

Introduction
Data validation is a key component in the realm of data warehousing, where the volume and diversity of data can be immense. Ensuring the quality of data is paramount when it is used for critical business decisions, especially in scenarios where accuracy and reliability must be meticulously guaranteed.
While data quality is ideally addressed during the extraction and transformation process, there are situations where it becomes imperative to run data validation tests with data at rest. The extraction and transformation steps offer the opportunity to cleanse and standardize data, setting a strong foundation for data quality. However, certain scenarios may make it challenging to enforce data quality at these early stages. This can occur when dealing with legacy systems, combining multiple external data sources, performing full table reloads, or when real-time processing constraints exist.
In a recent customer engagement, our team encountered these challenges when extracting data from SAP using Azure Synapse Analytics. We established a repeatable method to ensure data accuracy and reliability in our data warehouse. This post explains how we accomplished this with a data validation test suite in Synapse.
Defining the Test Plan and Important Metrics
The first step to the process is to define what and where to test. For us, the test cases were implemented based on a written AzDO test plan for two stages of our solution: the Gold and Serving landing zones.
We decided to focus on these data quality metrics:
- Consistency: Does our data match the source system?
- Completeness: Are there mismatched row counts between stages? Are all of the expected columns present?
- Accuracy: Are the column data types correct? Are numeric values rounded off correctly?
- Uniqueness: Are column values unique?
- Null/empty values: Do mandatory columns have null or empty values?
- Referential integrity: Does every row that depends on a dimension in the fact table actually have its associated dimension (i.e. foreign keys without a primary)?
Architecture
Our data validation test suite is a combination of data flows and pipelines within Synapse, triggered either by an Azure DevOps (AzDO) pipeline-based test harness or manually within Synapse itself. The results are retrieved via a second AzDO pipeline from the SQL database and are presented as a report within the pipeline run.
The infrastructure for this strategy requires:
- Source data to be tested
- Azure SQL database (DB) containing metadata
- Azure Synapse Analytics workspace
- Two AzDO pipelines (technically optional) to trigger the Synapse pipelines and retrieve the test results from the SQL DB
Note that Synapse needs to be able to access the SQL DB to read the metadata and also store the test results. Additionally, the AzDO pipelines need to be able to trigger the Synapse pipelines and retrieve the test results from the SQL DB (using the appropriate Service Connection permissions).
Metadata Database
Our solution relies on a proprietary SQL database known as the metadata database (metadata DB). This database serves as the backbone for our data warehousing solution and test suite. Our project’s dynamic nature and numerous entities necessitated the use of a metadata DB, which then enabled us to execute the same validations across multiple tables. If your data warehouse has a limited number of tables, consider simplifying your test suite instead of adopting this approach. The metadata we employ for the test suite includes:
- Table names
- Field names for each table
- Whether tables were considered in-scope to extract or not
- Expected data types of each field
- Table types (fact vs. dimension, etc.)
- Key fields for each table
- Length and decimals for numerical fields
This metadata plays a pivotal role in the test cases and orchestration setup. The test suite heavily relies on ForEach pipeline activities, especially after a lookup to the metadata DB when looping through in-scope tables. Pipeline parameters facilitate the passing down of metadata information to the data flows.
We also established a test schema in the metadata SQL DB, which serves as the organizational hub for all test suite-related entities. This schema encompasses tables, views, and stored procedures, including:
- Fact relationships: Defines relationships validated as part of fact table referential integrity check
- Field block list: Defines which fields in which tables to block/exclude from testing
- Field list: This is a view based on field metadata and and the field block list that defines which fields in which tables to test
- Test results: Sink for all test results from the test suite
- Generate test result: This is a stored procedure that generates the formatted NUnit XML output from the test results table
Implementation
Our approach involved implementing test cases individually as data flows. These data flow test cases are then grouped into Synapse pipelines based on the parameters they require to prevent unnecessary duplicate metadata lookups from the database. Some of these pipelines contain an “if” activity, which further categorizes test cases based on their type, and checks a boolean flag passed via pipeline parameter. These flags play a crucial role in specifying which test types should be run when initiating the main orchestration pipeline. The hierarchy typically follows this structure: Main Orchestration Pipeline > Test Suite Pipeline based on required parameters > “If” activity for categorizing individual data flow test cases > Test case data flow.
