

Introduction
Here at ISE we’ve had the privilege to work with some of Microsoft’s largest customers developing production Large Language Model (LLM) solutions. In any software project, the distance between Proof of Concept (POC) and production is significant, but with LLM solutions we’ve found that it’s often even more massive than traditional software (and even Machine Learning) projects, and yet even more underestimated by both crews and customers.
One common anti-pattern that we’re seeing is what we like to call the adoption of “unearned complexity”. Customers, often before we’ve even arrived, have decided on technology like LangChain or multi-agentic solutions without experimenting enough to understand if they actually need that complexity for their solution. In this post we’ll go through some of the reasons why you might want to reconsider reaching for a complex answer before you truly understand your own question. We do make some LangChain-specific points in here, but this post isn’t (entirely) just to criticize that library. Rather, we want solution developers to consider the points we raise regardless of what technology they are evaluating, and avoid adding complexity to their solutions unless it’s actually earned a place.
Agents of Chaos
Agents have proven to be a popular starting point for Retrieval Augmented Generation (RAG) and chatbot projects because they seemingly provide a dynamic template for an LLM to ‘observe/think/act’. The agent pattern seems to promote a simple and powerful pattern to handle a range of scenarios like choosing to use external tools and knowledge bases, transforming inputs to better use external tools, combining information, checking for errors and looping through its decisions if the quality is not deemed good for some goal.
When it works it’s amazing, but under the pressure of real-world data distributions we have observed that agent patterns can be incredibly brittle, hard to debug, and provide a lack of maintenance and enhancement options due to its general nature mixing several capabilities. Due to the stochastic nature of the models and the dynamic nature of agentic solutions, we have observed wide swings in accuracy and latency, as one call may result in many calls to the underlying model or models, or different orderings of tool invocation. If you have a fixed explicit set of components for a solution (e.g. routing, query rewriting, generation, guardrails) that are invoked in a predictable order, it makes it much easier to debug performance issues. This can definitely result in a perceived loss of flexibility, but in our experience most customers would prefer reliable and performant solutions to ones that can “flexibly fail”.
In fact, even with the advent of agentic frameworks from Microsoft Research and others, recent customer projects with ISE have explicitly avoided agentic designs as customers considered them too risky or low/sporadic-performance for production solutions. Going with a more explicit chained component design as mentioned above allows us to profile, debug, and optimize each component more easily. For instance, query rewriting can be judged as suboptimal and fine-tuned, without potentially causing impacts to an agent’s decision on which tools to use downstream.
Does this mean that you should never use agents? No, but you should carefully consider whether your scenario justifies the additional complexity, scalability, and reliability impacts that agentic solutions can bring. Often trying the simplest thing that can possibly work is a much better answer than jumping into an agentic solution, and a simple prompt-based, fixed-path solution makes a good baseline for you to benchmark more complex solutions against going forward.
Chaining Yourself to LangChain
Some of us (hi, we mean me, Mike) were strong advocates of LangChain early on (16 years ago in LLM-years, or early 2023), especially over Semantic Kernel which at the time was quite young. Times have changed however, and we can no longer give it an unqualified endorsement for use on any given project. Does that mean we’re anti-LangChain? No, but we believe it needs to be a carefully considered part of your solution and it really has to provide value for you to justify its weight. Weight in terms of cognitive load, in terms of software bill of materials (SBOM) and security concerns, and in terms of latency and maintenance. Harrison Chase himself admits that LangChain is not the right choice for every solution, and although LangChain 0.2 has improved significantly in several aspects, the weight is still there and still needs to pay for itself.
One of the selling points of LangChain is that it incorporates functionality like agents (such as ReAct, or OpenAI tool-calling agents) and integrations to other tooling like vector stores. However, the abstractions used by LangChain to encapsulate such functionality can make it difficult to flexibly configure or adapt the use of these features. The heavily abstracted structure of LangChain can make it hard to try new complex ideas, often leading to messy workarounds. For example, in adjusting the default prompts used by agents, the way tool signatures or descriptions are provided to LLMs, integrating custom data validation rules, or modifying the way vector or key-value stores are queried. Some of these are mitigated with v0.2, while others are still issues. Which brings us to our next point.
