

A friend once quipped to me that “computer science is entirely about sorting and searching”. While that’s a gross overgeneralization, there’s a grain of truth to it. Searching is, in one way, shape, or form, at the heart of many workloads, and it’s so important that multiple domain-specific languages have been created over the years to ease the task of expressing searches. Arguably none is more ubiquitous than regular expressions.
A regular expression, or regex, is a string that enables a developer to express a pattern being searched for, making it a very common way to search text and to extract from the results key finds. Every major development platform has one or more regex libraries, either built into the platform or available as a separate library, and .NET is no exception. .NET’s System.Text.RegularExpressions namespace has been around since the early 2000s, introduced as part of .NET Framework 1.1, and is used by thousands upon thousands of .NET applications and services.
At the time it was introduced, it was a state-of-the-art design and implementation. Over the years, however, it didn’t evolve significantly, and it fell behind the rest of the industry. This was rectified in .NET 5, where we re-invested in making Regex very competitive, with many improvements and optimizations to its implementation (elaborated on in Regex Performance Improvements in .NET 5). However, those efforts didn’t expand much upon its functionality. Now with .NET 7, we’ve again heavily invested in improving Regex, for performance but also for significant functional enhancements.
In this post, we’ll explore many of these improvements to highlight why Regex in .NET 7 is an awesome choice for your text searching needs in .NET.
Table Of Contents
- Backtracking (and
RegexOptions.NonBacktracking) - StringSyntaxAttribute.Regex)
- Case-insensitive matching (and RegexOptions.IgnoreCase)
- Source Generation
- Spans
- Vectorization
- Auto-Atomicity and Backtracking
- Set Optimizations
- What’s Next?
Backtracking (and RegexOptions.NonBacktracking)
There are multiple ways a regex engine (the thing that does the actual searching) can be implemented. Since the beginning of .NET’s Regex, it’s employed a “backtracking” engine, sometimes called a “regex-directed” engine. Such engines work the way you might logically think about performing a search in your head: try one thing, and if it fails, go back and try the next… hence, “backtracking”. For example, given a pattern "a{3}|b{4}", which says “match either three 'a' characters or four 'b' characters”, a backtracking engine will walk along the input text, and at each relevant position, first try to match three 'a's, and if it can’t, then try to match four 'b's. In doing so, it might end up needing to examine the same text multiple times. Backtracking engines are capable of supporting more than just “regular languages”, and are a very popular form of engine because they enable fully implementing features like backreferences and lookarounds. Such backtracking engines also can be incredibly efficient, in particular when the thing being searched for matches and does so with as few wrong tries along the way as possible.
The problem with backtracking engine performance isn’t the best-case or even the expected-case, however, but rather the worst-case. You can find explanations of “catastrophic backtracking” or “excessive backtracking” all over the internet. Most of them use nested loops as an example, however I find that it’s easier to reason about with alternations. Consider an expression like ^(\d\w|\w\d)$; this expression ensures you’re matching at the beginning of the input, then matches either a digit followed by a word character, or a word character followed by a digit, and then requires being at the end of the input. If you try to match this against the input "12a" (ASCII numbers are both digits and word characters), it will:
- Match
\d\wagainst"12". - Try to match
$but fail because it’s not at the end of the input, so backtrack to the last choice made. - Match
\w\dagainst"12". - Try to match
$but fail because it’s not at the end of the input, so backtrack to the last choice made. - There are no more choices left, so fail.
Seems simple enough, but now let’s copy-and-paste the alternation so there are two of them, and double the number of digits in the input, matching ^(\d\w|\w\d)(\d\w|\w\d)$ against "1234a". Now we find it performs roughly as follows:
- Match alternation 1’s
\d\wagainst"12". - Match alternation 2’s
\d\wagainst"34". - Try to match
$but fail because it’s not at the end of the input, so backtrack to the last choice made. - Match alternation 2’s
\w\dagainst"34". - Try to match
$but fail because it’s not at the end of the input, so backtrack to the last choice made. There are no more choices in the second alternation, so backtrack further. - Match alternation 1’s
\w\dagainst"12". - Match alternation 2’s
\d\wagainst"34" - Try to match
$but fail because it’s not at the end of the input, so backtrack to the last choice made. - Match alternation 2’s
\w\dagainst"34". - Try to match
$but fail because it’s not at the end of the input, so backtrack to the last choice made. - There are no more choices left, so fail.
Notice that by adding one more alternation, we actually doubled the number of steps in our matching operation. If we were to add one more alternation, we’d double it again. One more, double it again. And so on. And there in lies the rub. For every additional alternation we add here, each with two possible choices, we’re allowing the implementation to backtrack through two choices for each alternation, for each of which it needs to evaluate everything else, yielding an O(2^N) algorithm. That’s… bad.
We can actually see this in practice. Try running the following code (and after starting it, go get a cup of coffee), which is the expression we just talked about, except using a repeater to express multiple alternations rather than copy-and-pasting that subexpression multiple times:
using System.Diagnostics;
using System.Text.RegularExpressions;
var sw = new Stopwatch();
for (int i = 10; i <= 30; i++)
{
var r = new Regex($@"^(\w\d|\d\w){{{i}}}$");
string input = new string('1', (i * 2) + 1);
sw.Restart();
r.IsMatch(input);
sw.Stop();
Console.WriteLine($"{i}: {sw.Elapsed.TotalMilliseconds:N}ms");
}On my machine, I see numbers like this:
10: 0.14ms
11: 0.32ms
12: 0.62ms
13: 1.26ms
14: 2.43ms
15: 5.03ms
16: 9.82ms
17: 19.71ms
18: 40.12ms
19: 79.85ms
20: 152.44ms
21: 318.82ms
22: 615.87ms
23: 1,230.21ms
24: 2,436.38ms
25: 4,895.82ms
26: 9,748.99ms
27: 19,487.77ms
28: 39,477.51ms
29: 82,267.19ms
30: 160,748.51msNotice how at first it’s fast, but as we increase the number of alternations, it slows down exponentially, approximately doubling in execution time on every addition. By the time we get to 30 alternations, what once was fast is now taking more than two and a half minutes.
This is the whole reason .NET’s Regex introduced support for timeouts. In practice, most regular expressions and the inputs they’re provided do not result in this catastrophic behavior. But if you can’t trust that the pattern isn’t susceptible given the right (or, rather, wrong) input, a timeout serves as a stopgap to help mitigate the possibility of a “ReDoS” attack, a “Regex Denial-of-Service” where such catastrophic backtracking is taken advantage of to get the system to spin its wheels. Thus, Regex supports timeouts, and guarantees that it will only do at most O(n) work (where n is the length of the input) between timeout checks, thus enabling a developer to prevent such runaway execution. .NET also supports setting a global timeout, such that if a timeout isn’t set on an individual problematic expression, the app itself can mitigate any such concerns.
There’s another approach, however. I mentioned that some engines are backtracking, or “regex-directed”. Others, however, in particular ones that are ok eschewing more advanced features like backreferences, and that are interested in being able to make worst-case guarantees about execution time regardless of the pattern, can opt for a more traditional “input-directed” model based on the origins of regular expressions: finite automata.
Imagine the regular expression being turned into a graph, where every construct in the pattern is represented as one or more nodes in a graph, and you can transition from one node to another based on the next character in the input. For example, consider the simple expression abc|cd. As a directed graph, this expression could look like this:
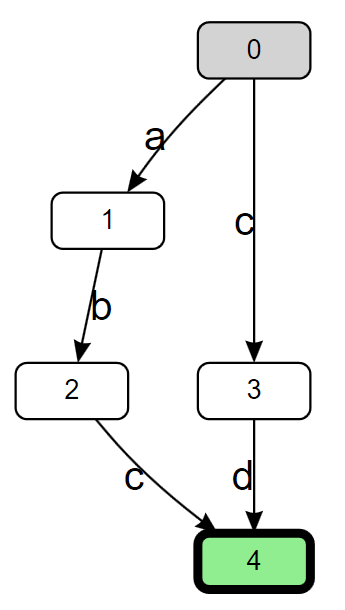
Here, the 0 node in the graph is the “start state”, the location in the graph at which we start the matching process. If the next character is a 'c', we transition to node 3. If the next character after that is a 'd', we transition to the final state of node 4 and declare a match. However, this graph really only represents the ability to match at a single fixed location in the input; if the initial character we read isn’t an 'a‘ or a 'c', nothing is matched. To address that, we can prefix the expression with a .*? lazy loop (here I’m using '.' to mean “match anything” rather than “match anything other than 'n'“, as if RegexOptions.Singleline was specified), to encapsulate the idea that we’re going to walk along the input until the first place we find "abc" or "cd" that matches. If we do that, we get almost the exact same graph, but this time with an extra transition from the start state back to the start state.
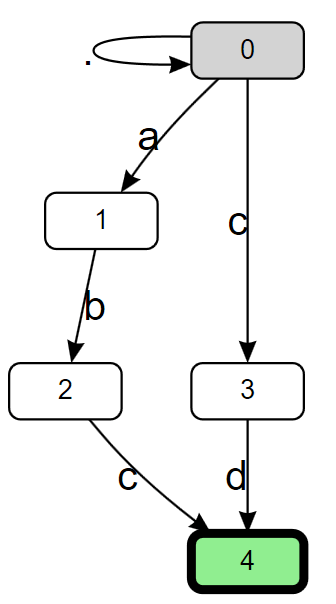
This graph represent’s what’s known as a “non-deterministic finite automata” (NFA). The “non-deterministic” part of it stems from that new transition we added from state 0 to state 0. Note that the transition is tagged as ., meaning it matches anything, and “anything” can include both 'a' and 'c', for which we already have transitions. That means if we’re in the start state and we read an 'a', we actually have two transitions we can take, one leading to node 1, and one leading back to node 0, which means after reading the 'a', we’re effectively in two nodes at the same time. A backtracking engine is often referred to as an NFA-based engine, as it’s logically walking the NFA graph, and when it comes to a point in the graph where it has to make a choice, it tries one choice, and if that ends up not matching, “backtracks” to the last choice it made, and goes a different way. As noted, this can result in exponential worst case processing time for some expressions.
But there are other ways to process an NFA. For example, rather than just considering ourselves in one node at a time, we can maintain a “current state” that’s the set of all nodes we’re currently “in”. For each character in the input we read, we enumerate all the states in our set, and for each, find all the new nodes we could transition to, creating our new set. This leads to O(n * m^2) worst-case processing time, where m is the number of nodes in the graph, and if you consider the pattern to be fixed and the only thing that’s dynamic is the input, then the size of the graph is constant, and this becomes O(n) worst-case processing time. For example, given the input "aaabc", we’d:
- Begin at the start state, such that our state set contains only that starting node: [0].
- Read
'a', find two transitions to nodes 0 and 1, yielding the new state set: [0, 1]. - Read
'a'again. From node 0, we again have two transitions to nodes 0 and 1, and from node 1, there’s no transition for'a'. This again yields: [0, 1]. - Read
'a'again. And again, we end up with [0, 1]. - Read
'b'. There’s only one transition from node 0 back to itself, and there’s only one transition from node 1 for'b'to node 2, yielding the new state set: [0, 2]. - Read
'c'. There’s now two transitions from node 0, one back to itself and one to node 3, and there’s one transition from node 2 to node 4: [0, 3, 4]. - Our state set includes the final state 4, so we’re done with a match.
There’s another form of finite automata, however, and that’s a “deterministic finite automata” (DFA). The key difference between a DFA and an NFA is the DFA is guaranteed to only have a single transition out of a node for a given input (so whereas every DFA is an NFA, not every NFA is a DFA). That makes a DFA really valuable for a regex engine, because it means the engine simply needs to make a single walk through the input (at least to determine whether there is a match): read the next character, transition to the next node, read the next character, transition to the next node, and on and on until either a final state is found (match) or it dead-ends, unable to transition out of the current node for the next input character (no match). This leads to O(n) worst-case processing time. The graph, however, is considerably more complex:
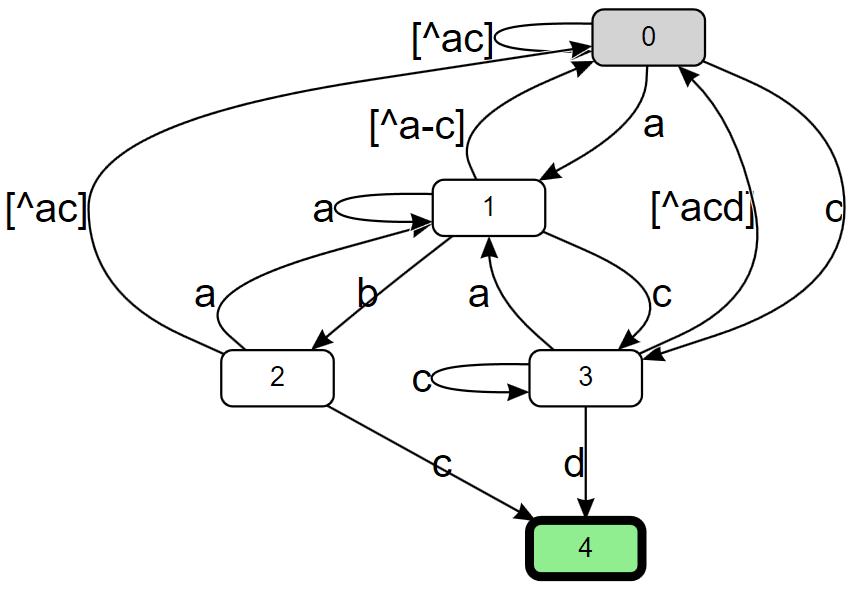
Notice how there are many more distinct transitions in this graph, to account for the fact that there’s only one possible transition out of a node for a given input, e.g. there are three transitions out of node 0, one for an 'a', one for a 'c', and one for everything other than 'a' or 'c'. Additionally, for any given state in the graph, we don’t have a lot of information about where we came from and what path we took to get there. That means a regex engine using this approach can employ such a graph to determine whether there is a match, but it then needs to do additional work to determine, for example, where the match starts, or the values of any subcaptures that might be in the pattern. Further, while every NFA can be transformed into a DFA, for an NFA with n nodes you can actually end up with a DFA with O(2^n) nodes. This leads most regex engines that use finite automata, like Google’s RE2 and Rust’s regex crate, to employ multiple strategies, for example starting out with a DFA that’s lazily computed (only adding nodes to the graph as they’re needed) and then falling back to an NFA-based model if the DFA-based model gets too large.
