
Fortis is an open source social data ingestion, analysis, and visualization platform built on Scala and Apache Spark. The tool is developed in collaboration with the United Nations Office for the Coordination of Humanitarian Affairs (UN OCHA) to provide insights into crisis events as they occur, via the lens of social media.
A key part of the Fortis platform is the ability to search events (such as Tweets or news articles) for key figures or places of interest. To increase the accuracy and index quality of this search, Fortis uses named entity recognition to differentiate between normal content words and special entities like organizations, people or locations. This code story explains how Fortis integrated named entity recognition using Spark Streaming and Scala, the challenges faced with this approach and with running named entity recognition on the Java Virtual Machine (JVM), and our solution based on Docker containers and Azure Web Apps for Linux.
The state of open source named entity recognition on the JVM
Several well-known packages in the Java ecosystem offer natural language processing and named entity recognition capabilities; the table below lists some of them. However, many of these projects are either not licensed under terms acceptable for the MIT-licensed Fortis project, or target only a few languages. Some only offer generic named entity recognition such as “this is an entity” as opposed more granular details like “this is a place” or “this is a person.”
| Project | Languages | License | Disambiguation |
| Annie | English | GPL | Yes |
| Azure Cognitive Services | English | Azure | No |
| Berkeley | English | GPL | Yes |
| Epic | English | Apache v2 | Yes |
| Factorie | English | Apache v2 | Yes |
| OpenNLP | English, Spanish, Dutch | Apache v2 | No |
| Stanford | English, German, Spanish, Chinese | GPL | Yes |
The OpeNER project, created by the European Union with a conglomerate of research universities and industry, stands out as a key package for Fortis use since OpeNER offers named entity recognition in many languages (English, French, German, Spanish, Italian, Dutch) and is licensed under the Apache v2 license which makes it easy to integrate into an existing open source project.
Named Entity recognition via OpeNER
OpeNER is based on a simple pipeline model in which text is analyzed by a sequence of models, each step augmenting the source text with additional information that is used by subsequent steps. The pipeline model is illustrated in the figure below.
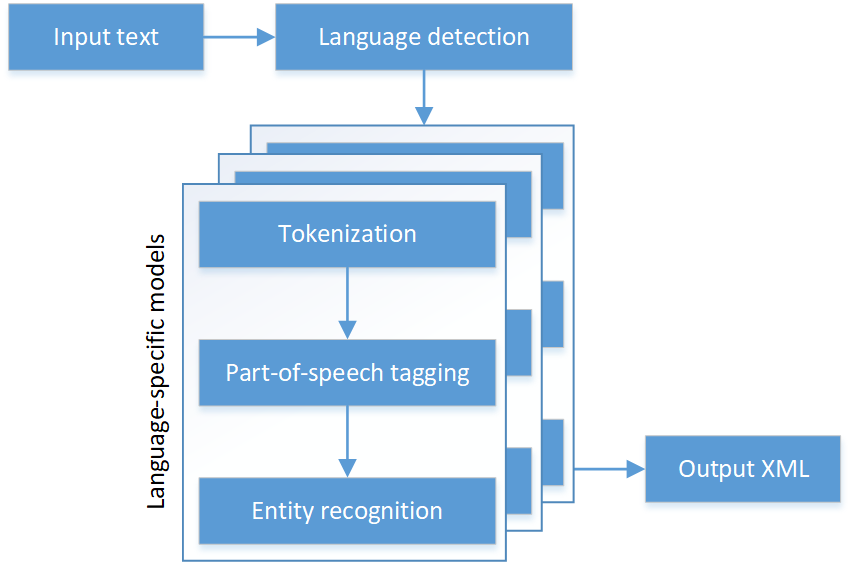
This pipeline can be added to a project via Maven and may be consumed from a JVM language such as Scala. The sample code below illustrates the analysis of an input text using the pipeline (see also the production code in the Fortis project). However, note that in the context of a Spark application the approach has four main limitations which will be discussed in the next section and addressed later in this code story.
// imports for the sample code below
import java.io.{BufferedReader, ByteArrayInputStream, File, InputStreamReader}
import java.util.Properties
import eus.ixa.ixa.pipe.nerc.{Annotate => NerAnnotate}
import eus.ixa.ixa.pipe.pos.{Annotate => PosAnnotate}
import eus.ixa.ixa.pipe.tok.{Annotate => TokAnnotate}
import ixa.kaflib.KAFDocument
// insert here the text from which to extract entities
val text = "..."
// language of the text, if unknown, can be inferred
// for example via Cognitive Services http://aka.ms/detect-language
val language = "..."
// path where OpeNER models are stored on disk
val resourcesDirectory = "..."
