

We shipped a lot at Build 2026: hosted agents, Toolboxes, Foundry IQ, Memory, Managed Compute, fine‑tuning, Frontier Tuning, and a new evaluation and optimization stack. Read as a feature list, it is a lot to hold in your head. So here is a simpler way to see it: these are the parts you need to build a learning system, with agents that get measurably better at your work over time, not a chatbot that answers once and forgets. This post is about assembling those parts into one loop you own, and the science that makes a small, owned model worth training.
It builds on two pieces worth reading first. Jay Parikh’s “AI alone won’t change your business, the system running it will” argues that the winners do not just adopt a model; they stand up a governed system that improves the longer it runs. Satya’s framing in “a frontier ecosystem, not just a frontier model” sharpens it: the durable asset is not the model you rent, it is the learning loop you own. Same idea from two angles. Build a system that improves against your outcomes, and make sure you own it.
Foundry makes that loop something you can build in an open, interoperable, and modular way, so you can swap any piece (the model, the trainer, the tools) without rebuilding the whole thing. Two ingredients sit under every such system: a place for the agent to practice (an environment) and a way to judge it (an eval). To keep both open, Microsoft joined the OpenEnv community.

However you come to this, whether PM, IT admin, developer, or AI engineer, the first half is the plain-language what and why. The second half is the deep science. Skim or dive as suits you.
Environments, evals, and rubrics, in plain language
An environment (an RLE, or reinforcement-learning environment) is a practice space for your agent (harness + model). It is your real workflow and your standard operating procedure, codified so an agent can act inside it: the steps, the tools it is allowed to use, the data it sees. Think of it as a flight simulator for one of your business processes, close enough to the real thing that getting good in the simulator means getting good at the job.
An eval is how you judge a result, and the heart of an eval is a rubric: a clear, scored definition of “done right” for your outcome, not a public leaderboard. “Did it reconcile the invoice to the contract? Did it cite a real clause? Did it stay inside policy?” Foundry ships agent evaluation for writing exactly these judgments, and an optimizer (below) for acting on the scores.
Here is the move that ties it together: an environment already contains its eval. Codify your workflow plus your outcome rubric, and you have not just written a test, you have built a hill-climbing space. The agent practices, the rubric scores, and the system climbs toward your outcome. That is why RLEs are also evals: it is one artifact that both exercises the agent and grades it.
Codify your workflow and your outcome into an environment, and the model becomes a part you can swap. The expertise lives in the loop you own, so the learning stays yours.
A system learns in two ways
Before any science, the single most useful idea in this post: a system can get better in two different ways, and you should reach for them in order.
1. Non-parametric learning (the weights stay frozen)
The first kind leaves the model’s weights untouched and improves the harness around them: the system prompt, the skills (named, reusable procedures), the tool descriptions, and the context the agent retrieves through Foundry IQ and Memory, plus which model it runs on. No GPUs, no training run, results in minutes. Foundry ships this as the agent optimizer: it runs a closed loop (evaluate your agent against your criteria, generate better configurations, score them, deploy the winner) and will rewrite your instructions, synthesize skills, sharpen tool descriptions, or pick a better model for your quality and cost trade-off. In our example a bare support agent climbs from 0.60 to 0.92 on its rubric with no retraining and no code changes, just a smarter prompt, skills, and tools.
Microsoft Research is pushing harness optimization even further. SkillOpt treats the skill document itself as the trainable thing: it edits a single Markdown skill from scored rollouts and accepts an edit only when a held-out validation score strictly improves, the same discipline that makes weight training reproducible, but with zero weight changes and zero extra calls at inference time. The deployable artifact is a compact best_skill.md that runs against an unchanged model, and it lifts no-skill accuracy by more than 20 points on a frontier model across six benchmarks (paper). Start here. Non-parametric learning is cheap, fast, and often enough on its own.
2. Parametric learning (the weights change)
The second kind is for when you want the behavior in the model itself: faster and cheaper to serve, and fully owned (sovereign). You change the weights with post-training. This is where a small open model can quietly overtake a frontier API on your task, and where the deepest new science lives, because you can teach the model not just what to do but how its world responds. That technique is ECHO, and most of the rest of this post is about it. The point to carry forward: do the cheap non-parametric learning first, and turn to parametric learning when the outcome, and the economics, justify owning the model.