In .NET 7, developers using Regex now also have a choice to pick such an automata-based engine, using the new RegexOptions.NonBacktracking options flag, with an implementation grounded in the Symbolic Regex Matcher work from Microsoft Research (MSR). Going back to my previous catastrophic backtracking example, we can change the constructor call from:
var r = new Regex($@"^(\w\d|\d\w){{{i}}}$");to
var r = new Regex($@"^(\w\d|\d\w){{{i}}}$", RegexOptions.NonBacktracking);and now run the program again. Don’t bother going to get a cup of coffee this time. On my machine, I see numbers like this:
10: 0.10ms
11: 0.11ms
12: 0.10ms
13: 0.09ms
14: 0.09ms
15: 0.10ms
16: 0.10ms
17: 0.10ms
18: 0.12ms
19: 0.12ms
20: 0.13ms
21: 0.12ms
22: 0.13ms
23: 0.14ms
24: 0.14ms
25: 0.14ms
26: 0.15ms
27: 0.15ms
28: 0.17ms
29: 0.17ms
30: 0.17msThe processing is now effectively linear in the length of the (short) input. And, actually, most of the cost here is in building the graph, which is done lazily as the implementation walks the graph and discovers it needs to transition to a node in the graph that hasn’t been computed yet (the implementation starts with a DFA, building out the nodes lazily, and at some point if the graph gets too big, it switches over dynamically to NFA-based processing, such that the graph then only grows linearly with the size of the pattern). If I subtly change the original program from doing:
sw.Restart();
r.IsMatch(input);
sw.Stop();to instead doing:
r.IsMatch(input); // warm-up
sw.Restart();
r.IsMatch(input);
sw.Stop();I then get numbers like these:
10: 0.00ms
11: 0.01ms
12: 0.00ms
13: 0.00ms
14: 0.00ms
15: 0.00ms
16: 0.01ms
17: 0.00ms
18: 0.00ms
19: 0.00ms
20: 0.00ms
21: 0.00ms
22: 0.01ms
23: 0.00ms
24: 0.00ms
25: 0.00ms
26: 0.00ms
27: 0.00ms
28: 0.00ms
29: 0.00ms
30: 0.00msWith the graph fully computed already, we’re now seeing just the costs associated with execution, and it’s fast.
The new RegexOptions.NonBacktracking option doesn’t support everything the other built-in engines support. In particular, the option can’t be used in conjunction with RegexOptions.RightToLeft or RegexOptions.ECMAScript, and it doesn’t allow for the following constructs in the pattern:
Some of these restrictions are fairly fundamental to the implementation, while some of them could be relaxed in time should there be sufficient demand.
RegexOptions.NonBacktracking also has a subtle difference with regards to execution. .NET’s Regex has historically been unique amongst popular regex engines with regards to its behavior around captures. If a capture group is in a loop, most engines only provide the last matched value for that capture, but .NET’s Regex supports the notion of tracking all values a capture group inside a loop captured, and providing access to all of them. As of now, the new RegexOptions.NonBacktracking only supports providing the last, as do most other regex implementations. For example, this code:
using System.Text.RegularExpressions;
foreach (RegexOptions option in new[] { RegexOptions.None, RegexOptions.NonBacktracking })
{
Console.WriteLine($"RegexOptions.{option}");
Console.WriteLine("----------------------------");
Match m = Regex.Match("a123b456c", @"a(\w)*b(\w)*c", option);
foreach (Group g in m.Groups)
{
Console.WriteLine($"Group: {g}");
foreach (Capture c in g.Captures)
{
Console.WriteLine($"\tCapture: {c}");
}
}
Console.WriteLine();
}outputs:
RegexOptions.None
----------------------------
Group: a123b456c
Capture: a123b456c
Group: 3
Capture: 1
Capture: 2
Capture: 3
Group: 6
Capture: 4
Capture: 5
Capture: 6
RegexOptions.NonBacktracking
----------------------------
Group: a123b456c
Capture: a123b456c
Group: 3
Capture: 3
Group: 6
Capture: 6Beyond that, most anything you do today with Regex you can do with RegexOptions.NonBacktracking. Note that the goal of NonBacktracking is not to be always faster than the backtracking engines. In fact, one of the reasons backtracking engines are so popular is they can be extremely fast in the best and even expected cases, and the .NET backtracking engines have been optimized with even more tricks and vectorization in .NET 7 to make them even faster than before in the best and typical use cases (I’ll discuss vectorization in more depth later in the post). NonBacktracking‘s bread-and-butter is to be fast (but not necessarily the fastest) for all cases, especially worst-case. Here’s an example to try to drive that home.
private Regex _backtracking = new Regex("a.*b", RegexOptions.Singleline | RegexOptions.Compiled);
private Regex _nonBacktracking = new Regex("a.*b", RegexOptions.Singleline | RegexOptions.NonBacktracking);
private string _input;
[Params(1, 2)]
public int Input { get; set; }
[GlobalSetup]
public void Setup()
{
_input = new string('a', 1000);
if (Input == 1)
{
_input += "b";
}
}
[Benchmark] public bool Backtracking() => _backtracking.IsMatch(_input);
[Benchmark(Baseline = true)] public bool NonBacktracking() => _nonBacktracking.IsMatch(_input);Here we’re matching the expression a.*b against an input of one thousand 'a's followed by a 'b'. The backtracking engine implements that essentially by doing an IndexOf('a') to find the first place to try to match. Then as part of the match, it’ll compare the 'a', then jump to the end of the input (since .* with RegexOptions.Singleline matches everything), then LastIndexOf('b'), and will declare success. In contrast, the non-backtracking engine will read a character in the input, look in a transition table to determine the next node to transition to, move to that node, and will rinse and repeat until it finds a match. So in one case, we’re effectively doing fractional amounts of instructions per character (thanks to the vectorization), and in the other, we’re executing multiple instructions per character. The impact of that is evident in the resulting benchmark numbers:
| Method | Input | Mean | Ratio |
|---|---|---|---|
| Backtracking | 1 | 43.08 ns | 0.008 |
| NonBacktracking | 1 | 5,541.18 ns | 1.000 |
For this input, the backtracking engine did effectively zero backtracking and was ~128x faster than the non-backtracking engine. But, now consider the second input, which is a thousand 'a's without a following 'b', such that it doesn’t match. The strategy employed by the non-backtracking engine will be exactly the same: read a character, transition to the next node, read a character, transition to the next node, and so on. But the backtracking engine will end up having to do much more work. It’ll start off the same way, doing an IndexOf('a') to find the next place to match, jumping to the end of the input, and doing a LastIndexOf('b')… but this time it won’t find one, so it’ll declare failure to match at position 0. It’ll then bump to position 1 and try again, finding the next 'a' at position 1, jumping to the end of the input, doing a LastIndexOf('b'), and not finding one. And it’ll bump again. And again. The result is it’ll end up doing O(n^2) work, and even though it’s vectorizing some of those operations, it’s still much more work, which again shows up in the numbers:
| Method | Input | Mean | Ratio |
|---|---|---|---|
| Backtracking | 2 | 44,888.64 ns | 8.14 |
| NonBacktracking | 2 | 5,514.10 ns | 1.00 |
With the same pattern and just a different input, now the backtracking engine is ~8x slower than the non-backtracking engine rather than being ~128x faster. And importantly, the time the non-backtracking engine took is almost exactly the same with both inputs. Which is the whole point.
StringSyntaxAttribute.Regex
For developers using Regex, Visual Studio has a really nice feature that provides syntax colorization, syntax validation, and regex IntelliSense when working with regular expressions.
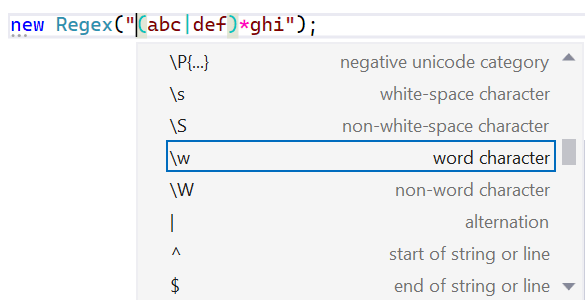
Historically, Visual Studio contained a hardcoded list of methods where it knew the arguments to those methods would be regular expressions. This isn’t scalable, however, with this treatment only afforded to Regex‘s constructors and static methods. This isn’t an issue unique to regular expressions, of course. There are many APIs that accept strings that need to adhere to specific syntaxes, for example passing JSON content into a method, or passing a DateTime format string into a ToString call, or any number of other domain-specific languages, and it’s not feasible for every tool that could meaningfully improve the developer experience around those APIs to hardcode the list of every possible API known to accept that syntax (nor to come up with heuristics for them).
Instead, .NET 7 introduces the new [StringSyntax(...)] attribute, which is used in .NET 7 on more than 350 string, string[], and ReadOnlySpan<char> parameters, properties, and fields to highlight to an interested tool what kind of syntax is expected to be passed or set. Now, any method that wants to indicate a string parameter accepts a regular expression can attribute it, e.g. void MyCoolMethod([StringSyntax(StringSyntaxAttribute.Regex)] string expression), and Visual Studio 2022 will provide the same syntax validation, syntax coloring, and IntelliSense that it provides for all the other Regex-related methods. For example, the WebProxy class provides a constructor that accepts an array of regex strings to be used as proxy bypasses; this string[] parameter is attributed in .NET 7 as [StringSyntax(StringSyntaxAttribute.Regex)], a fact that’s visible when using it in Visual Studio 2022:
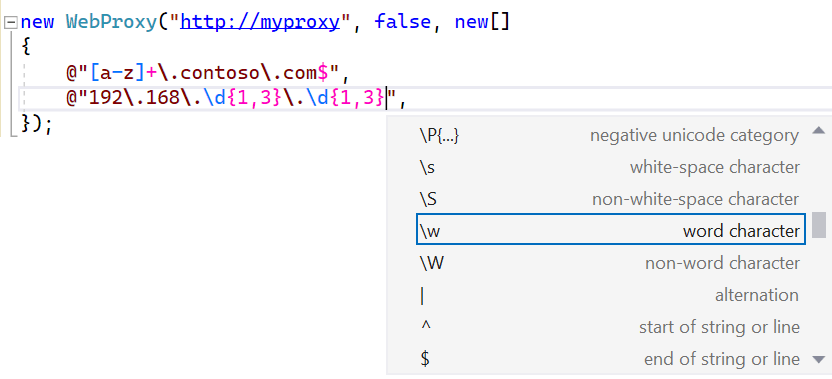
String parameters, properties, and fields throughout the core .NET libraries now have been attributed to say whether they’re regular expressions, JSON, XML, composite format strings, URLs, numeric format strings, and on and on.
Case-insensitive matching (and RegexOptions.IgnoreCase)
It’s common with regular expressions to want to tell the engine to perform the match in a case-insensitive way. For example, you might write the pattern [a-z0-9] in order to match an ASCII letter or digit, but you also want the uppercase values to be included. To achieve that, most modern regex engines have support for the (?i) inline syntax which, when included in the pattern, tells the engine that everything after that token in its current subexpression should be treated in a case-insensitive manner. Thus:
(?i)[a-z0-9]is equivalent to[A-Za-z0-9](?i)[abc]d*efgis equivalent to[AaBbCc][Dd]*[Ee][Ff][Gg](?i)abc|defis equivalent to[Aa][Bb][Cc]|defabc|(?i)defis equivalent toabc|[Dd][Ee][Ff](?i)(abc|def)is equivalent to([Aa][Bb][Cc]|[Dd][Ee][Ff])
.NET has long supported this inline syntax, but it’s also supported the RegexOptions.IgnoreCase option, which is equivalent to applying (?i), and thus case-insensitivity, to the whole pattern. .NET has also supported the RegexOptions.InvariantCulture option, which is only relevant when RegexOptions.IgnoreCase or (?i) is used and which changes exactly what values are considered case-equivalent.
In every version of .NET prior to .NET 7, this case-insensivity support is implemented via ToLower. When the Regex is constructed, the pattern is transformed such that every character in the pattern is lowercased, and then at match time, each time an input character is compared to something in the pattern, the input character is also ToLower‘d, and the lowercased values are compared. This support is functional, but there are some significant downsides to this implementation approach.
- Culture changes. By default, the “current” culture is used to perform the lowercasing, e.g.
