



Introduction
Imagine you’re building a powerful new AI assistant to support real business tasks — like answering maintenance questions in a manufacturing plant or surfacing insights from historical service data. To ensure that this AI system produces accurate and useful responses, we need a reliable way to measure its performance. That starts with defining what a “correct” answer actually looks like.
This is where the concept of ground truth comes in.
Ground truth refers to a set of accurate, verified answers that serve as the benchmark against which an AI system’s outputs are evaluated. It’s the gold standard — the data you use to test whether the system is behaving as expected. In practice, ground truths are carefully curated question-and-answer pairs that reflect what users should receive when they ask a particular question based on the system’s underlying data sources.
For example, if a user asks, “What are the most recent updates related to this item?”, the ground truth would be a verified, accurate list of those updates pulled directly from the system of record. This response represents the correct answer the AI system is expected to return and serves as the benchmark against which its performance can be tested and evaluated.
During a recent customer engagement, our team developed a structured approach to curate high-quality ground truths. This process was essential not just for evaluating the AI assistant’s performance, but also for building confidence among end users and stakeholders.
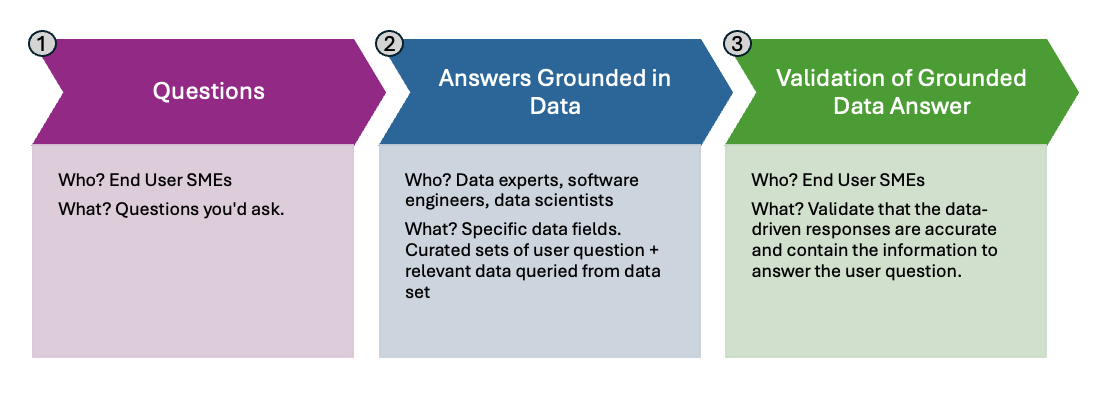
In this post, we’ll walk through the key steps in our approach:
- Collection of real user questions – to ensure relevance.
- Contextualized data curation – to ground questions in verifiable, representative examples.
- Subject matter expert (SME) validation – to ensure the answers reflect domain expertise and business reality.
Let’s dive into the details of how we created ground truths that truly reflect user intent and organizational knowledge.
1. Collecting User Questions
Once we’ve established access to the underlying data sources our AI system will rely on, the first step in building reliable ground truths is to gather a meaningful set of real user questions. While it’s possible to generate hypothetical prompts using the available data, these often miss the nuances, priorities, and terminology that actual users bring to the table. To develop ground truths that reflect real-world needs, we must engage directly with our target end users.
To do this, we conducted a focused, interactive workshop with subject matter experts (SMEs) — the people who understand the business domain and will ultimately use or benefit from the AI system. These sessions are not only about collecting questions, but also about building shared understanding and trust.
We began the workshop by clearly explaining the purpose of the project: to develop an AI assistant that can answer user questions accurately and consistently by drawing on existing organizational data. We emphasized how their expertise and participation were crucial to shaping an assistant that would be genuinely helpful and aligned with their day-to-day challenges.
To help SMEs generate high-quality questions, we gave them a set of thought-starters in advance. These prompts were designed to spark ideas and encourage them to think in terms of real scenarios:
- What types of questions do you frequently ask in your daily work?
- What information is hard to find or requires digging through multiple systems?
- What would you ideally ask an AI assistant if it could understand your intent and return exactly what you need?
- Are there any follow-up questions you typically ask after receiving an initial answer?
During the session, we used a collaborative Mural board — a virtual whiteboard with pre-labeled sections for different categories of questions. (If you have a Mural account, you can view our template here.) Participants added their questions using digital sticky notes, and the format encouraged conversation, cross-pollination of ideas, and deeper exploration of user needs. Importantly, all questions were considered valid and valuable, no matter how specific, broad, or exploratory.