LangChain is a pre-v1 library – before the current AI wave, none of our customers would consider going to production with a pre-v1 library, and for good reason. We have observed on many of our projects large, breaking changes roll through LangChain that required significant rework. Coupled with the pace of change of the other libraries most customers are taking dependencies on (OpenAI, search / vector stores), technical debt and maintenance can significantly hamper progress. Also, as a pre-v1 library, we have seen both internal and external reports on security issues in LangChain, and most of our first-party teams eschew its use for that reason.
Finally, we’d like to go into more detail on a couple of key aspects of LangChain to both demonstrate some of our concerns and to let the reader understand what we consider when we’re adopting a software package into a solution that is bound for production. First, in the world of LangChain, what does securing your software bill of materials (SBOM) look like. Second, in a pre-v1 library like LangChain, what do you have to consider when looking at the version, and how does it differ from semantic versioning best practices.
SBOMinable
In any supply chain, securing your materials is paramount to ensure the quality and safety of the final product. Similarly, in software development, securing your SBOM is crucial. An SBOM is a comprehensive list that outlines all the components, libraries, and dependencies that make up a piece of software. It acts as a roadmap, providing visibility into the third-party and open-source components your software relies on.
By understanding and managing your SBOM, you can identify potential vulnerabilities, ensure compliance with licensing requirements, and maintain the integrity of your software. Given the complexity of modern software, where applications often rely on numerous external libraries, building and maintaining an accurate SBOM is essential for mitigating risks.
For this blog, we’ll focus on creating an SBOM that lists all the dependencies of a piece of software. This approach will help you understand not only what your software is made of but also how to protect it against supply chain attacks, ensuring a more secure and resilient product.
Keeping the number of dependencies to a minimum is crucial for maintaining security within your software. Each dependency, while adding functionality, also introduces risks, including vulnerabilities and increased complexity in maintenance. Code owners must be fully aware of not only the direct dependencies but also the child dependencies that their software relies on. Understanding who owns these dependencies and their track record for addressing security issues is essential. Imagine if a security vulnerability is identified—how quickly and effectively can the owner of the dependency provide a patch? The ease with which dependencies can be patched directly impacts the security and stability of your software. Therefore, a leaner SBOM, with well-understood and responsibly maintained dependencies, is not only easier to secure but also more resilient against external threats.
Are we saying develop everything from scratch? Definitely not. Many library writers are much more capable of crafting secure solutions than regular software developers because they have a depth of security experience, and leaning on their expertise is the right thing to do. LangChain itself has good support for tracing and observability which might make it worth adopting, but you should understand the dependencies you’re taking.
Examples of Supply Chain Attacks
-
SolarWinds Attack (2020): The SolarWinds attack is one of the most notorious supply chain attacks in recent history. Attackers compromised the Orion software, a popular IT management tool used by thousands of organizations worldwide, by injecting malicious code into a software update. This allowed the attackers to infiltrate the networks of SolarWinds’ customers, including major government agencies and corporations. The attack went undetected for months, demonstrating the significant risk posed by compromised software dependencies.
-
Apache Struts Vulnerability (2017): The Apache Struts vulnerability (CVE-2017-5638) is another infamous example. This open-source web application framework had a critical security flaw that was exploited in the Equifax data breach. Attackers used this vulnerability to gain access to sensitive data, affecting over 140 million individuals. The incident highlighted the importance of staying on top of updates and understanding the risks associated with open-source dependencies.
-
Event-Stream NPM Package Attack (2018): In 2018, the event-stream package on npm, a widely used JavaScript package repository, was compromised after a malicious actor took over its maintenance. The attacker introduced malicious code designed to steal cryptocurrency from applications that used the package. This incident underscores the risks associated with third-party dependencies, particularly in open-source ecosystems where packages may be maintained by volunteers or transferred to new owners.