A visual representation of the structure might look like this:
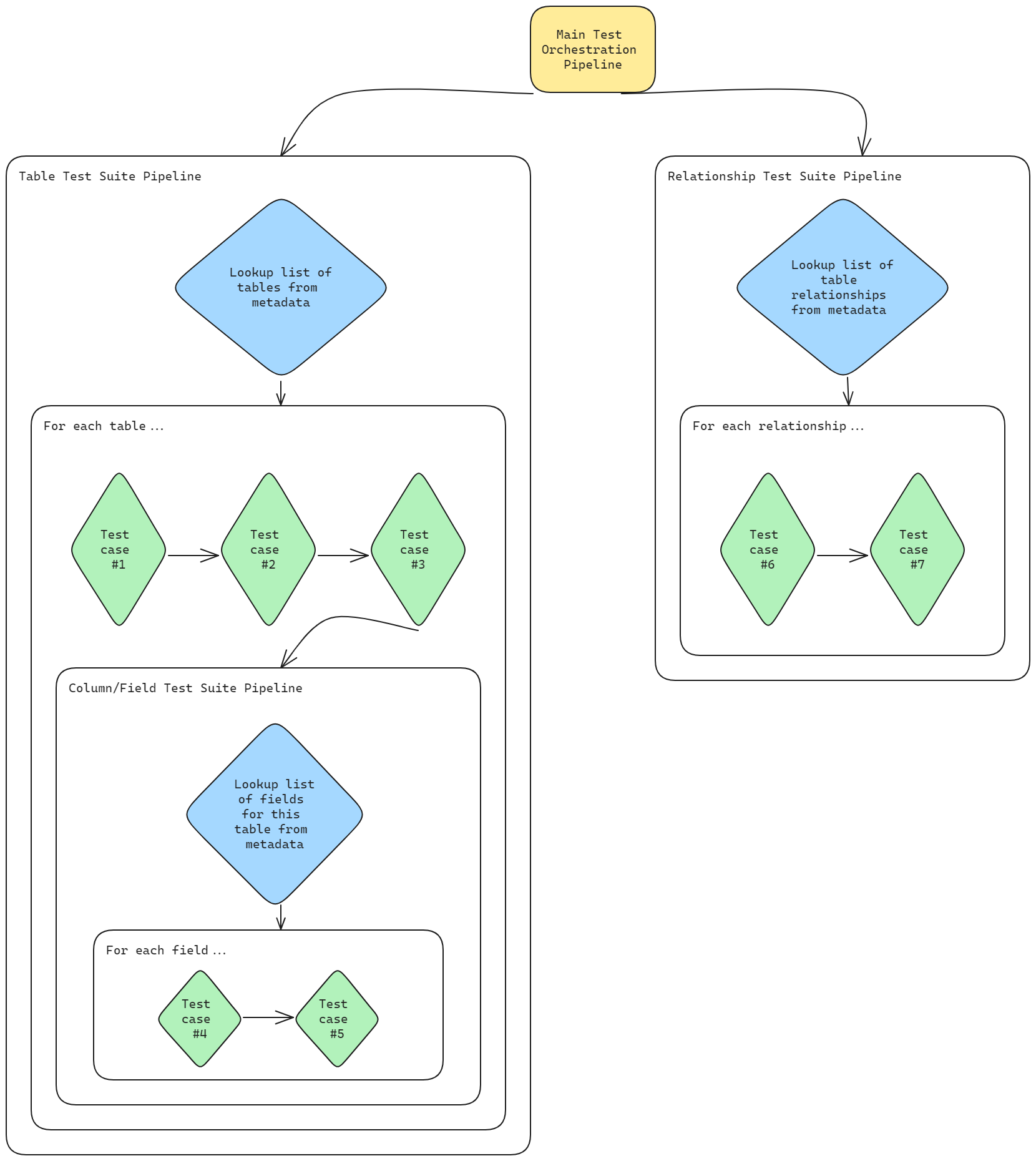
Anatomy of a Synapse Data Flow Test Case
Creating a data flow test case involves the following steps:
-
Create a new data flow in Synapse
- Add a source component that retrieves the relevant data (from Azure Data Lake Storage, DSQL, etc.).
