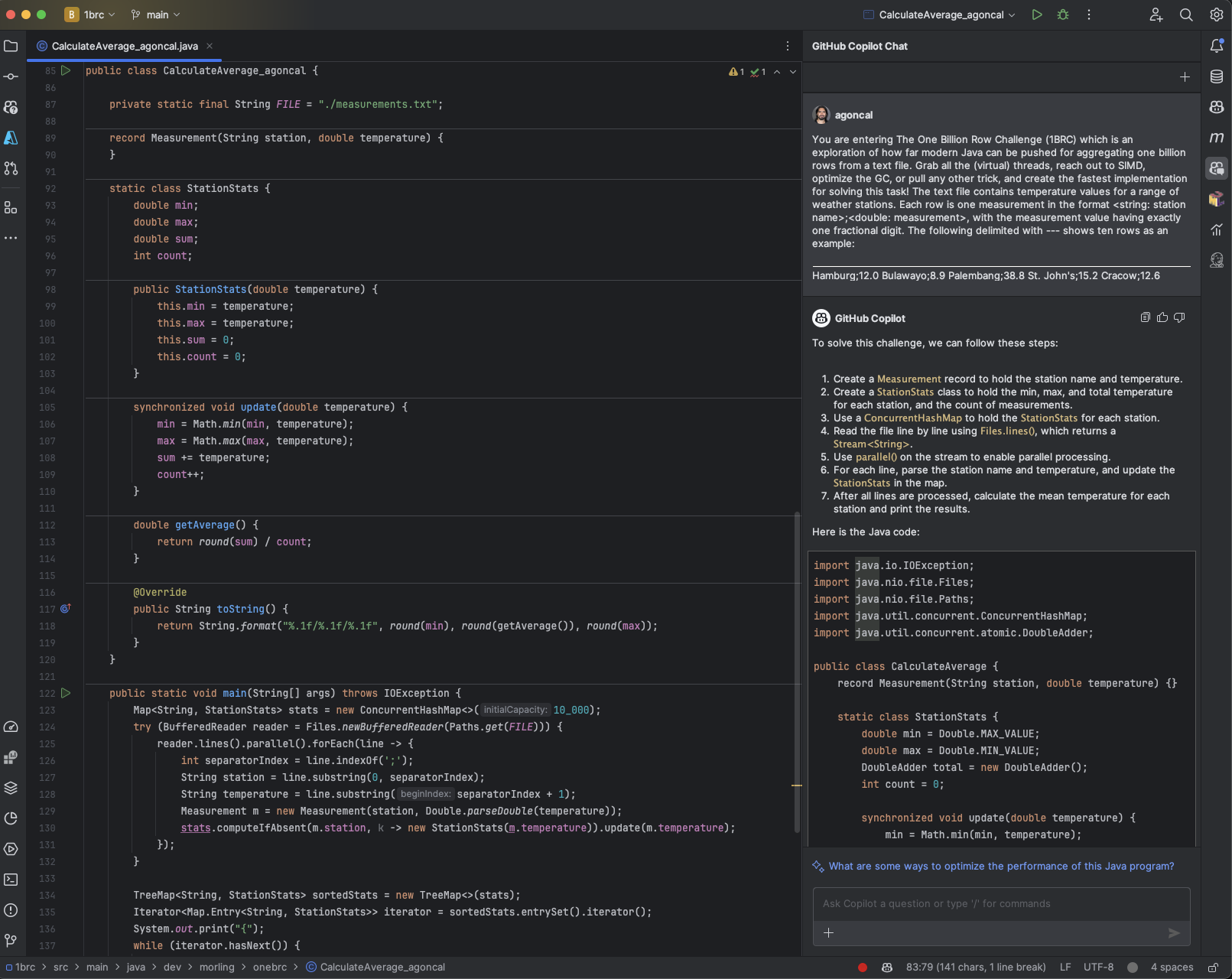
The First Prompt
I started the challenge by forking the One Billion Row Challenge repository and by creating an empty Java class. In GitHub Copilot Chat, I entered the following prompt:
You are entering The One Billion Row Challenge (1BRC) which is an exploration of how far modern Java can be pushed for aggregating one billion rows from a text file. Grab all the (virtual) threads, reach out to SIMD, optimize the GC, or pull any other trick, and create the fastest implementation for solving this task!
