

Purpose
As an Engineering team on Microsoft’s Commercial Software Engineering (CSE), we strive to empower customers to build and maintain their software-based solutions. A key factor in being successful in our goal is to educate, upskill and develop the solution by applying certain Engineering Fundamentals.
Engineering Fundamentals are essential principles and characteristics that contribute to high quality enterprise solutions. These include:
- An organized and well-defined backlog that captures the features the team will build
- Tooling for the team to manage the code base, and introduce mechanisms for code reviews
- Designing the solution and the engineering processes with Security from the beginning
- Quality rigor through the form of testability and code coverage
- Observability mechanisms that allow the team to analyze usage trends, troubleshoot issues, and identify opportunities for improvement
- A seamless developer experience that maximizes the productivity of the engineering team
- CICD (Continuous Integration and Continuous Delivery) to have a consistent process to take code contributions and seamlessly deploy the updated solution to an environment
This article is a part of a series of articles where we dive deep into one of these Engineering Fundamentals.
Each article will share the team’s journey, challenges, and learnings to apply each principle alongside the customer’s team.
Other articles in this series are:
In this article, we will cover Continuous Integration and Continuous Deployment (CICD).
Introduction
Continuous integration and delivery (CICD) free up developer time and energy by enabling automatic builds, tests, and deployments within a project. As such, when implemented, it is a critical part of any system. Teams without CICD are left to manually provision infrastructure and go through the application deployment process – which carries an elevated risk of human error.
Our latest project involved two distinct components in the codebase related to CICD:
- IaC: Vetting a new infrastructure as code (IaC) technology to create resources in Azure
- CICD: Deploying the applications that live on those resources
Through these 2 components, we were able to manage the provisioning of infrastructure separately from the application layer. Thereby optimizing the integration, testing, and delivery of both pieces. This was an ideal setup since part of the team focused on IaC and the other on the applications, allowing us to develop in parallel with minimal conflicts.
After working through spikes to identify our preferred course of action, we chose Azure DevOps to accomplish both tasks. The goal of this article is to detail our journey with CICD.
With respect to the key pieces mentioned above, we ended up with two pipelines:
The IaC pipeline used the Cloud Adoption Framework (CAF) which is used with Terraform. This enabled us to check in a set of Terraform variable files, referred to as the CAF configuration, alongside a Docker container, Rover, to deploy resources to Azure.
The CICD pipeline was responsible for building, testing, and deploying the application on top of the Azure infrastructure.
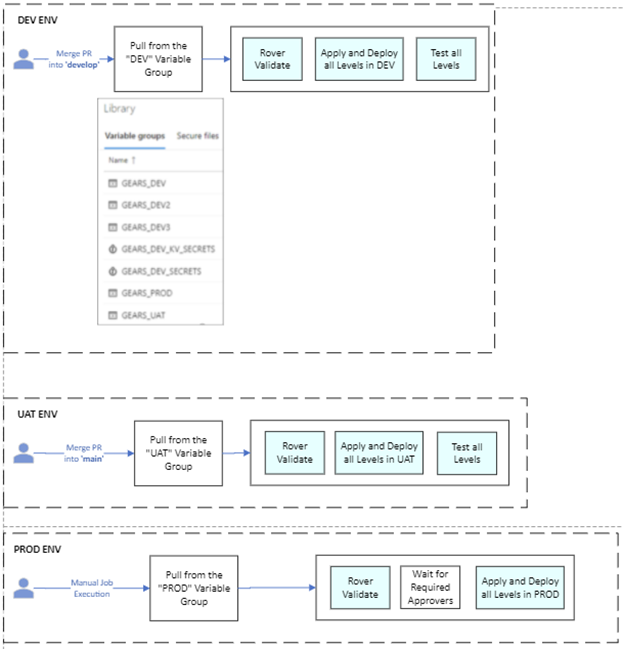
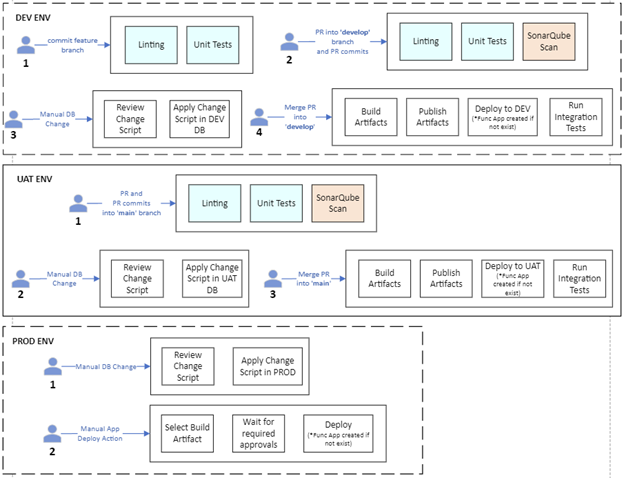
Below is a high level visual of both flows:
IaC Flow
CICD Flow
Considerations
The team initially used GitHub Actions to implement CICD and Terraform for IaC. However, shortly after starting, we pivoted to Azure DevOps as it aligned better with the team’s skillset and had built-in tasks for authenticating and communicating with an Azure subscription.
