
Background
For the tech companies designing tomorrow’s smart cities, making local authorities able to collect and analyze large quantities of data from many different sources and mediums is critical. Data can come from different sources – from posts on social media and data automatically collected from IoT devices, to information submitted by citizens on a range of different channels.
To consolidate a continuous stream from this myriad of sources, these companies need an infrastructure that is strong enough to support the load. But, they also require a flexible infrastructure that offers the right tools, has the ability to automatically scale up or down, and which offers an environment that is dynamic enough to support quick changes to model processing and data scoring.
One such company, ZenCity, is dedicated to making cities smarter by processing social, IoT and LOB data to identify and aggregate exceptional trends. In June 2018, ZenCity approached CSE to partner in building a pipeline that could analyze a varying array of data sources, scale according to need, and potentially scale separately for specific customers. At the outset of our collaboration with ZenCity, our team evaluated ZenCity’s existing infrastructure, which consisted of manually managed VMs that were proving difficult to maintain and support given the startup’s rapidly growing customer base. It was very important to understand ZenCity’s needs and to try and predict how those needs would evolve in the near future as the company grows.
Our primary role in the collaboration was to investigate Azure Databricks and other streaming alternatives that might meet their requirements and to recommend the best approach from a technical standpoint. However, we also aimed to integrate the systems with other Azure services and online OSS libraries that could support the sort of pipeline ZenCity needed.
As the project progressed, our team discovered that there are very few online open source examples that demonstrate building a CI/CD pipeline for a Spark-based solution. And, to the best of our knowledge, none of the examples demonstrated a Databricks-based solution that can utilize its rich features. As a result, we decided to provide a CI/CD sample and address the challenges of continuous integration and continuous deployment for a Databricks-based solution.
This code story describes the challenges, solutions and technical details of the approach we decided to take.
Challenges
In searching out the most suitable solution for ZenCity, we faced the following challenges:
- Finding an Event Stream Processing solution that was capable of near real-time processing of events coming in from social networks, LOB (line of business) systems, IoT devices, etc.
- Building a solution that scales and could support a growing market of customers
- Constructing a CI/CD pipeline around the solution that supports several environments (e.g., development, staging and production)
Solution
For simplicity, the architecture diagram below describes a single workload, chosen as an example from several somewhat similar ones that we focused on. This diagram depicts the processing of tweets from a Twitter feed and analyzing them.
Architecture
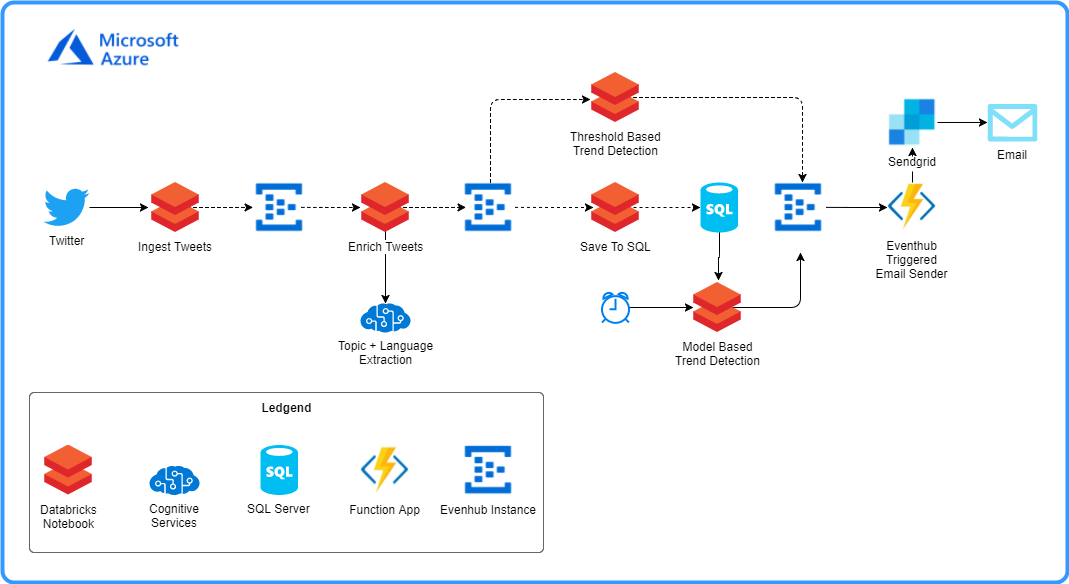
The above architecture uses Databricks notebooks (written in scala) and Event Hubs to distinguish between computational blocks and enable scalability in a smart way.