The workshop yielded dozens of user-submitted questions, many of which built on each other as SMEs discussed and refined their inputs in real time. In the second half of the session, we worked together to organize and tag the questions. We applied a color-coding system to indicate which data sources or systems would be required to answer each one. This step later enabled us to map questions to the appropriate context and data during the ground truth curation phase.
This collaborative question collection process not only gave us a strong foundation of realistic prompts, but also fostered user buy-in and deepened our understanding of the customer and their business — ensuring that the questions our AI assistant was being tested against were directly relevant to the people it was designed to serve.
2. Contextualizing Data Curation
Once we had a rich set of real user questions, the next step was to connect those questions to the actual data that could be used to answer them. This is what we call contextualized data curation — the process of identifying and extracting the relevant records or facts that represent a “correct” response to each user question based on the available data.
This step is critical because it transforms abstract questions into concrete, testable pairs of input and expected output, which is the essence of a ground truth. It ensures that each ground truth is rooted not only in what users want to know, but also in what the underlying data can support.
To streamline the effort, we grouped similar or related user questions into small sets. This allowed our team to work in parallel, with different individuals or subgroups focused on curating data for different clusters of questions. We also partnered with data scientists from the customer’s organization, which helped accelerate progress and ensured alignment with internal data knowledge.
We developed custom tooling to support this phase. These tools enabled curators to define the data queries needed to answer each question and associate those queries with the relevant context using a well-defined, repeatable method.
For each user question, we followed a structured three-step process:
- Identify relevant data sources
Determine which databases, data lakes, or structured files contain the information needed to answer the question.
- Define filters and properties
For each relevant source, identify the fields and values that should be used to retrieve precise results. This might include timestamps, asset IDs, status fields, or other filters specific to the domain.
- Write and test the database query
Construct a query that reliably returns the data needed for that specific question. These queries had to be complete and executable, returning interpretable results that could serve as the “correct” answer.
To give our queries real-world grounding and test their robustness, we introduced execution contexts — specific scenarios or entities that the query should operate on. For example, a query might be applied to a particular customer account, project, or product instance, depending on the domain.
We intentionally selected a mix of contexts to reflect different types of outcomes:
- Typical case: A standard scenario where the query returns a reasonable, expected set of results.
- Negative case: A valid scenario where no data should be returned, which is useful for testing how the system handles empty or null responses.
