

In this article, we’ll explore the challenges we faced in establishing LLMOps and continuous evaluation within a pipeline using Azure Machine Learning. In particular, when dealing with long runs and a restricted Bring-Your-Own (BYO) network.
Background
In our recent engagement, we developed a Large Language Model (LLM) application using Prompt Flow and conducted our experimentation and evaluation in Azure Machine Learning (AML). We established an automated pipeline to run the evaluations before deploying any changes. Since it was a restricted network and it was the first time the customer used Azure ML service in their environment, we had to do a lot of configuring, workarounds, and whitelisting of services to achieve it. We had also run an end-to-end evaluation on the LLM chat application, which took 6 hours. The Data Science (DS) team realized that this E2E evaluation run need not run for every commit, so we provided a mechanism to skip it and provided an option to the DS and Engineering team to make a conscious decision per CI run based on the committed changes.
Restricted network
The private network in this engagement in Azure operates entirely on private IPs within a Virtual Network , ensuring security and isolation. The network is divided into subnets, each hosting specific resources based on their roles and functionalities. Communication between resources occurs internally within the Virtual network, with strict controls to prevent unauthorized access. Network Security Groups enforce whitelisting rules, allowing only trusted IPs or specific resources to connect. The network is fully private, with no public IPs, relying on private endpoints or secure tunnels like VPN gateways for controlled external access. This design ensures a robust and secure environment for sensitive workloads.
Overall Pipeline flow
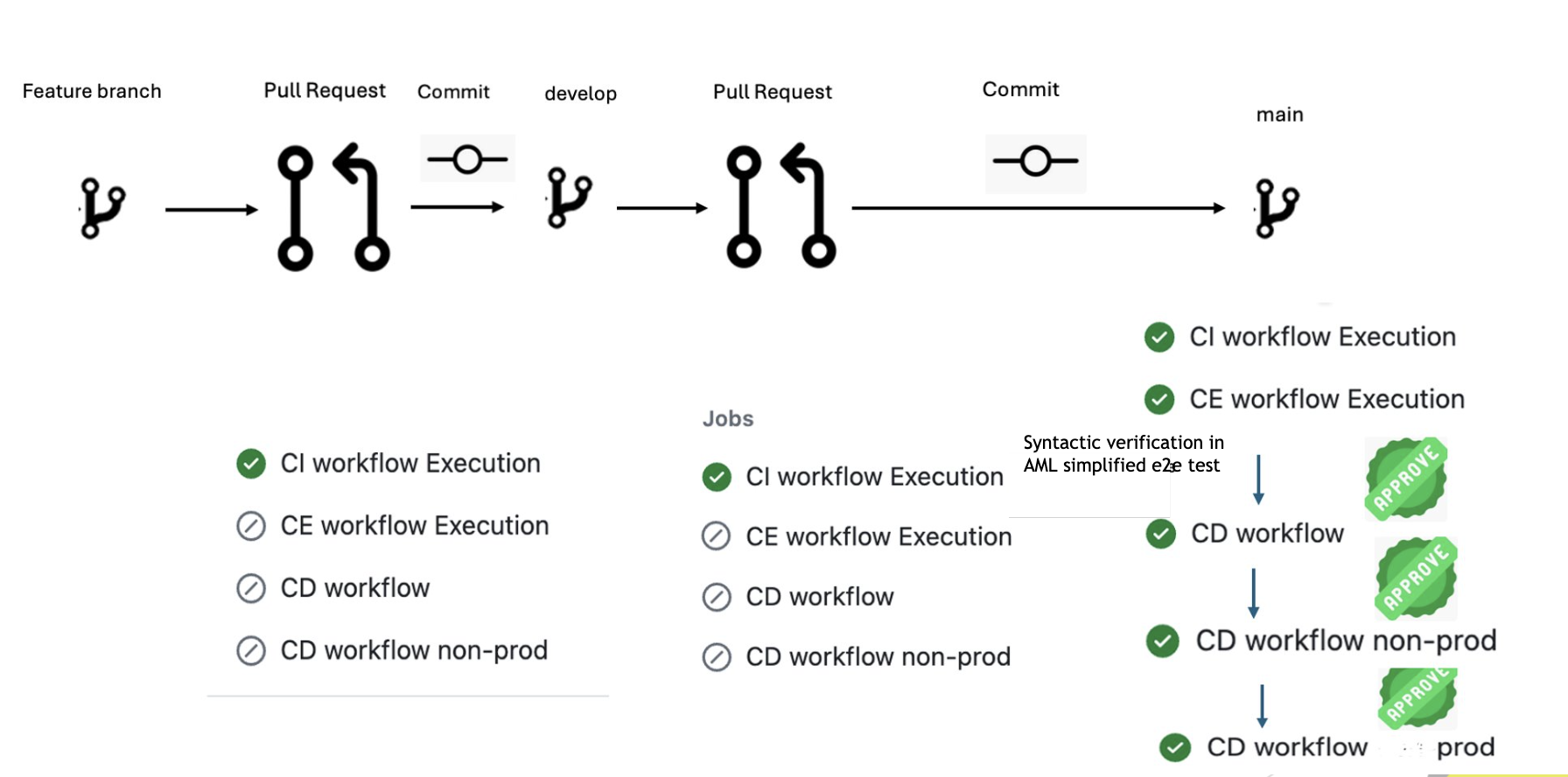
Branching strategy with git flow
There are three branches involved in the entire process
- develop branch – This is the gatekeeping branch from where the developer created a feature branch to do his/her changes and controlled when a release happens from the main branch by creating a PR.
- feature branch – Developers would branch from the develop branch, develop their changes, test it, and create pull requests (PR) back to the develop branch. This follows a naming rule developer-name/issue-id-feature-name
