

Background
Developers typically rely on regression testing done as a part of continuous integration or continuous delivery (CI/CD) pipelines to ensure that their recent changes do not introduce faults. Ideally, test failures during regression testing would reliably signal issues with the developers’ recent changes. Unfortunately, tests that pass and fail non-deterministically on the same code in the same environment prohibit this ideal. These tests are commonly known as flaky tests, and they negatively impact developers’ productivity by providing misleading signals about their recent changes. More specifically, developers may end up spending time investigating those failures, only to discover that the failures have nothing to do with their changes and may simply go away by rerunning the tests. Unfortunately, tests can be flaky due to several reasons, ranging from simple timing issues to complex dependencies on the external environments.
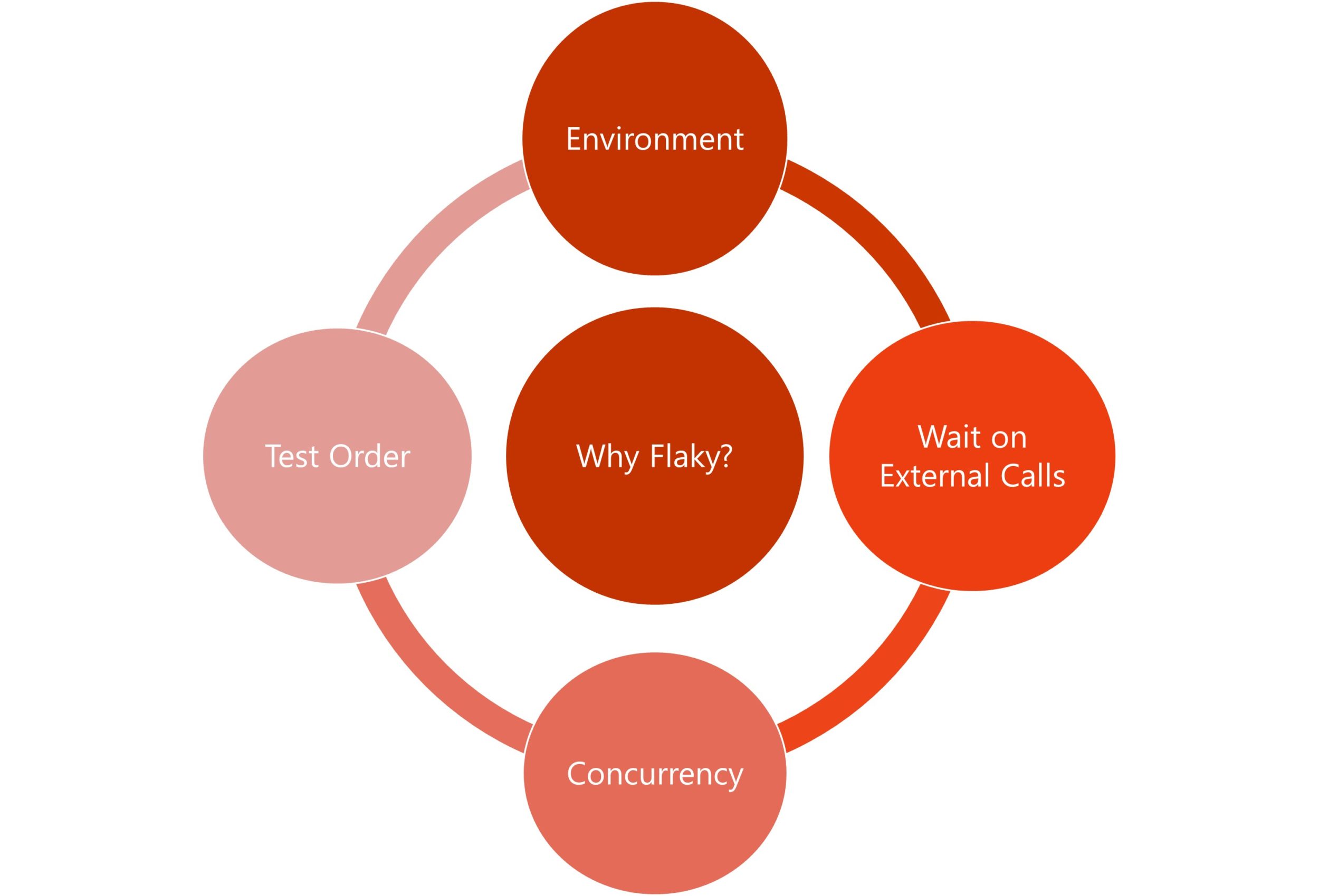
Flaky tests are a well-known problem across the industry and Microsoft is no exception. To address the issues with flaky tests and to improve developer productivity, we developed a comprehensive flaky test management system that helps to infer, triage, and quarantine those tests.
