

PromptFlow Serve: Benchmark Result Analysis
My team have been developing a relatively complex PromptFlow application for the last few months and as a part of getting it ready for production scale, did performance testing and optimisations. This blog post summarises our finding from doing performance testing of various runner options of promptflow-serve and our recommendations.
Test Scenario
Before testing the entire application, we created a sample flow that mimicked part of our real flow. It contained a fan-out and fan-in flow to replicate LLM nodes like guardrails running in parallelly and a final node that does an API call to an external dependency. This API call was made to a mock HTTP API. A synthetic delay was added to each of the parallel nodes to replicate LLM calls.
The harness contained these components:
- A mock HTTP API that acts as a service used by your PromptFlow flow.
- The following PromptFlow flows that are hosted using
pf-serve.- Synchronous flow hosted using WSGI.
- Asynchronous flow hosted using ASGI and async Python functions as PromptFlow nodes.
- Locust load test generator.
- Makefile, scripts and docker-compose file to orchestrate the tests.
The test harness and example used to create the test scenarios discussed has been contributed to the PromptFlow repository via a pull request here.
Flow
The directed acyclic graph (DAG) for both the flows are shown below.
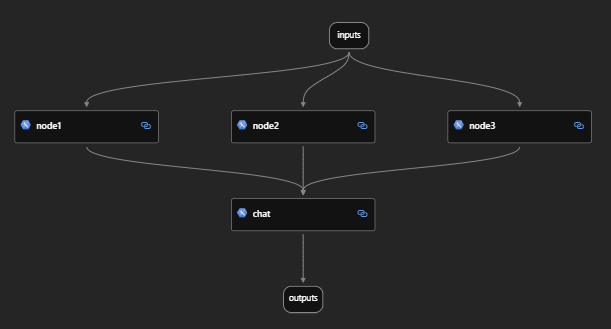
- Parallel
nodes 1, 2 and 3have a synthetic delay of0.25msto simulate an LLM call like guardrails. - The
chatnode makes a HTTP call to the mock API to simulate a downstream service call.
Host Runner Options, Synchronous and Asynchronous Nodes
The aim of our selected variations were to test how pf-serve behaves when using the default WSGI runner (Gunicorn) compared to an ASGI runner (FastApi) with the combination of async PromptFlow nodes.
The load was generated using Locust and had a maximum of 1000 concurrent users with a hatch rate of 10. The test was run for 5 minutes. We ran each combination with 8 workers and 8 threads per worker. The test was run on WSL which had 16GB of memory and 8 logical processors. The guidance around concurrency can be found here.
In hindsight, 1000 concurrent users were exhausting the limited resources available on the host environment. We not only had the test harness but also the mock API running in the same host. Ideally the mock API should have been run elsewhere so it would not interfere with the test harness. But our aim was to find patterns and bottlenecks rather than be super precise around maximum achievable throughput.
If you want to find a more accurate number for the sustainable concurrent users for your environment, run the included load test against the mock API endpoint provided in the benchmark suite. This will give you sense of what ASGI (FastApi) can support in your environment without PromptFlow in the mix. You can also use this result as a guide to compare the throughput to the sync and async variants (where PromptFlow is in the mix).
Sync vs Async Nodes
The PromptFlow @tool annotation supports both sync and async functions. Hence both of the below code examples are valid but as you will see later, they have a massive performance impact as the sync example blocks the thread.
The sync example uses the requests library to make a synchronous call to the mock API.
import os
import time
import requests
from promptflow.core import tool
@tool
def my_python_tool(node1: str, node2: str, node3: str) -> str:
start_time = time.time()
# make a call to the mock endpoint
url = os.getenv("MOCK_API_ENDPOINT", None)
if url is None:
raise RuntimeError("Failed to read MOCK_API_ENDPOINT env var.")
# respond with the service call and tool total times
response = requests.get(url)
if response.status_code == 200:
response_dict = response.json()
end_time = time.time()
response_dict["pf_node_time_sec"] = end_time - start_time
response_dict["type"] = "pf_dag_sync"
return response_dict
else:
raise RuntimeError(f"Failed call to {url}: {response.status_code}")The below async example uses aiohttp to make an async call to the mock API which allows the node function to be async as well.
import os
import time
import aiohttp
from promptflow.core import tool
@tool
async def my_python_tool(node1: str, node2: str, node3: str) -> str:
start_time = time.time()
# make a call to the mock endpoint
url = os.getenv("MOCK_API_ENDPOINT", None)
if url is None:
raise RuntimeError("Failed to read MOCK_API_ENDPOINT env var.")
async with aiohttp.ClientSession() as session:
async with session.get(url) as response:
if response.status == 200:
response_dict = await response.json()
end_time = time.time()
response_dict["pf_node_time_sec"] = end_time - start_time
response_dict["type"] = "pf_dag_async"
return response_dict
else:
raise RuntimeError(f"Failed call to {url}: {response.status}")Combinations Tested
- WSGI (
gunicorn) + Sync PF Nodes - ASGI (
fastapi) + Async PF Nodes
It’s important to note that PromptFlow Docker image based deployment uses the WSGI runner (Flask) by default. You must opt-in to use FastApi.