CultureInfo.CurrentCulture.TextInfo.ToLower(c), and that’s relevant because culture impacts how characters change case. One of the most famous examples of this is the “Turkish i”. If you run(int)new CultureInfo("en-US").TextInfo.ToLower('I'), that will produce the value105, the numerical value for the ASCII lowercase ‘i’, known in Unicode as “LATIN SMALL LETTER I”. If, however, you run the exact same code but changing the name of the culture to “tr-TR”, as in(int)new CultureInfo("tr-TR").TextInfo.ToLower('I'), that code will now produce the value305, otherwise known in Unicode as the “LATIN SMALL LETTER DOTLESS I”. So culture matters (specifyingRegexOptions.InvariantCulturesimply serves to make the implementation useCultureInfo.InvariantCultureinstead ofCultureInfo.CurrentCulture). But there’s a functional issue here. I mentioned that the pattern is lowercased at construction time and the input is lowercased at match time, and that the current culture is used to perform that lowercasing… what happens if the culture changes between when the pattern is constructed and the input is matched? Nothing good. You then end up with inconsistencies, trying to compare one character lowercased according to one culture’s rules against another character lowercased according to another culture’s rules.using System.Globalization; using System.Text.RegularExpressions; CultureInfo.CurrentCulture = new CultureInfo("tr-TR"); var r = new Regex("İ", RegexOptions.IgnoreCase); // "construction time" ... // some other code CultureInfo.CurrentCulture = new CultureInfo("en-US"); Console.WriteLine(r.IsMatch("I")); // "match time" - ToLower overhead.
ToLowerisn't super expensive, but it's also not free. Having to callToLoweron every character in order to process it means a comparatively high cost to processing each value. This overhead was decreased in previous versions of .NET, for example changing the code generated byRegexOptions.Compiledto cache the culture information so that rather than emitting the equivalent ofCultureInfo.CurrentCulture.TextInfo.ToLower(c)on each comparison, it instead output_textInfo.ToLower(c). But even with such optimizations, this still contributes meaningfully to the gap in performance between case-sensitive and case-insensitive matching. Consider this example:private Regex _r1 = new Regex("^[Aa]*$", RegexOptions.Compiled); private Regex _r2 = new Regex("^a*$", RegexOptions.Compiled | RegexOptions.IgnoreCase); private string _input1 = new string('a', 100_000); [Benchmark] public bool ManualSet1() => _r1.IsMatch(_input1); [Benchmark] public bool IgnoreCase2() => _r2.IsMatch(_input1);In theory, these two expressions should be identical, and functionally they are. But in the first case, with the set, in .NET 6 the compiled implementation will use code along the lines of
(c == 'A') | (c == 'a')to match[Aa], whereas with theIgnoreCaseversion, in .NET 6 the compiled implementation will use code along the lines of_textInfo.ToLower(c) == 'a', such that on my machine I get results like this from the microbenchmark:Method Runtime Mean ManualSet1 .NET 6 85.75 us IgnoreCase2 .NET 6 235.40 us For two expressions that should be identical, ~3x is a sizeable difference, and it's all because of
ToLower. - Vectorization. There are two primary ways regular expressions end up being used: to validate whether some text fully matches a pattern, or to find occurrences of the pattern within some larger text. For the latter, it's critically important for performance to move as quickly as possible through the portions of text that can't possibly match in order to only spend more resources on the portions that might possibly match. The more comparisons that can be elided or done concurrently, the better off we are. And that's where vectorization comes into play. Vectorization is the approach of taking advantage of hardware instructions that support doing multiple things at the same time. Consider if I have 4 bytes and I want to compare all 4 of them to see if they're each 0xFF. I could write a for loop that walks each byte and compares each of the 4 against 0xFF, or I could treat the 4 contiguous bytes as if they were a 32-bit integer and just compare all 4 at the same time against 0xFFFFFFFF. Doing so will end up being ~4x faster. In a 64-bit process, I could do the same with 8 bytes, comparing against 0xFFFFFFFFFFFFFFFF, and it'd be ~8x faster. And modern hardware offers specialized instruction sets that support performing operations like this on 16, 32, or even 64 bytes at a time, and not just comparisons, but other more complicated operations as well. .NET exposes APIs for these "intrinsics", and exposes higher-level "vector" types like
Vector<T>,Vector128<T>, andVector256<T>that make targeting these instructions easier, but the core libraries also use all of this support internally to vectorize operations likeIndexOf. That way, a developer can just useIndexOfto perform their search and gain the full benefits of vectorization without having to manually write that vectorization code by hand. In .NET 5,Regexgot in on this vectorization game by trying to useIndexOfandIndexOfAnyto find the next location a pattern may match, if possible. But now consider this slightly tweaked version of the previously shown benchmark:private Regex _r3 = new Regex("[Aa]+", RegexOptions.Compiled); private Regex _r4 = new Regex("a+", RegexOptions.Compiled | RegexOptions.IgnoreCase); private string _input2 = new string('z', 100_000) + "AaAa"; [Benchmark] public bool ManualSet3() => _r3.IsMatch(_input2); [Benchmark] public bool IgnoreCase4() => _r4.IsMatch(_input2);Here we're searching a string of mostly
'z's that ends with"AaAa"against the pattern[Aa]+or theIgnoreCasepatterna+. With the former, the implementation in .NET 6 could useIndexOfAny('A', 'a')to find the next possible start of a match, but because the case-insensitive implementation forIgnoreCaseneeds to callToLoweron every character, that implementation is forced to walk character by character through the input rather than vectorizing to process it in batches. The difference is stark:Method Runtime Mean ManualSet3 .NET 6 4.312 us IgnoreCase4 .NET 6 222.387 us
All of these issues have led us to entirely reconsider how RegexOptions.IgnoreCase is handled. In .NET 7, we no longer implement RegexOptions.IgnoreCase by calling ToLower on each character in the pattern and each character in the input. Instead, all casing-related work is done when the Regex is constructed. Regex now uses a casing table to essentially answer the question "given the character 'c', what are all of the other characters it should be considered equivalent to under the selected culture?" So for example, in my current culture:
- Given the character
'a', it'll be determined to also be equivalent to'A'. - Given the "GREEK CAPITAL LETTER OMEGA" (
'u03A9'), it'll be determined to also be equivalent to the "GREEK SMALL LETTER OMEGA" ('u03C9'), and the "OHM SIGN" ('u2126').
From that, the implementation throws away the original IgnoreCase character and replaces it instead with a non-IgnoreCase set composed of all the equivalent characters. So, for example, given the pattern (?i)abcd, it'll replace that with [Aa][Bb][Cc][Dd]. This solves all three of the problems previously outlined:
- Culture changes. The only culture that matters is the one at the time of construction, since that's when the pattern is being transformed.
- ToLower overhead.
ToLoweris no longer being used, so its overhead doesn't matter. - Vectorization. We now have sets of known characters we can search for with methods like
IndexOfAny.
Now with .NET 7, I can run these benchmarks again:
private Regex _r1 = new Regex("^[Aa]*$", RegexOptions.Compiled);
private Regex _r2 = new Regex("^a*$", RegexOptions.Compiled | RegexOptions.IgnoreCase);
private string _input1 = new string('a', 100_000);
[Benchmark] public bool ManualSet1() => _r1.IsMatch(_input1);
[Benchmark] public bool IgnoreCase2() => _r2.IsMatch(_input1);
private Regex _r3 = new Regex("[Aa]+", RegexOptions.Compiled);
private Regex _r4 = new Regex("a+", RegexOptions.Compiled | RegexOptions.IgnoreCase);
private string _input2 = new string('z', 100_000) + "AaAa";
[Benchmark] public bool ManualSet3() => _r3.IsMatch(_input2);
[Benchmark] public bool IgnoreCase4() => _r4.IsMatch(_input2);and we can see that the difference between the expressions has disappeared, since the IgnoreCase variants are being transformed to be identical to their counterparts.
| Method | Runtime | Mean |
|---|---|---|
| ManualSet1 | .NET 6 | 85.75 us |
| IgnoreCase2 | .NET 6 | 235.40 us |
| ManualSet3 | .NET 6 | 4.312 us |
| IgnoreCase4 | .NET 6 | 222.387 us |
| ManualSet1 | .NET 7 | 47.167 us |
| IgnoreCase2 | .NET 7 | 47.130 us |
| ManualSet3 | .NET 7 | 4.147 us |
| IgnoreCase4 | .NET 7 | 4.135 us |
It's also interesting to note that the first benchmark not only trippled in throughput to match the set-based expression, they both then further doubled in throughput, dropping from ~86us on .NET 6 to ~47us on .NET 7. More on that in a bit.
Now, several times I've stated that this eliminates the need for casing at match time. That's ~99.5% true. In almost every regex construct, the input text is compared against the pattern text, which we can compute IgnoreCase sets for at construction. Great. There is, however, a single construct which compares input text against input text: backreferences. Imagine I had the pattern "(?i)(\w\w\w)1". What happens when we try to match this against input text like "ABCabc". The engine will successfully match the "ABC" against the \w\w\w, storing that as the first capture, but the \1 backreference is itself IgnoreCase, which means it's now case-insensitively comparing the next three characters of the input against the already matched input "ABC", and it needs to somehow determine whether "ABC" is case-equivalent to "abc". Prior to .NET 7, it would just use ToLower on both, but we've moved away from that. So for IgnoreCase backreferences, not only will the casing tables be consulted at construction time, they'll also be used at match time. Thankfully, use of case-insensitive backreferences is fairly rare. In an open-source corpus of ~19,000 regular expressions gathered from appropriately-licensed nuget packages, only ~0.5% include a case-insensitive backreference.
Source Generation
When you write new Regex("somepattern"), a few things happen. The specified pattern is parsed, both to ensure validity of the pattern and to transform it it into an internal RegexNode tree that represents the parsed regex. The tree is then optimized in various ways, transforming the pattern into a variation that's functionally equivalent but that can be more efficiently executed, and then that tree is written into a form that can be interpreted, a series of opcodes and operands that provide instructions to the internal RegexInterpreter engine on how to match. When a match is performed, the interpreter simply walks through those instructions, processing them against the input text. When instantiating a new Regex instance or calling one of the static methods on Regex, the interpreter is the default engine employed; we already saw how the new RegexOptions.NonBacktracking can be used to opt-in to the new non-backtracking engine, and RegexOptions.Compiled can be used to opt-in to a compilation-based engine.
When you specify RegexOptions.Compiled, prior to .NET 7, all of the same construction-time work would be performed. Then, the resulting instructions would be transformed further by the reflection-emit-based compiler into IL instructions that would be written to a few DynamicMethods. When a match was performed, those DynamicMethods would be invoked. This IL would essentially do exactly what the interpreter would do, except specialized for the exact pattern being processed. So for example, if the pattern contained [ac], the interpreter would see an opcode that essentially said "match the input character at the current position against the set specified in this set description" whereas the compiled IL would contain code that effectively said "match the input character at the current position against 'a' or 'c'". This special-casing and the ability to perform optimizations based on knowledge of the pattern are some of the main reasons specifying RegexOptions.Compiled yields much faster matching throughput than does the interpreter.
There are, however, several downsides to RegexOptions.Compiled. Most impactfully, it involves much more construction cost than does using the interpreter. Not only are all of the same costs paid as for the interpreter, but it then needs to compile that resulting RegexNode tree and generated opcodes/operands into IL, which adds non-trivial expense. And that generated IL further needs to be JIT-compiled on first use leading to even more expense at startup. RegexOptions.Compiled represents a fundamental tradeoff between overheads on first use and overheads on every subsequent use. The use of reflection emit also inhibits the use of RegexOptions.Compiled in certain environments; some operating systems don't permit dynamically generated code to be executed, and on such systems, Compiled will become a nop.
To help with these issues, the .NET Framework provides a method Regex.CompileToAssembly. This method enables the same IL that would have been generated for RegexOptions.Compiled to instead be written to a generated assembly on disk, and that assembly can then be referenced as a library from your app. This has the benefits of avoiding the startup overheads involved in parsing, optimizing, and outputting the IL for the expression, as that can all be done ahead of time rather than each time the app is invoked. Further, that assembly could be ahead-of-time compiled with a technology like ngen / crossgen, avoiding most of the associated JIT costs as well.
Regex.CompileToAssembly itself has problems, however. First, it was never particularly user friendly. The ergonomics of having to have a utility that would call CompileToAssembly in order to produce an assembly your app would reference resulted in relatively little use of this otherwise valuable feature. And on .NET Core, CompileToAssembly has never been supported, as it requires the ability to save reflection-emit code to assemblies on disk, which also isn't supported.
.NET 7 addresses all of this with the new GeneratedRegex source generator. (EDIT: After this blog post was published, the RegexGenerator attribute was renamed to GeneratedRegex.) The original compiler for C# was implemented in C/C++. A decade ago, in the grand tradition of compilers being implemented in the language they compile, the "Roslyn" C# compiler was implemented in C#. As part of this, it exposed object models for the entire compilation pipeline, with APIs the compiler itself uses to parse and understand C# but that are also exposed for arbitrary code to use to do the same. It then also enabled components that could plug into the compiler itself, with the compiler handing these "analyzers" all of the information the compiler had built up about the code being compiled and allowing the analyzers to inspect the data and issue additional "diagnostics" (e.g. warnings). More recently, Roslyn also enabled source generators. Just like an analyzer, a source generator is a component that plugs into the compiler and is handed all of the same information as an analyzer, but in addition to being able to emit diagnostics, it can also augment the compilation unit with additional source code. The .NET 7 SDK includes a new source generator which recognizes use of the new GeneratedRegexAttribute on a partial method that returns Regex, and provides an implementation of that method which implements on your behalf all the logic for the Regex. For example, if previously you would have written:
private static readonly Regex s_myCoolRegex = new Regex("abc|def", RegexOptions.Compiled | RegexOptions.IgnoreCase);
...
if (s_myCoolRegex.IsMatch(text) { ... }you can now write that as:
[GeneratedRegex("abc|def", RegexOptions.IgnoreCase)]
private static partial Regex MyCoolRegex();
...
if (MyCoolRegex().IsMatch(text) { ... }The generated implementation of MyCoolRegex() similarly caches a singleton Regex instance, so no additional caching is needed in consuming code.