Flaky Test Management System Overview
Our flaky test management system is offered as a service within CloudBuild (Microsoft’s distributed build service) and CloudTest (Microsoft’s verification service). At a high-level, our system infers flaky tests from the test execution telemetry, quarantines those tests to avoid test failures due to known flaky tests, and files bugs to notify developers. The tests are removed from the quarantine soon after the developer fixes the bug, ensuring that we do not lose the test coverage permanently. Our system includes three major phases:
Inference
The inference phase helps identify the flaky tests by monitoring the telemetry emitted while executing tests in CloudTest. The default logic relies on CloudTest’s retry mechanism. In rolling sessions triggered off the master/main branch of a repo, whenever a test fails and the retry passes, we identify the test as flaky. We’ve experimented with more advanced algorithms, but found that for large, established test suites, simple retries yield impressive results. However, we also provide extensibility where individual teams can use different logic to infer flaky tests. For example, one team identifies a test as flaky if it fails and passes for different users within a given time window.
Reporting
The goal of this phase is to file bugs for the inferred flaky tests and assign them to the owner of the test. The bug reports include detailed information about the failure, associated sessions, and ways to identify the latest failures in case the bug is not triaged immediately. If no owner is explicitly specified for the test, we use a heuristic of identifying the owner as the developer who made recent frequent changes to the test.