-
Include activities and transformations that validate the intended data quality metric.
- This is where the “assert” and “derived column” transformations come in handy.
Using the “assert” transformation in a Synapse Data Flow, you can assert the result of your expression and it will show you which rows passed or failed.
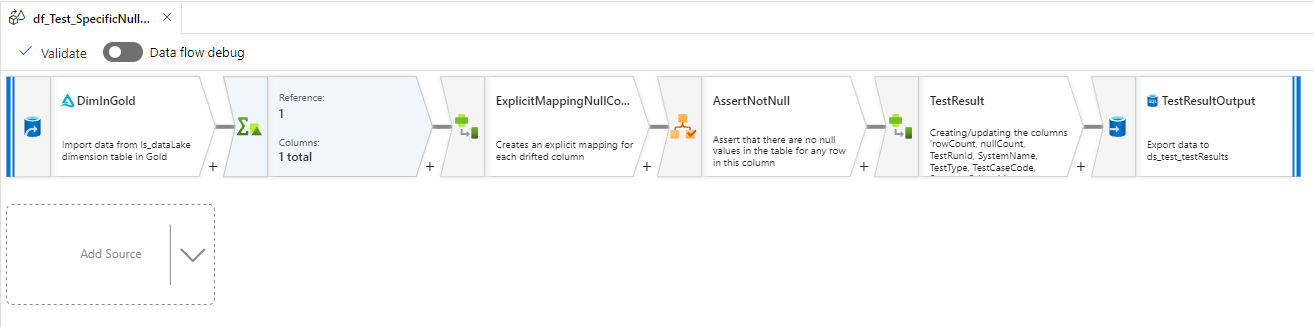
Additionally, using “assert” allows you to use
isError()andhasError()downstream in the flow, and it is possible to use a derived column to capture the results of the assert validation and add them as columns as well.Alternatively, when using a “derived column” transformation, you can add a new column that evaluates an expression using an
iif()function. In the example below, the new column shows if values in the “Name” column are null or not.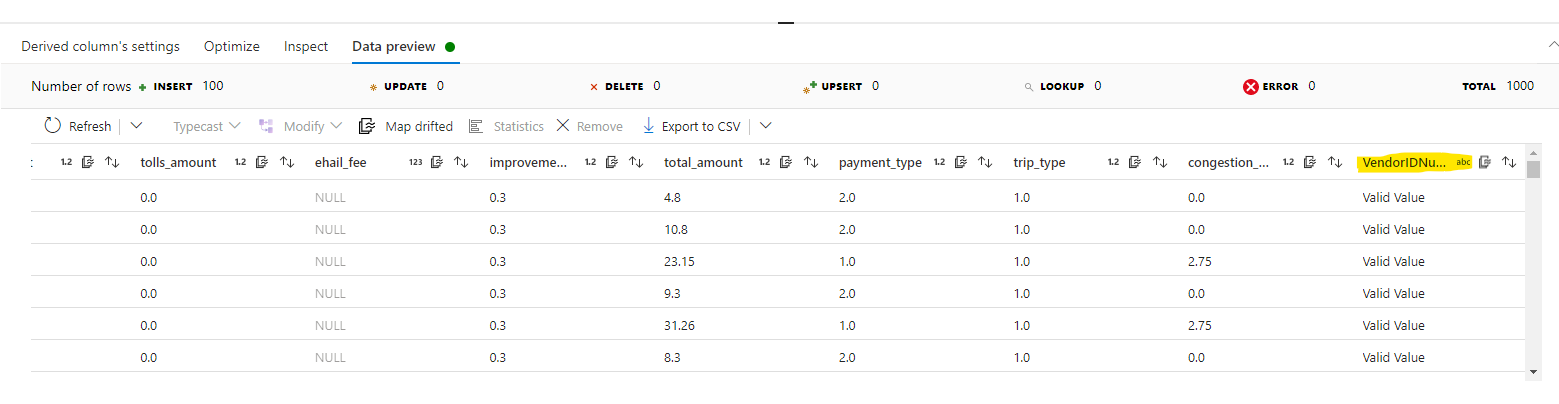
-
Add a “Derived Column” activity that adds columns needed for the test result format. We use the following columns:
TestType: A string specifying the test category (e.g., ‘SilverToGold.DataValidation’ for testing between Silver and Gold stages).TestCaseCode: A string providing a short identifier for the test case (e.g., ‘ColumnsExist.’ + $tableName for testing if columns persist).Success: An integer (1 for pass, 0 for fail) based on the test case outcome.FailureMessage: A string explaining why the test case failed.FailureDetails: A string offering more specific data on the failure (e.g., the number of rows with duplicated data).TestRunId: A string receiving the test run ID from the pipeline that initiated this data flow. (This run ID is passed down from the main orchestration pipeline to each data flow, and is how we can tell which test run the results are from!)