But as can be seen, it's not just doing new Regex(...). Rather, the source generator is emitting as C# code a custom Regex-derived implementation with logic akin to what RegexOptions.Compiled emits in IL. You get all the throughput performance benefits of RegexOptions.Compiled (more, in fact) and the start-up benefits of Regex.CompileToAssembly, but without the complexity of CompileToAssembly. The source that's emitted is part of your project, which means it's also easily viewable and debuggable.
You can set breakpoints in it, you can step through it, and you can use it as a learning tool to understand exactly how the regex engine is processing your pattern and your input. The generator even spits out XML comments in order to help make the expression understandable at a glance at the usage site.
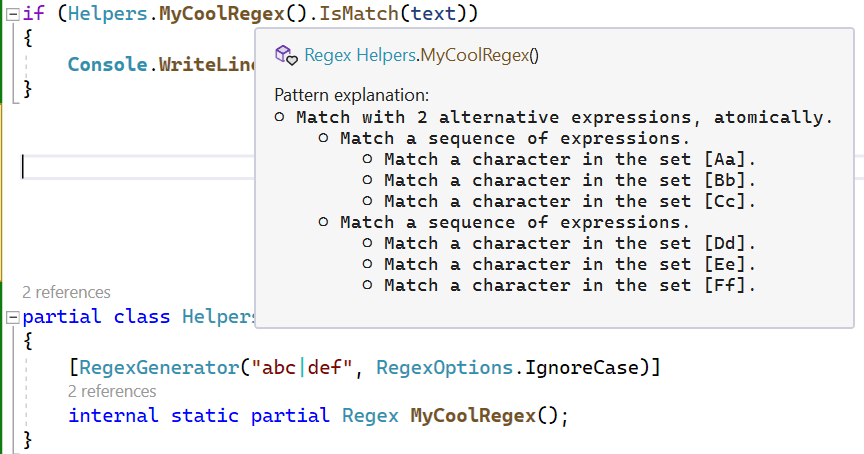
The initial creation of the source generator was a straight port of the RegexCompiler used internally to implement RegexOptions.Compiled; line-for-line, it would essentially just emit a C# version of the IL that was being emitted. Let's take a simple example:
[GeneratedRegex(@"(a|bc)d")]
public static partial Regex Example();Here's what the initial incarnation of the source generator emitted for the core matching routine:
protected override void Go()
{
string runtext = base.runtext!;
int runtextbeg = base.runtextbeg;
int runtextend = base.runtextend;
int runtextpos = base.runtextpos;
int[] runtrack = base.runtrack!;
int runtrackpos = base.runtrackpos;
int[] runstack = base.runstack!;
int runstackpos = base.runstackpos;
int tmp1, tmp2, ch;
// 000000 *Lazybranch addr = 20
L0:
runtrack[--runtrackpos] = runtextpos;
runtrack[--runtrackpos] = 0;
// 000002 *Setmark
L1:
runstack[--runstackpos] = runtextpos;
runtrack[--runtrackpos] = 1;
// 000003 *Setmark
L2:
runstack[--runstackpos] = runtextpos;
runtrack[--runtrackpos] = 1;
// 000004 *Lazybranch addr = 10
L3:
runtrack[--runtrackpos] = runtextpos;
runtrack[--runtrackpos] = 2;
// 000006 One 'a'
L4:
if (runtextpos >= runtextend || runtext[runtextpos++] != 97)
{
goto Backtrack;
}
// 000008 *Goto addr = 12
L5:
goto L7;
// 000010 Multi "bc"
L6:
if (runtextend - runtextpos < 2 ||
runtext[runtextpos] != 'b' ||
runtext[runtextpos + 1] != 'c')
{
goto Backtrack;
}
runtextpos += 2;
// 000012 *Capturemark index = 1
L7:
tmp1 = runstack[runstackpos++];
base.Capture(1, tmp1, runtextpos);
runtrack[--runtrackpos] = tmp1;
runtrack[--runtrackpos] = 3;
// 000015 One 'd'
L8:
if (runtextpos >= runtextend || runtext[runtextpos++] != 100)
{
goto Backtrack;
}
// 000017 *Capturemark index = 0
L9:
tmp1 = runstack[runstackpos++];
base.Capture(0, tmp1, runtextpos);
runtrack[--runtrackpos] = tmp1;
runtrack[--runtrackpos] = 3;
// 000020 Stop
L10:
base.runtextpos = runtextpos;
return;
Backtrack:
int limit = base.runtrackcount * 4;
if (runstackpos < limit)
{
base.runstackpos = runstackpos;
base.DoubleStack(); // might change runstackpos and runstack
runstackpos = base.runstackpos;
runstack = base.runstack!;
}
if (runtrackpos < limit)
{
base.runtrackpos = runtrackpos;
base.DoubleTrack(); // might change runtrackpos and runtrack
runtrackpos = base.runtrackpos;
runtrack = base.runtrack!;
}
switch (runtrack[runtrackpos++])
{
case 0:
{
// 000000 *Lazybranch addr = 20
runtextpos = runtrack[runtrackpos++];
goto L10;
}
case 1:
{
// 000002 *Setmark
runstackpos++;
goto Backtrack;
}
case 2:
{
// 000004 *Lazybranch addr = 10
runtextpos = runtrack[runtrackpos++];
goto L6;
}
case 3:
{
// 000012 *Capturemark index = 1
runstack[--runstackpos] = runtrack[runtrackpos++];
base.Uncapture();
goto Backtrack;
}
default:
{
global::System.Diagnostics.Debug.Fail($"Unexpected backtracking state {runtrack[runtrackpos - 1]}");
break;
}
}
}That's... intense. But it's the equivalent of what RegexCompiler was producing, essentially walking through the operators/operands created for the interpreter and emitting code for each. There are multiple issues with this. First, it's mostly unintelligible. If one of the goals of the source generator is to emit debuggable code, this largely fails at that goal, as even for someone deeply knowledgable about regular expressions, this isn't going to be very meaningful. Second, there are performance issues; for example, every operation involves pushing and popping state from a "runstack". And third, this loses out on additional possible optimizations, such as being able to use vectorized operations as part of handling specific constructs in the pattern; with this lowered opcode/operand representation, we lose much of the information that could enable the compiler or source generator to add useful improvements based on knowledge of the initial tree.
As such, for .NET 7, after this initial incarnation of the source generator, both the source generator and RegexCompiler were almost entirely rewritten, fundamentally changing the structure of the generated code. In .NET 5, we experimented with an alternative approach, and for simple patterns that didn't involve any backtracking, the RegexCompiler could emit code that was much cleaner, the primary goal being performance. That approach has now been extended to handle all constructs (with one caveat), and both RegexCompiler and the source generator still mapping mostly 1:1 with each other, following the new approach.
Now, here's what the source generator outputs for that same method (which has been renamed) today:
private bool TryMatchAtCurrentPosition(ReadOnlySpan<char> inputSpan)
{
int pos = base.runtextpos;
int matchStart = pos;
int capture_starting_pos = 0;
ReadOnlySpan<char> slice = inputSpan.Slice(pos);
// 1st capture group.
{
capture_starting_pos = pos;
// Match with 2 alternative expressions.
{
if (slice.IsEmpty)
{
UncaptureUntil(0);
return false; // The input didn't match.
}
switch (slice[0])
{
case 'a':
pos++;
slice = inputSpan.Slice(pos);
break;
case 'b':
// Match 'c'.
if ((uint)slice.Length < 2 || slice[1] != 'c')
{
UncaptureUntil(0);
return false; // The input didn't match.
}
pos += 2;
slice = inputSpan.Slice(pos);
break;
default:
UncaptureUntil(0);
return false; // The input didn't match.
}
}
base.Capture(1, capture_starting_pos, pos);
}
// Match 'd'.
if (slice.IsEmpty || slice[0] != 'd')
{
UncaptureUntil(0);
return false; // The input didn't match.
}
// The input matched.
pos++;
base.runtextpos = pos;
base.Capture(0, matchStart, pos);
return true;
}That's a whole lot more understandable, with a much more followable structure, with comments explaining what's being done at each step, and in general with code emitted under the guiding principle that we want the generator to emit code as if a human had written it. Even when backtracking is involved, the structure of the backtracking gets baked into the structure of the code, rather than relying on a stack to indicate where to jump next. For example, here's the code for the same generated matching function when the expression is [ab]*[bc]:
private bool TryMatchAtCurrentPosition(ReadOnlySpan<char> inputSpan)
{
int pos = base.runtextpos;
int matchStart = pos;
int charloop_starting_pos = 0, charloop_ending_pos = 0;
ReadOnlySpan<char> slice = inputSpan.Slice(pos);
// Match a character in the set [ab] greedily any number of times.
//{
charloop_starting_pos = pos;
int iteration = 0;
while ((uint)iteration < (uint)slice.Length && (((uint)slice[iteration]) - 'a' <= (uint)('b' - 'a')))
{
iteration++;
}
slice = slice.Slice(iteration);
pos += iteration;
charloop_ending_pos = pos;
goto CharLoopEnd;
CharLoopBacktrack:
if (Utilities.s_hasTimeout)
{
base.CheckTimeout();
}
if (charloop_starting_pos >= charloop_ending_pos ||
(charloop_ending_pos = inputSpan.Slice(charloop_starting_pos, charloop_ending_pos - charloop_starting_pos).LastIndexOfAny('b', 'c')) < 0)
{
return false; // The input didn't match.
}
charloop_ending_pos += charloop_starting_pos;
pos = charloop_ending_pos;
slice = inputSpan.Slice(pos);
CharLoopEnd:
//}
// Advance the next matching position.
if (base.runtextpos < pos)
{
base.runtextpos = pos;
}
// Match a character in the set [bc].
if (slice.IsEmpty || (((uint)slice[0]) - 'b' > (uint)('c' - 'b')))
{
goto CharLoopBacktrack;
}
// The input matched.
pos++;
base.runtextpos = pos;
base.Capture(0, matchStart, pos);
return true;
}You can see the structure of the backtracking in the code, with a CharLoopBacktrack label emitted for where to backtrack to and a goto used to jump to that location when a subsequent portion of the regex fails.
If you look at the code implementing RegexCompiler and the source generator, they will look extremely similar: similarly named methods, similar call structure, even similar comments throughout the implementation. For the most part, they spit identical code, albeit one in IL and one in C#. Of course, the C# compiler is then responsible for translating the C# into IL, so the resulting IL in both cases likely won't be identical. In fact, the source generator relies on that in various cases, taking advantage of the fact that the C# compiler will further optimize various C# constructs. There are a few specific things the source generator will thus produce more optimized matching code for than does RegexCompiler. For example, in one of the previous examples, you can see the source generator emitting a switch statement, with one branch for 'a' and another branch for 'b'. Because the C# compiler is very good at optimizing switch statements, with multiple strategies at its disposal for how to do so efficiently, the source generator has a special optimization that RegexCompiler does not. For alternations, the source generator looks at all of the branches, and if it can prove that every branch begins with a different starting character, it will emit a switch statement over that first character and avoid outputting any backtracking code for that alternation (since if every branch has a different starting first character, once we enter the case for that branch, we know no other branch could possibly match).
Here's a slightly more complicated example of that. In .NET 7, alternations are more heavily analyzed to determine whether it's possible to refactor them in a way that will make them more easily optimized by the backtracking engines and that will lead to simpler source-generated code. One such optimization supports extracting common prefixes from branches, and if the alternation is atomic such that ordering doesn't matter, reordering branches to allow for more such extraction. We can see the impact of that for a weekday pattern Monday|Tuesday|Wednesday|Thursday|Friday|Saturday|Sunday, which produces a matching function like this:
private bool TryMatchAtCurrentPosition(ReadOnlySpan<char> inputSpan)
{
int pos = base.runtextpos;
int matchStart = pos;
ReadOnlySpan<char> slice = inputSpan.Slice(pos);
// Match with 5 alternative expressions, atomically.
{
if (slice.IsEmpty)
{
return false; // The input didn't match.
}
switch (slice[0])
{
case 'M':
// Match the string "onday".
if (!slice.Slice(1).StartsWith("onday"))
{
return false; // The input didn't match.
}
pos += 6;
slice = inputSpan.Slice(pos);
break;
case 'T':
// Match with 2 alternative expressions, atomically.
{
if ((uint)slice.Length < 2)
{
return false; // The input didn't match.
}
switch (slice[1])
{
case 'u':
// Match the string "esday".
if (!slice.Slice(2).StartsWith("esday"))
{
return false; // The input didn't match.
}
pos += 7;
slice = inputSpan.Slice(pos);
break;
case 'h':
// Match the string "ursday".
if (!slice.Slice(2).StartsWith("ursday"))
{
return false; // The input didn't match.
}
pos += 8;
slice = inputSpan.Slice(pos);
break;
default:
return false; // The input didn't match.
}
}
break;
case 'W':
// Match the string "ednesday".
if (!slice.Slice(1).StartsWith("ednesday"))
{
return false; // The input didn't match.
}
pos += 9;
slice = inputSpan.Slice(pos);
break;
case 'F':
// Match the string "riday".
if (!slice.Slice(1).StartsWith("riday"))
{
return false; // The input didn't match.
}
pos += 6;
slice = inputSpan.Slice(pos);
break;
case 'S':
// Match with 2 alternative expressions, atomically.
{
if ((uint)slice.Length < 2)
{
return false; // The input didn't match.
}
switch (slice[1])
{
case 'a':
// Match the string "turday".
if (!slice.Slice(2).StartsWith("turday"))
{
return false; // The input didn't match.
