

Introduction
In a recent engagement, our team of Data Scientists and Software Engineers, developed a series of custom AI models to meet our customer’s specific use case. While doing so, consideration was given to how best to allow Data Scientists the freedom to quickly experiment and iterate on model development, while also incorporating engineering fundamentals such as CI / CD, PR review, testing, and observability into the process of delivering candidate models for performance evaluation at inference time in production environments. This article will review several designs / patterns we evaluated to accomplish this, weighing the pros and cons of each.
Data Scientists want the ability to quickly experiment with models and explore data, while Software Engineers want to enforce code quality and engineering fundamentals such as CI/CD, automated testing, and observability. Enforcing these strict engineering fundamentals on Data Scientists during model development and experimentation may cause unnecessary overhead and a potential tax on productivity. And so, we arrived at a question: “What engineering fundamentals and processes allow Data Scientists the freedom to quickly iterate, experiment, and prototype while also providing the visibility and collaboration necessary for ML engineers to support eventual production deployment?”
The Data Science Workflow
Developing a machine learning model is a highly iterative workflow starting with Exploratory Data Analysis (EDA). EDA is a crucial step in every data science project that involves thoroughly examining and characterizing the data to uncover its underlying characteristics, possible anomalies, and hidden patterns and relationships. By exploring the data, Data Scientists build towards a deep understanding of the data’s characteristics which allows them to more confidently develop the subsequent steps in the machine learning pipeline, such as data preprocessing, model building, and analysis scripts. The data scientist will iterate over these scripts to determine how a model performs against a defined set of benchmarks to warrant additional engineering resource investment and, when models show promise, implement observability libraries such as MLFlow into their scripts to enable decision making about a model for downstream production deployment.
The goal is to tailor the model development process to be as productive as possible when prototyping and experimenting as part of model development. In the spirit of “fail fast”, implementing full engineering fundamentals on this experimentation process may simply add friction and may not be well-received by Data Scientists accustomed to performing model development as a solo or siloed effort. To meet these requirements, our team established a dedicated prototyping repo with branch protection and a minimal CI workflow. This includes linting and checks to prevent checking in secrets which balanced the needs and skill sets of the Data Scientists and engineers on the project during the early model exploration and experimentation process.
Assumptions
This article focuses on the experience of using a customized implementation of the model factory / dstoolkit-mlops-v2 as part of a customer engagement. This article assumes that you have already made the decision to leverage this MLOps framework or similar approach with built-in strong engineering fundamentals.
Model Factory
Our team leveraged the dstoolkit-mlops-v2 Model Factory as a starting point. We initially had several conversations with the customer to understand their requirements and long-term goals. From these conversations we learned the following:
- They are building up their data science skill sets and team.
- They have numerous experiments in mind for a range of machine learning and generative AI model capabilities.
- For candidate models to promote to production environments, they need a process that enables strong engineering fundamentals and observability to provide decision makers and leaders confidence to ship ML models in production as a new capability in their flagship product suite.
Based on this feedback, our team added several enhancements to the dstoolkit-mlops-v2 to meet the specific needs of our customer. The resulting Model Factory based on this architecture, served as the main integration point between the data science and software engineering teams, enabling them to collaborate on model creation during the development from data analysis to a stable, reliable and auditable production model artifact. The model factory housed productized models via strong engineering fundamentals with automation provided by CI / CD workflows. Below is a diagram showing a conceptual overview of the solution.