Example settings:
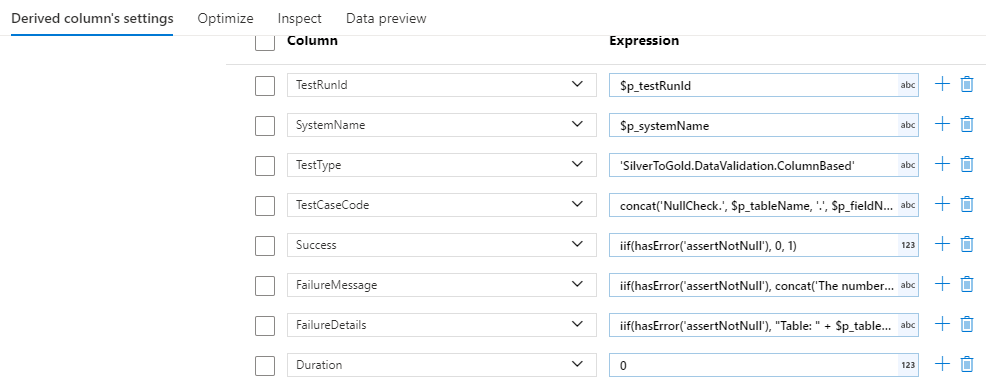
In the example, the
Success,FailureMessage, andFailureDetailsuse theiif(hasError('insert-assertion-id-here'), ...pattern because this derived column activity comes after an assert activity that enables the use ofhasErrorto report failures. - Add a “Sink” component to write the test results to the designated table in the metadata database.
-
Incorporate the data flow into one of the test suite pipelines, taking note of which test group it aligns with based on its required parameters. We established three primary test suite pipelines:
- A suite for cases requiring only table names to be looked up.
- A suite for cases needing table names, field names, and their data types.
- A suite utilizing the fact relationships table.
-
Further categorize data flows by their test type, allowing for more granular test suite execution using an “if” activity within Synapse pipelines.
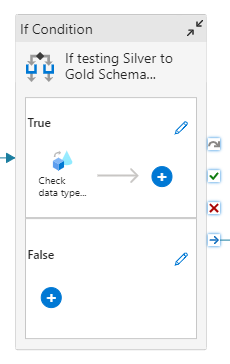
- Some examples of possible test types include schema validation, referential integrity tests, and column/field-based tests.
-
Ensure that the parameters supplied to the data flow are derived from the correct pipeline parameters or ForEach items. Proper parameter management is essential for test case success.
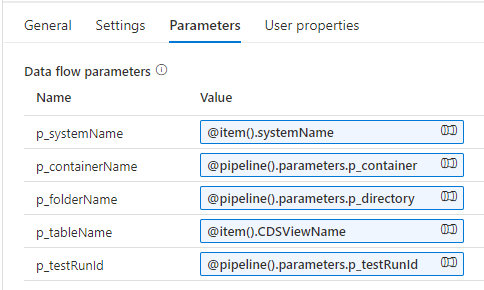
Running the Test Suite
To execute the test suite, follow these steps:
- Run the
trigger-synapse-pipelinepipeline in AzDO, specifying which test cases to run by enabling/disabling the appropriate boolean flag parameters. - Wait for the main test orchestration pipeline to complete in Synapse.