The pipeline works as a stream that flows in the following manner:
- Ingest tweets and push them into the pipeline for processing
- Each tweet is enriched with Language and an associated Topic
- From here the stream diverges into 3 parallel parts:
- Each enriched tweet is saved in a table on an Azure-based SQL Database
- A model meant to run on an active window frame and scan the last 10 minutes for topic anomalies
- Once a day, the entire batch of tweets is processed for topic anomalies
- Each time an anomaly is detected, it is passed to a function app that sends an email describing the anomaly
Databricks
Databricks is a management layer on top of Spark that exposes a rich UI with a scaling mechanism (including REST API and cli tool) and a simplified development process. We chose Databricks specifically because it enables us to:
- Create clusters that automatically scale up and down
- Schedule jobs to run periodically
- Co-edit notebooks (*)
- Run Scala notebooks interactively and see results interactively
- Integrate with GitHub
The option to create clusters on demand can also potentially enable a separate execution environment for a specific customer that scales according to their individual need.
* The idea of notebooks used in Databricks, is borrowed from Jupyter Notebooks and meant to provide an easy interface to manipulate queries and interact with data during development.
Databricks Deployment Scripts
In order to create a maintainable solution that supports CI/CD and manual deployment with ease, it was necessary to have a suite of scripts that could support granular actions like “deploy resources to azure” or “upload environment secrets to Databricks.” While almost all of the actions are achievable using azure-cli, Databricks-cli, or other libraries needed to deploy, build and test such a solution, it is essential to be able to call on those actions quickly when developing the solution and wanting to check changes. More importantly, it is critical for supporting a CI/CD pipeline that doesn’t require any manual interaction.
To aggregate all scripts/actions into a manageable and coherent collection of commands, we built upon Lace Lofranco’s work and used make which can be run locally from a Linux terminal or on Travis.
Using make, the entire solution can be deployed by running make deploy , while providing (according to prompt) the appropriate parameters for the resource group name, region and subscription id.
The Makefile deployment script, runs a collection of script that uses azure-cli, databricks-cli and Python scripts.
Getting Started
Using our sample project on GitHub, you can run deployment on Azure from your local environment and follow the prompt for any details.
Running the make deploy command can also be done with all parameters, but would still require a prompt for a token from Databricks by using the command:
make deploy resource-group-name=sample-social-rg region=westeurope subscription-id=5b86ec85-0709-4021-b73c-7a089d413ff0
To set up a test environment, follow the Integration Tests section on the README file.
Deploying the ARM template
The ARM template enabled us to deploy all the resources in the solution in a single resource group, while associating the keys and secrets between them. Using ARM deployment, all resources, except for Databricks, could also be configured, and the various secrets and keys could be configured quickly.
We also used the ARM output feature to export all keys and secrets into a separate .env file which could later be used to configure Databricks.
deploy/deploy.sh [Shell]
# Deploying an ARM template with all resources to Azure
arm_output=$(az group deployment create \
--name "$deploy_name" \
--resource-group "$rg_name" \
--template-file "./azuredeploy.json" \
--parameters @"./azuredeploy.parameters.json" \
--output json)
# Extracting deployment output parameters
storage_account_key=$(az storage account keys list \
--account-name $storage_account \
--resource-group $rg_name \
--output json |
jq -r '.[0].value')
# Dumping the secrets into a local .env file
echo "BLOB_STORAGE_KEY=${storage_account_key}" >> $env_file
Configuring Databricks Remotely
To configure Databricks, we used databricks-cli, which is a command line interface tool designed to provide easy remote access to Databricks and most of the API it offers.