We also pivoted from using Terraform to CAF (which uses Terraform underneath) as we felt that leveraging the groundbreaking technology fit well with our project. Additionally, most of the key Azure resources needed were supported by CAF and we felt we had the skills and time to contribute back our learnings along the way.
Key Terms
The use of Azure Pipelines in Azure DevOps enabled several built-in opportunities:
- Service Connection – A built-in tool for managing connections to services including Azure. In our case, we used an Azure Service Principal in one and a Managed Identity in another Service Connection.
- Variable Groups – A collection of variables and secrets that can easily be integrated into a pipeline.
- Predefined Variables – Built-in variables regarding the system of the pipeline.
- Pipeline Triggers – An event that automatically starts a pipeline.
- Build Policies – A set of restrictions on when a Pull Request can be merged into the destination branch.
Overall Flow
Both pipelines followed similar patterns regarding setup.
A trigger sets off the pipeline, typically a PR being merged to the ‘develop’ branch, followed by the pipeline pulling all variables from the Variable Groups and setting local variables, followed by pulling any Resources (typically other repositories), then running all the Stages.
Azure Government Cloud
For the pipelines to work with an Azure Government Cloud subscription, rather than an Azure Commercial subscription, a couple of modifications were made.
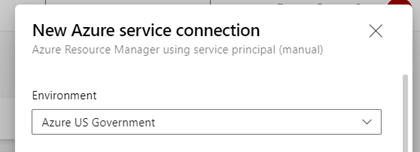
- The Service Connection was created manually using the Environment “Azure US Government”
- The environment variables below were added to bash script tasks
- ARM_ENVIRONMENT: usgovernment
- AZURE_ENVIRONMENT: AzureUSGovernmentCloud
Environments
The two pipelines can deploy resources to multiple environments.
- DEV: deployed from ‘develop’ branch
- UAT: deployed from ‘main’ branch
Future environments can be added based on the customer’s release process. Our approach was that deploying to production would be done manually and involve promoting a version of the application that has been validated to be healthy in UAT.
Common Triggers
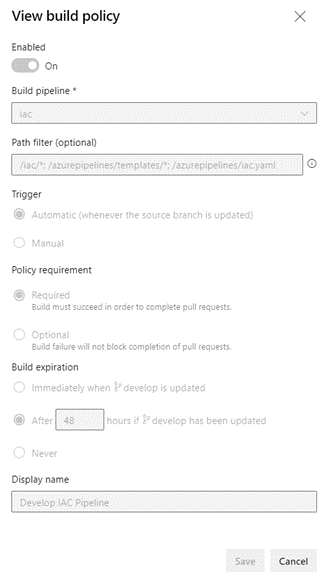
Both pipelines were found best to run after a PR merge and only for merging into the ‘develop’ or ‘main’ branches. That was configured in the Build Policy for those two branches.
This image shows the Build Policy for the IaC pipeline.