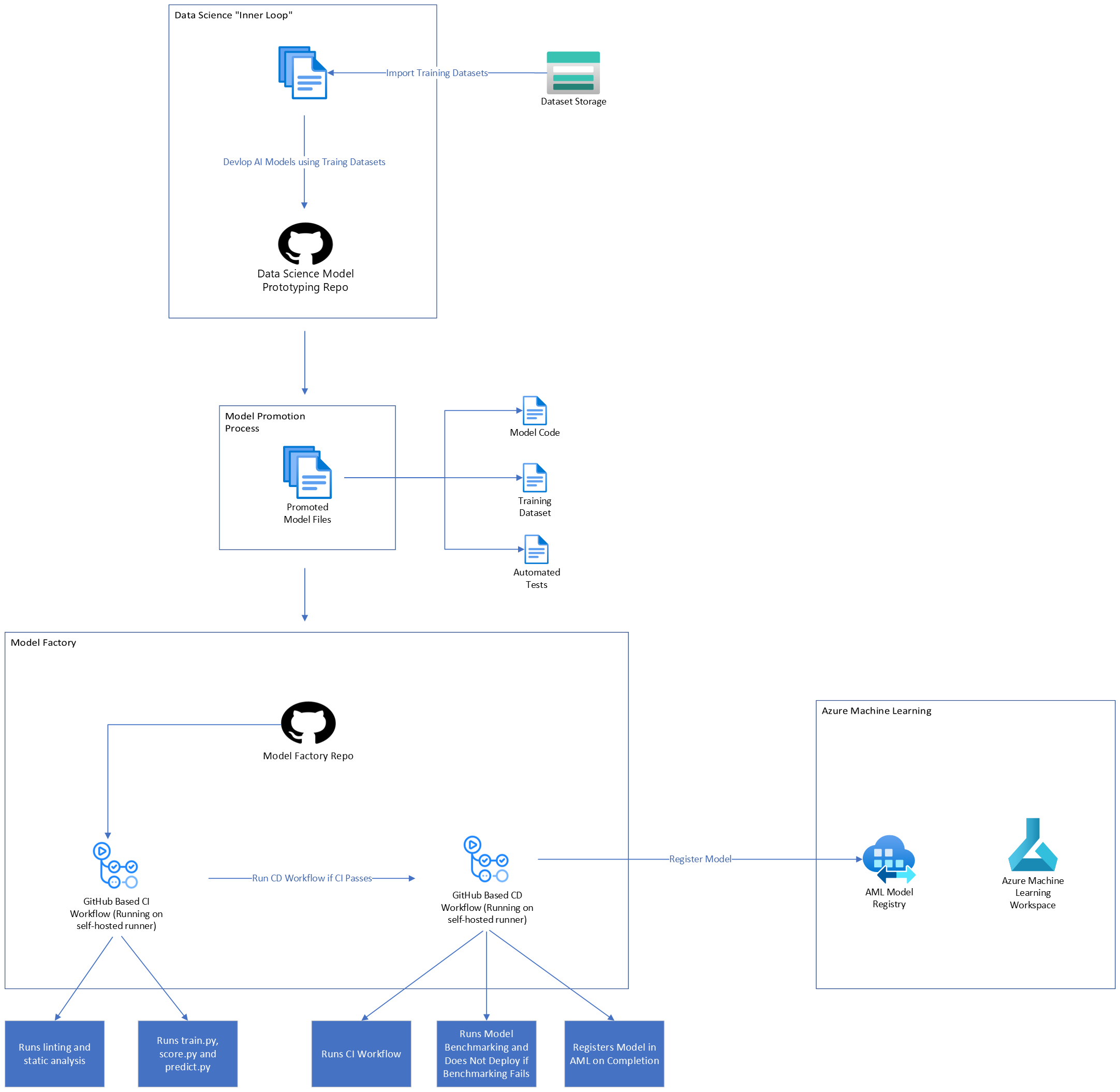
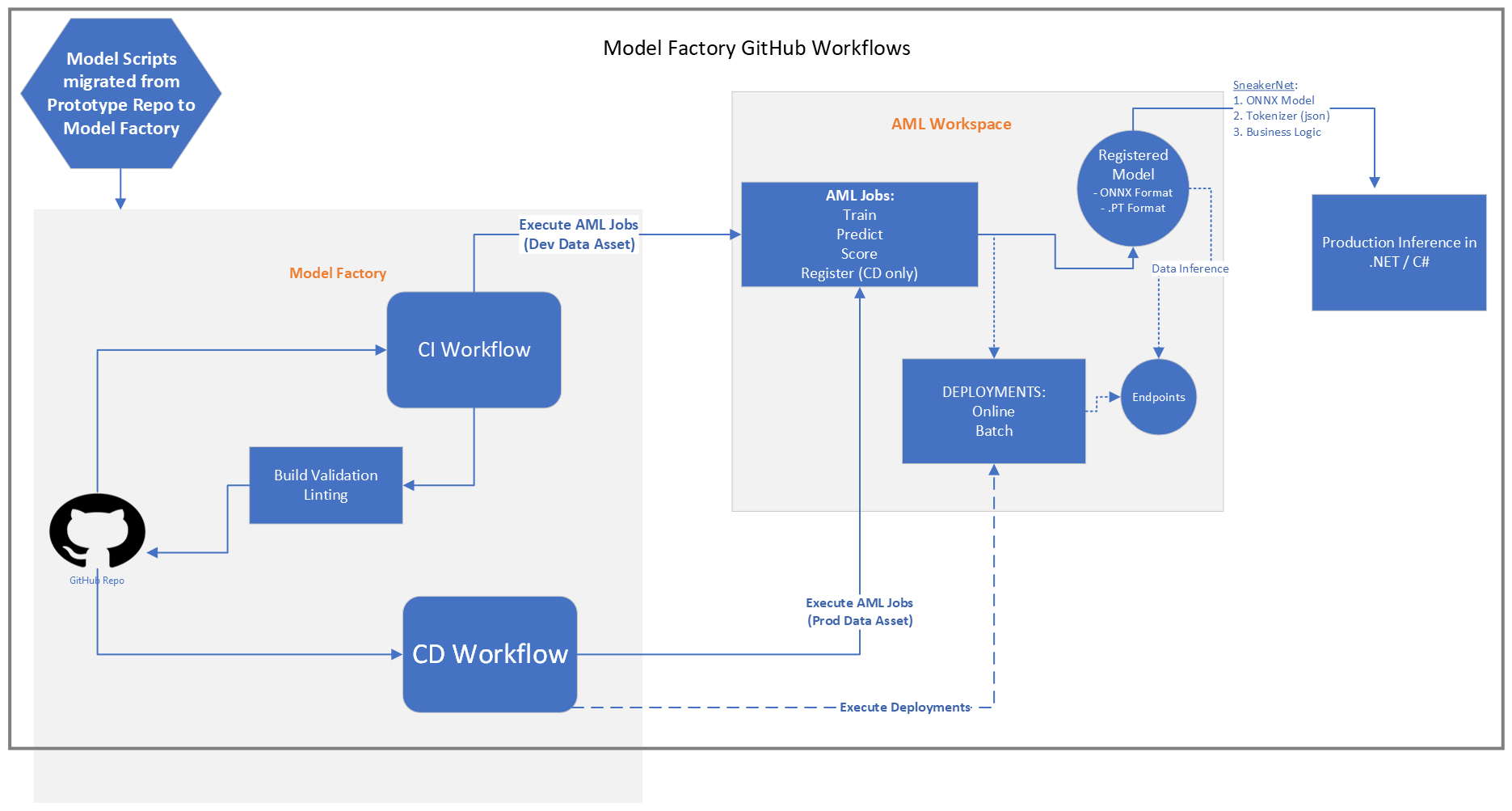
Below is another view of the solution, including additional enhancements we made to the model factory. While model production was completed in Python, this customer was a .NET shop for production application deployment. These enhancements include the ability to evaluate model inference hosted in a .NET based model candidate test harness.
Designs Considered
These sections outline the three different designs we considered while creating the model factory and weigh the pros and cons of each.
Data Scientists Working Directly in the Model Factory Repo
One approach is to have Data Scientists work directly in the model factory. This represents essentially having Data Scientists create models with rigorous software engineering processes and mandatory engineering fundamentals. Working directly in the model factory requires Data Scientists to apply engineering fundamentals to what are often experimental changes in model development. This introduces significant overhead for experimental work that may never make it past prototyping development and therefore working within this environment is a tax on data scientist productivity.
Also, using a single repository for both experimentation and production work can clutter the git commit history with experimental data science changes, making it messy to separate failed experiments from production candidate builds. One way to prevent this is to only allow squash commits on PRs. Doing this, however, does not preserve the incremental experiment history and removes the ability to go back to a specific experiment in the commit history.
One benefit of maintaining a single repository is the absence of any need for explicit model integration into the model factory from the separate repository. It also facilitates tight collaboration between Data Scientists and Software Engineers since all changes occur in the same repo and are immediately visible and available to everyone.