What is Out There for LangChain?
Now that we understand the risks, let’s list the packages that LangChain offers. We’ll then assume a scenario, install the required packages, and list all the dependencies and sub-dependencies needed for each package.
| Package Name | Version | Purpose | Versioning |
|---|---|---|---|
| langchain-core | 0.2.x | Provides the base abstractions and runtime for the LangChain ecosystem. | Minor: Breaking changes for public beta interfaces.Patch: Bug fixes, new features, private/beta changes. |
| langchain | 0.2.x | Broader set of tools and features for general LangChain usage. | Minor: Breaking changes for public interfaces not marked as beta.Patch: Bug fixes, new features, private/beta changes. |
| langchain-community | 0.2.x | Community-contributed tools and integrations. | Follows the same versioning guidelines as langchain. |
| langchain-experimental | 0.0.x | Experimental features in early development. | All changes result in a patch version increase. |
| Partner Packages e.g. langchain-openai | Varies | Independently versioned packages that integrate with LangChain. | Versioned independently. |
Sample Scenario
Let’s imagine a typical “talk with your data” scenario where we are building a Generative AI (GenAI) chatbot using a Retrieval Augmented Generation (RAG) architecture. In this scenario, the chatbot will utilize OpenAI models like ChatGPT-4 for generating responses and the Ada model for creating embeddings. To efficiently retrieve relevant information, Azure Cognitive Search will act as our vector database (VectorDB). The chatbot will be powered by a LangChain agent, with various LangChain tools integrated to enhance its capabilities. This setup will allow the chatbot to engage in natural conversations while effectively retrieving and presenting information from a large dataset.
Based on the scenario, we would need to install the following packages to set up our chatbot:
• langchain: This package provides the broader set of tools and features necessary for general LangChain usage, including agent management and tools integration.
• langchain-core: This package includes the essential abstractions and runtime required to support the LangChain ecosystem, which will be crucial for integrating the various components of our chatbot.
• langchain-openai: Since we are leveraging OpenAI models like ChatGPT-4 and Ada for generating responses and embeddings, this package will provide the necessary connectors and tools.
• langchain-community: Given that we are using Azure Cognitive Search as our vector database, this package will include community-contributed tools and integrations that are essential for working with AzureSearch.
We will install these packages and then list all their dependencies and sub-dependencies to understand the full scope of what will be required to bring this scenario to life.
# Install required packages
pip install langchain langchain-core langchain-openai langchain-community
# Install pipdeptree for listing dependencies
pip install pipdeptree
# List dependencies for each package
pipdeptree -p langchain | wc -l
pipdeptree -p langchain-core | wc -l
pipdeptree -p langchain-openai | wc -l
pipdeptree -p langchain-community | wc -lResults
| Package Name | Version | Total Dependencies | Reason for Installation |
|---|---|---|---|