}
pos += 8;
slice = inputSpan.Slice(pos);
break;
case 'u':
// Match the string "nday".
if (!slice.Slice(2).StartsWith("nday"))
{
return false; // The input didn't match.
}
pos += 6;
slice = inputSpan.Slice(pos);
break;
default:
return false; // The input didn't match.
}
}
break;
default:
return false; // The input didn't match.
}
}
// The input matched.
base.runtextpos = pos;
base.Capture(0, matchStart, pos);
return true;
}Note how Thursday was reordered to be just after Tuesday, and how for both the Tuesday/Thursday pair and the Saturday/Sunday pair, we end up with multiple levels of switches. In the extreme, if you were to create a long alternation of many different words, the source generator would end up emitting the logical equivalent of a trie, reading each character and switch'ing to the branch for handling the remainder of the word.
At the same time, the source generator has other issues to contend with that simply don't exist when outputting to IL directly. If you look a couple of code examples back, you can see some braces somewhat strangely commented out. That's not a mistake. The source generator is recognizing that, if those braces weren't commented out, the structure of the backtracking would be relying on jumping from outside of a scope to a label defined inside of that scope; such a label would not be visible to such a goto and the code would fail to compile. Thus, the source generator needs to avoid there actually being a scope in the way. In some cases, it'll simply comment out the scope as was done here. In other cases where that's not possible, it may sometimes avoid constructs that require scopes (e.g. a multi-statement if block) if doing so would be problematic.
The source generator handles everything RegexCompiler handles, with one exception. Earlier in this post we discussed the new approach to handling RegexOptions.IgnoreCase, how the implementations now use a casing table to generate sets at construction time, and how IgnoreCase backreference matching needs to consult that casing table. That table is internal to System.Text.RegularExpressions.dll, and for now at least, code external to that assembly (including code emitted by the source generator) does not have access to it. That makes handling IgnoreCase backreferences a challenge in the source generator. We could choose to also output the casing table if it's required, but it's quite a hefty chunk of data to blit into consuming assemblies. So at least for now, IgnoreCase backreferences are the one construct not supported by the source generator that is supported by RegexCompiler. If you try to use a pattern that has one of these (which, at least according to our research, are very rare), the source generator won't emit a custom implementation and will instead fall back to caching a regular Regex instance:
Also, neither RegexCompiler nor the source generator support the new RegexOptions.NonBacktracking. If you specify RegexOptions.Compiled | RegexOptions.NonBacktracking, the Compiled flag will just be ignored, and if you specify NonBacktracking to the source generator, it will similarly fall back to caching a regular Regex instance. (It's possible the source generator will support NonBacktracking as well in the future, but that's unlikely to happen for .NET 7.)
Finally, the $10 million dollar question: when should you use the source generator? The general guidance is, if you can use it, use it. If you're using Regex today in C# with arguments known at compile-time, and especially if you're already using RegexOptions.Compiled (because the regex has been identified as a hot spot that would benefit from faster throughput), you should prefer to use the source generator. The source generator will give your regex all the throughput benefits of RegexOptions.Compiled, the startup benefits of not having to do all the regex parsing, analysis, and compilation at runtime, the option of using ahead-of-time compilation with the code generated for the regex, better debugability and understanding of the regex, and even the possibility to reduce the size of your trimmed app by trimming out large swaths of code associated with RegexCompiler (and potentially even reflection emit itself). And even if used with an option like RegexOptions.NonBacktracking for which it can't yet generate a custom implementation, it will still helpfully emit caching, XML comments describing the implementation, and so on, such that it's still valuable. The main downside of the source generator is that it is emitting additional code into your assembly, so there's the potential for increased size; the more regexes in your app and the larger they are, the more code will be emitted for them. In some situations, just as RegexOptions.Compiled may be unnecessary, so too may be the source generator, e.g. if you have a regex that's needed only rarely and for which throughput doesn't matter, it could be more beneficial to just rely on the interpreter for that sporadic usage. However, we're so confident in the general "if you can use it, use it" guidance that .NET 7 will also include an analyzer that identifies use of Regex that could be converted to the source generator, and a fixer that does the conversion for you:
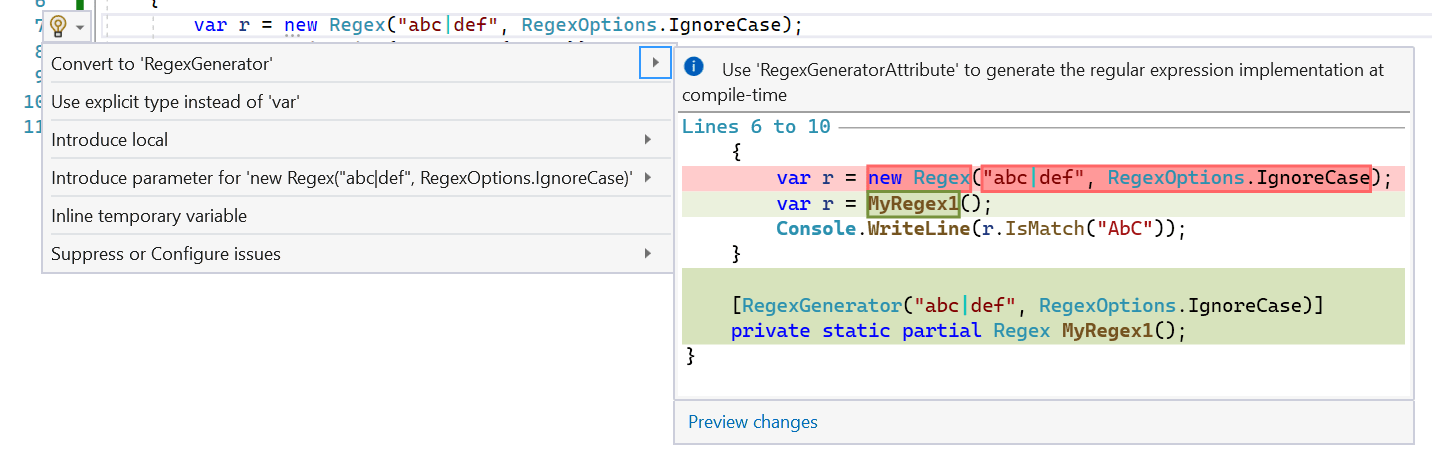
Spans
Span<T> and ReadOnlySpan<T> have fundamentally transformed how code gets written in .NET, especially in higher-performance scenarios. These types make it easy to implement a single algorithm that's able to process strings, arrays, slices of data, stack-allocated state, or native memory, all behind a fast, optimized veneer. Hundreds of methods in the core libraries now accept spans, and ever since spans were introduced in .NET Core 2.1, developers have been asking for span support in Regex. This has been challenging to accomplish for two main reasons.
The first issue is Regex's extensibility model. The aforementioned Regex.CompileToAssembly generated a Regex-derived type that needed to be able to plug its logic into the general scaffolding of the regex system, e.g. you call a method on the Regex instance, like IsMatch, and that needs to find its way into the code emitted by CompileToAssembly. To achieve that, System.Text.RegularExpressions exposes an abstract RegexRunner type, which exposes a few abstract methods, most importantly FindFirstChar and Go. All of the engines plug into the execution via RegexRunner: the internal RegexInterpreter derives from RegexRunner and overrides those methods to implement the regex by interpretering the opcodes/operands written during construction, the NonBacktracking engine has a type that derives from RegexRunner, and RegexCompiler ends up creating delegates to DynamicMethods it reflection emits and creates an instance of a type derived from RegexRunner that will invoke those delegates. The source generator also emits code that plugs in the same way. The problem as it relates to span, though, is how to get the span into these methods. RegexRunner is a class and can't store a span as a field, and these FindFirstChar and Go methods were long-since defined and don't accept a span as an argument. As such, with the shape of this model as it's been defined for nearly 20 years, there's no way to get a span into the code that would process it.
The second issue is around the API for returning results. IsMatch is simple: it just returns a bool. But Match and Matches are both based on returning objects that represent matches, and such objects can't hold a reference to a span. That's an issue, because the mechanism by which the current model supports iterating through results is lazy, with the first match being computed, and then using the resulting Match's NextMatch() method to pick up where the first operation left off. If that Match can't store the input span, it can't provide it back to the engine for subsequent matching.
In .NET 7, we've tackled these issues, such that Regex in .NET 7 now supports span inputs, at least with some of the APIs. Overloads of IsMatch accept ReadOnlySpan<char>, as do overloads of two new methods: Count and EnumerateMatches. This means you can now use the .NET Regex type with data stored in a char[], or data from a char* passed via interop, or data from a ReadOnlySpan<char> sliced from a string, or from anywhere else you may have received a span.
The new Count method takes a string or a ReadOnlySpan<char>, and returns an int for how many matches exist in the input text; previously if you wanted to do this, you could have written code that iterated using Match and NextMatch(), but the built-in implementation is leaner and faster (and doesn't require you to have to write that out each time you need it, and works with spans). The performance benefits are obvious from a microbenchmark:
private Regex _r = new Regex("a", RegexOptions.Compiled);
private string _input = new string('a', 1000);
[Benchmark(Baseline = true)]
public int Match()
{
int count = 0;
Match m = _r.Match(_input);
while (m.Success)
{
count++;
m = m.NextMatch();
}
return count;
}
[Benchmark]
public int Count() => _r.Count(_input);which on my machine yields results like this:
| Method | Mean | Ratio | Allocated |
|---|---|---|---|
| Match | 75.00 us | 1.00 | 208000 B |
| Count | 32.07 us | 0.43 | - |
The more interesting method, though, is EnumerateMatches. EnumerateMatches accepts a string or a ReadOnlySpan<char> and returns a ref struct enumerator that can store the input span and thus is able to lazily enumerate all the matches in the input.
using System.Text.RegularExpressions;
ReadOnlySpan<char> text = "Shall I compare thee to a summer’s day";
foreach (ValueMatch m in Regex.EnumerateMatches(text, @"\b\w+\b"))
{
Console.WriteLine($"Word: {text.Slice(m.Index, m.Length)}");
}One of the interesting things about both Count and EnumerateMatches (and the existing Replace when not employing backreferences in the replacement pattern) is that they can be much more efficient than Match or Matches in terms of the work required for an engine. In particular, the NonBacktracking engine is implemented in a fairly pay-for-play manner: the less information you need, the less work it has to do. So with IsMatch only requiring the engine to compute whether there exists a match, NonBacktracking can get away with doing much less work than for Match, where it needs to compute the exact offset and length of the match and also compute all of the subcaptures. Neither Count nor EnumerateMatches requires computing the captures information, however, and thus can save NonBacktracking a non-trivial amount of work. Here's a microbenchmark to highlight the differences:
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
using System.Text.RegularExpressions;
[MemoryDiagnoser]
public class Program
{
static void Main(string[] args) => BenchmarkSwitcher.FromAssembly(typeof(Program).Assembly).Run(args);
private static string s_text = """
Shall I compare thee to a summer’s day?
Thou art more lovely and more temperate:
Rough winds do shake the darling buds of May,
And summer’s lease hath all too short a date;
Sometime too hot the eye of heaven shines,
And often is his gold complexion dimm'd;
And every fair from fair sometime declines,
By chance or nature’s changing course untrimm'd;
But thy eternal summer shall not fade,
Nor lose possession of that fair thou ow’st;
Nor shall death brag thou wander’st in his shade,
When in eternal lines to time thou grow’st:
So long as men can breathe or eyes can see,
So long lives this, and this gives life to thee.
""";
private readonly Regex _words = new Regex(@"\b(\w+)\b", RegexOptions.NonBacktracking);
[Benchmark]
public int Count() => _words.Count(s_text);
[Benchmark]
public int EnumerateMatches()
{
int count = 0;
foreach (ValueMatch _ in _words.EnumerateMatches(s_text))
{
count++;
}
return count;
}
[Benchmark]
public int Match()
{
int count = 0;
Match m = _words.Match(s_text);
while (m.Success)
{
count++;
m = m.NextMatch();
}
return count;
}
}which on my machine yields results like these:
| Method | Mean | Allocated |
|---|---|---|
| Count | 26,736.0 ns | - |
| EnumerateMatches | 28,680.5 ns | - |
| Match | 82,351.7 ns | 30256 B |
Note that Count and EnumerateMatches are much faster than Match, as Match needs to compute the captures information, whereas Count and EnumerateMatches only need to compute the bounds of the match. Also note that both Count and EnumerateMatches end up being ammortized allocation-free.
So, spans are supported, yay. You can see we overcame the second highlighted issue by creating a new EnumerateMatches method that doesn't return a class Match and instead returns a ref struct ValueMatch. But what about the first issue? To address that, we introduced a new virtual Scan(ReadOnlySpan<char>) method on RegexRunner, and changed the existing abstract methods to be virtual (they now exist only for compatibility with any CompileToAssembly assemblies that might still be in use), such that Scan is the only method that now need be overridden by the source generator. If we try a sample like:
using System.Text.RegularExpressions;
partial class Program
{
public static void Main() => Console.WriteLine(Example().IsMatch("aaaabbbb"));
[GeneratedRegex(@"a*b", RegexOptions.IgnoreCase, -1)]
private static partial Regex Example();
}we can see the source generator spits out a RegexRunner-derived type that overrides Scan:
/// <summary>Scan the <paramref name="inputSpan"/> starting from base.runtextstart for the next match.</summary>
/// <param name="inputSpan">The text being scanned by the regular expression.</param>
protected override void Scan(ReadOnlySpan<char> inputSpan)
{
// Search until we can't find a valid starting position, we find a match, or we reach the end of the input.
while (TryFindNextPossibleStartingPosition(inputSpan) &&
!TryMatchAtCurrentPosition(inputSpan) &&
base.runtextpos != inputSpan.Length)
{
base.runtextpos++;
}
}With that, the public APIs on Regex can accept a span and pass it all the way through to the engines for them to process the input. And the engines are all then fully implemented in terms of only span. This has itself served to clean up the implementations nicely. Previously, for example, the implementations needed to be concerned with tracking both a beginning and ending position within the supplied string, but now the span that's passed in represents the entirety of the input to be considered, so the only bounds that are relevant are those of the span itself.