We also identified the need for built-in variable batch to be set to true in each trigger so that only one run of each pipeline could occur at a time. This prevented conflicts with the leasing of the Terraform state files and helped maintain a stable environment in Azure: batch: true
Common Variables
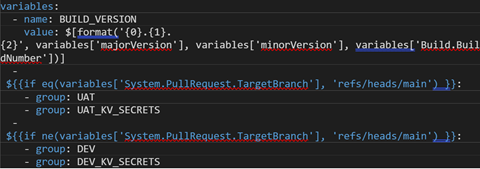
Both pipelines used the same Variable Groups, ‘DEV’ and ‘UAT’. This made it convenient to manage all variables in one place. This also enabled the sharing of those variables across pipelines. The groups were pulled based on what the target branch was. If it was ‘main’, the ‘UAT’ variable group would be used, if it was ‘develop’, the ‘DEV’ variable group would be used.
Common Conditions
In each of the stages across both pipelines, a common check was implemented to verify the target branch was ‘main’ or ‘develop’. This way we did not deploy individual branches and maintained a stable environment in Azure.
The IaC Pipeline
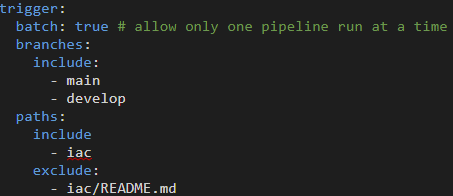
Triggers
The “paths” settings shown ensured the pipeline only ran with changes inside the IaC folder, excluding the README.
Variables
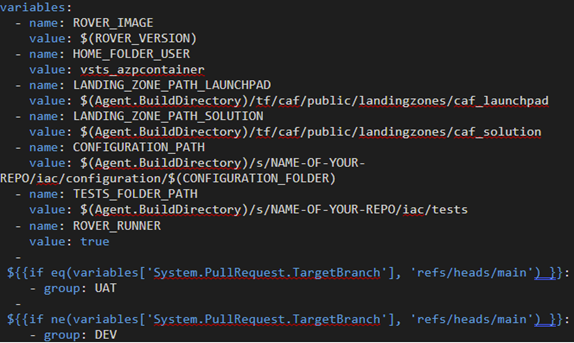
A handful of variables were set directly in the pipeline itself and a few came from one of the common Variable Groups. The variables not in the Variable Group are meant to change infrequently, if at all. They are mostly there for the Docker container to have the correct path information since this pipeline runs on a Microsoft-hosted agent that is managed for us. We also experimented with running the pipeline with a self-hosted agent so that those path variables were especially useful.
Some of the variables such as Agent.BuildDirectory and System.PullRequest.TargetBranch are predefined variables. The CONFIGURATION_PATH variable uses the pattern “Agent.BuildDirectory/s/Name-of-the-Repo/path” to the IaC configuration folder. The ‘s’ in the path is a bit odd but has to do with the fact that later in the pipeline, we checkout the repository containing our codebase with the command checkout: self which is automatically placed into a directory ‘s’.
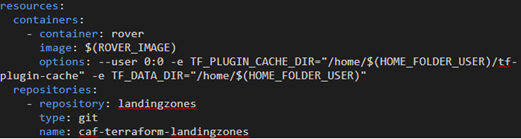
Resources
The IaC pipeline then pulled the necessary resources, using a built-in tool to pull from a variety of sources into the pipeline run. It required one Docker container, Rover, and the repository that contains the Landingzones for CAF. These are downloaded and made available for the rest of the pipeline to use.
The pipeline is then ready to work through the various Stages.
Stages
After implementing the Build Policy to only allow the pipeline to run after a PR merge to ‘develop’ or ‘main’, only one stage was needed for this pipeline.
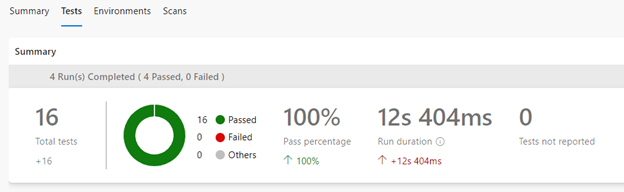
The following image shows the summary of a run in which the one stage “Apply All Levels” ran successfully showing the Sources that were pulled in, the repo with the codebase itself and the referenced repo for landingzones.