Pros:
- Eliminates Integration: Models are developed and tested directly within the model factory, eliminating the need to integrate model code promoted from the prototyping repo.
- Seamless Collaboration: Working directly in the model factory ensures that all team members are working from the same codebase. Changes made by Data Scientists and Software Engineers are immediately visible to everyone, fostering better communication and collaboration.
Cons:
- Increased Overhead / Inability to Make Breaking Changes: The model factory contains CI / CD workflows, automated tests and benchmarking which run on PR. This means that each change must be production ready, deployable and able to pass automated testing and benchmarking. These strict criteria introduce a lot of overhead that are a tax on the ability of Data Scientists to rapidly make experimental changes during model development and could drive Data Scientists back to experimenting with models locally or in stand-alone environments.
- Experiments are Integrated / Deployed: Because experimental, data science related changes are made in the same repository as the productized models and CI / CD workflows, each change is integrated and potentially deployed whether it’s ready for production or not. Without adding additional complexity to filter these changes out, this leads to the training, publishing, and deployment of models that were experimental in nature and never intended for production—although this may be acceptable as part of experimentation.
- Repository Clutter: Keeping data science experimentation / prototyping files in the same repository as the model factory could cause the repository to become cluttered with files such as test datasets, python notebooks, etc. It also clutters the git history as it mixes experimental commits / changes in with those for officially promoted models.
- Experiment History Not Preserved: When data science experimentation occurs in the same repository as promoted models, it also means the git history contains both experimental and productized changes. This clutters the git history and makes it hard to identify which commits are tied to experiments vs. production candidate models. This can be prevented by requiring squash merge commits in PR, however, doing this means that the git history of experimental changes is lost.
Data Scientists Working in Dedicated Directory in Model Factory
Another approach is to have Data Scientists work in a dedicated directory in the model factory. This directory would be ignored by CI / CD and would not enforce engineering fundamentals. This approach could offer a good balance between Data Scientists working directly in the model factory vs. in a dedicated repository. It provides Data Scientists with an isolated area where they can experiment without the overhead of continually applying engineering fundamentals. In addition, since data science and software engineering work are still done in the same repository, it retains the benefits of tight collaboration between teams. It also, however, retains the downsides of experimental files cluttering the repository as well as the git commit history. Furthermore, because model code developed in a dedicated directory is no longer continually developed to be compatible with the model factory, integrating it into the model factory would still require a well-defined model promotion and integration process.
Pros:
- Seamless Collaboration: Working directly in the model factory enables all team members to work from the same codebase, which is appealing to Software Engineers. Changes made by Data Scientists and Software Engineers are immediately visible to everyone, fostering better communication and collaboration.
Cons:
- Models Require Integration: Once models developed in the data science directory meet the requirements, they can be promoted, at which time they must be explicitly copied from the
experimentationdirectory and integrated into the model factory. This merging process takes time away from model experimentation. - Repository Clutter: Keeping data science experimentation / prototyping files in the same repository as the model factory could cause the repository to become cluttered with files such as test datasets, python notebooks, etc. It also clutters the git history as it mixes experimental commits / changes in with those for officially promoted models.
- Experiment History Not Preserved: When data science experimentation occurs in the same repository as promoted models, it also means the git history contains both experimental and productized changes. This clutters the git history and makes it hard to identify which are which. This can be prevented by executing / enforcing squash merge commits, however, doing this means that the git history of experimental changes is lost.
Suppose we designate and folder experimentation placed at the root of the dstoolkit-mlops-v2 as a place to host EDA and experimental development. Using the sample Nyc Taxi PR Workflow(.github/workflows/nyc_taxi_pr_pipeline.yml) in the dstoolkit-mlops-v2, we could configure GitHub workflows to ignore this directory by adding a paths-ignore block. For example:
name: Nyc Taxi PR Workflow
on:
pull_request:
branches:
- development
paths:
- '.github/**'
- 'mlops/common/**'
- 'mlops/nyc_taxi/**'
- 'model/nyc_taxi/**'
- 'src/nyc_src/**'
- 'test/nyc_taxi/**'
paths-ignore:
- '.experimentation/**'
Data Scientists Working in a Separate Prototyping Repo
The final approach is to have Data Scientists work in their own repository for model experimentation. This is what we found worked best with our customer. In this approach, Data Scientists perform exploratory data analysis and experimentation in a separate and dedicated repo. It provides Data Scientists the freedom to experiment and preserves experiment history. However, like the dedicated repo approach, it requires explicit model integration. When models meet the customer criteria for promotion, they are integrated into the model factory via a well-defined promotion process.