Vectorization
As noted earlier when talking about IgnoreCase, vectorization is the idea that we can process multiple pieces of data at the same time with the same instructions (also known as "SIMD", or "single instruction multiple data"), thereby making the whole operation go much faster. .NET 5 introduced a bunch of places where vectorization was employed. .NET 7 takes that significantly further.
Leading Vectorization
One of the most important places for vectorization in a regex engine is when finding the next location a pattern could possibly match. For longer input text being searched, the time to find matches is frequently dominated by this aspect. As such, as of .NET 6, Regex had various tricks in place to get to those locations as quickly as possible:
- Anchors. For patterns that began with an anchor, it could either avoid doing any searching if there was only one place the pattern could possibly begin (e.g. a "beginning" anchor, like
^orA), and it could skip past text it knew couldn't match (e.g.IndexOf('\n')for a "beginning-of-line" anchor if not currently at the beginning of a line). - Boyer-Moore. For patterns beginning with a sequence of at least two characters (case-sensitive or case-insensitive), it could use a Boyer-Moore search to find the next occurrence of that sequence in the input text.
- IndexOf(char). For patterns beginning with a single case-sensitive character, it could use
IndexOf(char)to find the next possible match location. - IndexOfAny(char, char, ...). For patterns beginning with one of only a few case-sensitive characters, it could use
IndexOfAny(...)with those characters to find the next possible match location.
These optimizations are all really useful, but there are many additional possible solutions that .NET 7 now takes advantage of:
- Goodbye, Boyer-Moore.
Regexhas used the Boyer-Moore algorithm sinceRegex's earliest days; theRegexCompilereven emitted a customized implementation in order to maximize throughput. However, Boyer-Moore was created at a time when vector instruction sets weren't yet a reality. Most modern hardware can examine 8 or 16 16-bitchars in just a few instructions, whereas with Boyer-Moore, it's rare to be able to skip that many at a time (the most it can possibly skip at a time is the length of the substring for which it's searching). In the aforementioned corpus of ~19,000 regular expressions, ~50% of those expressions that begin with a case-sensitive prefix of at least two characters have a prefix less than or equal to four characters, and ~75% are less than or equal to eight characters. Moreover, the Boyer-Moore algorithm works by choosing a single character to examine in order to perform each jump, but a well-vectorized algorithm can simultaneously compare multiple characters, such as the first and last in the prefix (as described in SIMD-friendly algorithms for substring searching), enabling it to stay in the inner vectorized loop longer. In .NET 7,IndexOfperforming an ordinal search for a string has been significantly improved with such tricks, and now in .NET 7,RegexusesIndexOfrather than Boyer-Moore, the implementation of which has been deleted (this was inspired by Rust's regex crate making a similar change last year). You can see the impact of this on a microbenchmark like the following, which is finding every word in a document, creating aRegexfor that word, and then using eachRegexto find all occurrences of each word in the document (this would be an ideal use for the newCountmethod, but I'm not using it here as it doesn't exist in the previous releases being compared):private string _text; private Regex[] _words; [Params(false, true)] public bool IgnoreCase { get; set; } [GlobalSetup] public async Task Setup() { using var hc = new HttpClient(); _text = await hc.GetStringAsync(@"https://www.gutenberg.org/files/1661/1661-0.txt"); _words = Regex .Matches(_text, @"\b\w+\b") .Cast<Match>() .Select(m => m.Value) .Distinct(IgnoreCase ? StringComparer.OrdinalIgnoreCase : StringComparer.Ordinal) .Select(s => new Regex(Regex.Escape(s), RegexOptions.Compiled | (IgnoreCase ? RegexOptions.IgnoreCase | RegexOptions.CultureInvariant : RegexOptions.None))) .ToArray(); } [Benchmark] public int FindAllOccurrencesOfAllWords() { int count = 0; foreach (Regex word in _words) { Match m = word.Match(_text); while (m.Success) { count++; m = m.NextMatch(); } } return count; }On my machine, I get numbers like this:
Method Runtime IgnoreCase Mean Ratio FindAllOccurrencesOfAllWords .NET Framework 4.8 False 7,657.1 ms 1.00 FindAllOccurrencesOfAllWords .NET 6.0 False 5,056.5 ms 0.66 FindAllOccurrencesOfAllWords .NET 7.0 False 522.3 ms 0.07 FindAllOccurrencesOfAllWords .NET Framework 4.8 True 12,624.1 ms 1.00 FindAllOccurrencesOfAllWords .NET 6.0 True 5,649.4 ms 0.45 FindAllOccurrencesOfAllWords .NET 7.0 True 1,649.1 ms 0.13 Even when compared against an optimized string searching algorithm like Boyer-Moore, this really highlights the power of vectorization.
- IndexOfAny in More Cases. As noted, .NET 6 supports using
IndexOfAnyto find the next matching location when a match can begin with a small set, specifically a set with two or three characters in it. This limit was chosen becauseIndexOfAnyonly has public overloads that take two or three values. However,IndexOfAnyalso has an overload that takes aReadOnlySpan<T>of the values to find, and as an implementation detail, it actually vectorizes the search for up to five. So in .NET 7, we'll use that span-based overload for sets with four or five characters, expanding the reach of this valuable optimization.private static Regex s_regex = new Regex(@"Surname|(Last[_]?Name)", RegexOptions.Compiled | RegexOptions.IgnoreCase); private static string s_text = @"We're looking through text that might contain a first or last name."; [Benchmark] public bool IsMatch() => s_regex.IsMatch(s_text);Method Runtime Mean Ratio IsMatch .NET Framework 4.8 2,429.02 ns 1.00 IsMatch .NET 6.0 294.79 ns 0.12 IsMatch .NET 7.0 82.84 ns 0.03 - Fixed-Distance Sets. Just looking at what starts a pattern can be limiting. Consider a pattern like this one, which could be used to match United States social security numbers:
d{3}-d{2}-d{4}. Even if\dmatched only 10 possible characters (it actually matches any Unicode digit, which is closer to 370 characters), that's more difficult to vectorize a search for. However, it's trivial to vectorize a search for'-'.Regexin .NET 7 is now able to compute sets of characters that can exist at fixed-distance offsets from the beginning of the pattern (e.g. in this social security example, the set[-]exists at index 3 into the pattern), and it can then pick the one it expects will yield the fastest search. Here's a microbenchmark to show the impact this can have:private static string s_text = """ Shall I compare thee to a summer’s day? Thou art more lovely and more temperate: Rough winds do shake the darling buds of May, And summer’s lease hath all too short a date; Sometime too hot the eye of heaven shines, And often is his gold complexion dimm'd; And every fair from fair sometime declines, By chance or nature’s changing course untrimm'd; But thy eternal summer shall not fade, Nor lose possession of that fair thou ow’st; Nor shall death brag thou wander’st in his shade, When in eternal lines to time thou grow’st: So long as men can breathe or eyes can see, So long lives this, and this gives life to 012-34-5678. """; private static readonly Regex s_social = new Regex(@"\d{3}-\d{2}-\d{4}", RegexOptions.Compiled); [Benchmark] public bool ContainsSocial() => s_social.IsMatch(s_text);On my machine, I get numbers like this:
Method Runtime Mean Ratio ContainsSocial .NET Framework 4.8 8,614.77 ns 1.000 ContainsSocial .NET 6.0 566.84 ns 0.066 ContainsSocial .NET 7.0 67.41 ns 0.008 In other words, .NET 6 is more than 15x faster for this search than .NET Framework 4.8, and .NET 7 is still more than 8x faster than .NET 6 (almost 128x faster than .NET Framework 4.8).
- Non-Prefix String Search. Just as we can search for a string at the beginning of the pattern, we can also search for a string in the middle of the pattern. This is effectively an extension of the fixed-distance sets optimization: rather than searching for a single character, if there are multiple next to each other, we can search for all of them and enable
IndexOfto work its magic and minimize the number of false positives and the number of times we need to jump back and forth between the vectorized search and the matching logic. For example, the regex benchmarks at rust-leipzig/regex-performance contain a pattern[a-z]shing. The opening set is fairly large, with 26 possible characters, so the fixed-distance sets optimization would prefer to use one of the subsequently computed sets, each of which has just a single character. But it's even better to search for all of them ("shing") as a string.private static Regex s_regex = new Regex(@"[a-z]shing", RegexOptions.Compiled); private static string s_text = new HttpClient().GetStringAsync(@"https://github.com/rust-leipzig/regex-performance/blob/13915c5182f2662ed906cde557657037c0c0693e/3200.txt").Result; [Benchmark] public int SubstringSearch() { int count = 0; Match m = s_regex.Match(s_text); while (m.Success) { count++; m = m.NextMatch(); } return count; }This produces numbers like this on my machine:
Method Runtime Mean Ratio SubstringSearch .NET Framework 4.8 3,625.875 us 1.000 SubstringSearch .NET 6.0 976.662 us 0.269 SubstringSearch .NET 7.0 9.477 us 0.003 showing that, for this test, .NET 7 is an enormous ~103x faster than .NET 6, and ~383x faster than .NET Framework 4.8. This support is also valuable even in more complicated patterns. Consider this pattern from Rust's regex performance tests:
(?m)^Sherlock Holmes|Sherlock Holmes$. The(?m)inline modifier is the same as specifyingRegexOptions.Multiline, which changes the meaning of the^and$anchors to be beginning-of-line and end-of-line, respectively. Thus, this is looking for "Sherlock Holmes" at either the beginning of a line or the end of a line. Either way, though, we can search for "Sherlock Holmes" in each line (noting, too, that the lines in this input are fairly short). I've been showing mostly benchmarks withRegexOptions.Compiled, but to highlight that these optimizations benefit the interpreter as well, I'll leave that option off here:private static Regex s_sherlock = new Regex(@"(?m)^Sherlock Holmes|Sherlock Holmes$"); private static string s_text = new HttpClient().GetStringAsync(@"https://raw.githubusercontent.com/rust-lang/regex/b217bfebd2e5b253213c3d5c4a0ad82548c3037e/bench/src/data/sherlock.txt").Result; [Benchmark] public int Match() { int count = 0; Match m = s_sherlock.Match(s_text); while (m.Success) { count++; m = m.NextMatch(); } return count; }which on my machine produces:
Method Runtime Mean Ratio Match .NET Framework 4.8 1,080.80 us 1.00 Match .NET 6.0 94.13 us 0.09 Match .NET 7.0 52.29 us 0.05 - Literals After Loops. Consider a pattern like the simple email regex in the cross-language regex benchmarks at https://github.com/mariomka/regex-benchmark:
[\w.+-]+@[\w.-]+.[\w.-]+. There's no leading prefix here, and there's no small set we can vectorize a search for at a fixed distance from the beginning of the pattern, because of that pesky[\w.+-]+set loop at the beginning. But there are also some interesting things to notice here. Most importantly, there's an@following that loop, the loop has no upper bound, and the set being looped around can't match@. That means, even though the loop wasn't written as an atomic loop, it can be processed as one. We can search for the@, match backwards through the opening loop, and then if it's successful, continue the matching forward after the@. So rather than walking each character looking to see if it's in the set[\w.+-], we can vectorize a search for the@. Here's that mariomka/regex-benchmark benchmark extracted into a standalone benchmarkdotnet test:private static Regex s_email = new Regex(@"[\w.+-]+@[\w.-]+.[\w.-]+", RegexOptions.Compiled); private static string s_text = new HttpClient().GetStringAsync(@"https://raw.githubusercontent.com/mariomka/regex-benchmark/8e11300825fc15588e4db510c44890cd4f62e903/input-text.txt").Result; [Benchmark] public int Email() { int count = 0; Match m = s_email.Match(s_text); while (m.Success) { count++; m = m.NextMatch(); } return count; }which on my machine produces lovely numbers like this:
Method Runtime Mean Ratio Match .NET Framework 4.8 11,019,362.9 us 1.00 Match .NET 6.0 48,723.8 us 0.048 Match .NET 7.0 623.0 us 0.001 That's not a copy-and-paste error. .NET 6 is ~21x faster than .NET Framework 4.8 here, primarily because of optimizations added in .NET 5 to precompute set lookups for ASCII characters, and .NET 7 is ~78x faster than .NET 6 (and a whopping ~1,636x faster than .NET Framework 4.8) because of this vectorization. This optimization was inspired by a nicely-written description of what nim-regex does for similar patterns, highlighting how many regex engines are turning to this kind of vectorization for improved performance (HyperScan has long been a leader in this area, in particular for domains focused on streaming, such as intrusion prevention systems).