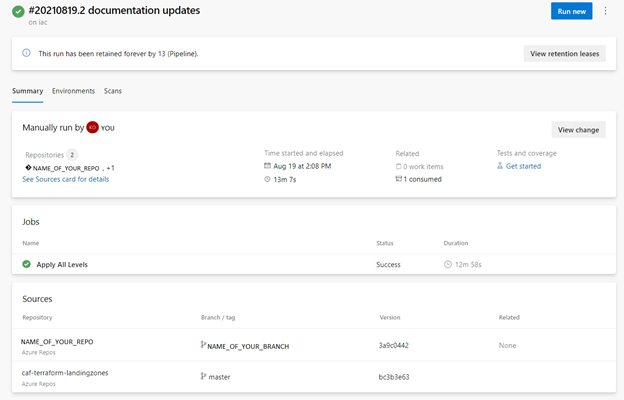
“Apply All Levels” Stage
Drilling into the “Apply All Levels” stage shows the steps that were taken during the run, which involved initializing the Rover container, checking out the repositories, running the deploy and test scripts, and finally cleaning up.
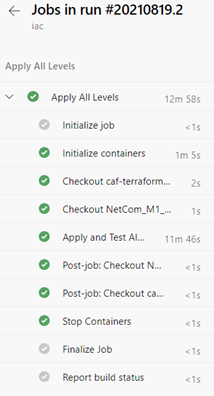
We can drill down into each of those steps as well and see the output.
The pipeline then uses a Deployment job which made it quite easy to pull the needed Rover container and set a strategy to run this job once. What ran was a series of Azure CLI (command-line interfaces) tasks that used the Service Connection to Azure Government Cloud to deploy and test the IaC.
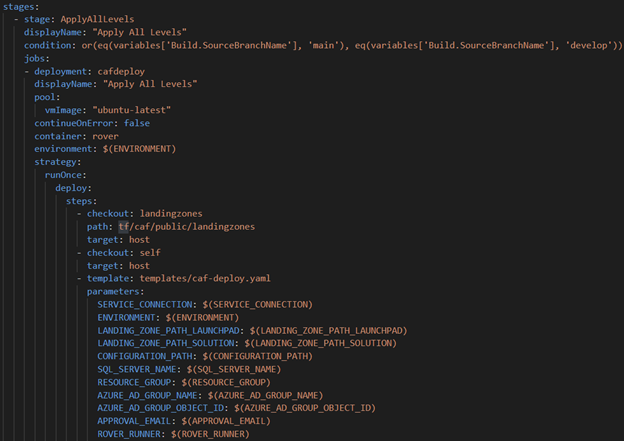
Azure Pipelines Template
Initially, we implemented an Azure Pipelines Template to enable the reuse of the Rover scripts or tasks. This is highlighted below and is part of the Deployment Job pictured above. Note how the Deployment job passes parameters to the Template pipeline. These can be customized based on your needs.
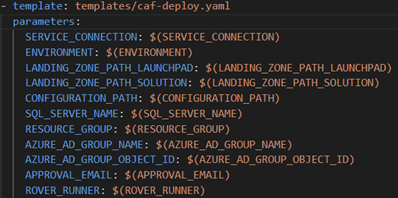
In our case, we had to specify that CAF target the Azure US Government sovereign cloud. Below are 2 images of the template’s structure and how we specified this condition.