Test Results
| Metric | WSGI + Sync Nodes | ASGI + Async Nodes |
|---|---|---|
| Request Count | 12,157 | 65,554 |
| Failure Count | 1 | 43 |
| Median Response Time (ms) | 9,900 | 1,400 |
| Average Response Time (ms) | 13,779.82 | 1,546.90 |
| Min Response Time (ms) | 1.07 | 0.73 |
| Max Response Time (ms) | 48,101.42 | 4,212.50 |
| Requests/s | 40.60 | 218.85 |
| Failures/s | 0.0033 | 0.1435 |
| 50% Response Time (ms) | 9,900 | 1,400 |
| 66% Response Time (ms) | 17,000 | 1,500 |
| 75% Response Time (ms) | 22,000 | 1,700 |
| 80% Response Time (ms) | 24,000 | 1,800 |
| 90% Response Time (ms) | 34,000 | 2,100 |
| 95% Response Time (ms) | 40,000 | 2,400 |
| 98% Response Time (ms) | 47,000 | 2,800 |
| 99% Response Time (ms) | 48,000 | 3,000 |
| 99.9% Response Time (ms) | 48,000 | 4,000 |
| 99.99% Response Time (ms) | 48,000 | 4,100 |
| 100% Response Time (ms) | 48,000 | 4,200 |
Throughput Graph
WSGI + Sync Nodes
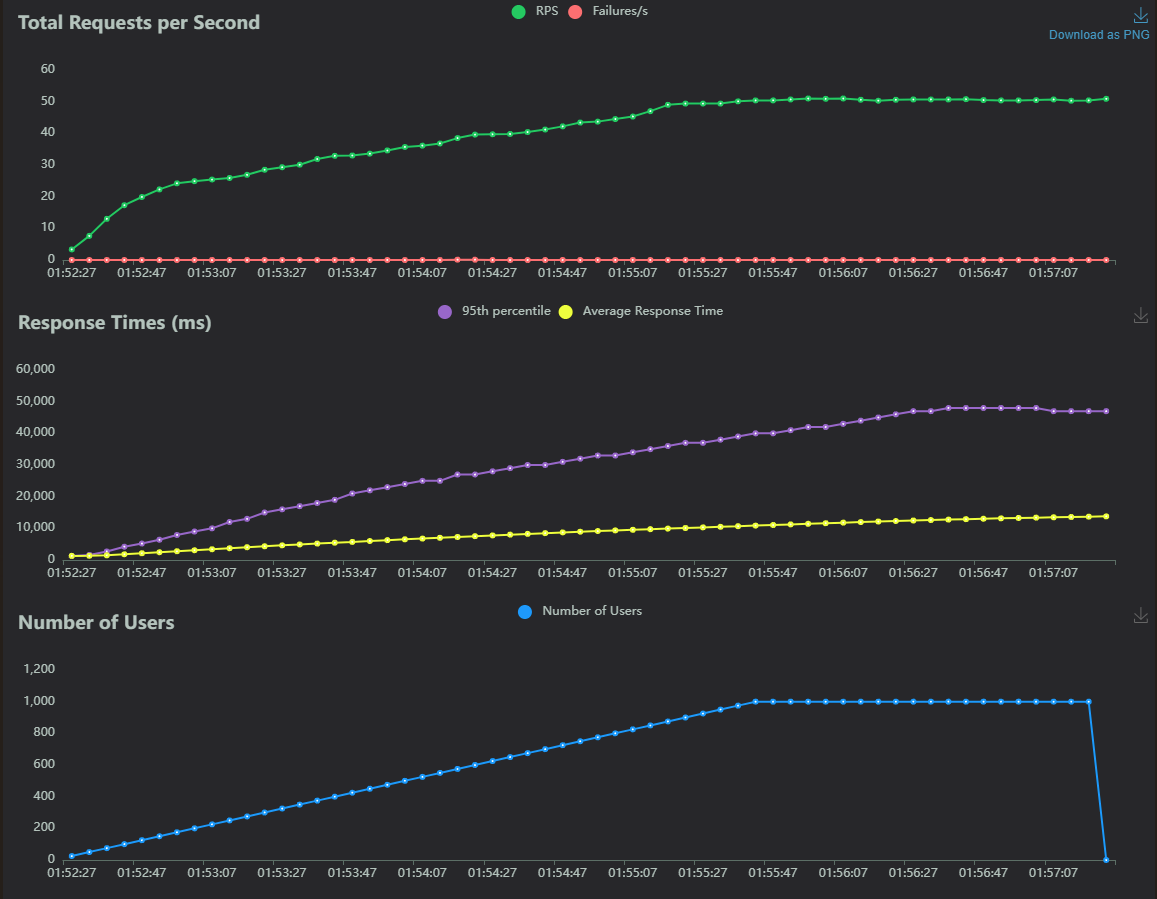
ASGI + Async Nodes

Detailed Comparison
Request Count and Throughput
- Request Count: Async variant handled approximately 5.4 times more requests than Sync setup.