- Edge or extreme case: A scenario that produces an unusually large or complex result — such as a case with high data volume or inconsistent formatting — which helps stress-test the system.
By including this range of contexts, we ensured that the curated ground truths represented a realistic cross-section of how users might interact with the system — from everyday questions to more difficult or uncommon scenarios.
This curated set of data-backed answers, anchored in well-defined contexts, became the foundation for the next step: automating the generation of structured ground truth files that could be validated and refined through SME review.
2.1 – Operations: Contextualized Data Curation Utility
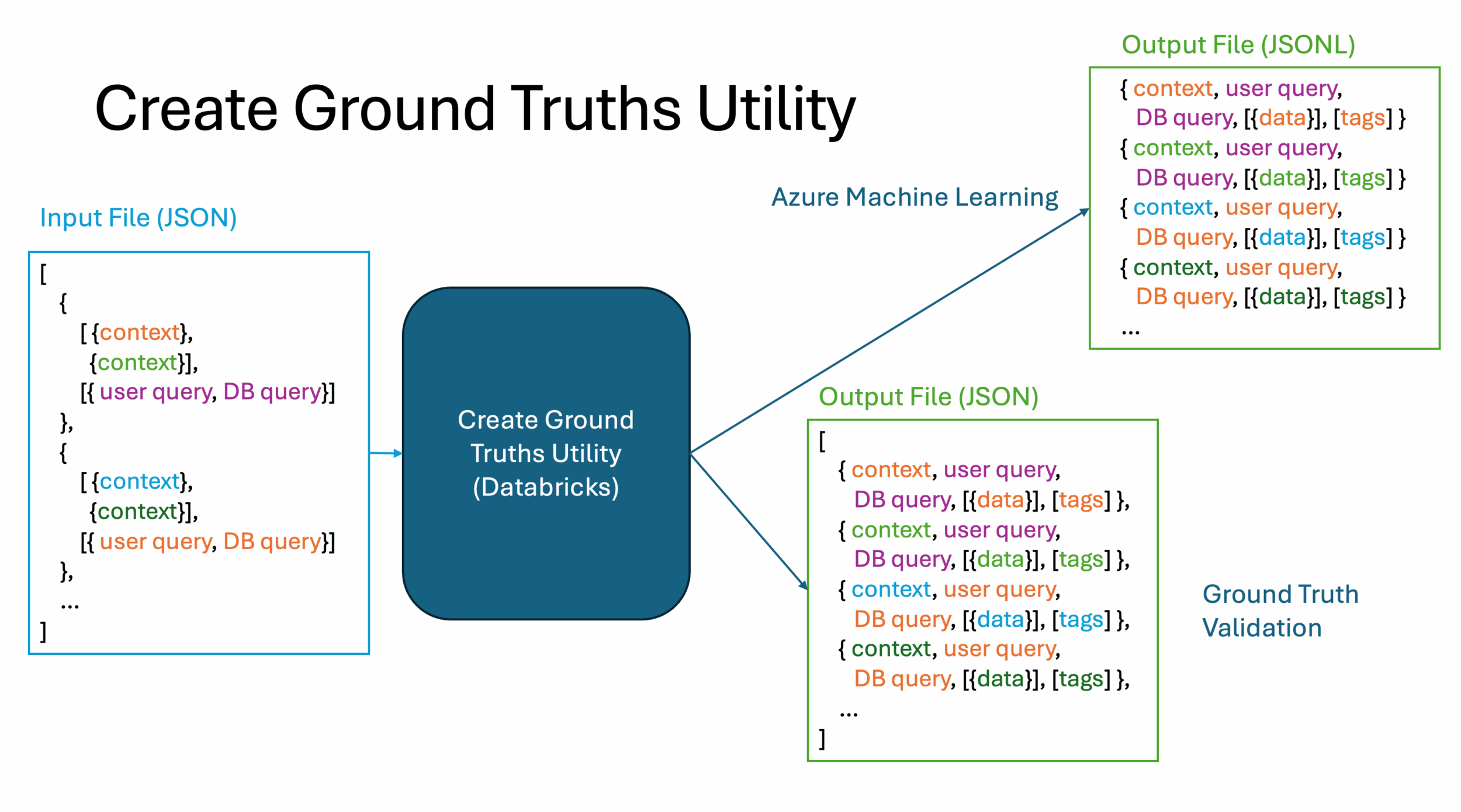
To operationalize the data curation process, we developed a utility that automates the generation of ground truth records at scale. For each set of user questions, we created a structured JSON input file. This file contains:
- The original user query
- The corresponding database query logic
- A list of execution contexts (e.g. specific identifiers or filter values)
This input is fed into our Create Ground Truths Utility, which systematically runs each database query across all defined contexts for every user question. The utility then captures the resulting data records and packages them into a structured output file.
Each output JSON file maps:
- The user question
- The execution context
- The resulting data records
These elements together form a ground truth entry — a verified, context-specific answer to a user question.
To further enrich the dataset, the utility also applies automated tagging to each ground truth. For example:
- “Negative Case” for queries that return no records
- “Multiple Data Sets” for queries pulling from more than one source or table
In addition to the primary JSON output, the utility generates JSONL (JSON Lines) versions of the data. This format is especially useful for machine learning workflows, as it’s compatible with platforms like Azure Machine Learning (AML), where it can be used for testing, experimentation, and model evaluation.
This tooling helped ensure consistency and reproducibility while dramatically accelerating the process of building a robust, diverse set of ground truths.
3. Subject Matter Expert Validation
Once we’ve curated contextualized data for each user question, the next critical step is validation — ensuring that the curated answers truly reflect what a domain expert would consider correct. After all, even a well-structured query can produce misleading or incomplete results if the intent of the question was misunderstood or if the wrong data properties were used.
To ensure the quality and credibility of our ground truths, we built a review loop centered on subject matter expert (SME) feedback. These experts are best positioned to assess whether the question was interpreted accurately and whether the returned data constitutes a valid and useful answer.
To streamline this feedback process, we created a utility that programmatically extracts the latest curated ground truths and converts them into a human-readable review format. Specifically, it generates an XLSX (Excel) document containing worksheets for the latest batch of ground truth sets that need review.
