
Background
From giant online shoe shops to e-commerce furniture mega-companies, inventory management for online retailers drives one of their largest expenses. When workers can’t find catalogue items that match a physical apparel item in the warehouse, errors are introduced and time is wasted. Updating the catalog delivers even more challenges in managing large collections of photographs of apparel, avoiding duplicates and managing similar items. These activities require time-consuming look-ups and often require the workers to have deep knowledge of the inventory.
Nowhere is this more the case than with big online fashion retailers tasked with cataloging every newly arrived piece of apparel. For each new item that arrives, retailer staff must determine if the merchandise matches an item already in stock. And while they certainly lack the time to manually sift through the catalog for matches, they’re often also without an automated solution for search and retrieval. These retailers need the ability to visually search their apparel catalogue based on photos in order to look up matching items.
In early 2018, Microsoft teamed up with a successful international online fashion retailer to tackle just this sort of headache. Our aim was to work with this retailer to design an algorithm capable of identifying whether a newly arrived item was in stock using only a mobile phone image of the new item as a reference. If the retailer’s staff could snap a photo of a new arrival and use our solution to search their catalog of studio images for matches, we could eliminate the cost of errors and wasted time. Such a retrieval algorithm could allow our partner and other online retailers of all kinds to better manage their inventory – what’s more, the same solution might also assist in the development of a powerful search and retrieval tool.
Challenges and Objective
When applying any content-based image retrieval, it is very likely that the performance will be hindered by the difference between the visual environment of the image and its target match. These differences are introduced due to the busy background of one image compared with the clean background of a studio image, inconsistent folding or creases in the apparel, lighting differences, scale and point of view angle differences. Of all of these, the biggest obstacle for our retrieval solution was accounting for the discrepancy between the often busy background of a mobile image – our query image – and the clear, uncluttered background of the studio quality image – our target image. In other words, in applying our content-based image retrieval solution, we had to find a way to make sure the mobile images’ busy backgrounds didn’t confuse our retrieval algorithm.

Figure 1: Query image versus target image.
Our mission thus was to develop a specialized image segmentation tool that could remove the background of the query image and thereby ensure the success of the retrieval algorithm. To this end, we experimented with two different approaches: first, using a computer vision approach known as GrabCut, and then afterward employing the recently developed deep learning segmentation approach, Tiramisu.
GrabCut
The most promising computer vision background removal technique we originally thought of to try was GrabCut. GrabCut is an iterative segmentation method that requires the user to specify a bounding box around the region of interest. A Gaussian mixture model, typically of 5 components, is then used to estimate the color distribution of the target and background in an iterative manner until convergence.
One property that makes GrabCut an excellent choice is the ability to provide cleaner segmented edges, owing to its border-matting feature. Given that our aim was to reduce as much irrelevant content as possible from the query image, this feature was crucial in this use case. It’s also worth noting that the GrabCut method allows human interaction to ‘correct’ the segmented results, manually indicating misclassified regions and then rerunning the optimization (though manual correction was not used in this experiment).
Figure 2 below illustrates the GrabCut process. Figure 3 then shows two query images in the first column, a blue and white shirt, each 10 pixels smaller than the original image size. In the second column, we see the automated GrabCut method applied, and the third displays results after the method was rerun and corrected by human interaction.
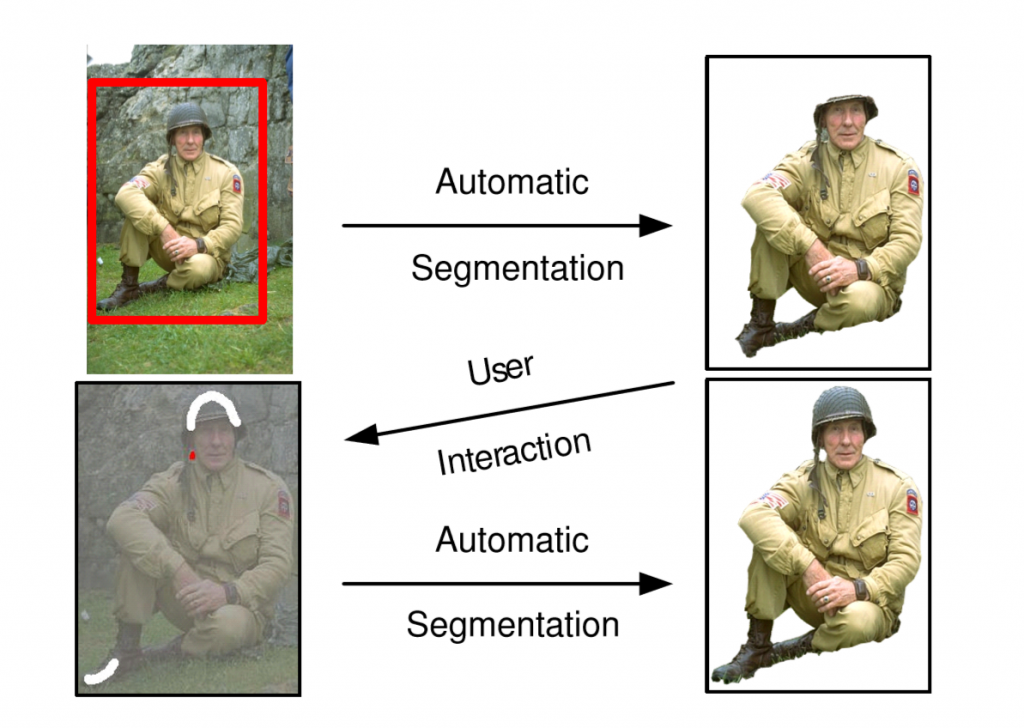
Figure 2: GrabCut process. Image reference (Rother, Kolmogorov, & Blake, 2004)