- main branch – Deployments happen when changes are merged to the main branch.
Considerations for branching strategy
The Benefits of Git Flow:
- Organized Work: The various types of branches (feature, release, hotfix, etc.) make it easy and intuitive to organize your work.
- Efficient Testing: The systematic development process allows for efficient testing at different stages.
- Multi-Version Support: The use of release branch-main allows you to easily and continuously support multiple versions (we used semver) of code and control deployments (e.g. deploy changes when a feature is complete and not deploy on every commit).
The Challenges of Git Flow:
- Over complication: Depending on the complexity of the product, the Git flow model could over complicate and slow the development process and release cycle.
- Delay in deployments: Hot fixes and bug fixes must follow the full Git flow. Bypassing this process can cause code conflicts, disruptions and breaching the process in place.
The challenge of LLM application development, or with any ML application development, is that it involves Data Scientists, Engineers, and Platform teams all collaborating and working on independent modules. Adopting the git flow strategy, and having a representative to own and perform releases, helped our team reliably perform controlled releases of changes.
Steps in each component
Our pipeline is made up of three core components. These are listed below alongside some of the actions performed in these stages.
CI: Continuous Integration
- Code Quality Checks
- Unit Tests
- End-to-end Flow (PromptFlow) syntactic validation on the Sample Data
CE: Continuous Evaluation
- Environment setup
- Synthetic data preparation for evaluation
- (PromptFlow) Node-level Evaluation
- (PromptFlow) Node-level Evaluation metrics
- (PromptFlow) End-to-end Flow Simulation and Evaluation
- PromptFlow registered in Azure ML
CD: Continuous Deployment
- PromptFlow is Versioned
- Versioned PromptFlow is containerized
- Image pushed to Azure Container Registry
- PromptFlow deployed to Azure Web App
- Smoke Test on the test dataset
- Endpoint monitoring (Health checks on the hosted endpoint)
- Performance monitoring (Response time, Latency, etc. reviewed)
Detailed Steps and flow:
PR creation from ‘feature’ branch to ‘develop’
PR from feature to develop runs CI checks and merges on success, needing human intervention on failure.