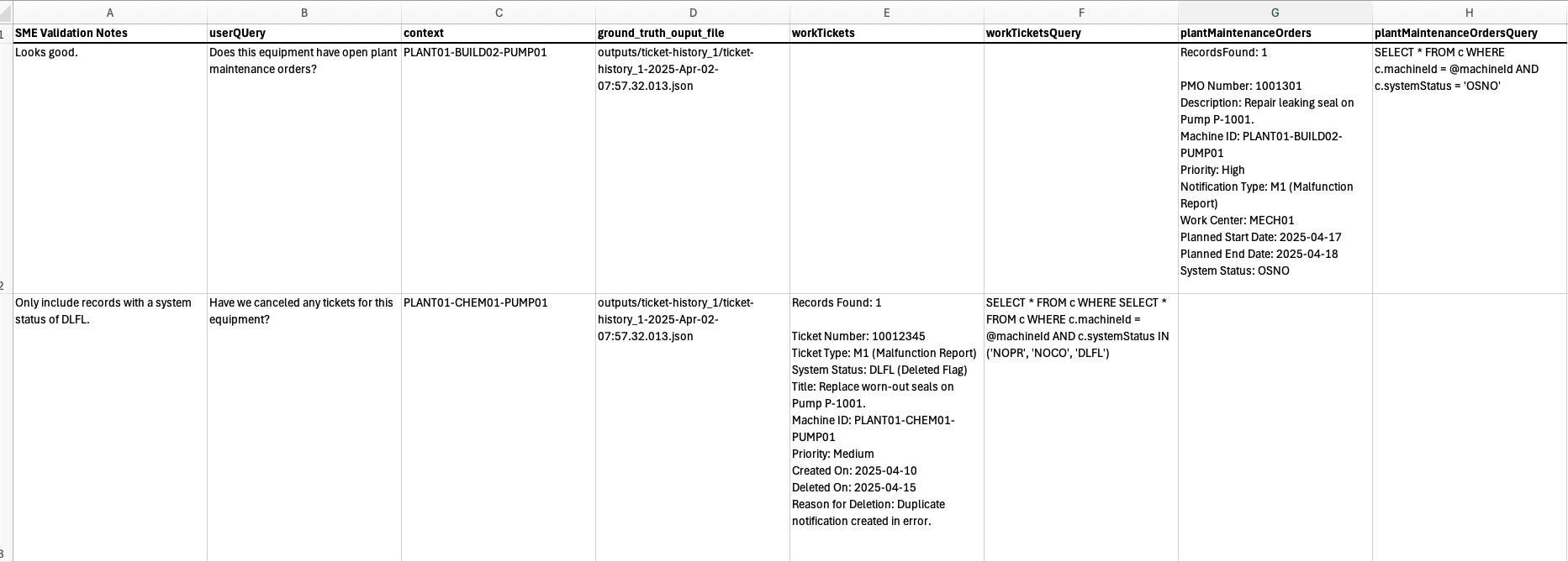
Each spreadsheet file includes:
- One worksheet per set of user questions
- One row per ground truth entry that represents a unique combination of question and context
- Columns for:
- The original user question
- The execution context (e.g. specific item, timeframe, or filter value)
- The resulting data records (as pulled from the database)
- The database query used
- A placeholder for SME feedback
- Metadata such as tags and links to the original JSON files
Here is a generic example of an Excel spreadsheet showing contextualized ground truths for a fictionalized manufacturing plant that uses SAP terms and values:
SMEs can review each entry, provide feedback on interpretation, flag any issues, and suggest adjustments. This feedback loop is intentionally iterative. Once feedback is collected, the ground truth input files can be updated, and the utility can regenerate revised versions of each spreadsheet for further review.
Because the entire process — from query execution to spreadsheet generation — is automated, we can rapidly repeat the cycle of curation, validation, and refinement as needed.