Figure 3: Examples of background removal using GrabCut and GrabCut with human interaction. (1st column: snapshots; 2nd column: using Grabcut; 3rd column: Grabcut with human interaction)
Though effective, the GrabCut automated background removal technique does require a human to make initial basic settings for each image including the bounding box. It also requires a number of iterations for the iterative graph-cut optimization.
With these advantages and disadvantages noted, our team then experimented with a different approach to background removal which didn’t require humans in the loop beyond creating the first labelled training set. For this we employed Tiramisu, one of the latest types of deep learning architecture for image segmentation.
Tiramisu
Tiramisu is a type of DenseNets, a recently proposed type of convolutional architecture. When applied to image segmentation, and training from scratch with a relatively small set of training data, DenseNets has been shown to achieve a remarkable accuracy. For example, Tiramisu achieved 94% accuracy on a street scene training set as demonstrated here, where 12 segmentation classes were trained with only about 600 images from the CamVid dataset.
With only a few mobile snapshots available for training, the effectiveness of Tiramisu with relatively small sets of training data made it an optimal choice for our team. For this task’s relatively unique set of apparel images, which share many homogeneous characteristics, we hypothesized that a ‘from scratch’ trained network would perform better.
DenseNets are built from dense blocks and pooling operations. Within each dense block is an iterative concatenation of previous feature maps. This architecture is thought of as an extension of ResNets, with the key improvements of parameter efficiency, implicit deep supervision through short paths to all feature maps, and feature reuse. Figure 4 shows the Tiramisu network architecture (paper), while the reference examples we leveraged are available here and here.

Figure 4: Tiramisu architecture.
In our case, due to GPU memory constraints, we modified a few training parameters with respect to the reference example. We used 6 dense blocks and applied 4, 5, 7, 10, 12 and 15 layers per block, respectively (as per the reference example). The training epochs and batch size were both reduced from 500 to 100 epochs, and from 9 to 4, respectively. The learning rate was reduced from 1e-3 to 1e-4, and we changed the optimizer from RMSProp to ADAM optimizer with amsgrad enabled. All other parameters were defaulted to the reference example. The code can be found in this Jupyter notebook.
Model Input/Training Data
Sample data consisted of 249 mobile snapshot images sized 516 x 516 and segmented with GrabCut using human intervention. Each snapshot had a human-labeled mask, identifying the foreground apparel item and the background. The data is split into a training set of 199 images and a test set of 50 images. They are then augmented with horizontal flipping.
Model Output
The output is a 2-class prediction, identifying those pixels belonging to the foreground and the background. While the reference examples were trained for 500 epochs, the network was trained for 100 epochs. The model achieved a very respectable 93.7% accuracy rate at this stage of training, proving itself a fit for our use case.
This task is a binary segmentation: the two classes are the background and the foreground (the garment). This means that, given a picture, the segmentation model is expected to generate a segmentation mask. Such masks can be represented as a ‘0’ and ‘1’, representing the background and foreground, respectively, as shown in Figure 5.

Figure 5: an example of input (original image), label to be predicted (mask), and predicted Tiramisu result.
Figure 6 shows examples of good segmentation results, where most images have reasonable contrast against the background. Figure 7 shows the results of segmentation achieved after 100 epochs, where the segmentation is not perfect.

Figure 6: Example results where the model performs well.
 Figure 7: Example results where the model’s performance is less promising.
Figure 7: Example results where the model’s performance is less promising.
It is interesting to note that in a few examples where the human labeling was not perfect the model partially reproduces the same error. It seems like the network has not only ‘learned’ to segment, but it may have also ‘learned’ the human labeling error. Figure 8 illustrates this effect – note the right collar of the first row of images, and the left sleeve of the second row of images. It seems that the model was also uncertain about backgrounds with either lighter or very distinctive colors. Both issues could be mitigated by sampling more samples representative of such cases.