- Trailing Anchors. Since the beginning of
Regexin .NET, it's applied anchor-based optimizations, like the ones cited earlier. However, these optimizations have all been based on leading anchors, i.e. anchors at the beginning of the pattern. It's largely ignored trailing anchors, such as$at the end of the pattern. But such anchors are potentially huge sources of performance improvements, in particular for patterns that aren't also anchored at the beginning. .NET 7 now looks for patterns that end with anchors and also computes whether there's a maximum length a pattern could match (.NET 5 added an optimization to compute the minimum length a pattern could match, which is used primarily to determine whether there's even enough input left to try to match); if it has both a trailing end anchor and a maximum match length, the engine can immediately jump to that offset from the end, as there's no point trying to match anything before then. It's almost unfair to show a benchmark and resulting improvements here... but these numbers are just plain fun, so I will:private static Regex s_endsInDigits = new Regex(@"\d{5}$|\d{5}-\d{4}$", RegexOptions.Compiled); private static string s_text = new HttpClient().GetStringAsync(@"https://raw.githubusercontent.com/mariomka/regex-benchmark/8e11300825fc15588e4db510c44890cd4f62e903/input-text.txt").Result; [Benchmark] public bool IsMatch() => s_endsInDigits.IsMatch(s_text);On my machine, I get:
Method Runtime Mean Ratio IsMatch .NET Framework 4.8 105,698,117.33 ns 1.000 IsMatch .NET 6.0 16,033,030.00 ns 0.152 IsMatch .NET 7.0 34.47 ns 0.000 Making operations faster is valuable. Entirely eliminating unnecessary work is priceless.
- Better Leading Anchors. Consider a pattern like
^abc. Every previous version ofRegexwill notice that this pattern leads with a beginning anchor, and will use that to root the match at the beginning of the input, avoiding the unnecessary expense of trying to match the pattern elsewhere in the input when it's guaranteed to not. However, now consider a pattern like^abc|^def. Previous versions ofRegexwould fail to notice that the pattern was still rooted, since every possible branch of the alternation begins with the same anchor. In .NET 7, the optimizer does a better job of properly searching for leading anchors, and will see that this pattern is the equivalent of^(?:abc|def), which it knows how to optimize. This can make matching way faster. Consider this Dutch century pattern:(^eeuw|^centennium)b. The implementation previously wouldn't have optimized for that leading^, but now in .NET 7 it will:private static Regex s_centuryDutch = new Regex(@"(^eeuw|^centennium)b", RegexOptions.Compiled);private static string s_text = """ Shall I compare thee to a summer’s day? Thou art more lovely and more temperate: Rough winds do shake the darling buds of May, And summer’s lease hath all too short a date; Sometime too hot the eye of heaven shines, And often is his gold complexion dimm'd; And every fair from fair sometime declines, By chance or nature’s changing course untrimm'd; But thy eternal summer shall not fade, Nor lose possession of that fair thou ow’st; Nor shall death brag thou wander’st in his shade, When in eternal lines to time thou grow’st: So long as men can breathe or eyes can see, So long lives this, and this gives life to thee. """; [Benchmark] public bool IsMatch() => s_centuryDutch.IsMatch(s_text);
Method Runtime Mean Ratio IsMatch .NET Framework 4.8 9,949.83 ns 1.000 IsMatch .NET 6.0 1,752.20 ns 0.175 IsMatch .NET 7.0 34.23 ns 0.003
Note that most of these optimizations apply regardless of the engine being used, whether it's the interpreter, RegexOptions.Compiled, the source generator, or RegexOptions.NonBacktracking. For the backtracking engines, all of these find optimizations apply as part of the scan loop. The loop essentially repeatedly calls a TryFindNextStartingPosition method, and for each viable location found, invokes the TryMatchAtCurrentPosition method; these optimizations form the basis of the TryFindNextStartingPosition method. For the non-backtracking engine, as mentioned previously, it's essentially just reading the next character from the input and using that to determine what node in a graph to transition to. But one or more nodes in that graph are considered a "starting state", which is essentially a state that's guaranteed not to be part of any match. In such states, the non-backtracking engine will use the same TryFindNextStartingPosition that the interpreter does in order to jump past as much text as possible that's guaranteed not to be part of any match.
It's also important to note that, as with almost any optimization, when one things gets faster, something else gets slower. Hopefully the thing that regresses is rare and doesn't regress by much, and the thing that gets faster is so much faster and so much more common that the upsides completely outweigh the downsides. This is the case with some of these optimizations. It's possible, for example, that we use IndexOf in cases where we didn't previously, and it turns out that the IndexOf for a given input wasn't actually necessary, because the very first character in the input matches; in such a case, we will have paid the overhead for invoking IndexOf (overhead that is very small but not zero) unnecessarily. Thankfully, these wins are so huge and the costs so small, that they're almost always the right tradeoff, and in cases where they're not, the losses are tiny and have workarounds (e.g. if you know the input will match at the beginning, using a beginning anchor).
Internal Vectorization
Finding the next possible location for a match isn't the only place vectorization is useful; it's also valuable inside the core matching logic, in various ways. .NET 5 added a few such optimizations here:
- "not" loops. Consider an expression like
abc.*def. With a backtracking engine, this is going to match"abc", then consume anything other than a'\n'greedily, and then backtrack (giving back some of what was greedily matched) until it finds"def". Thus, the forward portion of that match can useIndexOf('\n')to find the initial end of the loop. Similarly,abc[^-:]*defwill try to match"abc", then greedily consume anything other than'-'and':'characters, and then backtrack until it finds"def". Here as well, the forward portion of that match can useIndexOfAny('-', ':'). - Singleline
.*. When you specify theRegexOptions.Singlelineoption, that has the sole effect of changing.in a pattern from meaning "match anything other than'\n'to "match anything". With a.*loop withRegexOptions.Singlelinethen, that really says "greedily consume everything", and the implementation needn't even useIndexOforIndexOfAny... it can simply jump to the end of the input.
.NET 7 adds more:
- Loop Backtracking. The previous "not" loop example of
abc.*defis interesting. I highlighted that this will match the"abc", then useIndexOf('\n')to find the end of the greedy consumption, and then backtrack looking for"def". In .NET 6, such backtracking would happen one character at a time. But in .NET 7, we now useLastIndexOf("def")to find the next possible place to run the remainder of the pattern, allowing that search to be vectorized. This extends not just to multiple-character sequences and single characters following such loops, but also to sets. If the pattern were insteadabc.*[def], the compiler and source generator will instead emit a call toLastIndexOfAny('d', 'e', 'f'). Here's an example microbenchmark:private static Regex s_regex = new Regex(@"abc.*def", RegexOptions.Compiled); private static string s_text = @"abcdef this is a test to see what happens when it needs to backtrack all the way back"; [Benchmark] public bool IsMatch() => s_regex.IsMatch(s_text);and we can see the effect this vectorization has on the numbers I get back:
Method Runtime Mean Ratio IsMatch .NET Framework 4.8 627.48 ns 1.00 IsMatch .NET 6.0 354.59 ns 0.57 IsMatch .NET 7.0 71.19 ns 0.11 Throughput here almost doubles going from .NET Framework 4.8 to .NET 6, primarily because the
.*matching is performed in .NET 6 using anIndexOf('\n')rather than matching each next character consumed by the loop individually. And then throughput gets ~5x faster again going to .NET 7, as now not only is the forward direction vectorized withIndexOf('\n'), the backtracking direction gets vectorized withLastIndexOf("def"). - Lazy Loop Backtracking. Consider a pattern like
<.*?>. This is looking for an opening'<', then lazily consuming as many characters other than'\n'as it can until the next'>'. In .NET 6, this would dutifully backtrack one character at a time, consuming the next non-'\n'and then checking whether the current character is a'>', consuming the next non-'\n'and then checking whether the current character is a'>', and on. Now in .NET 7, this recognizes the operation for what it is, a search for either'\n'or'>', and will use anIndexOfAny('\n', '>')to speed up that search:private static Regex s_regex = new Regex(@"<.*?>", RegexOptions.Compiled); private static string s_text = @"This is a test <to see how well this does at finding the bracketed region using a lazy loop>."; [Benchmark] public bool IsMatch() => s_regex.IsMatch(s_text);Here I get these numbers:
Method Runtime Mean Ratio IsMatch .NET Framework 4.8 527.24 ns 1.00 IsMatch .NET 6.0 352.56 ns 0.67 IsMatch .NET 7.0 50.90 ns 0.10 - StartsWith. Going back to the earliest days of the
RegexCompiler, one of the main optimizations employed was to unroll various loops. For example, if a pattern contained the string"abcd", rather than emitting that as a loop over the string comparing each character with the input, it would emit it as a hardcoded check against'a', a hardcoded check against'b', and so on. This helps to avoid some of the loop overhead as well as the overhead associated with indexing into and reading from the pattern string. In .NET 5, this was improved upon by reading not just one character at a time, but either two or four at a time, reading and comparingInt32orInt64values rather than 16-bit character values, a process that can double or quadruple the matching time for such strings. This manual vectorization, however, has some downsides, especially in the face of the source generator. Such code is difficult to read and comprehend. On top of which, such operations need to be very careful about endianness. WithRegexCompiler, where the numerical comparison values were being computed in the same process that was then doing the same operation on the input, endianness isn't an issue as the endianness of the values computed at compilation time are guaranteed to be the same as the endianness of the machine at execution time. But with the source generator, the source generator could end up being run on a machine with one endianness and then executed on a machine with a different endianness, which means the generated code needs to be able to handle both. Since comparing against literal strings is a common task, in .NET 7 the Just-in-Time compiler (JIT) adds optimizations for methods likeStartsWithwhen passed a string literal. The JIT is now able to generate assembly code employing similar styles of vectorization, which means developers can just use methods likeStartsWithand get these optimizations for free. So can the source generator. So now in .NET 7, both theRegexCompilerand the source generator do the simple thing of just emitting calls toStartsWith, and in doing so get all the perf benefits of the vectorized comparisons, while also getting code that's very readable. Further, this applies toRegexOptions.IgnoreCaseas well. If theRegexCompilerand source generator find a sequence of sets that have pairs of ordinal-case-insensitive-equivalent ASCII letters, rather than emitting set comparisons for each, it will emit for the whole sequence a single call toStartsWithwithStringComparison.OrdinalIgnoreCase, and the JIT again will vectorize the processing of this literal. Meaning, we get nicely readable source and as good or better performance.private static Regex s_regex = new Regex(@"babcd", RegexOptions.Compiled | RegexOptions.IgnoreCase); private static string s_text = @"ABCD"; [Benchmark] public bool IsMatch() => s_regex.IsMatch(s_text);Method Runtime Mean Ratio IsMatch .NET Framework 4.8 222.85 ns 1.00 IsMatch .NET 6.0 62.61 ns 0.28 IsMatch .NET 7.0 44.54 ns 0.20 To see this in action, this is what the source generator emits for the TryMatchAtCurrentPosition method for the above regex:
/// <summary>Determine whether <paramref name="inputSpan"/> at base.runtextpos is a match for the regular expression.</summary> /// <param name="inputSpan">The text being scanned by the regular expression.</param> /// <returns>true if the regular expression matches at the current position; otherwise, false.</returns> private bool TryMatchAtCurrentPosition(ReadOnlySpan<char> inputSpan) { int pos = base.runtextpos; int matchStart = pos; ReadOnlySpan<char> slice = inputSpan.Slice(pos); // Match if at a word boundary. if (!Utilities.IsBoundary(inputSpan, pos)) { return false; // The input didn't match. } if ((uint)slice.Length < 4 || !slice.StartsWith("abcd", StringComparison.OrdinalIgnoreCase)) // Match the string "abcd" (ordinal case-insensitive) { return false; // The input didn't match. } // The input matched. pos += 4; base.runtextpos = pos; base.Capture(0, matchStart, pos); return true; }
Auto-Atomicity and Backtracking
In a backtracking engine, especially when matching inputs that force a lot of backtracking, that backtracking tends to be the dominating cost of the match operation itself. It's thus very beneficial to try to construct patterns in a way that avoids incurring backtracking as much as possible. One way a developer can do this is by manually using an atomic group, (?> ). Such an atomic group tells the engine that, regardless of what happens inside the group, once the group matches, it matches, and nothing after the group can backtrack into the group. For example, if you had the pattern a*b, and you try to match it against "aaaa", a backtracking engine might successfully match four 'a's, then try to match the 'b', see it doesn't match, so backtrack one, try to match there, it doesn't, backtrack again, etc. But if you instead wrote it as (?>a*)b, an engine will match the four 'a's as before, but then when it goes to match the 'b' and fails, there's nothing to backtrack to other than failing the whole match, since the loop is now atomic and doesn't give anything back.
Of course, using such atomic groups isn't something most developers are accustomed to doing. In recognition of that, and because it's easy to miss opportunities where atomicity could be used without negative impact, .NET 5 added some "auto-atomicity" optimizations, inspired by discussion in Jeffrey Friedl's seminal "Mastering Regular Expressions" book. Effectively, as part of optimizing the RegexNode tree from parsing the expression, the analyzer would look for loop and alternation constructs (which are where backtracking comes from) where backtracking wouldn't actually have a behavioral impact such that it could be eliminated. Let's look at the previous example of a*b again. After finding there's no 'b' to match, the engine can backtrack to see if it could match 'b' against something earlier in the input that had matched as part of the 'a*'. But there's nothing 'a' matches that 'b' could possibly match, hence all attempts at getting a match via backtracking here are for naught. In such cases, the optimizer can automatically upgrade the loop to being an atomic one. You can see this taking affect with the source generator... here's that same email regex used in a microbenchmark earlier:

Note that there's no atomic loop in the pattern as I wrote it in the GeneratedRegex attribute, but the IntelliSense comment is highlighting that both the first and third loop in this pattern are atomic. The analyzer has determined that there's no behavioral difference whether these are greedy as written or atomic, other than the negative perf implications of them being greedy; hence it's made them atomic.