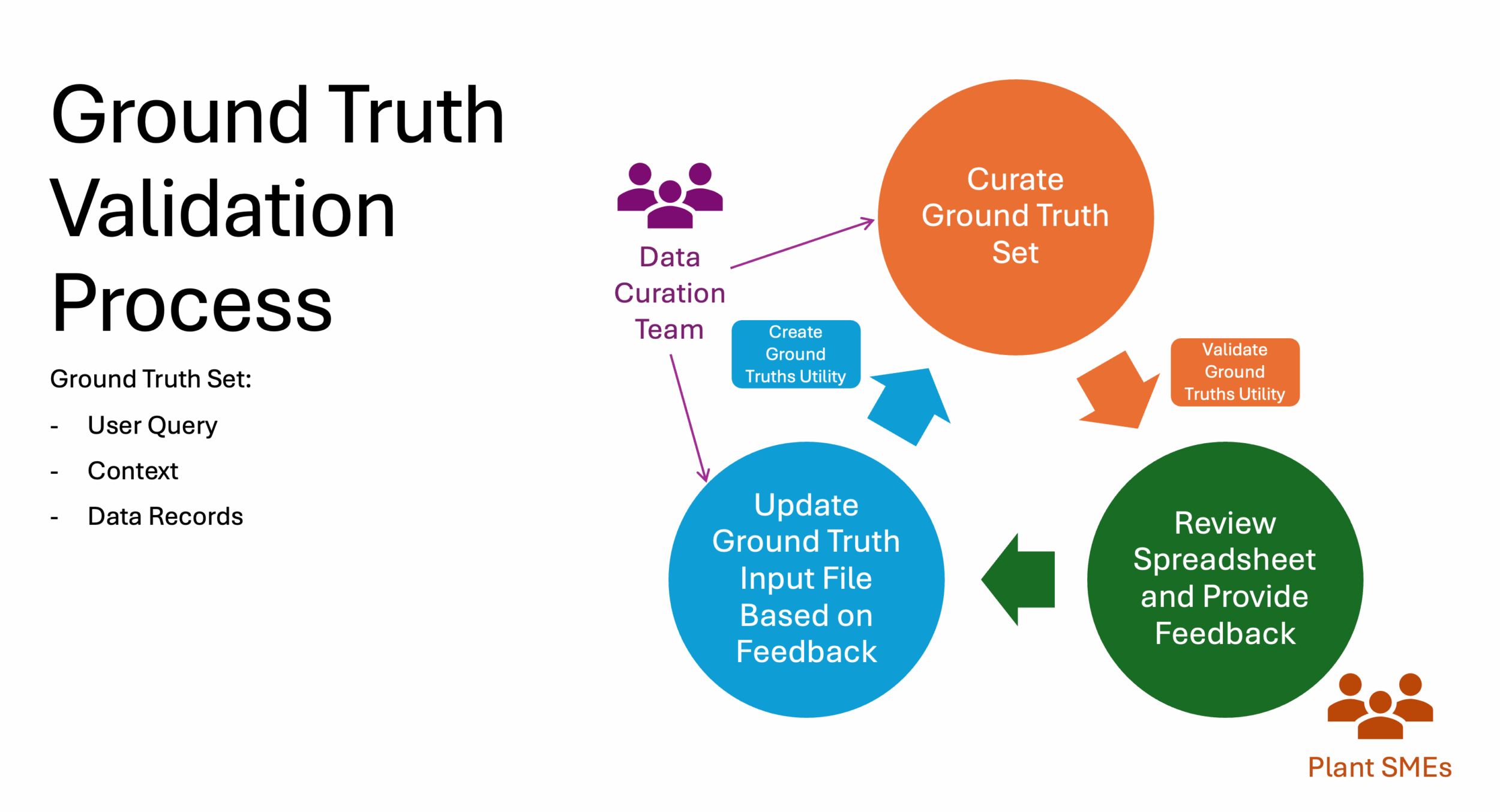
This collaborative loop with SMEs ensures that the final ground truth dataset is not only technically sound, but also aligned with domain expertise and user expectations — a foundational step in delivering trusted AI systems.
Conclusion
High-quality ground truth data is the foundation of any reliable and trustworthy AI system. It ensures that models are not only trained on accurate examples but also evaluated against realistic, domain-relevant expectations.
By following a structured and collaborative process that collects authentic user questions, grounds those questions in real data, and validates the results with subject matter experts, teams can build ground truth datasets that reflect the complexity and nuance of real-world use cases.
This iterative approach doesn’t just improve model performance. It strengthens alignment between technical teams and end users, ensures transparency in how AI systems are evaluated, and ultimately fosters trust in the solutions being delivered.
Investing in the ground truth process is more than a technical necessity — it’s a strategic step toward building AI systems that are truly useful, dependable, and aligned with business goals.
Acknowledgments
We are grateful for the data science insights provided by Amatullah Badshah, Farhan Baluch, and Bryan Ostdiek and the data expertise shared by Jose Perales. We also appreciate Bindu Chinnasamy, John Hauppa, Cameron Taylor, and Kanishk Tantia for their valuable contributions to this project.
The feature image was generated using Bing Image Creator. Terms can be found here.