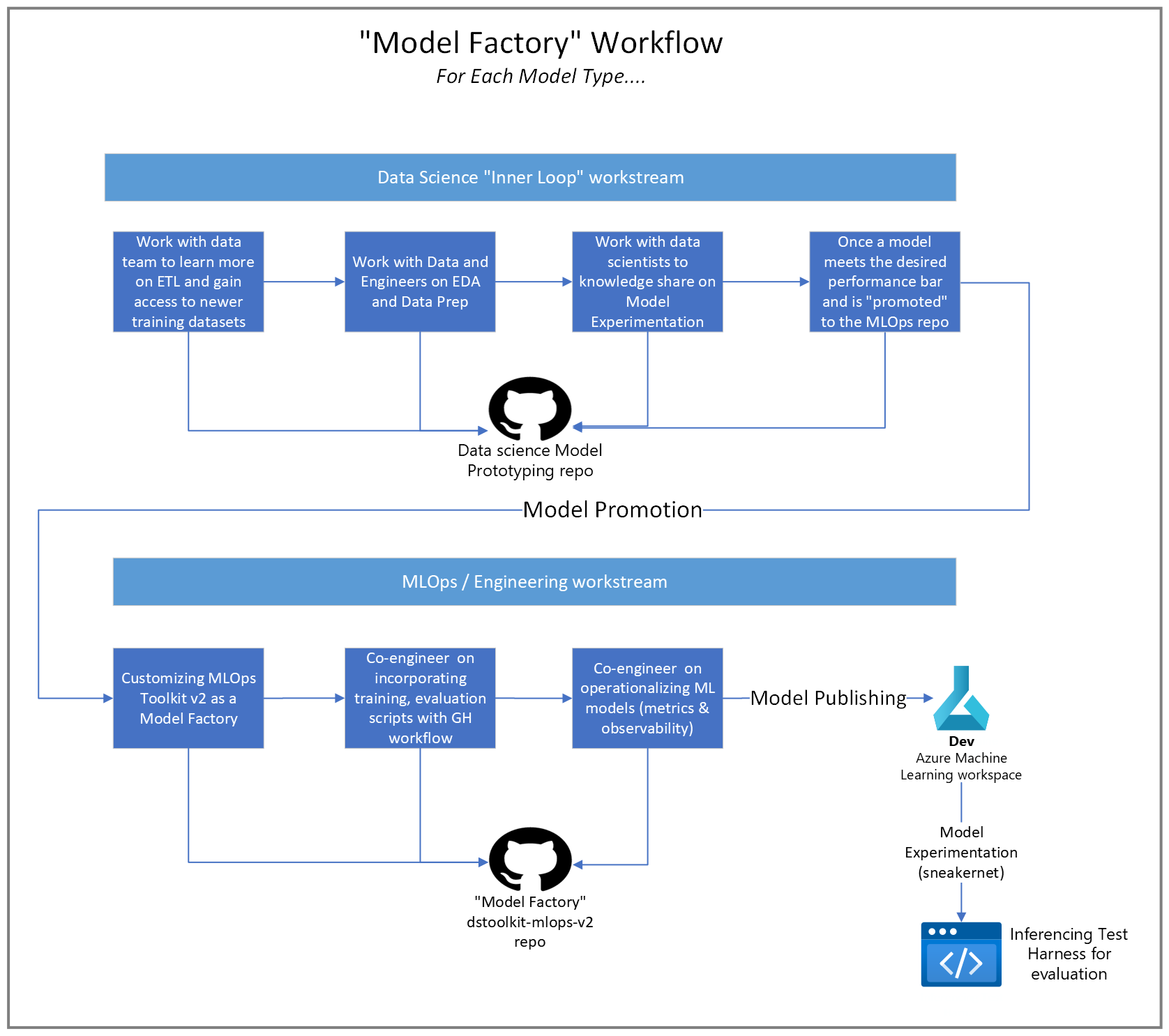
Pros:
- Freedom for Experimentation: Working in an independent repo provides Data Scientists the freedom to experiment and iterate quickly without the constraints of the strict engineering fundamentals applied in the model factory. Each change does not need to be production ready / deployable.