The first script uploads all the relevant secrets into the Databricks environment, making them available to all clusters that will be created in it. The second script configures the libraries, clusters, and jobs that are required to run as part of the pipeline.
deploy/databricks/create_secrets.py [Python]
# Using Databricks REST API to create a secret for every environment variable in the .env file
api_url = "https://" + dbi_domain + "/api/2.0/"
scope = "storage_scope"
r = requests.post(api_url + 'preview/secret/secrets/write',
headers={"Authorization": "Bearer " + token},
json={"scope": scope, "key": secret_name, "string_value": secret_value
})
response_body = r.json()
if r.status_code != 200:
raise Exception('Error creating scope: ' + json.dumps(response_body))
return (response_body)
deploy/databricks/configure.sh [Shell]
# Configure databricks cli profile to use the user generated token
> ~/.databrickscfg
echo "[DEFAULT]" >> ~/.databrickscfg
echo "host = $DATABRICKS_URL" >> ~/.databrickscfg
echo "token = $DATABRICKS_ACCESS_TOKEN" >> ~/.databrickscfg
echo "" >> ~/.databrickscfg
# Create + Start a cluster to use for library deployments
databricks clusters create --json-file "./config/cluster.config.json"
databricks clusters start --cluster-id $cluster_id
# installing libraries on Databricks
databricks libraries install --maven-coordinates com.microsoft.azure:azure-eventhubs-spark_2.11:2.3.1 --cluster-id $cluster_id
databricks libraries install --maven-coordinates org.apache.bahir:spark-streaming-twitter_2.11:2.2.0 --cluster-id $cluster_id
databricks libraries install --maven-coordinates org.json4s:json4s-native_2.11:3.5.4 --cluster-id $cluster_id
# Uploading build artifacts from Java project (containing twitter wrapper and test validator)
blob_file_name="social-source-wrapper-1.0-SNAPSHOT.jar"
blob_local_path="src/social-source-wrapper/target/$blob_file_name"
blob_dbfs_path="dbfs:/mnt/jars/$blob_file_name"
databricks fs cp --overwrite "$blob_local_path" "$blob_dbfs_path"
databricks libraries install --cluster-id $cluster_id --jar "$blob_dbfs_path"
# Uploading notebooks to Databricks
databricks workspace import_dir "../../notebooks" "/notebooks" --overwrite
# Executing the jobs according to configuration paths
for filePath in $(ls -v $PWD/config/run.*.config.json); do
declare jobjson=$(cat "$filePath")
databricks runs submit --json "$jobjson"
done
To make sure the notebooks run with test configuration, it is important to execute the notebooks with a declared parameter, setting the social source to “Custom”:
jobjson=$(echo "$jobjson" | \
jq '.notebook_task.base_parameters |= \
{ "socialSource": "CUSTOM" }')
This line adds a parameter to the job execution of each notebook. The notebooks which are affected by this parameter will change their functionality to run with mock data.
Cleanup
When running on a test environment, it was necessary to remove the excess resources once the test had completed its execution. In a full scenario, we’d be able to completely delete the ARM resource group and re-create it in the next execution. But, because there’s currently no API for creating a token for Databricks, it was necessary to generate the token manually. This meant we were not able to delete the resources between executions and it was important to keep the Databricks resource (although not its clusters) alive between test runs. Because this was the case, we needed to make sure all jobs we initiated were terminated so that they didn’t continue to consume resources – the cleanup script would only be run in a test deployment, after a successful / failed test run.
deploy/databricks/cleanup.sh [Shell]
# Stopping all active jobs deployed in the databricks deployment
for filePath in $(ls -v $PWD/config/run.*.config.json); do
for jn in "$(cat "$filePath" | jq -r ".run_name")"; do
declare runids=$(databricks runs list --active-only --output JSON | \
jq -c ".runs // []" | \
jq -c "[.[] | \
select(.run_name == \"$jn\")]" | \
jq .[].run_id)
for id in $runids; do
databricks runs cancel --run-id $id
done
done
done
Java Packages and Build
The build stage is used to build the Java packages that are uploaded and used in the job execution on Databricks.