Mitigation
Finally, the mitigation phase aims to suppress the test failures that happen due to known flaky tests, referred to as quarantined tests. Our system also explicitly reports the tests as flaky in our UI (User Interfaces) as shown in the screenshot below.
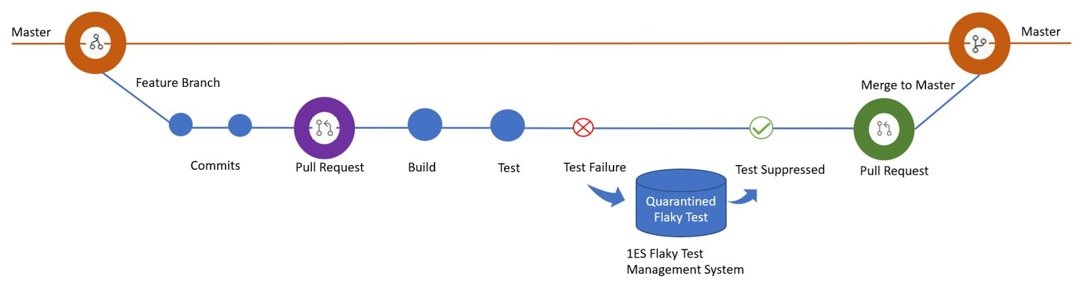
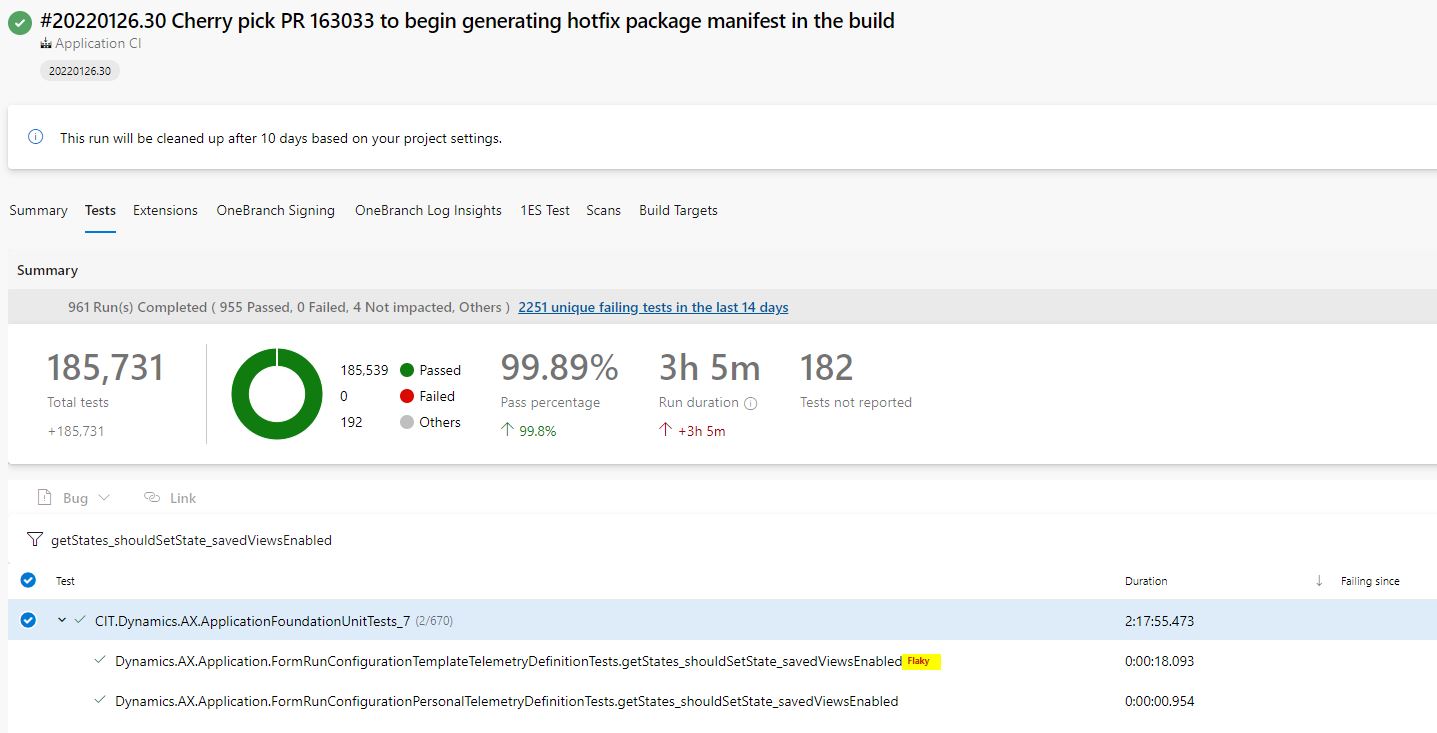
Given the diversity of languages and test frameworks used at Microsoft, our mitigation phase is specifically designed to be independent of any language or test framework and operates purely on the generated test results.
Whenever a developer closes a bug report, our system automatically removes the test from quarantine — any further failures of that test will block the validation pipeline. Note that we always run all the tests and only suppress the results of the quarantined tests. This helps us in monitoring quarantined tests as well, to automatically remove them from quarantine and close the associated bug if they are not flaky over a certain period. This feature helps further reduce the developer effort, especially in the presence of many flaky tests.
Summary
Our flaky test management system is currently used by more than 100 product teams across Microsoft. The system has already identified ~49K flaky tests and helped pass 160K sessions that would have failed due to flaky test failures. Our telemetry also shows that many of the reported bugs have been closed, demonstrating how our system is helping improve the overall quality of the test collateral at Microsoft. Lastly, our system helps influence the culture, where teams enforce additional policies, like blocking PRs for developers, if they have more than 10 flaky test bugs assigned to them.
0 comments