The text file contains temperature values for a range of weather stations. Each row is one measurement in the format <string: station name>;<double: measurement>, with the measurement value having exactly one fractional digit. The following delimited with --- shows ten rows as an example:
---
Hamburg;12.0
Bulawayo;8.9
Palembang;38.8
St. John's;15.2
Cracow;12.6
Bridgetown;26.9
Istanbul;6.2
Roseau;34.4
Conakry;31.2
Istanbul;23.0
---
You must write a Java program which reads the file, calculates the min, mean, and max temperature value per weather station, and emits the results on stdout like the result below delimited by --- (i.e. sorted alphabetically by station name, and the result values per station in the format <min>/<mean>/<max>, rounded to one fractional digit). Notice the curly braces:
---
{Abha=-23.0/18.0/59.2, Abidjan=-16.2/26.0/67.3, Abéché=-10.0/29.4/69.0, Accra=-10.1/26.4/66.4, Addis Ababa=-23.7/16.0/67.0, Adelaide=-27.8/17.3/58.5, ...}
---
You must use Java 21.
Create an algorithm in any way you see fit including parallelizing the computation, using the (incubating) Vector API, memory-mapping different sections of the file concurrently, using AppCDS, GraalVM, CRaC, etc. for speeding up the application start-up, choosing and tuning the garbage collector, and much more.
No external library dependencies may be used.
|
GitHub Copilot Chat’s first response was a version that I wasn’t very satisfied with. It was sequentially reading the text file, using basic Java APIs. So I asked Copilot Chat to read the file in parallel, and it responded with a better version of the code using Streams.
public static void main(String[] args) throws IOException {
Map<String, StationStats> stats = new ConcurrentHashMap<>(10_000);
try (BufferedReader reader = Files.newBufferedReader(Paths.get(FILE))) {
reader.lines().parallel().forEach(line -> {
int separatorIndex = line.indexOf(';');
String station = line.substring(0, separatorIndex);
String temperature = line.substring(separatorIndex + 1);
Measurement m = new Measurement(station, Double.parseDouble(temperature));
stats.computeIfAbsent(m.station, k -> new StationStats(m.temperature)).update(m.temperature);
});
}
TreeMap<String, StationStats> sortedStats = new TreeMap<>(stats);
Iterator<Map.Entry<String, StationStats>> iterator = sortedStats.entrySet().iterator();
System.out.print("{");
while (iterator.hasNext()) {
Map.Entry<String, StationStats> entry = iterator.next();
StationStats s = entry.getValue();
if (iterator.hasNext()) {
System.out.printf("%s=%s, ", entry.getKey(), s.toString());
}
else {
System.out.printf("%s=%s", entry.getKey(), s.toString());
}
}
System.out.println("}");
}
|
I ran the code and it worked instantaneously! I was very impressed by the result. In only a few prompts I got the algorithm working.
The 1BRC comes with a few tests to make sure you have the correct results, the correct numbers, and the correct formatting. The tests were failing on my code: my formatting was not correct and the min, mean, and max temperature values were not correctly rounded. I had to ask GitHub Copilot Chat to tweak the code a bit to pass the tests:
The output is not correct, make sure you have curly brackets at the beginning and at the end of the output. Each metric needs to be delimited by a comma, please change the algorithm. The calculation of the mean temperatures is not correct. The mean should be based on the rounded min and max, and then rounded itself. |
Optimizing the Algorithm
With the tests up and running, I was more comfortable in using GitHub Copilot Chat to optimize the algorithm. For example, I asked Copilot Chat to use a different data structure to store the results:
Being written in Java 21, please use records instead of classes when you can. |
Records are relatively new in Java, but GitHub Copilot Chat knew about them and answered with the following code:
record Measurement (String station, double temperature) { }
|
I kept on chatting with GitHub Copilot Chat to optimize pieces of the algorithm. I also used a runtime profiler to find out which parts of the code were slow or consumed too much memory, and asked Copilot Chat to optimize it.
If the temperatures are small numbers, why use double? Can't you use another datatype?
There is a maximum of 10000 unique station names. Can you optimize the code taking this into account?
The profiler mentions that the following line of code has very bad performance. Can you refactor it, so it has better performance:
---
String[] parts = line.split(";")
---
|
By the end of this conversation, I was able to run my code 15 seconds faster than the original prompt (80 seconds) reaching 65 seconds.
Optimizing the JVM
I then decided to tweak the JVM to make it run faster. The 1BRC allows you to pass any parameters you want to the JVM you want. Changing these parameters can have a huge impact on the performance of the application, for good or for bad. I asked GitHub Copilot Chat to help me tweaking the JVM.