- Run the
retrieve-data-validation-test-resultspipeline in AzDO. - Inspect the test results within the “Tests” tab of the AzDO pipeline run.
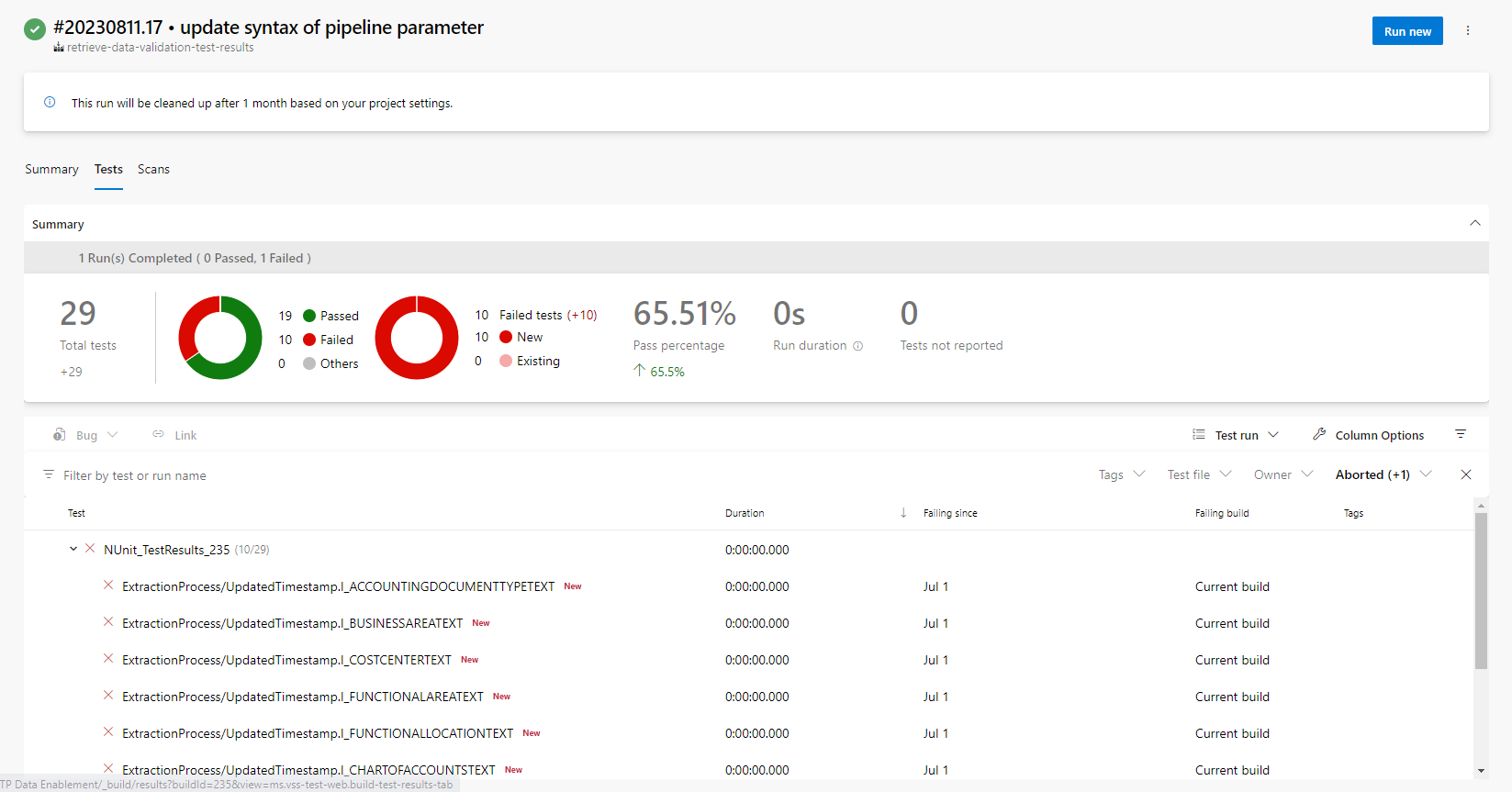
Alternatively, the data validation test suite can be run manually within the Synapse studio. You can also use the Debug option when triggering the pipeline to gather additional information during the run.