One agent, one sandbox, both kinds of learning
Both kinds of learning run against the same thing: a hosted agent (your model plus prompt plus tools and skills) executing in an isolated, project-owned sandbox. Foundry runs hosted agents on Azure Container Apps (ACA) sandboxes: each gets its own filesystem, session, and state, with default-deny networking so a tool call cannot quietly exfiltrate a secret. The agent optimizer drives that hosted agent through its evaluation loop inside exactly this sandbox.
And Microsoft’s contribution to OpenEnv (more in a moment) makes the very same ACA sandbox an OpenEnv environment, so the agent you optimize non-parametrically is the agent you post-train parametrically, in the same secure box. One agent, one sandbox, two ways to climb. The diagram at the top of this post shows the whole loop on a page.
Mapped to what shipped: Toolboxes give the agent one governed set of tools; ACA sandboxes give it an isolated place to run; Foundry IQ is the knowledge plane that grounds it; agent evaluation is the rubric; the agent optimizer and post-training are the two improve steps; Managed Compute serves the result. One open standard underneath keeps the parts from locking you in: OpenEnv.
We joined OpenEnv, with contributions for enterprise agentic learning loops
OpenEnv is a protocol for environments: a small, shared contract (reset, step, state, carried over MCP, packaged with Docker, with the promise that the training environment matches production). It is not a reward framework and not a trainer; it is the thin interoperable layer that lets any model, harness, trainer, and environment compose. That is the interoperable in open-and-interoperable, and it is why Microsoft joined the community alongside Meta’s PyTorch team, NVIDIA, Hugging Face, Unsloth, Prime Intellect, and others.
Two of those contributions are already merged into OpenEnv: a hosted Azure Container Apps sandbox provider, so an RLE can run rollouts in the isolated, project-owned Azure sandbox above, with default-deny egress that blocks token theft, the enterprise-grade isolation an RLE needs; and ECHO env-token world-modeling as RFC 010, which teaches trainers to learn from the environment’s own tokens. Private RLEs and private evals, kept open and interoperable on purpose with more to come.

Post-training, without the heavy lifting
Before the frontier technique, the basics, because owning the weights is far more approachable than it used to be. Fine-tuning a small model on your task and serving it once meant standing up GPU clusters and a training stack. Foundry’s managed post-training removes that: it exposes a Tinker-style training loop, the low-level primitives sample, forward_backward, and optim_step, running server-side on Foundry’s GPUs while you keep the data and the loop. You write the loop; the service owns the hardware. No client GPUs, no cluster to babysit. Two Build sessions walk it end to end: BRK231, Deploy. Observe. Learn and BRK232, Post-Training and Deploying Open-Source Reasoning Models in Foundry.
That same managed loop is where Microsoft is pushing the frontier: not just consuming the stack but advancing it and contributing the pieces back to OpenEnv (the ACA sandbox provider, and the world-modeling work in the next section), so the whole ecosystem benefits. The clearest example is next. It turns the wasted half of every rollout into a free training signal, and it lands as a one-line change on exactly this loop.
Pushing OpenEnv environments to the frontier
Joining OpenEnv is not a logo exercise. An open standard stays relevant only if it keeps absorbing the research frontier, so part of our work is diffusing that frontier into it. The clearest example is a contribution we landed as a pull request, ECHO world-modeling (RFC 010), which brings a Microsoft Research result (“Terminal Agents Learn World Models for Free”) into OpenEnv, where any team can pick it up. That is how a lab technique becomes a shared capability and the learning loop gets democratized.
Here is what it does. An agent transcript is half actions (what the model writes) and half observations (what the environment writes back). Standard agent-RL trains the actions and masks the observations away. ECHO keeps them: a small cross-entropy term that makes the policy predict the environment’s own tokens, a world model, from logits it already computed in the same forward pass. No extra rollouts, no teacher, no labels.