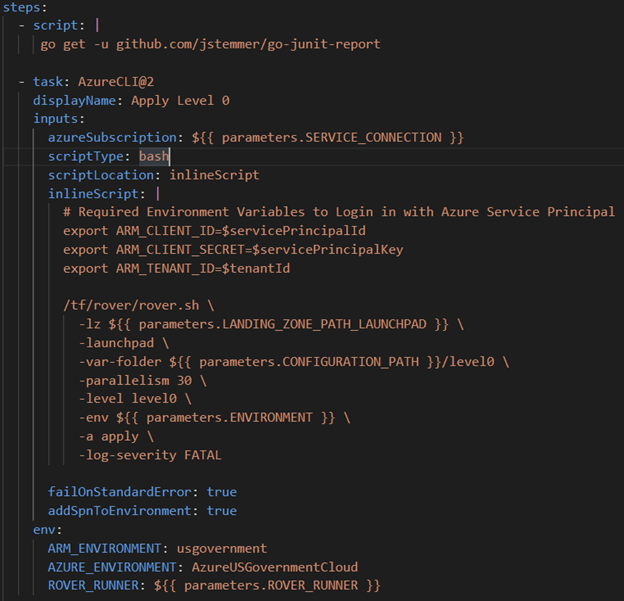
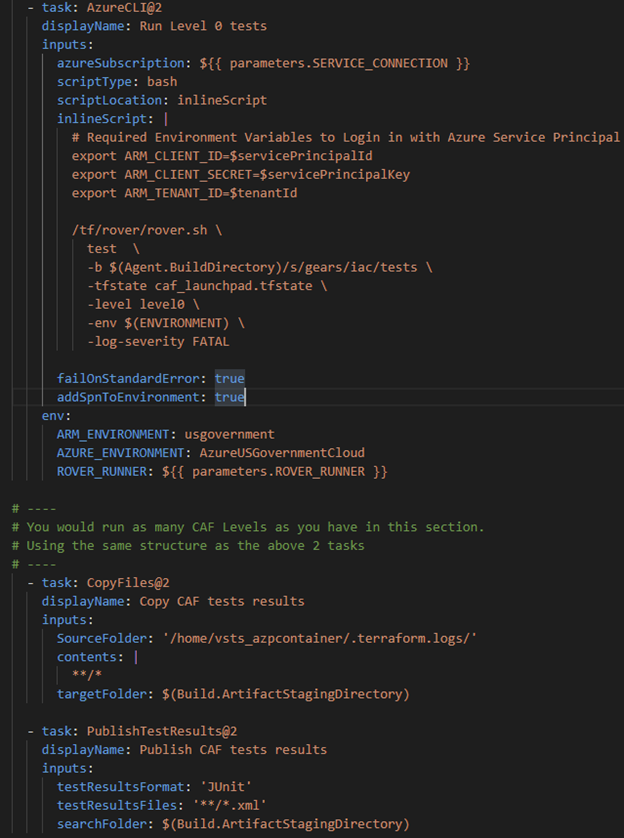
The last two tasks allow the tests to be viewable in Azure DevOps.
The LandingZones Repo
In the resources section, we reference another repository called landingzones. This is a requirement from the CAF technology and is simply a fork of the public landingzones GitHub repo that we placed in our Azure DevOps.
At one point, we were also pulling in another resource, a CAF repository fork for the public modules GitHub repo. This allowed us to make local changes to the forks and pull those into our pipeline easily. This is worthwhile to perform only if the team finds that the primary CAF repo is missing capabilities. Forking it and referencing a team’s own repo allows them to add these new capabilities, test them, and allow them to contribute the changes back to CAF.
SQL Server
Initially, our CAF configuration included a SQL Server and SQL Database. However, we encountered a conflict related to setting an Azure AD (Active Directory) Admin on the DB server. Limitations with the CAF configuration prevented us from easily and securely setting an Azure AD Admin within our IaC without hard-coding potential secrets.
We developed a workaround with an Azure CLI command in the pipeline to add the Azure AD Admin. After running the pipeline like this, we discovered that future deployments would error out if there was an AD Admin set because the CAF configuration did not expect one. This led us to adding a temporary task to remove the Azure AD Admin prior to deploying the SQL Server and adding it back afterwards.
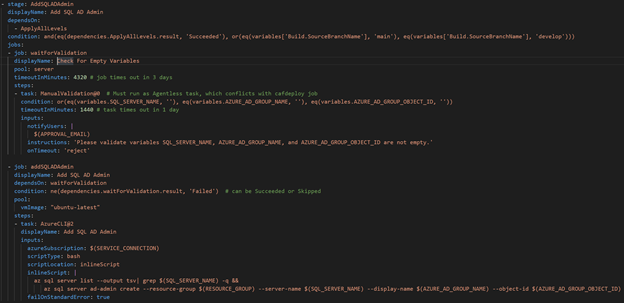
We achieved that by implementing a check on the variables related to the SQL Server and Azure AD Group. If the values were there, that meant the SQL Server existed and we could continue automatically with the pipeline to add the AD Admin. If the variables were empty, we could notify an admin to add those variables and wait to resume the pipeline until the admin gave the okay.