| langchain | 0.2.12 | 90 | For using Agents and Tools feature |
| langchain-core | 0.2.28 | 24 | For langchain/openai package |
| langchain-openai | 0.1.20 | 59 | For OpenAI models and completion |
| langchain-community | 0.2.11 | 155 | Since we are using AzureSearch vector database |
Always a good practice to inspect for vulnerabilities. For this example lets use pip-audit and the following requirements file:
langchain==0.2.12
langchain-core==0.2.28
langchain-openai==0.1.20
langchain-community==0.2.11# Install pip-audit
pip install pip-audit
# Check for vulnerabilities
pip-audit -r requirements.txt
# Output will list any vulnerabilities found
# > No known vulnerabilities foundLet’s create a visualization of the installed packages and their dependencies using pipdeptree:
# Generate a dependency tree for the installed packages
pipdeptree -p langchain,langchain-core,langchain-community,langchain-openai --graph-output png > langchain_dependencies.png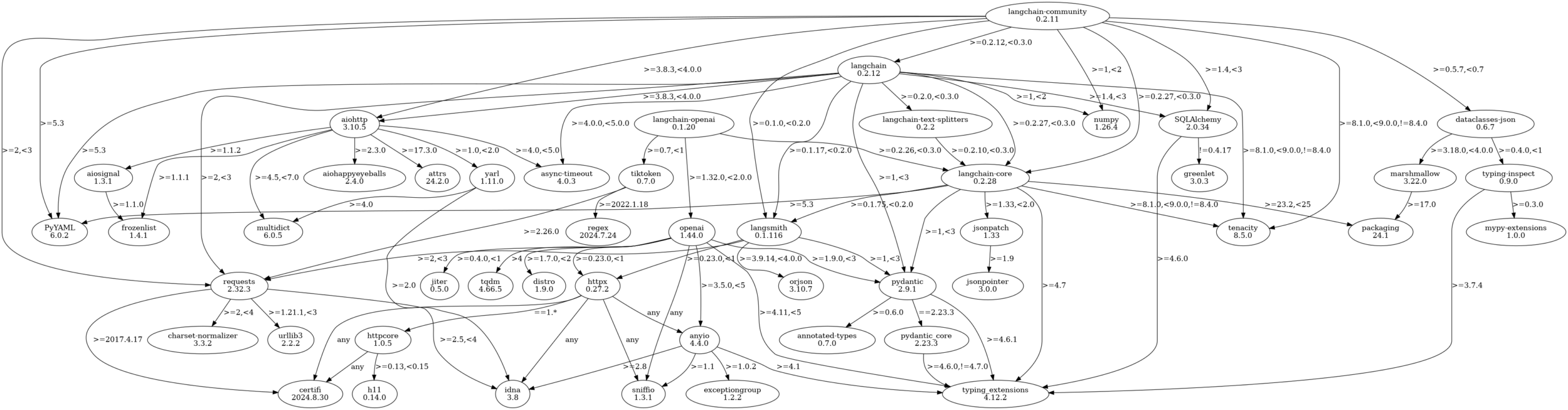
SBOM Summary
When integrating software packages into your projects, it’s crucial to be aware of the number of dependencies and sub-dependencies each package brings along. Every dependency adds complexity and potential risks, such as vulnerabilities, compatibility issues, and maintenance overhead. A package with numerous dependencies can significantly increase the attack surface of your software, making it harder to secure and manage. Therefore, understanding and carefully evaluating the dependency tree of each package is essential to ensure that you’re not unknowingly introducing weaknesses into your system.
Semantic Versioning in LangChain
LangChain’s release policy, while adhering to certain aspects of semantic versioning, presents several challenges that could lead to confusion and potential issues for users. Here’s a breakdown of where the current approach deviates from best practices and why these deviations might undermine the security and stability of your Software Bill of Materials (SBOM).
- Major Version
0for Production Packages
LangChain uses major version 0 for all packages, including those used in production environments. According to semantic versioning principles, a 0.Y.Z version is typically reserved for initial development where anything can change at any time. Continuing to use major version 0 for production-level packages sends a mixed message about the stability of the software.
Best Practice: Once a package is being used in production or is expected to maintain a certain level of stability, it should move to version 1.0.0 or higher. This change signals to users that the package is stable and that breaking changes will only occur with a major version increment.
- Inconsistent Use of Minor Versions
The policy states that minor version increases will occur for breaking changes in public interfaces not marked as beta, while patch versions will include new features. This approach conflicts with semantic versioning best practices, where minor versions should indicate the addition of backward-compatible functionality, and patches should be reserved exclusively for bug fixes.
Best Practice: New features should always trigger a minor version bump. This allows users to upgrade with a clear understanding that new functionality has been added, without fearing breaking changes in a patch update.