- Requests/s: Async variant achieved 218.85 requests/s compared to Sync setup’s 40.60 requests/s. This indicates async variant handled requests more efficiently, possibly due to its asynchronous nature.
Response Time
- Median Response Time: Async variant’s median response time (1,400 ms) was significantly lower than Sync setup’s (9,900 ms). This shows that most requests in async variant were completed faster.
- Average Response Time: Async variant’s average response time (1,546.90 ms) was also significantly lower than Sync setup’s (13,779.82 ms). This highlights async variant’s overall better performance in handling requests.
- Min Response Time: Async variant’s minimum response time (0.73 ms) was slightly lower than Sync setup’s (1.07 ms), indicating faster handling of the quickest requests.
- Max Response Time: Async variant’s maximum response time (4,212.50 ms) was much lower than Sync setup’s (48,101.42 ms), suggesting async variant managed peak loads more effectively.
Failure Count and Rate
- Failure Count: Sync setup had only 1 failure, whereas async variant had 43 failures. Despite this, async variant’s higher request count still resulted in a very low failure rate.
- Failures/s: Sync setup’s failure rate (0.0033 failures/s) was lower than async variant’s (0.1435 failures/s), although this needs to be considered in the context of the much higher load handled by async variant.
Percentiles
- Sync setup: The higher percentiles (75%, 90%, 95%, etc.) showed very high response times, peaking at 48,000 ms. This indicates Sync setup struggled significantly with higher loads, leading to large delays.
- Async variant: The percentiles for async variant were much lower, with the 99.9th percentile at 4,000 ms. This shows async variant provided more consistent performance under load.
Analysis of Performance Differences
The async variant demonstrated significantly better performance compared to the Sync setup application across all key metrics, handling more requests with lower response times and higher throughput. The primary reason for this difference is async variant’s end-to-end asynchronous nature, which allows it to handle I/O-bound operations more efficiently and manage multiple requests concurrently, unlike Sync setup’s synchronous handling. While async variant had a slightly higher failure rate, this was relatively minor considering the much higher load it managed to process effectively.
Evidence Of Backpressure In The Sync Setup
Backpressure occurs when a system becomes overwhelmed by the volume of incoming requests and cannot process them quickly enough, leading to increased response times and potential failures. Here are the indicators suggesting backpressure in the sync variant:
- High Median and Average Response Times:
- Median Response Time: 9,900 ms
- Average Response Time: 13,779.82 ms
These high response times indicate that the sync variant is taking a long time to process requests, which is a sign that it is struggling to keep up with the incoming load.
- Wide Range of Response Times:
- Min Response Time: 1.07 ms
- Max Response Time: 48,101.42 ms
The vast difference between the minimum and maximum response times shows that while some requests are processed quickly, others take an excessively long time, suggesting the system is experiencing periods of high load that it cannot handle efficiently.
- High Percentile Response Times:
- 75% Response Time: 22,000 ms
- 90% Response Time: 34,000 ms
- 95% Response Time: 40,000 ms
- 99% Response Time: 48,000 ms
- 99.9% Response Time: 48,000 ms
The high response times at these percentiles indicate that a significant proportion of requests are delayed, further suggesting the application is overwhelmed.
- Max Response Time:
- The maximum response time of 48,101.42 ms is extremely high and indicates that under peak load, some requests are waiting an excessively long time to be processed.