The following test is run by Travis-CI to connect to Azure Event Hubs and listen on the last event hub in the pipeline, the event hub receiving the alerts. If a new alert is identified, it will exit the test process successfully. Otherwise, it will fail the test.
src/integration-tests/src/main/java/com/microsoft/azure/eventhubs/checkstatus/ReceiveByDateTime.java [Java]
package com.microsoft.azure.eventhubs.checkstatus;
// Creating an Even Hub events receiver
final EventHubClient ehClient =
EventHubClient.createSync(connStr.toString(), executorService);
final PartitionReceiver receiver = ehClient.createEpochReceiverSync(
EventHubClient.DEFAULT_CONSUMER_GROUP_NAME, partitionId,
EventPosition.fromEnqueuedTime(Instant.EPOCH), 2345);
final LocalDateTime checkupStartTime = LocalDateTime.now();
// Making sure 15 minutes haven't passed since the test started
while (LocalDateTime.now().minusMinutes(15).isBefore(checkupStartTime)) {
receiver.receive(100).thenAcceptAsync(receivedEvents -> {
// After parsing each event, check event time is after start of execution
if (eventDateTime.isAfter(startTime)) {
System.out.println("Found a processed alert: " + dataString);
System.exit(0);
}
}, executorService).get();
}
// If no event was found for 15 minutes, fail the process
System.exit(1);
Databricks Continuous Integration Using Travis
Travis-CI is a great tool for continuous integration, listening to GitHub changes, and running the appropriate deployment scripts.
In this project, we used Travis to listen to any change in the master branch and execute a test deployment. This configuration can also be changed to run once a day if you think that every change should cause a build.
All the configuration of Azure and Databricks can currently be done remotely and automatically via the scripts described in this article, except for one task – creating an authentication token in Databricks. This task requires manual interaction with the Databricks API.
For that reason, to run tests in a test environment, it was necessary to first deploy a test environment, and use the output from the deployment to configure Travis repository settings with those parameters. To see how to do that, continue reading here.
Integration Testing
Together with ZenCity, we discussed adding Unit Testing to the Databricks pipeline notebooks, but we found that running unit tests on a stream-based pipeline was not something we wanted to invest in at that moment. For more information on Unit Testing Spark-based stream, see here.
Integration testing on the other hand seemed like something that would help us figure out the maturity of the code being checked end to end, but also seemed quite a challenge. The idea behind the integration testing was to spin up an entire test environment, let the tests run with mock data, and “watch” the end of the pipeline while waiting for specific results.
Mocking Cognitive Services
We used Text Analytics in Cognitive Services to get a quick analysis of the language and topics on each tweet. Although this solution worked great, the throttling limits on Cognitive Services (which are present on all SKU levels with varying limits) could not support a pipeline with the scale we were hoping to support. Therefore, we used those services as an implementation example only, while in the customer deployment, we used scalable propriety models developed by the customer.
For that reason, in the published sample, we chose to mock those requests using a Function App with constant REST responses – in a real-life scenario this should be replaced with Cognitive Services (in case of a small scale stream), an external REST API, or a model that can be run by Spark.
Twitter API
In this sample, the production version uses Twitter API to read tweets on a certain hashtag/topic and ingests them into the data pipeline. This API was encapsulated to enable mocking using predefined data in a test environment. Both the Twitter and the mock implementations use the following interface:
src/social-source-wrapper/src/main/java/social/pipeline/source/SocialQuery.java [Java]
// Defining the interface to query a social service
public interface SocialSource {
SocialQueryResult search(SocialQuery query) throws Exception;
void setOAuthConsumer(String key, String secret);
void setOAuthAccessToken(String accessToken, String tokenSecret);
}
Conclusion
We started out looking to help ZenCity solve a challenge around building a cloud-based data pipeline, but found that the real challenge was finding and creating a CI/CD pipeline that can support that kind of solution.
Along the way we worked on generalizing the solution in a way that would allow it to be configured and enhanced to work for any CI/CD pipeline around a Databricks-based pipeline. The generalization process made our solution flexible and adaptable for other similar projects.
Additionally, the approach we took with the pipeline – which includes integration testing on the entire pipeline in a full test environment – can also be integrated into other projects with include a data pipeline.
There are two requirements needed to adopt this approach: first, a streaming pipeline, with which it’s hard to test each component or the SDK does not expose an easily testable API; and second, a data pipeline that enables controlling the input to the pipeline and monitoring the output.
The scripts in this solution can be changed to support the deployment and configuration of any remotely controlled streaming infrastructure.
Resources
- Link to GitHub repo: https://github.com/Azure-Samples/twitter-databricks-topic-extractor
- This solution was built on top of the great work done by Lace Lofranco in azure-databricks-recommendation.
- Databricks on Azure