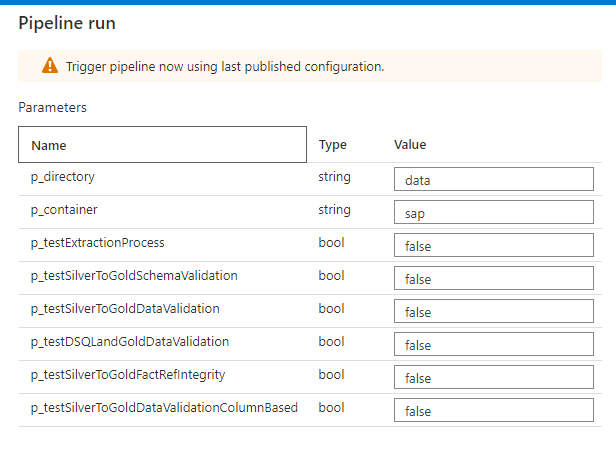
Once the pipeline run is complete, you can view the test results within the table in the metadata database, which has been used as the sink in your data flows. Simply use the query editor in Azure Portal within your metadata DB to manually inspect the results.
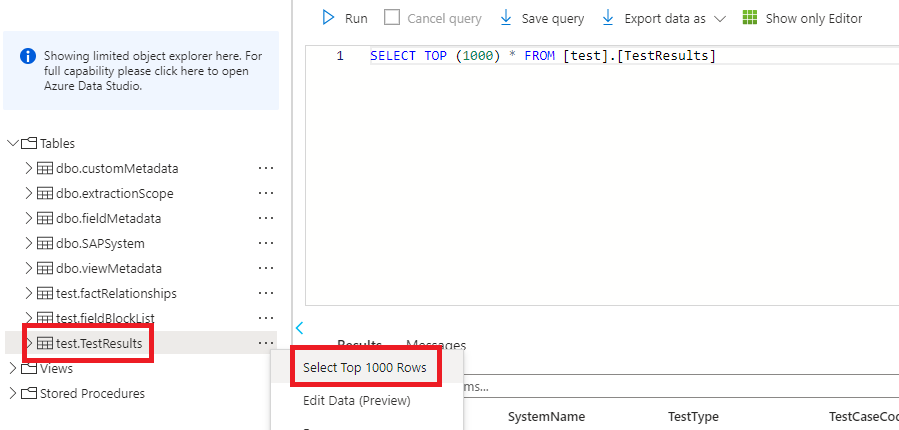
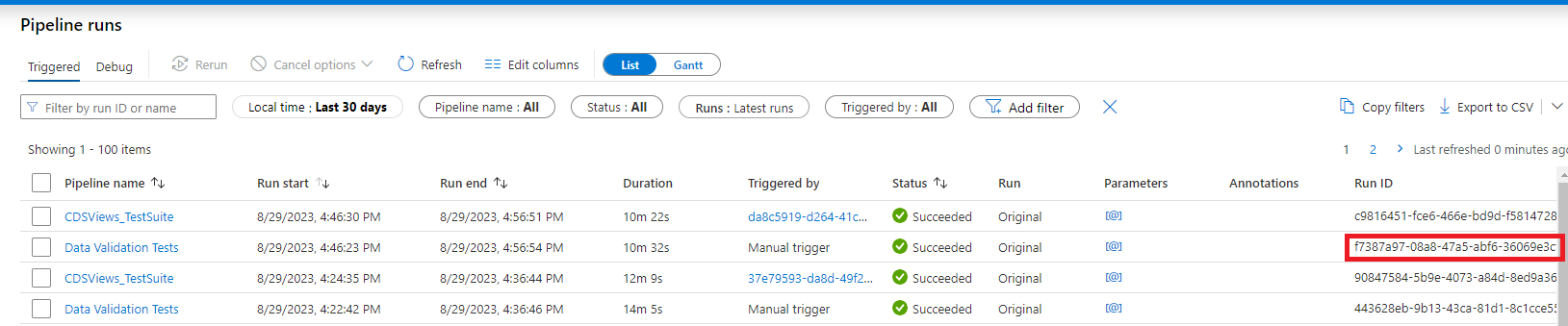
Ensure you employ a WHERE TestRunId = 'insert-pipeline-run-id-here' clause in your query to view results for the test run you’ve just completed. To obtain the pipeline run ID, navigate to pipeline runs in Synapse and locate the “Run ID” column for the main orchestration pipeline’s run. See the image below for an example, given that our main orchestration pipeline is Data Validation Tests.