L = L_GRPO(action tokens) + λ · CrossEntropy(observation tokens)

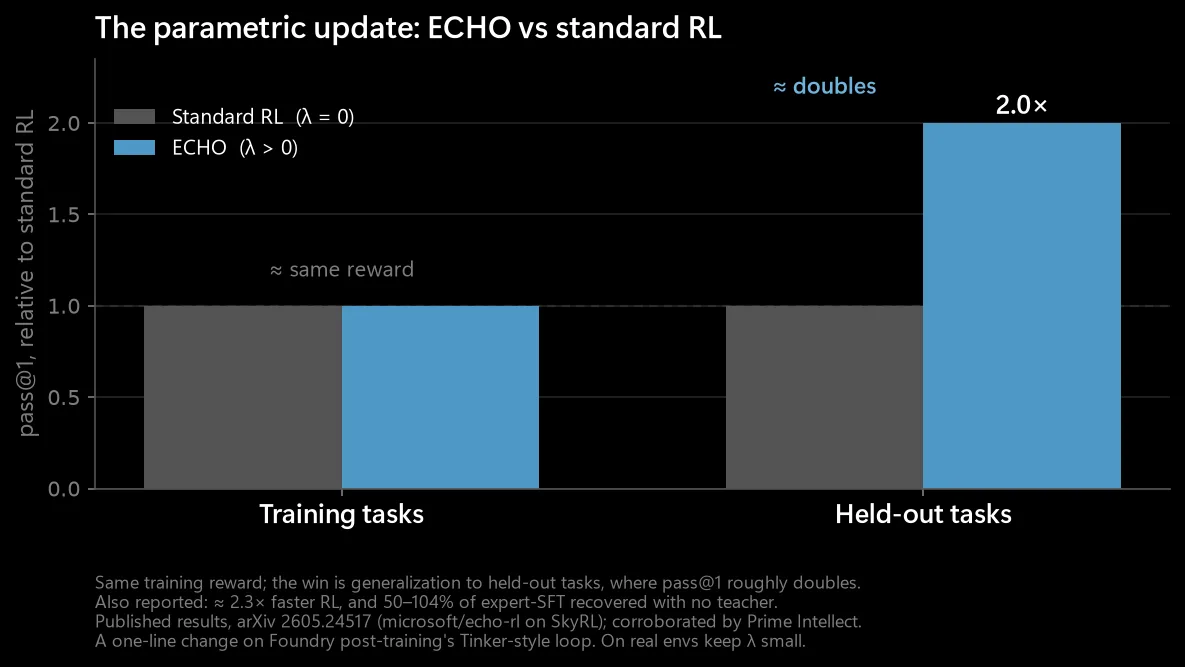
The free signal is large and real: on a captured agent episode, 4,659 of 5,247 learnable tokens (89%) are environment observations, 7.9× the action tokens, exactly the half standard agent-RL discards. Prime Intellect reaches the same conclusion in “True Agents Model the World”, restating supervised learning on tool-response tokens as RL with a constant positive advantage, foldable in at no extra cost. Two groups, one direction: world-modeling belongs inside the RL loop, not bolted on afterward.
On the honest ablation (λ on versus off), the training reward barely moves; the gain is generalization. ECHO’s published results: held-out pass@1 roughly doubles on TerminalBench-2.0, RL reaches its target about 2.3× faster, and it recovers 50 to 104% of expert-SFT with no teacher. Even verifier-free (reward off), held-out tasks improve. Keep λ small and sweep it; the dense signal overfits if pushed (one open model collapsed at 0.05 and was stable at 0.005).
You can watch the mechanism on a laptop in about 40 seconds: a small model on a deterministic toy terminal env drives held-out env-token cross-entropy toward zero. It reaches zero only because that world is fully predictable; a real environment keeps its irreducible entropy (near 4.4 nats), so ECHO sharpens predictions rather than perfecting them. Reproduce it: OpenEnv examples/echo_world_model, python train_echo.py --steps 60 --seed 0.