Which parameters can I pass to the JVM to make it run faster? Which GC can I use to run my code faster? |
I realized that I hadn’t given enough information to GitHub Copilot Chat about the platform I was running on (macOS) and the version of the JVM I was running the code with (Microsoft Build of OpenJDK). Because I didn’t provide enough context, the first results were not very good. GitHub Copilot gave too much memory on the JVM and wasn’t setting up the Garbage Collector correctly. So, I used a few extra prompts:
You increased the memory too much; therefore, it does not start. Can you fix it? What are the available Garbage Collectors? Why should I use the Shenandoah GC? What are the benefits of using String Deduplication? The parameter you gave only works on the Oracle JVM, give me the equivalent for Temurin. |
During this phase, GitHub Copilot made a few mistakes. Some were easy to spot (e.g. the JVM did not start at all with wrong parameters), some were more difficult (you must run the profiler again to see if the performance is better or worse). With a few more prompts I finally got the following JVM parameters right:
- Use the Shenandoah Garbage Collection to reduce the GC pause time.
- Using String Deduplication to save some memory by referencing similar String objects instead of keeping duplicates.
JAVA_OPTS="--enable-preview -XX:+UseShenandoahGC -XX:+UseStringDeduplication -da" |
The result
With these few optimizations, I was able to run the code in less than one minute on my Mac M1 running on Sonoma with 8 cores and 64Gb of RAM. So, I created a Pull Request on the 1BRC repository and Gunnar Morling merged it. My code ran slower on the target platform (Hetzner AX161 server with eight cores): 1 minute and 9 seconds. I was disappointed because it was slower than what I had on my machine.
I knew my score was very far from the top submissions who were around 2 seconds, but it was faster than the 4 minutes 50 seconds base algorithm that Gunnar Morling created to give developers a base to start with. For reference, the fastest algorithms used different low-level technics:
- Partitioning the file into ranges equal to the number of available processors.
- Extracting and storing the weather station names using sun.misc.Unsafe as sequences of integers.
- Using parallelism, branchless code and implementing SWAR (SIMD as a Register).
- Implementing their own “very simple” HashMap backed by an array.
- Creating code without branches and instead performing a few complex arithmetic and bit operations.
- Compiling Java into native code using GraalVM
Feedback on Using GitHub Copilot Chat
I was genuinely impressed by the results achieved with GitHub Copilot Chat. In just a few prompts, I was able to get the algorithm up and running and then to pass the required tests. With only a few extra prompts I also managed to improve the performances of the algorithm and the efficiency of the JVM.
The dialogue with GitHub Copilot Chat was an ongoing process that lasted for several hours. It was able to maintain the context of the conversation effectively, providing relevant suggestions and solutions based on the current coding challenge.
After only a few hours, I decided to halt the experiment. As I observed the work of top submissions, it became clear that I could easily invest dozens more hours delving into various aspects of the Java language and runtime. I chose to stop, understanding that there’s always more to improve. But if I had continued, GitHub Copilot Chat would have been my number one choice to help me improving the performances.
So even if 1 minute and 9 seconds is far from 2 seconds, I thought it would be a good idea to write about this experience of developing with GitHub Copilot Chat.
Conclusion
Gunnar Morling created a fun and very interesting challenge. The Java community got very excited about it and hundreds of developers tried to optimize their code to get the best performances. Other languages also got into the challenge, like SQL, C, .Net, Rust, etc.
My algorithm is indeed slower than the top ones listed on the leader board. But it only took me a couple of hours to write, and the code produced by GitHub Copilot is easy to read and to understand… and still 4 times faster than the baseline.
During all the process I was the one in charge of the code. I was the one who decided to accept or reject the suggestions made by GitHub Copilot Chat, or to use a profiler or not. Sometimes GitHub Copilot would give me a suggestion that I would reject because I knew it would not improve the code. Sometimes I would just take control of the code and change it directly in the IDE. Sometimes I would impose my choices to GitHub Copilot (e.g. Being written in Java 21, please use records instead of classes). Sometimes GitHub Copilot gave me a suggestion that I knew wouldn’t improve the code, so I rejected it with a thumbs down (which helps Copilot provide better responses in the future).
GitHub Copilot Chat is a great tool to help developers’ productivity. Rest assured; it is not going to replace developers anytime soon. It will allow them to be more productive and to focus on their application logic and take care of a lot of a plumbing.
References
- The One Billion Row Challenge GitHub Repository
- The One Billion Row Challenge presented on Gunnar Morling’s blog
- The implementation done with GitHub Copilot Chat
- My PR: GitHub Copilot Chat with the help of agoncal
- InfoQ: The One Billion Row Challenge Shows That Java Can Process a One Billion Rows File in Two Seconds
- The One Billion Row Challenge with SQL
- The One Billion Row Challenge with PostgreSQL
- The One Billion Row Challenge in C
- The One Billion Row Challenge in .Net
- The One Billion Row Challenge in Rust
Hey Antonio, this is very interesting to me, I’ve one query can we implement it the Python?
currently I’m working on Random Phone Number , I’m looking to impletment the same.