- Patch Versions with New Features Introducing new features in patch versions can lead to unintended consequences. Users generally expect patch releases to be safe for application in critical systems because they are assumed to only include bug fixes. New features introduced in patch versions may inadvertently introduce new bugs or alter behavior in unexpected ways.
Best Practice: Reserve patch versions strictly for backward-compatible bug fixes. Any new feature, regardless of size or impact, should be part of a minor version update.
- Release Candidates and Stability
LangChain’s policy of using release candidates (rc versions) is a good practice for pre-release testing. However, the current approach could benefit from clearer guidelines. If no issues are found in an rc, it’s promoted to a stable release with the same version number. This practice can create a situation where a package is released as stable without any additional testing between the rc and the final release.
Best Practice: After thorough testing, release candidates should be promoted with an additional minor version bump if any features were added during the rc phase. This ensures the stable release is well-verified and reflects any additional changes made during testing.
- Deprecation and Removal Timing
The deprecation policy states that deprecated features will continue to work for the current and next minor version but may be removed within 2-6 months. This timeline may not provide enough time for users to migrate, especially in environments where upgrades are managed on a longer schedule.
Best Practice: A more conservative deprecation policy would extend support for deprecated features across at least two minor versions or a minimum of six months, whichever is longer. This approach gives users ample time to adjust and plan their migration strategies without rushing.
- Clarity on API Stability
The distinction between public and internal APIs in LangChain is crucial, but the current policy might benefit from clearer guidelines. While the policy follows Python’s convention of prefixing internal methods with an underscore (_), users could still become confused, especially if these internal methods are widely used in the community.
Best Practice: Formalize the distinction between public, private, and beta APIs within the documentation and enforce stricter guidelines on when and how internal APIs can change. For public APIs, any breaking change should warrant a major version bump, even if the major version is currently 0.
Following the policy. To ensure that your Python requirements.txt file is configured to receive only bug fixes without introducing breaking changes, you should specify the version ranges carefully using semantic versioning principles. Here’s an example:
langchain-core>=0.2.0,<0.3.0
langchain>=0.2.0,<0.3.0
langchain-openai>=0.2.0,<0.3.0Another example that includes release candidates and beta versions:
langchain-core>=0.2.0rc0,<0.3.0
langchain>=0.2.0b0,<0.3.0
langchain-openai>=0.2.0rc0,<0.3.0Conclusion
Building modern AI applications meant for production is an incredibly complex endeavor. Most people have bought into the hype and believe that AI “just works”, but as with most stochastic solutions it only “just works” some of the time. Adding extra layers of complexity to an already complex solution is not something that should be entered into lightly. We advocate a careful, considered approach when adopting any new design pattern or library into your solution, whether that be agentic frameworks, ReAct-style patterns, LangChain, or others. Is the gain you’re receiving paying for the weight of the new element? Is the complexity earned?
As in traditional ML solutions, starting with a simpler “benchmark” solution that may involve fixed flows and direct API calls can provide “good enough” results for your scenario at a significantly cheaper maintenance and cognitive load. Plus, if it does not, you now have a benchmark to measure against as you add complexity to your solution, and are in a much better position to be able to answer the question “is this complexity paying for itself?”
We (ISE) are working on broader guidance, but until then we’d recommend that those looking for more information on developing and deploying secure software look to the OpenSSF guidance:
- Concise Guide to Developing More Secure Software
- Concise Guide to Evaluating Open Source Software
- and the OpenSSF Scorecard
- as well as our Well-Architected Framework
We had more authors than we’re allowed to credit, so we would like to call out Bhavik Maneck and Abdul Karim for their work on overall LangChain and Agentic complexity issues and David Ratcliffe for his additions, Juan Burckhardt for his detailed analysis of the LangChain SBOM and Semantic Versioning complexities, and Michael Lanzetta for putting it all together into something the reviewers have judged to be cohesive. The cover image was generated using DALL-E, while the dependency graphs were generated using pipdeptree which uses GraphViz for building the visualizations.