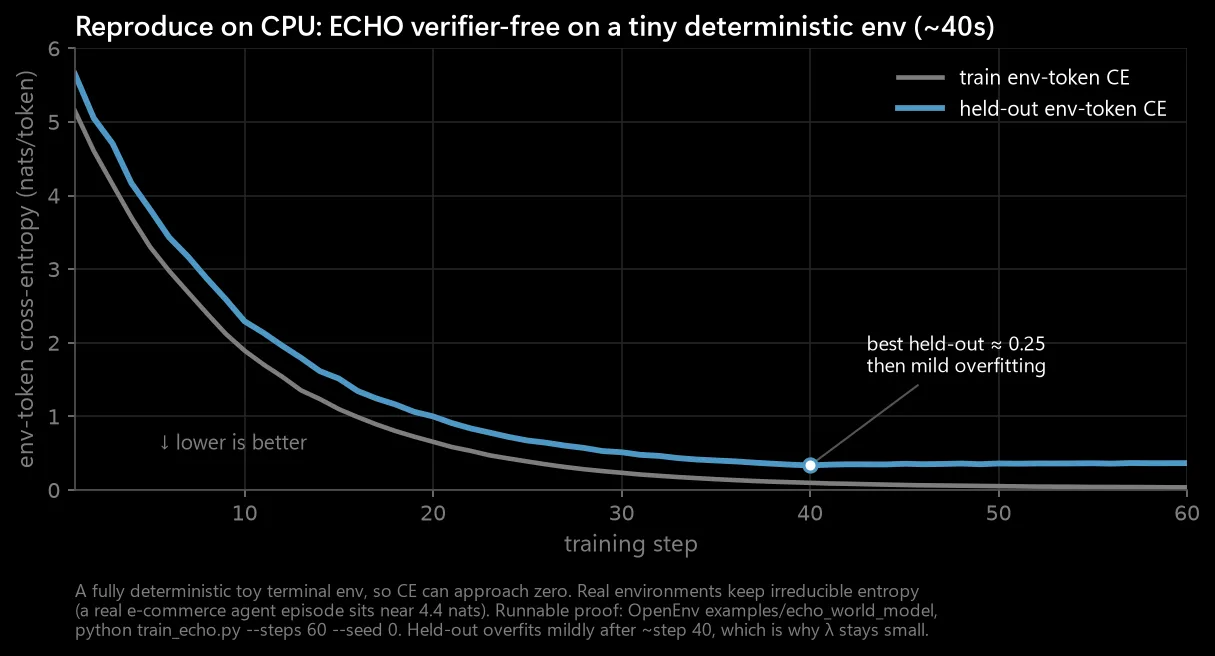
examples/echo_world_model, python train_echo.py --steps 60 --seed 0.And it holds on the managed path. Because supervised learning on the observation tokens is just RL with a constant positive advantage, there is no second loss function: you reuse the same forward_backward and add a small positive advantage λ on the environment tokens. One vector changes, and the same one-line config runs on the open SkyRL reference, Tinker, and Foundry post-training unchanged. We ran it live with a small Qwen model, and it also runs with MAI-Reasoning-1-Flash; the backend metrics came back namespaced skyrl.ai, the open reference stack running underneath the managed service.
The loop that improves itself: RSI
One last reason to own the environment, not just the model: the gym is where compounding begins. Once your workflow, tools, and rubric live in an OpenEnv RLE, the same trace data that post-trains the model can also improve the environment itself. The OpenEnv roadmap points squarely at this, a family of self-improving-gym designs: curricula that generate harder tasks as the agent gets better, harness optimizers, and new environments built automatically from captured production traces. That is recursive self-improvement (RSI) in action. The system writes its own next set of exercises, and each cycle sharpens the next. The learning does not only accrue in the weights; it accrues in the gym, which is the part you own.
Start building the loop that is yours
Pull it back up to the top. Codify your workflow and your outcome into an OpenEnv-compatible RLE, and you have a hill-climbing learning system that is genuinely yours: open, interoperable, and outcome-driven. Improve it the cheap way first (tune the prompt, skills, tools, and model choice with the agent optimizer and ideas from SkillOpt), then the deep way when the economics justify it (post-train the weights, with ECHO turning the discarded 89% of your trajectories into a free world model). The model in the middle is a part you can swap; the loop around it is the asset that compounds the longer it runs.
The managed on-ramp is Frontier Tuning: frontier-grade performance with superior token efficiency, improved through real usage in Foundry and Copilot, and secured inside your own environment. Early adopters including McKinsey, Bristol Myers Squibb, and Land O’Lakes are already building with it.
The fastest way in is a partnership. Ask your Microsoft Forward-Deployed Engineer (FDE) or your Microsoft account team to engage, and build the OpenEnv-compatible RLEs and outcome-driven learning systems where the model is swappable and the learning stays yours.
0 comments
Be the first to start the discussion.