PR creation from ‘develop’ branch to ‘main’
PR from develop to main runs CI checks and syntactic check with end to end flow, merging on success and needing human intervention on failure.
Code merged to main and deployment to dev environment
Code on main runs CI and CE stages, builds Docker, deploys to dev if successful, and requires human approval which requires human intervention on failure.
Deployment to Non-Prod environment
Builds Docker image from main, pushes to Azure Container Registry, deploys to Azure WebApp with human approval which requires human intervention on failure.
Deployment to Prod environment
Deploy to prod builds Docker, pushes to Azure Container Registry, and deploys to WebApp with human approval which requires human intervention on failure.
LLMOps Pipeline Challenges
- The proof of concept for the llmops-promptflow-template demonstrated the integration with the pfazure SDK. Initially, there was an issue with resolving the compute/runtime host, which was later fixed by configuring the Fully Qualified Domain Name (FQDN). The pfazure SDK is designed to be generic, but handling compute host resolution at the SDK level within the PFClient module presented challenges. Specifically, maintaining a customer-specific version of the SDK to accommodate these changes is cumbersome and requires additional maintenance efforts.
- AML managed end point was not working with private network and integrated services and needs to fall back to the pf docker packaging and deploy in the web service which again made it impossible to use llmops-promptflow-template samples.
- Lengthy process to get permissions for the Service Principal to access AML and other resources which were specific to the customer.
- The blob storage and other resources need to be resolved to the private IP which required explicit no proxy configurations in the scripts used in the pipeline.
LLMOps Pipeline decisions
- After the FQDN was added the samples from llmops-promptflow-template would work. However, we decided to do the AML flow validations with command line to keep pipeline lightweight and reduce maintenance of scripts required in platform side.
- The links to the metrics and AML jobs for end-to-end component validations will be provided in the summary, and they will be validated manually by the data scientist before promoting to the next stages.
- The end-to-end evaluation flow, which takes 6 hours because it runs a very large set of simulated data and goes through a detailed evaluation flow , doesn’t need to run for every release. This process was improved by making it configuration-driven. Now, whether the evaluation runs or skips in the CE pipeline is dictated by a pull request label set for the release. More details about it is in the below section.
End to end (e2e) evaluation flow based on pull request label
End to end (e2e) evaluation run takes ~6hrs to complete – which might not be needed to run for all the cases. For example, if it is a simple bug fix then it can be skipped, and the team can avoid waiting 6 hours for the deployment.
We introduced an opt-out flag to allow the person creating the PR into main to avoid executing the full end-to-end eval run if it is not necessary.
- when opt-out flag is ON – long running e2e eval flow is not executed as part of CE pipeline
- when opt-out flag is OFF – long running e2e eval flow is executed as part of CE pipeline
To avoid creating bottleneck for Dev deployment, we will have two end-to-end eval runs:
- end-to-end run on a minimal dataset will be executed before every Dev deployment (~30 mins)
- End-to-end on a complete dataset is executed in parallel with Dev deployment (~6hrs), and has an opt-out option as set by the PR label
Conditional End-to-End Evaluation Based on PR Labels
- Label Definition: Define a specific label in your version control system (like GitHub, GitLab, Azure devops etc. since they support PR labels) that signifies the need for an end to end evaluation. For example, you might create a label named skip-e2e-evaluation.