Figure 8: Example results where the model seems to ‘learn’ human error.
Train and Test Procedure
As previously mentioned, the model was trained for 100 epochs. We leveraged Keras’s Callback features of early stopping to avoid overfitting, as well as ModelCheckpoint to monitor model progress during the training. To continue learning when the model has hit a loss plateau, we used the ReduceLRonPlateau callback to reduce the learning rate when the model hasn’t been learning for 10 epochs. Since AMSGrad is applied, the ReduceLRonPlateau was never triggered. We used the same test set throughout, which was never used for training. We found the model was sensitive to initialization and, generally speaking, it learned very slowly. It is likely that with an increased amount of training data, the model accuracy will improve. Figure 9 shows the training metrics.
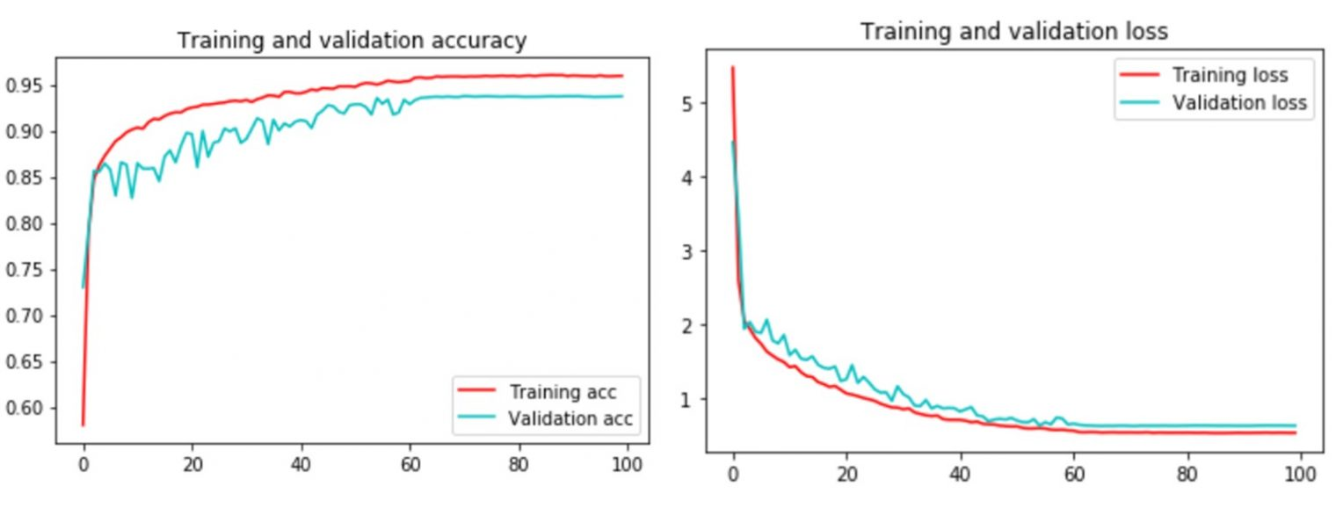
Figure 9: Training and validation accuracy, and training and validation loss.
Keras with a TensorFlow backend is used for modeling, Jupyter notebooks as the IDE, and compute on Azure Data Science Virtual Machine with 16 VCPUs with 16GB of RAM, and 32000 max IOPS. The notebook example can be found here. It took 56 seconds per epoch to train at a batch size of four.
Applying the Output of Semantic Segmentation
Our results confirmed that the ‘from scratch’ semantic segmentation model allows the automated masking of the background through identification of apparel and non-apparel pixels from the Tiramisu model. Based on the model’s predicted foreground and background, the original query image was cropped to the edges of the predicted foreground, with the background set to the color white, mimicking the target images. Next, the image similarity algorithms were applied in order to achieve higher quality image matching results.
Summary
We have developed an image segmentation model for application to background removal using Tiramisu, one of the most recent types of deep learning architecture. With the hope of assisting in the development of a retrieval algorithm to simplify the retailer’s inventory process, our aim in the above-described project was to enable an effective visual search algorithm by neutralizing interference from the images’ varied backgrounds.
Ultimately, our garment segmentation tool proved quite capable of segmenting photograph foreground from background, and allowing us to eliminating the query image’s busy background. By successfully removing this obstacle to matching the query image with an item potentially already in stock, this helps to improve the content-based image retrieval performance to meet the operational needs of our use case.
Our approach can also assist others in future content-based image retrieval projects. We encourage anyone building a visual search solution to leverage this background removal technique, and leverage the code we have shared in our GitHub repo.
If you have any questions or feedback on this code story, please reach out in the comments below.
References
- Grabcut
- Tiramisu
Hi,
I would like to reproduce your results. So, I need to download the dataset. I have a azure storage account. I failed to download. I got error:
AzureMissingResourceHttpError: The specified container does not exist.
ContainerNotFoundThe specified container does not exist.How can I download the dataset?
Hi, the dataset used is a private dataset. Please see my reply to @alimul hoque, thanks.
Hello,
I like your approach. I would like to retrain the network. Where can a get a copy of the training and test datasets?
Thanks
Hi, the dataset used is a private dataset. One option is to consider some computer vision methods, such as ‘grabcut’ to semi-automate the labelling of segmented region of your own data. semi-automate here means that, e.g., if your region of interest is always within the frame, and most of the time cover a large area of the frame, in this case, you can ‘draw’ a box that is, say, (x1=5, x2=maxx-5, y1=5, y2=maxy). I hope that make sense. While this does not fully replace manually labelling, but it will help to reduce time spent on manual labelling.