The 2 snippets below shows the tasks to:
- Remove the SQL AD Admin temporarily, which was placed before deploying the CAF Configuration containing the SQL Server
- Check that the SQL Server related variables are in the Variable Group, meaning the SQL Server exists. If not, send an email notification and wait until they signal to continue the pipeline (and hopefully after they update the Variable Group)
- Add the Azure AD Admin to the SQL Server
This was a fun set of workarounds, but ideally the CAF configuration would be updated in the future to make setting an Azure AD Admin on a SQL Server a bit easier.

The CICD Pipeline
Triggers
Along with the Common Triggers, this pipeline watched all branches and files which was useful for linting all files.

Variables
The variables set in the pipeline pertained to versioning. This was useful when publishing the artifacts after building the projects and easily locating them later.
KeyVault Linked Variable Group
We decided to place a handful of secrets in a Key Vault and have the built-in feature to link them in a Variable Group. This was a convenient method since we could have our CAF configuration place secrets, such as the Application Insights Connection String required for our Function App (not deployed with CAF), in the Key Vault to reduce passing secrets around.
Stages
The image here shows a successful run of the CICD pipeline and the flow of the stages. Note that the Deploy Web App and Deploy Function App stages could efficiently run in parallel.
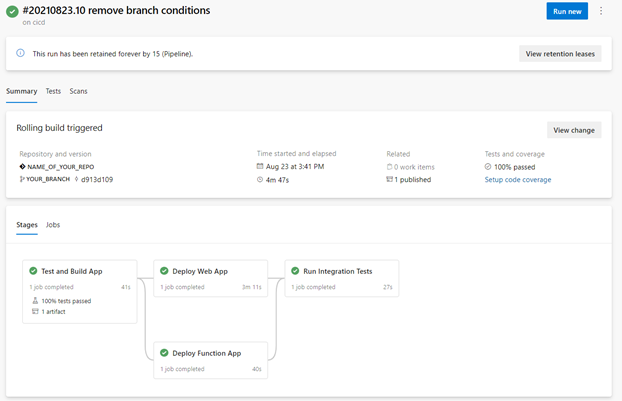
Conditions
In each stage, an additional condition was set to check if a variable DEPLOYABLE was set to ‘true’. This was helpful for times where we did not want to deploy, such as when the infrastructure was not ready in Azure early in the project.
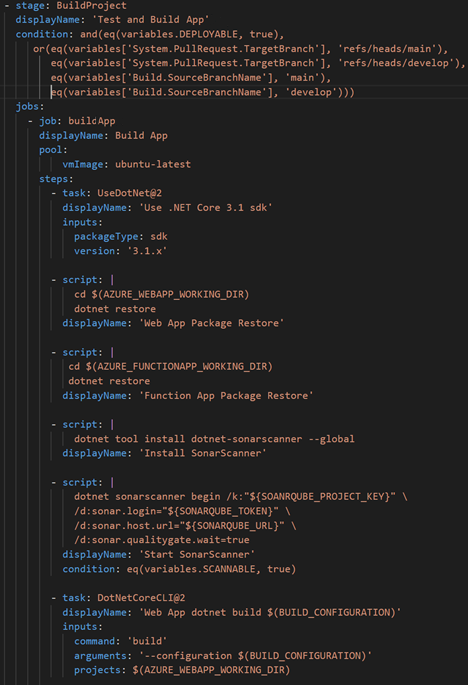
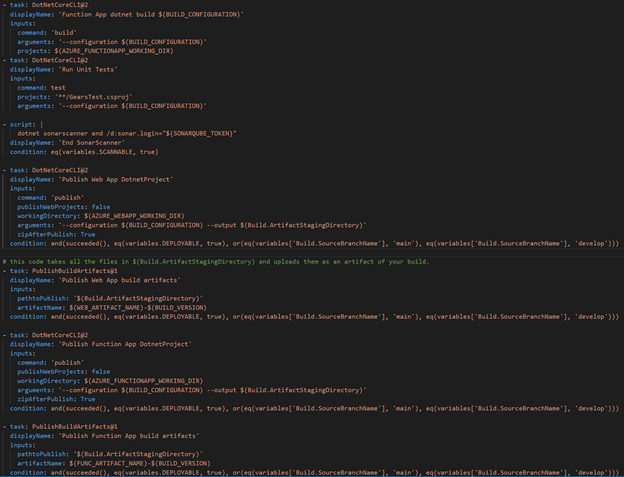
Build, Test, Publish Stage
The first stage in the CICD pipeline included all scripts and tasks needed for building the applications, linting, running SonarQube scanner, running unit tests, and publishing the built projects in an artifact accessible to other parts of the pipeline.