- Only Production Candidate Models are Registered: Because data science experimentation is confined to the dedicated data science repository, only models that are candidates for production are integrated into the model framework and published to the Azure Machine Learning Model Registry. This reduces clutter and provides a clean git history by regulating experimental models, files and related data to the data science repository.
- Self-Documenting Experimentation: Because data science experimentation is done in its own repository, a history of prototyping changes is preserved in the source control history. This can be used for later reference or if new modeling techniques become available and we want to revisit an experiment with a base model.
Cons:
- Models Require Integration: Once models developed in the data science repo meet the requirements, they can be promoted, at which time they must be explicitly integrated into the model factory. This merging process takes time and is a tax on productivity. This process is outlined in the Model Promotion Process section below.
While there are pros and cons to each design, our team felt that the freedom to experiment, separate git commit history, and reduced clutter that having two repos provides is extremely valuable and heavily impacted our decision to use this approach. The cons associated with having two repos can be minimized by:
- Establishing / enforcing consistency in how model building and other associated scripts are implemented and organized (i.e. not one big / long Python script). A consistent pattern / structure of model creation Python files should be established and followed when implementing new models.
- Establishing / enforcing a minimum code quality bar in the prototyping repo. While the rigorous engineering fundamentals of the model factory are not necessary or desirable, Python code developed in the prototyping repo should be linted, have static analysis performed and checked for secrets / credentials. It’s a good idea to implement a simple CI pipeline to handle this and that is what we implemented.
- Standardizing the parameter inputs and outputs to the Python scripts in the prototyping repo eased promotion by confirming to what was designed in the model factory. It would be easy to simply reference local files as inputs and outputs to scripts in the prototyping repo. This, however, causes additional work when integrating model production candidates that meet the bar into the model factory as they need to be updated to read and write from files in AML. Preemptively standardizing in the prototyping repo saves time during integration into the model factory and conforms to software engineering best practices as well.
Model Promotion Process
Model promotion into the Model Factory is a collaborative process between the Data Scientists and ML Software Engineers to incorporate the data scientist’s machine learning source artifacts into a production quality framework for maintaining, testing, and producing models for production inference evaluation and feedback.
Once models developed in the data science repo meet the defined requirements, they are eligible for promotion. During promotion, the versioned model source code and inference tests are copied from the data science repo and manually integrated into the model framework repo. Additionally, the versioned dev dataset used to train the promoted model is registered in AML as a Data Asset that can be referenced when the model is trained as part of the model factory’s CI processes. The dev data asset can also be integrated into existing ETL processes such that it is automatically registered in AML when ETL runs.
This trio of versioned files, i.e. the model source code, training dataset (dev and production versions) and data inference tests, represent a promoted model which is then integrated into the model factory. The CD pipeline trains the model on the full Data Asset and registers the production model candidate in the Azure Machine Learning Model Registry.
Data Product and Dataset Management
When the data science team is working with models, a key driver of model performance is the underlying dataset. As part of Exploratory Data Analysis (EDA) and model training, experiments with the dataset shape and underlying data are expected.