Performance Considerations
Striking a balance between thoroughness and performance was a challenging aspect of this project. The computational resources utilized by our comprehensive data validation test suite were substantial, leading to increased costs and run times. While implementing your test cases, take into account the performance impacts they might have. For example, fact tables are typically larger than dimension tables, so it might be necessary to sample data in fact tables to prevent performance issues. In such cases, consider turning a test case into a random sampling test using a window transformation. Using boolean flags to separate different test types can also help reduce the run time of the test suite when you only need to run specific tests.
In our testing, the best Integration Runtime (IR) settings for our test suite were as follows:
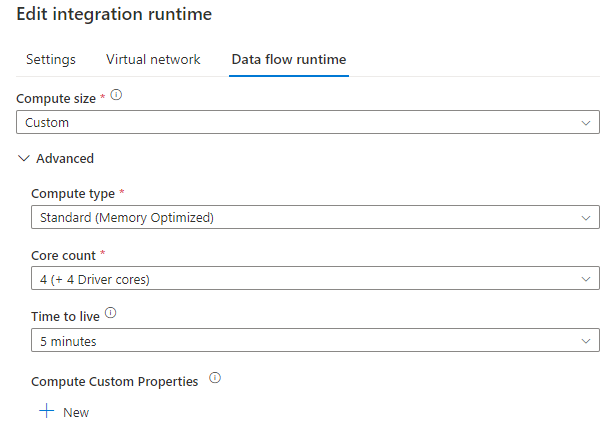
With these settings, the full test suite runs in approximately 90-120 minutes with our set of test data.
Test Result Format
The test results are written to the test results table in the metadata DB, with columns as described in the Anatomy of a Synapse Data Flow Test Case section. Using the GenerateTestResult stored procedure, called by the retrieve-data-validation-test-results AzDO pipeline, this data is converted into the NUnit XML format and displayed in the report in the AzDO pipeline run under the “Tests” tab.
For more information on the NUnit test result XML format, see this documentation.
Conclusion
This strategy, while effective for our specific project, may not be the ideal approach for every situation. The advantages include the visual nature of data flows and pipelines, consistency with the overall solution (which also uses data flows), the ability to clone existing test cases and make modifications, and the avoidance of manual testing, which can be error-prone and time-consuming. The drawbacks, however, include the performance issues we encountered and the challenge of diagnosing the root causes of detected problems. Different projects may necessitate alternative approaches, such as using Python in notebooks. Nevertheless, for our project, the benefits outweighed the drawbacks, and we successfully identified numerous issues through the test suite.
There are various ways to enhance this strategy further. One idea is to automate the triggering of the suite when changes occur. Another is to have the test failures notify stakeholders and provide information about the issues. Additionally, you can consider incorporating the validation quality checks into the solution itself or creating different test suites for different environments (Test, QA, Dev, Prod, etc.).
Acknowledgements
I want to extend my gratitude to my teammates for their invaluable contributions to this project. I did not undertake the task of writing all the test cases or creating the AzDO pipelines alone. I’d like to thank Kira Soderstrom and Diego Gregoraz for their outstanding work. Furthermore, I couldn’t have accomplished this without the support of my manager, Jeremy Foster, and TPM, Denise Burnett.