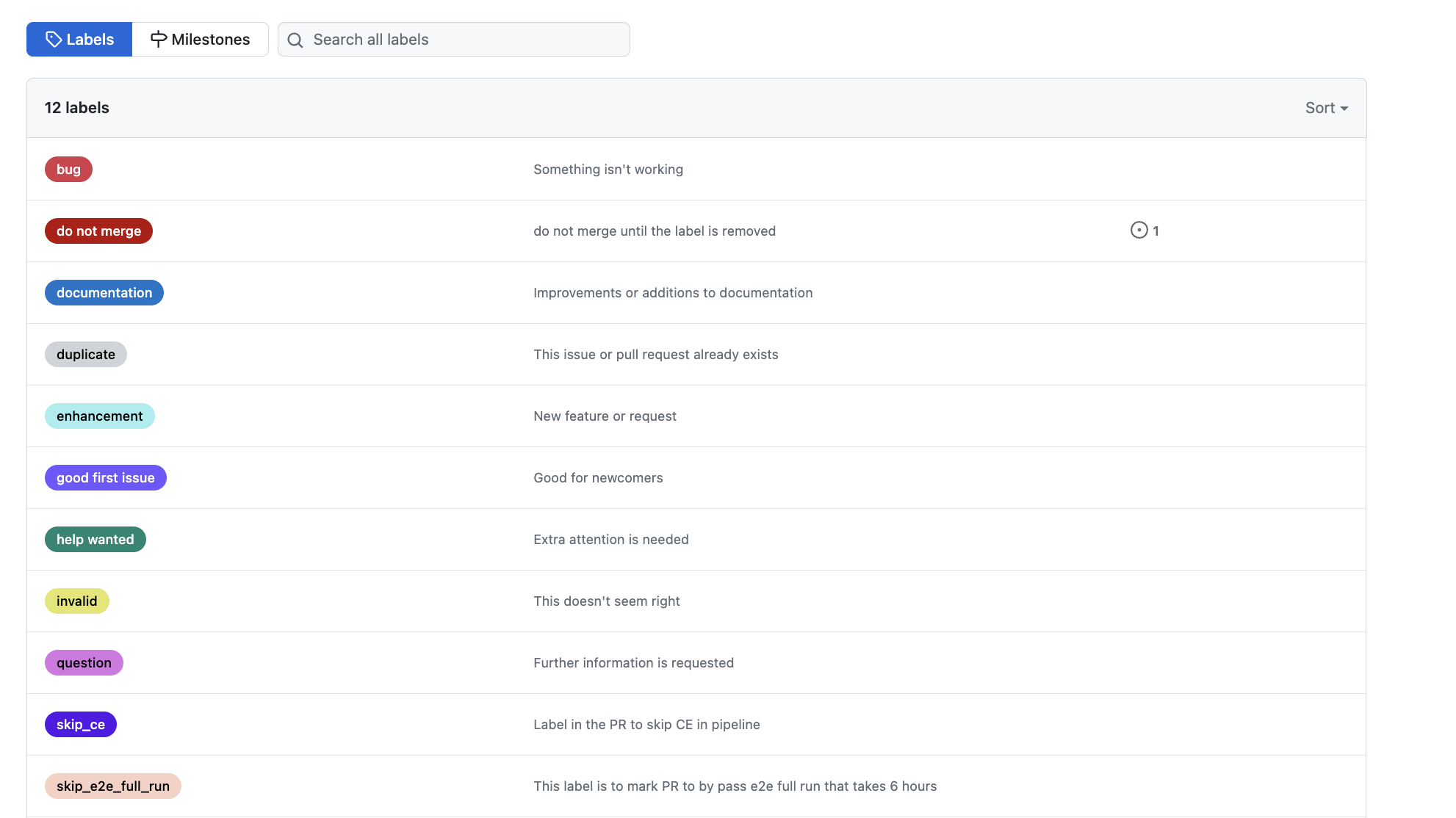
- Pull Request Workflow:
When a developer or team completes a feature or a significant change, they create a pull request (PR) as usual. The below code sample shows the implementation for a workflow to retrieve the PR number associated with a commit or directly if it from a pull request event.