- Low Requests per Second (Requests/s):
- WSGI sync setup: 40.60 Requests/s
- ASGI async setup: 218.85 Requests/s
The sync variant handled far fewer requests per second compared to the async variant, indicating it is less capable of handling high loads efficiently.
These metrics collectively suggest that the sync variant is experiencing backpressure. The high and variable response times, coupled with the lower throughput, indicate that the application cannot process requests quickly enough under high load, resulting in delays and potentially dropped requests. In contrast, the async variant demonstrates significantly better performance and is more resilient to high loads, thanks to its asynchronous processing model.
The sync setup blocks the thread while waiting for the nodes to finish executing and thread pool exhaustion occurs when all available threads in the thread pool are occupied and new requests cannot be processed until some threads are freed up. This situation can lead to backpressure, where incoming requests are delayed or queued because the application server cannot handle them immediately. Increasing the worker and thread count may help but ultimately still suffers from thread blocking operations.
While async setup also shows signs of backpressure, such as higher response times for a small percentage of requests and a non-zero failure rate, it performs significantly better than sync setup under similar conditions. The asynchronous nature allows it to handle higher loads more efficiently, but it is still not entirely immune to the effects of backpressure when pushed to its limits. The signs of backpressure in FastAPI are much less severe compared to that of the synchronous gunicorn setup, highlighting its superior performance in handling concurrent requests.
tldr
The experiment showed that the bottleneck on the sync variant was the PromptFlow application itself, where as with the async variant the limiting factor was the system resources. This is an important learning showing that the async option achieves more with the same resources. This may seem obvious but there is responsibility on your part as a developer to ensure that the Python functions are async compatible (using the async await pattern and picking the right libraries for I/O) so the PromptFlow flow executor and ASGI hosting can take advantage of it.
Bonus Reading: Why Are There Relatively High Network Failures In The Async Variant?
During the test, the async setup resulted in 44 network errors while the sync setup only had 1.
The observed errors were:
| Error | Description |
|---|---|
RemoteDisconnected('Remote end closed connection without response') |
This error occurs when the client closes the connection abruptly. In the context of a high-load environment, this can happen if the server is too slow to respond, causing the client to time out and close the connection. |
ConnectionResetError(104, 'Connection reset by peer') |
This error indicates that the server closed the connection without sending a response. This can happen if the server is overwhelmed and cannot handle new incoming connections or if it runs out of resources to maintain open connections. |
These can be indicative of resource limits on the host.
- CPU Limits: If the server’s CPU is fully utilized, it might not be able to process incoming requests in a timely manner, leading to clients timing out and closing connections.
- Memory Limits: If the server runs out of memory, it might kill processes or fail to accept new connections, leading to connection resets.
Remember that we ran the mock API on the same environment and it required CPU, memory and network resources as well. As mentioned earlier the mock API is competing for resources with the test harness in this shared environment.
Explaining The Abrupt Changes In Requests Per Second and Response Time
If you looked at the time series graph closely, you would have noticed that there is some abrupt changes in the throughput and response times.

We observed that these occurred at the same timestamps when the above mentioned network errors occurred. Further indicating that this happened due to resource limitations.
Summary Of Findings And Recommendations
As observed, the async setup demonstrated significantly higher throughput and better response times. The only metric that was worse in the async setup was the number of network exceptions occurred but that was most likely due to the limitation of the memory and CPU in the environment the test was run in.
- Utilise an async supported http client like
aiohttporhttpxwhen calling downstream APIs or LLM endpoints. This would allow you to bubble up the async await pattern up to the node function level and allow PromptFlow flow executor to take advantage of it. - Start using FastAPI as the runner for
pf-serveby setting thePROMPTFLOW_SERVING_ENGINE=fastapienvironment variable.
These recommendations are easy to implement and should be good defaults for most scenarios. We tested the new flex flow from PromptFlow with an async setup and it behaved similar to the static DAG based flow.
Closing
You can start using the test harness we developed to test your own flow if you haven’t done any form of throughput testing.
It’s important that you make evidence based decisions when it comes to performance optimisations. This ensures you invest the effort in the most critical areas and helps make informed decisions. The approach we took to create a sample representation allowed us to experiment and isolate different aspects of a complex system. This approach needs to be continuous as your application evolves to identify the bottlenecks and make trade-off where required.
The feature image was generated using Bing Image Creator using prompt “There is a water stream flowing through a lush grassland. There are boulders blocking the flow and a robot is fixing a meter to measure the flow. View from above. Digital art.” – Terms can be found here.