// do language processing, incrementally building up an annotated
// document in the standard "NLP Annotation Format" style https://aka.ms/naf
val kaf = new KAFDocument(language, "v1.naf")
doTokenization(resourcesDirectory, language, kaf)
doPartOfSpeechTagging(resourcesDirectory, language, kaf)
doNamedEntityRecognition(resourcesDirectory, language, kaf)
// code for the helper functions used above
def doTokenization(resourcesDirectory: String, language: String, kaf: KAFDocument): Unit = {
val properties = new Properties
properties.setProperty("language", language)
properties.setProperty("resourcesDirectory", resourcesDirectory)
properties.setProperty("normalize", "default")
properties.setProperty("untokenizable", "no")
properties.setProperty("hardParagraph", "no")
val input = new BufferedReader(new InputStreamReader(new ByteArrayInputStream(text.getBytes("UTF-8"))))
new TokAnnotate(input, properties).tokenizeToKAF(kaf)
}
def doPartOfSpeechTagging(resourcesDirectory: String, language: String, kaf: KAFDocument): Unit = {
val properties = new Properties
properties.setProperty("language", language)
properties.setProperty("model", new File(resourcesDirectory, s"$language-pos.bin").getAbsolutePath)
properties.setProperty("lemmatizerModel", new File(resourcesDirectory, s"$language-lemmatizer.bin").getAbsolutePath)
properties.setProperty("resourcesDirectory", resourcesDirectory)
properties.setProperty("multiwords", "false")
properties.setProperty("dictag", "false")
properties.setProperty("useModelCache", "true")
new PosAnnotate(properties).annotatePOSToKAF(kaf)
}
def doNamedEntityRecognition(resourcesDirectory: String, language: String, kaf: KAFDocument): Unit = {
val properties = new Properties
properties.setProperty("language", language)
properties.setProperty("model", new File(resourcesDirectory, s"$language-nerc.bin").getAbsolutePath)
properties.setProperty("ruleBasedOption", "off")
properties.setProperty("dictTag", "off")
properties.setProperty("dictPath", "off")
properties.setProperty("clearFeatures", "no")
properties.setProperty("useModelCache", "true")
new NerAnnotate(properties).annotateNEs(kaf)
}
After running text through the pipeline, it is now possible to extract entities from the annotated pipeline output. OpeNER supports eight types of entities ranging from concrete real-world entities such as “person”, “geopolitical entity (GPE)” or “location” to more abstract concepts like “date”, “time” and “money.”
// imports for the sample code below
import scala.collection.JavaConversions._
import ixa.kaflib.Entity
// find the entities in the text annotated by the OpeNER pipeline
val entities = kaf.getEntities.toList
// here is an example of how to access place and person entities
// the full list of entities can be found at https://aka.ms/opener-entities
val places = entities.filter(entityIs(_, Set("location", "gpe")))
val people = entities.filter(entityIs(_, Set("person")))
// code for the helper functions used above
def entityIs(entity: Entity, types: Set[String]): Boolean = {
val entityType = Option(entity.getType).getOrElse("").toLowerCase
types.contains(entityType)
}
Simplifying the integration with OpeNER via Docker and Azure Web Apps for Linux
In a Spark application context, several issues exist in the approach outlined above:
- The model binaries must be managed and deployed to every Spark worker node
- Loading the models from disk is time-consuming for short-lived Spark workers
- Spark workers are often run with low-spec resources for scaling horizontally instead of vertically
- Model files, however, are large binaries so Spark workers can run out of memory when loading more than one or two models
To address these limitations, OpeNER has the option to host models behind HTTP services so that developers can separate their natural language processing infrastructure from their application infrastructure. These HTTP services are simple to consume but hard to set up since they have several complex dependencies. To simplify deployment, the Fortis team created Docker images for each of the services. It is possible to run the services locally as follows (using Bash, after installing Docker):
# start the OpeNER containers docker run -d -p 8080:80 cwolff/opener-docker-language-identifier docker run -d -p 8081:80 cwolff/opener-docker-tokenizer docker run -d -p 8082:80 cwolff/opener-docker-pos-tagger docker run -d -p 8083:80 cwolff/opener-docker-ner # verify that the four containers started above are running docker ps # input some text to be processed by the OpeNER pipeline text_raw="I went to Rome last year. It was fantastic." # run the text through the OpeNER pipeline text_with_language="$(curl -d "input=$text_raw" http://localhost:8080)" text_tokenized="$(curl -d "input=$text_with_language" http://localhost:8081)" text_tagged="$(curl -d "input=$text_tokenized" http://localhost:8082)" text_entities="$(curl -d "input=$text_tagged" http://localhost:8082)" # check the output XML, the token "Rome" is identified as a place entity echo "$text_entities"
Each of the Docker images also comes with a one-click deployment template to set up and run the services in production on Azure Web Apps for Linux. The one-click deployment templates can be found in the following repositories on Github:
- opener-docker-language-identifier
- opener-docker-tokenizer
- opener-docker-pos-tagger
- opener-docker-ner
The one-click deployments running the OpeNER containers on Azure Web Apps for Linux are convenient as they offer a simple deployment and management story. Deploying the services is as simple as clicking the “Deploy to Azure” button on the GitHub repositories and stepping through the wizard. Once the deployment is done, the Azure Portal can be used to easily scale the services horizontally (distributing the service over more instances) and vertically (hosting the service on more powerful virtual machines).
When dealing with large workloads with low latency or high-throughput requirements, however, introducing four HTTP hops for natural language processing will be prohibitively expensive. In such scenarios, there is the option to run the natural language processing models in-process as described earlier in this post or to host multiple Docker images for the OpeNER services on the same host and expose them via a wrapper service such as opener-docker-wrapper. An end-to-end usage example of the wrapper service can be found in its Github repository. Deploying the wrapper service on an Azure Standard F1 Virtual Machine leads to an average entity extraction speed of 280ms per request with a standard deviation of 165ms.plea
The ability to identify entities, such as places, people, and organizations adds a powerful level of natural language understanding to applications. However, the open source ecosystem for named entity recognition on the JVM is quite limited, with many projects either being licensed under non-permissive licenses, targeting few languages or being hard to deploy.
To solve this problem, the Fortis team created an MIT-licensed one-click deployment to Azure for web services that lets developers get started with a wide range of natural language tasks in 5 minutes or less, by consuming simple HTTP services for language identification, tokenization, part-of-speech-tagging and named entity recognition. These services can be used in a wide variety of additional contexts including identifying organizations in product reviews, automatically tagging places in social media posts, and so forth.
Resources
- Language identification service Docker image
- Tokenization service Docker image
- Part-of-speech tagging service Docker image
- Named entity recognition service Docker image
- Cross-service batch request wrapper server
- OpeNER natural language processing tools project
- Deploying Docker images via Azure Web Apps for Linux