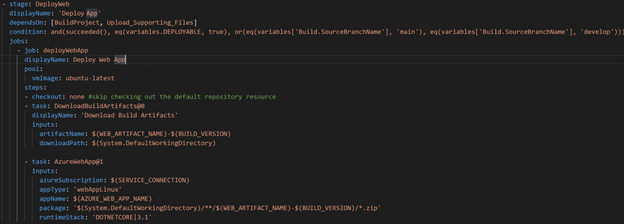
Deploy Web Stage
After checking that the previous stage was successful and all other conditions passed, DeployWeb stage then used the built-in tasks to grab the build artifact from the previous stage and deploy to the Azure Web App
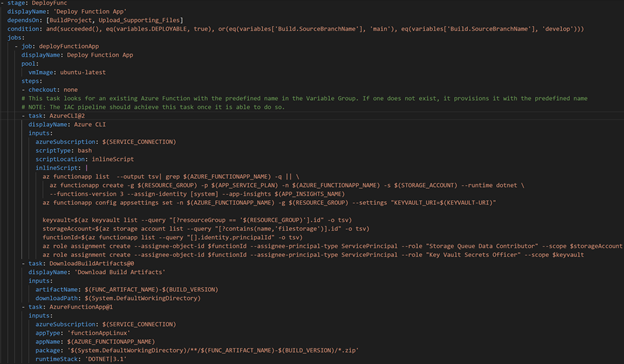
Deploy Function App Stage
The DeployFunc stage varies from the DeployWeb stage in that it has an extra task to create an Azure Function App. It uses some variables from the Key Vault linked Variable Group to deploy to App Settings and sets appropriate Role Assignments so other Azure resources could authenticate to the Function App. This was a workaround, as creating a Function App was not available with CAF at the time. The variable KEYVAULT-URI was the Uniform Resource Identifier (URI) to the Key Vault which was read from the Key Vault itself. This was certainly a quick and easy implementation to have that variable available. However, it is not a long-term solution as updating the CAF technology to support Azure Function Apps is the true goal.
It then used the built-in tasks to grab the build artifact from the previous stage and deploy to the Azure Function App.
Run Integration Tests Stage
The final stage of this pipeline was to run the Integration tests after checking conditions using bash script tasks.
We were finding that the integration tests were failing because the Web App didn’t have enough time to restart after the deployment and become publicly available. Therefore, we implemented a script using the curl command to check and wait until the Web App reported that it was up and running.
The script at the end of the stage looks for the WEB-APP-HOSTNAME variable in the Key Vault linked Variable Group and runs `dotnet test` pointing at the Web App.

SonarQube
We used Sonar Scanner when the variable ‘SCANNABLE’ was set to true to “detect bugs, vulnerabilities, and code smells.” If a team doesn’t have a SonarQube instance provisioned yet, the variable set to false wouldn’t prevent the team from development. Once their instance is provisioned, they can simply toggle this to true and update the Variable Group variables.
Summary
Instrumenting automation for both the provisioning of the system’s infrastructure, as well as the application deployment process, will accomplish having a consistent deployment process. In doing so, the business impact will result in minimizing the probability of human error and reducing the time to deploy the solution in a net-new environment.
Although each team may have their own application deployment process, this article demonstrated how to use Terraform and Azure DevOps Pipelines as the building blocks to develop the appropriate CICD flow for customers.
Team Members
The CSE US Government team below was instrumental in delivering the impact throughout the engagement, and in sharing our journey through the form of this article.
- Kristin Ottofy *Primary author of this article
- Adrian Gonzalez
- David Lambright
- Gavin Bauman
- James Truitt
- Jordon Malcolm