Management of models and the Datasets used to train them requires strong engineering fundamentals. These include observability to ensure traceability of a given model version to the dataset version used to train it for production deployment. At the same time, Data Scientists and Software Engineers require a low friction means to transform datasets as needed into new datasets to enable model training experimentation to meet performance goals. The following diagram depicts the dataset lifecycle:
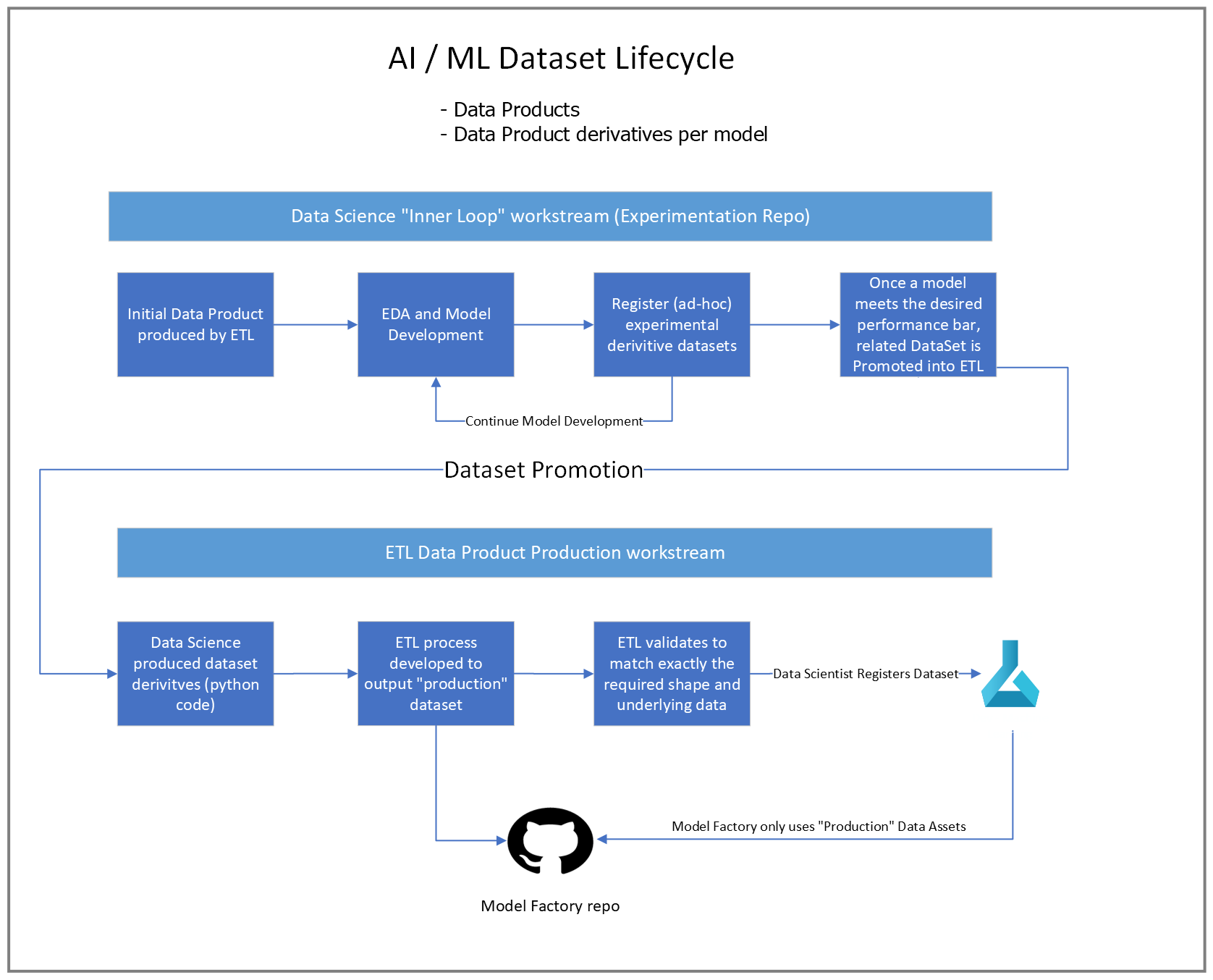
Conclusion
Selecting the right workflow for Data Scientists and Software Engineers to collaborate effectively is essential in delivering successful AI models to production. In our exploration, we evaluated several repository structures and workflows, each with distinct pros and cons around productivity, traceability, and collaboration. Ultimately, we found that providing Data Scientists with a dedicated prototyping repository for experimentation—while maintaining a separate model factory repository governed by strong engineering fundamentals—provided the best balance. This allowed our Data Scientists the freedom to innovate and iterate rapidly, while still ensuring Software Engineers could efficiently integrate, test, and deploy production-ready models with confidence. Establishing clear guidelines, minimum code quality standards, and consistent script structures further streamlined the promotion process and minimized integration overhead. We hope our experience helps your team navigate similar challenges, enabling you to build and deploy robust AI solutions effectively and efficiently.
The feature image was generated using Bing Image Creator. Terms can be found at Bing Image Creator Terms of Use.