However, the .NET 5 optimizations had some limitations. In particular, the optimizer would only look at a single node guaranteed to come immediately after the construct in question. So for example, with the expression a+b+c+, when analyzing the a+, it would only look at the b+. In that particular case, it's fine, because b+ is the same as bb*, guaranteeing there will be a b after the a+, and since a and b don't overlap, enabling the a+ to be made atomic. But now consider if our expression was instead a*b*c*. Now the b* is "nullable", meaning it can match the empty string, and that means the a* could actually be followed by whatever comes after the b*. At that point the optimizations from .NET 5 would just give up, and the a* would remain greedy. Now in .NET 7, the optimizer is able to continue processing the rest of the expression, and will see that the a* could be followed by either a b or c (or nothing), neither of which overlaps with a, so it can still be made atomic; in fact in this example, all of the loops will be made atomic.
private static Regex s_regex = new Regex(@"a*b*c*d*$", RegexOptions.Compiled);
private static string s_text = @"aaaaaaaaaaaaaaaaaz";
[Benchmark]
public bool IsMatch() => s_regex.IsMatch(s_text);| Method | Runtime | Mean | Ratio |
|---|---|---|---|
| IsMatch | .NET Framework 4.8 | 2,459.49 ns | 1.00 |
| IsMatch | .NET 6.0 | 1,701.23 ns | 0.69 |
| IsMatch | .NET 7.0 | 50.51 ns | 0.02 |
This applies to lazy loops as well (though due to their nature of preferring fewer rather than more iterations, there are also fewer circumstances in which they can be made atomic). So, for example, whereas in .NET 6 the expression a*?b*?c wouldn't be modified, in .NET 7 that will now be equivalent to (?>a*)(?>b*)c. The analyzer recognizes here that, for example, there's nothing b*? can match that will also match c. If the lazy loop were to match fewer bs than existed in the input, then the subsequent c wouldn't match (because it would try to match c against b), and the lazy loop would backtrack to add an additional iteration (that sounds funny, but whereas a greedy loop means match as much as possible and then backtrack to give some of it back, a lazy loop means match as little as possible and then backtrack to take more). The net result of that is when a lazy loop doesn't overlap with what's guaranteed to come next, it's indistinguishable from a greedy loop in terms of what it will end up matching, and so it can similarly be made into an atomic greedy loop.
private static Regex s_regex = new Regex(@"a*?b*?c$", RegexOptions.Compiled);
private static string s_text = @"aaaaaaaaaaaaaaaaabbbbbbbbbbbbbbbbz";
[Benchmark]
public bool IsMatch() => s_regex.IsMatch(s_text);| Method | Runtime | Mean | Ratio |
|---|---|---|---|
| IsMatch | .NET Framework 4.8 | 6,311.5 ns | 1.00 |
| IsMatch | .NET 6.0 | 4,166.5 ns | 0.66 |
| IsMatch | .NET 7.0 | 285.7 ns | 0.05 |
The optimizer is now also better at handling loops and lazy loops at the end of expressions. This can even result in some fairly surprising output from the source generator that might leave you scratching your head for a moment, e.g.
Why is the expression a*? described as "Match an empty string"? Because the optimizer sees that there's nothing after the a*?, which means nothing can backtrack into it, which means it can be made atomic. And lazy loops only add additional iterations either because they're required by the minimum bound or in response to backtracking, so a lazy loop that's atomic can be transformed into a loop with its upper bound lowered to its lower bound. A * loop has an upper bound of infinity and a lower bound of 0, which means a*? actually becomes a{0}, which is the same as empty. As a result, here's the entirety of the generated Scan method for this pattern:
/// <summary>Scan the <paramref name="inputSpan"/> starting from base.runtextstart for the next match.</summary>
/// <param name="inputSpan">The text being scanned by the regular expression.</param>
protected override void Scan(ReadOnlySpan<char> inputSpan)
{
// The pattern matches the empty string.
int pos = base.runtextpos;
base.Capture(0, pos, pos);
}Neat.
There's another valuable related optimization, and while not about auto-atomicity, it is about avoiding redoing the same computations when we know they won't produce any new payoff. In .NET 5, one of the optimizations added was an "update bumpalong" operation. The main Scan loop repeatedly invokes the logic to find the next possible match location, and then match there. If the match at that location fails, we need to "bump along" the position pointer to start from at least one past where we previously tried. But there are other situations where we might want to update that position pointer. Consider an expression like a*c invoked on input like "aaaaaaaabaaaaaaaac", in other words a sequence of as followed by a b and then a sequence of as followed by a c. We'll try to match at position 0, match all 8 as, but then find that what comes next isn't a c. Thanks to the auto-atomicity logic, this won't try to backtrack. But, when it goes back to the scan loop, the bumpalong logic will increment the position from 0 to 1, and start the match over there. Now the a* will match from position 1 and find 7 as, followed by a b rather than a c, and again we'll exit out to the Scan loop. You can see where this is going. We're trying to perform the same match at each of the first 8 positions, even though we actually can prove after the first that none of the rest will be successful. It won't be until we get past where the atomic loop examined that we might have a chance of finding a match. To help with this, .NET 5 added the optimization of updating the bumpalong, such that at the end of the opening atomic loop, the top-level bumpalong pointer would be updated to refer to the furthest position seen by the loop. That way, after the match at position 0 failed, we would next try not at position 1 but rather at position 8.
However, while valuable for leading atomic loops, this optimization ended up not helping with leading greedy loops. With an atomic loop, when we're done consuming and update the bumpalong, that's it, we never revisit the loop. But with a greedy loop, we'd start by updating the bumpalong to the furthest value seen, but then when we'd backtrack, we'd update the position to that lower index, and then we'd backtrack again and update the position to there, and so on. So even though we did in fact already examine all of the positions up to the updated location, the updated bumpalong pointer wouldn't retain its value, and we could end up redoing some or all of the matches again.
.NET 7 tweaks the logic to ensure, for appropriate greedy loops, that the update bumpalong ensures the position is as far into the input as it can be. It also is updated to support lazy loops in addition to greedy ones. The effect is evident from this (silly but representative) benchmark (note the capital 'D' amongst all the lowercase letters in the input):
private static readonly Regex s_greedy = new Regex(".*abcd", RegexOptions.Compiled);
private static readonly Regex s_lazy = new Regex(".*?abcd", RegexOptions.Compiled);
private static readonly string s_input = string.Concat(Enumerable.Repeat("abcDefghijklmnopqrstuvwxyz", 1000));
[Benchmark] public void Greedy() => s_greedy.IsMatch(s_input);
[Benchmark] public void Lazy() => s_lazy.IsMatch(s_input);Not having to redo the same work over and over and over is one of the best possible performance optimizations, as the numbers relay:
| Method | Runtime | Mean | Ratio |
|---|---|---|---|
| Greedy | .NET Framework 4.8 | 2,349,997.367 us | 1.000 |
| Greedy | .NET 6.0 | 1,304,689.850 us | 0.555 |
| Greedy | .NET 7.0 | 2.593 us | 0.000 |
| Lazy | .NET Framework 4.8 | 2,203,364.785 us | 1.000 |
| Lazy | .NET 6.0 | 1,389,932.393 us | 0.631 |
| Lazy | .NET 7.0 | 7.616 us | 0.000 |
Set Optimizations
After backtracking, the cost of determining whether a character is in a character class (a set) is often one of the largest costs associated with matching a regular expression. In versions of .NET prior to .NET 5, there were very few optimizations around this, however. Sets containing just one character, e.g. [a], or the negation of just one character, e.g. [^a], were well optimized, but beyond that, determining whether a character matched a character class involved a call to the protected RegexRunner.CharInClass method. This method accepts the character to be tested as well as a string-based description of the set, and returns a Boolean indicating whether the character is included. .NET 5 recognized that this is a significant cost, and added some very impactful optimizations here which were often the source of 3-4x speedups in regex when migrating to .NET 5, in particular for RegexOptions.Compiled. For example:
\dwould be emitted as a call tochar.IsDigit.\swould be emitted as a call tochar.IsWhiteSpace.- A range like
[0-9]would be emitted as the equivalent of C# like((uint)ch) - '0' <= (uint)('9' - '0'). - A single Unicode category like
\p{Lt}would be emitted as the equivalent of C# likechar.GetUnicodeCategory(ch) == UnicodeCategory.TitlecaseLetter. - A small set of just a couple of characters like
[ac]would be emitted as the equivalent of C# like(ch == 'a') | (ch == 'c').
Beyond those, however, the implementation would compute a 128-bit ASCII bitmap (stored as an 8-character string) that it could use to quickly answer the question of set inclusion for ASCII characters, and would then only fall back to calling the original RegexRunner.CharInClass if none of the special-cases handled the set and an input character was non-ASCII. For example, the character class [\w\s], which contains all Unicode word characters and all Unicode spaces, will yield a check equivalent to:
ch < 128 ? ("\u3e00\u0000\u0001\u03ff\ufffe\u87ff\ufffe\u07ff"[ch >> 4] & (1 << (ch & 0xF))) != 0 : !RegexRunner.CharInClass((char)ch, "\u0000\u0000\u000B\u0000\u0002\u0004\u0005\u0003\u0001\u0006\u0009\u0013\u0000\u0064"))That first string isn't really text, but rather 128 bits representing the ASCII characters, with a 1 bit for each that's in the set and a 0 bit for each that's not... 8 characters in a string is just a convenient way to store the data.
There are a variety of ways we can improve on this, though, and .NET 7 does:
- .NET 6 already optimized
.withRegexOptions.Singlelineto be the equivalent oftrue. However, it turns out in practice a lot of developers end up using somewhat odd looking sets like[\s\S],[\w\W], and[\d\D]to be the equivalent of "match anything", yet the code generator didn't recognize that these sets were all-inclusive. Now it does. - .NET 6 optimizes sets that are simply a single Unicode category, as shown previously. Now in the source generator, .NET 7 supports any number of categories, emitting a check as a
switchexpression that enables the C# compiler's optimizations around switch expressions to kick in. For example,\p{L}will now be emitted as:char.GetUnicodeCategory(ch) switch { UnicodeCategory.LowercaseLetter or UnicodeCategory.ModifierLetter or UnicodeCategory.OtherLetter or UnicodeCategory.TitlecaseLetter or UnicodeCategory.UppercaseLetter => true, _ => false })which the C# compiler in turn will optimize to the equivalent of
(uint)char.GetUnicodeCategory(ch) <= 4uThe C# compiler doesn't yet optimize pattern matching to the same degree, but when it does, this will likely change to be based on an
isinstead of aswitch. - .NET 6 optimizes small sets of characters as previously shown, but not small negated sets of characters. Now in .NET 7 if you write a set like
[^14], you'll get a check like(ch != '1') & (ch != '4'). - .NET 7 also now recognizes the very common pattern of two ASCII characters that differ by only a single bit, which is common in large part because of case-insensitivity, due to uppercase ASCII letters differing by only a single bit (0x20) from their lowercase ASCII counterparts. Thus if you write the set
[Aa], that will be emitted as(ch | 0x20) == 'a'. Interestingly, the optimization is written in such a way that it doesn't care which bit it is that differs, so if for example you write[<>], that will be emitted as(ch | 0x2) == '>'. This also applies for three character sets where the lower two case to each other. That's relevant because there are a handful of sets generated byRegexOptions.IgnoreCasethat follow this pattern. For example, in the "en-US" culture, the letteri(0x69) is not only considered case-insensitive-equivalent to the letterI(0x49) but also to LATIN CAPITAL LETTER I WITH DOT ABOVE (0x130). With this optimization in place, then,iwithRegexOptions.IgnoreCasebecomes the equivalent of[Iiİ], which is now emitted as((ch | 0x20) == 'i') | (ch == 'İ'). - .NET 6 optimized sets with a single range, e.g. the
[0-9]shown earlier. .NET 7 now similarly handles sets with two ranges, e.g. the set[\p{IsGreek}\p{IsGreekExtended}]will now be emitted as:((uint)(ch - 'Ͱ') <= (uint)('Ͽ' - 'Ͱ')) | ((uint)(ch - 'ἀ') <= (uint)('u1fff' - 'ἀ')).
One of the more valuable set improvements, though, is another level of fallback before we get to the string-based ASCII bitmap. If upon examination of the set we can determine that the smallest and largest character in the set are within 64 values of each other, then we can emit a ulong-based bitmap, and we can do so in a way that's not only smaller in size, but is also branchless in execution. This allows for sets like [A-Fa-f0-9], which is a set for all hexadecimal digits, to be handled very efficiently, e.g. that set will now be handled with code emitted like:
(long)((0xFFC07E0000007E00UL << (int)(charMinusLow = (uint)ch - '0')) & (charMinusLow - 64)) < 0and the impact of that can add up:
private static Regex s_regex = new Regex(@"0x[A-Fa-f0-9]+", RegexOptions.Compiled);
private static string s_text = @"This is a test to find hex numbers like 0x123ABC.";
[Benchmark]
public bool IsMatch() => s_regex.IsMatch(s_text);| Method | Runtime | Mean | Ratio |
|---|---|---|---|
| IsMatch | .NET Framework 4.8 | 170.99 ns | 1.00 |
| IsMatch | .NET 6.0 | 88.25 ns | 0.52 |
| IsMatch | .NET 7.0 | 53.41 ns | 0.31 |
What's Next?
We still have months before .NET 7 ships, and we've not seen the end of improvements coming for Regex. In fact, while writing this post I'm using a nightly .NET 7 Preview 5 build, which includes improvements new since Preview 4. All of the new features discussed in this post will continue to see improvements prior to release, and additional performance gains are also expected. We'd love your feedback on the new APIs, the new NonBacktracking engine, the new performance improvements, and in general your feedback on using Regex in .NET in general. And for anyone interested, we'd welcome improvements in the form of issues and pull requests as well.
Happy coding.
38 comments