- name: Get PR details for the current commit id: get_pr_data if: github.event_name == 'push' uses: actions/github-script@v7 with: result-encoding: string script: | const { data } = await github.rest.repos.listPullRequestsAssociatedWithCommit({ commit_sha: context.sha, owner: context.repo.owner, repo: context.repo.repo, }); return data[0].number;- name: Check Label for ce run requirement uses: actions/github-script@v7 id: check_if_ce_required if: github.event_name == 'push' with: result-encoding: string github-token: ${{ secrets.GITHUB_TOKEN }} script: | const { data } = await github.rest.pulls.get({ owner: context.repo.owner, repo: context.repo.repo, pull_number: ${{ steps.get_pr_data.outputs.result }} }); const skip_e2e = data.labels.some(label => label.name === '<<label_name>>'); if (skip_e2e) { return 'false'; } else { return 'true'; } - Label Assignment: To skip the end-to-end evaluation, the developer assigns the skip-e2e-evaluation label to the pull request. This label acts as a signal to the CI/CD pipeline or the team responsible for testing that this PR should skip a full end-to-end evaluation.
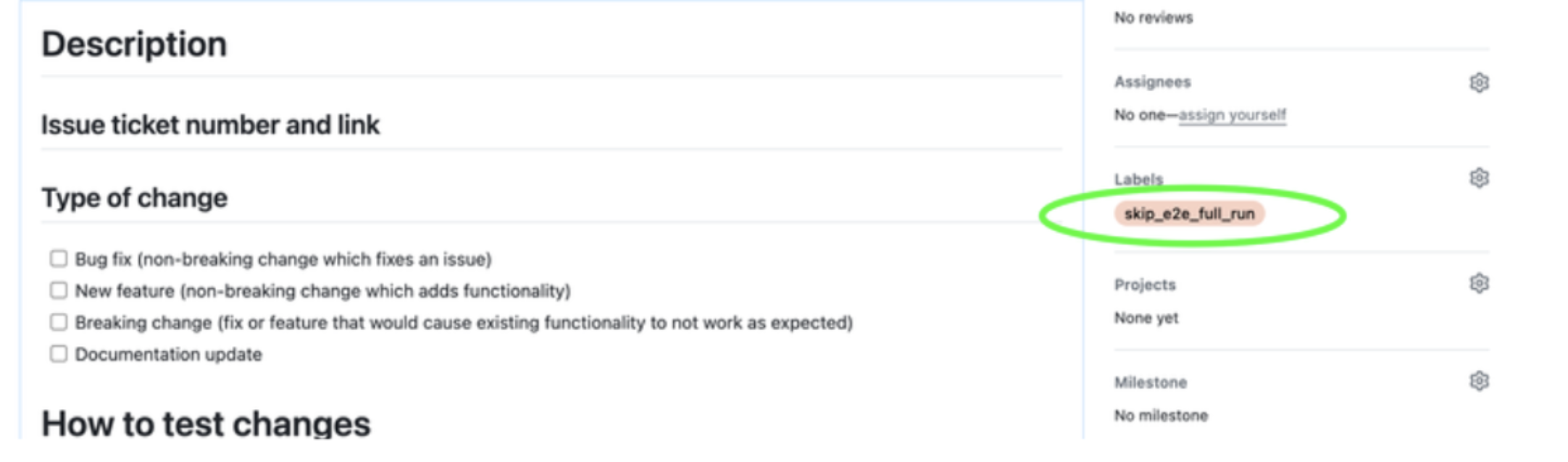
-
Automated Trigger (Optional): Optionally, you can configure your CI/CD pipeline to detect the presence of the skip-e2e-evaluation label automatically. This automation can start the end-to-end testing process without any change explicitly required in the code. For example, if you decide to run the CE just remove the label and if you decide to skip with a new change in the same PR just set it.
-
Testing and Evaluation: Upon detecting the label, the CI/CD pipeline skips the end to end evaluation flow. This typically involves deploying the changes to a test environment that mirrors the production environment and running comprehensive tests to ensure the new code integrates correctly and does not introduce regressions.
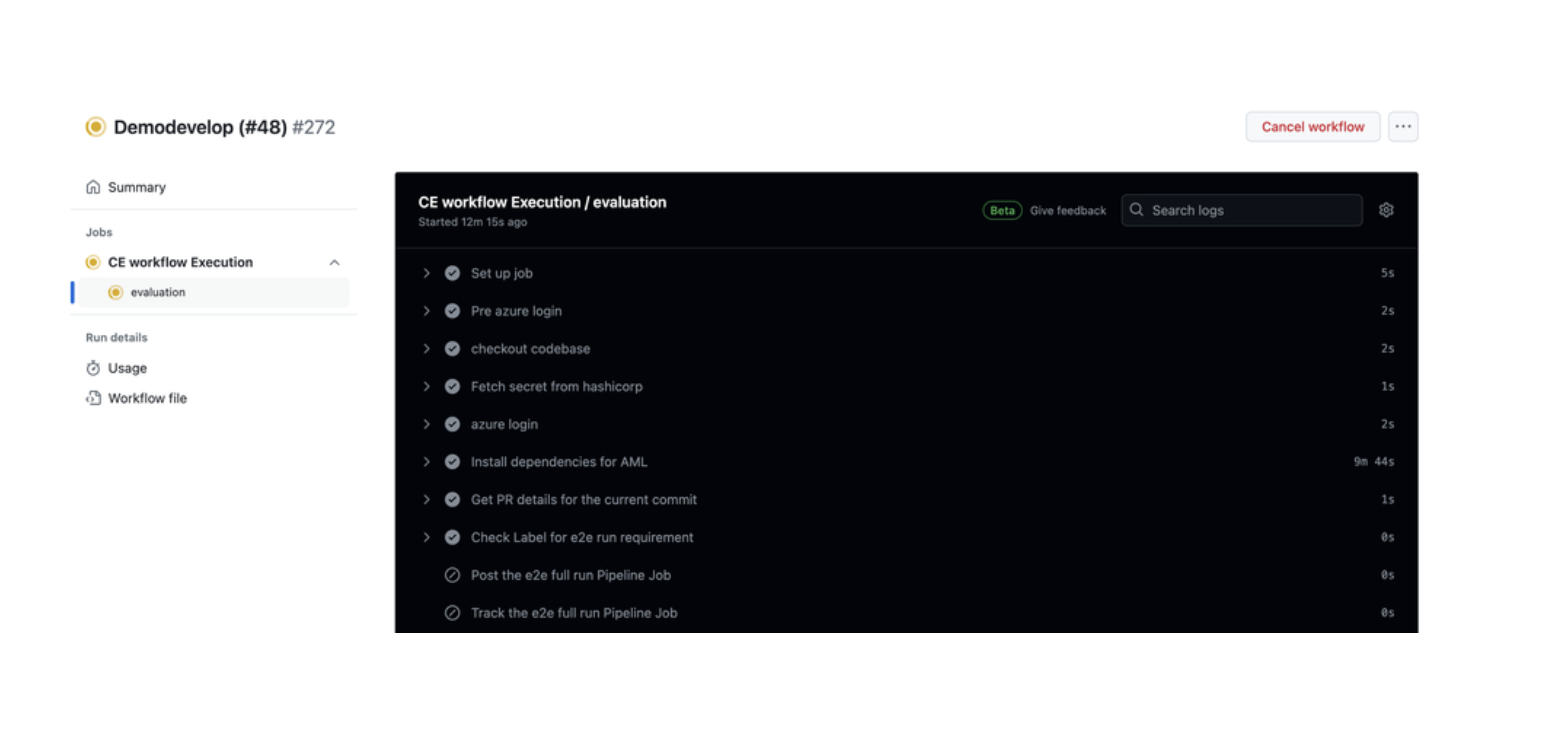
- Decision Making: Based on the results of the end to end evaluation, stakeholders can make an informed decision regarding the readiness of the code for deployment. The decision could include approving the deployment or requesting further fixes and re-evaluation. If the evaluation pipeline is run the reports are listed in the summary of the pipeline run which can be used by the Data Science team to analyse.
Advantages
- Clear Trigger Mechanism: The use of a labeled PR provides a clear, explicit trigger for initiating the end to end evaluation process. This reduces ambiguity and ensures that important steps are not missed.
- Automation Potential: By integrating label detection into your CI/CD pipeline, you can automate part of the process, speeding up the overall evaluation and decision-making cycle.
- Focused Testing: The label helps in directing testing efforts specifically towards PRs that have been marked for end to end evaluation. This prevents unnecessary testing on changes that do not require it, optimizing resource utilization.
- Visibility and Accountability: The 6-hour end-to-end evaluation flow was made configuration-driven, allowing it to be skipped based on a pull request label. The “opt-out” flag requires PR creators to explicitly decide to skip the evaluation. To prevent misuse, a PR template with a checklist ensures the Data Science team or other stakeholders are informed when the evaluation is skipped. Labels provide visibility to all team members about a PR’s status and testing requirements, aiding in tracking and accountability by clearly indicating which PRs have undergone comprehensive testing.
- Scalability: As your project grows, using labels scales well with the increasing number of PRs and complexity of changes. It maintains a structured approach to managing testing requirements.
Limitations
- Communication and Adaptation: Team members need to be informed and trained on the labeling and its importance and requires ongoing adoption to ensure adherence. While labels improve visibility, they also require clear and consistent communication among team members about their usage. Misunderstandings or lack of clarity can lead to ineffective implementation.
- Risk of Misuse or Human error : The ability to opt-out of the evaluation process with a label might be misused or prone to human error, intentionally or unintentionally, leading to skipped evaluations that could compromise the stability and reliability of the project.
- Maintenance overhead: Although labels can help focus testing efforts, the automation and processes involved in managing these labels and triggering evaluations can be a code and resource Maintenance overhead especially when there are multiple labels.
Considerations
- Consistency: Ensure consistency in applying the label across the team to avoid missed evaluations.
- Integration: Verify that your CI/CD tools and processes support label detection and automation if you choose to automate the process.
- Feedback Loop: Establish a feedback loop so that developers receive timely updates on the results of the end to end evaluation, facilitating quick resolution of any issues found.
Considerations for the Frequency of Continuous Evaluation Runs
Continuous Evaluation (CE) runs need to align with project requirements. Evaluate the project’s specific requirements to determine if continuous evaluation is necessary. High-frequency updates or critical changes might demand continuous runs.
Types of Continuous Evaluation Schedules
- Continuous: Suitable for projects with frequent commits and high collaboration levels. Ensures immediate feedback but can be resource-intensive.
- On-Demand: Best for projects with infrequent updates or when manual triggering of jobs is preferred. Provides flexibility but may delay feedback.
- Timer-Based: Ideal for projects that require periodic updates or have predictable workflows. Can be scheduled at specific intervals (e.g., nightly builds) to balance feedback and resource usage.
Factors Influencing Continuous Evaluation Frequency
- Codebase Activity: High-activity repositories benefit from continuous or frequent CE runs to catch issues early.
- Resource Availability: Consider the availability of CI/CD infrastructure and resources. Continuous runs may require more computational resources.
- Testing Requirements: Extensive or time-consuming tests may influence the decision towards less frequent or on-demand runs to optimize resource usage.
- Deployment Cycles: Align CE frequency with deployment schedules to ensure timely integration and delivery.
Conclusion
Implementing LLMOps in a restricted BYO network using Azure Machine Learning presented several challenges, including configuring services within a restrictive network, managing long end to end (E2E) evaluation runs, and optimizing the continuous integration, evaluation, and deployment pipeline.
Our strategy involved using Git Flow for effective development and deployments, implementing CI checks for code quality, CE for thorough model evaluations, and CD for deploying validated changes. We introduced an opt-out mechanism for lengthy E2E evaluations to improve resource efficiency and reduce bottlenecks.
By adopting a systematic approach with structured branching and strategic CE runs, we managed complex dependencies and collaborations among data scientists, engineers, and platform teams. This ensured controlled and reliable deployments while maintaining high standards of code quality and model performance.
Overall, our experience highlights the importance of flexibility, automation, and strategic decision-making in successfully operating LLMOps in restricted network environments.