

本篇翻译于Richard Lander的The convenience of System.IO – .NET Blog (microsoft.com)
与其他形式的 I/O 一样,读写文件很常见的。文件 API 用于读取应用程序配置、缓存内容以及将数据(从磁盘)加载到内存中以执行一些计算,例如(今天的主题)字数统计。File、FileInfo、FileStream和相关类型为需要访问文件的 .NET 开发人员完成了大量繁重的工作。在这篇文章中,我们将在System.Text API的帮助下了解使用System.IO读取文本文件的便利性和性能。
我们最近启动了关于.NET 便利性的系列博客,该系列描述了我们为常见任务提供便捷解决方案的方法。System.Text.Json 的便利性是本系列中的另一篇文章,介绍如何读取和编写 JSON 文档。为什么选择.NET?则描述了支持这些文章中涵盖的解决方案的架构选择。
这篇文章分析了文件 I/O 和文本 API 在大型小说中用于计算行数、字数和字节数的便利性和性能。结果表明,高级 API 易于使用,性能优异,而较低级别的 API 需要付出更多努力才能提供出色的效果。您还将看到本机 AOT如何将 .NET 应用程序启动的性能表现提升到一个新的级别。
The APIs
基准测试中使用了以下 File API(及其配套 API)。
- File.OpenHandle和RandomAccess.Read
- File.Open和FileStream.Read
- File.OpenText和StreamReader.ReadStream以及Reader.ReadLine
- File.ReadLines和IEnumerable<string>
- File.ReadAllLines和string[]
API 按照控制程度最高到最方便的顺序列出。如果您对这些API不熟悉也没关系。这篇文章仍然是一份有趣的读物。
较低级别的基准测试依赖于以下 System.Text 类型:
我还使用了新的SearchValues 类来查看它是否比将Span<char>传递给 Span<char>.IndexOfAny 具有更显著的优势。它预先计算搜索策略以避免 IndexOfAny 的前期成本。 剧透:效果非常显著。
接下来,我们将研究一个已经实现了多次的应用程序(针对每个 API),测试可访问性和效率。
目标App
该应用程序统计文本文件中的行数、字数和字节数。它是基于wc 的行为建模的,wc 是一种在类 Unix 系统上可用的流行工具。
字数统计是一种需要查看文件中每个字符的算法。计数是通过计算空格和换行符来完成的。
单词是由空格分隔的非零长度的可打印字符序列。
这是来自 wc –help。 应用程序代码需要遵循该原则。 看起来很简单直接。
该基准对塞缪尔·理查森(Samuel Richardson)的《Clarissa Harlowe》(《一位年轻女士的历史》)中的字数进行统计。之所以选择这本书,是因为它是最长的英语书籍之一,而且可以在古腾堡计划上免费获取。1991年,BBC甚至还对它进行了电视改编。
我还用另一篇长文本《悲惨世界》做了一些测试。遗憾的是,24601没有出现在字数统计中。
结果
每个实施都根据以下方面进行衡量:
- 代码行数
- 执行速度
- 内存使用
我使用的 .NET 8 版本非常接近最终的 GA 版本。在撰写本文时,我看到另一个 .NET 8 版本即将发布,所以,我使用的版本可能是该版本最终版本的最后两到三个版本。
我使用BenchmarkDotNet进行性能测试。如果您从未使用过它,那么它将是一个很棒的工具。编写基准测试类似于编写单元测试。
下面的 wc用法列出了我的 Linux 机器上的内核。每个内核在 /proc/cpuinfo 文件中都有自己的行,每行中都出现了“model name”,并且 -l 计算行数。
$ cat /proc/cpuinfo | grep "model name" | wc -l
8
$ cat /proc/cpuinfo | grep "model name" | head -n 1
model name : Intel(R) Core(TM) i7-7700K CPU @ 4.20GHz
$ cat /etc/os-release | head -n 1
NAME="Manjaro Linux"我在这篇文章中使用这台机器进行性能测试。您可以看到我正在使用 Manjaro Linux,它是 Arch Linux 系列的一部分。.NET 8 已在Arch 用户存储库中可用(Manjaro 用户也可以使用)。
代码行数
我喜欢简单易懂的解决方案。代码行数是最好的指证。

上面的图表中有两个簇,分别位于 ~35 和 ~75 行处。您将看到这些基准测试归结为两种算法,它们之间存在一些细微差别,以适应不同的 API。相比之下,wc实现要长的多,接近 1000 行。然而,它的作用还不止这些。
我使用 wc 来计算基准的行数,再次使用 -l。
$ wc -l *Benchmark.cs
73 FileOpenCharSearchValuesBenchmark.cs
71 FileOpenHandleAsciiCheatBenchmark.cs
74 FileOpenHandleCharSearchValuesBenchmark.cs
60 FileOpenHandleRuneBenchmark.cs
45 FileOpenTextCharBenchmark.cs
65 FileOpenTextCharIndexOfAnyBenchmark.cs
84 FileOpenTextCharLinesBenchmark.cs
65 FileOpenTextCharSearchValuesBenchmark.cs
34 FileOpenTextReadLineBenchmark.cs
36 FileOpenTextReadLineSearchValuesBenchmark.cs
32 FileReadAllLinesBenchmark.cs
32 FileReadLinesBenchmark.cs
671 total我编写了几个基准测试,为每个文件 API 使用性能最佳的基准(为了简单起见缩短了名称)。我在上图中总结了这些内容,完整的基准测试将在稍后介绍。
功能与wc相当
让我们验证我的 C# 实现是否与wc匹配。
wc:
$ wc ../Clarissa_Harlowe/*
11716 110023 610515 ../Clarissa_Harlowe/clarissa_volume1.txt
12124 110407 610557 ../Clarissa_Harlowe/clarissa_volume2.txt
11961 109622 606948 ../Clarissa_Harlowe/clarissa_volume3.txt
12168 111908 625888 ../Clarissa_Harlowe/clarissa_volume4.txt
12626 108592 614062 ../Clarissa_Harlowe/clarissa_volume5.txt
12434 107576 607619 ../Clarissa_Harlowe/clarissa_volume6.txt
12818 112713 628322 ../Clarissa_Harlowe/clarissa_volume7.txt
12331 109785 611792 ../Clarissa_Harlowe/clarissa_volume8.txt
11771 104934 598265 ../Clarissa_Harlowe/clarissa_volume9.txt
9 153 1044 ../Clarissa_Harlowe/summary.md
109958 985713 5515012 total以及随着计数, FileOpenHandleCharSearchValuesBenchmark的独立副本:
$ dotnet run ../Clarissa_Harlowe/
11716 110023 610515 ../Clarissa_Harlowe/clarissa_volume1.txt
12124 110407 610557 ../Clarissa_Harlowe/clarissa_volume2.txt
11961 109622 606948 ../Clarissa_Harlowe/clarissa_volume3.txt
12168 111908 625888 ../Clarissa_Harlowe/clarissa_volume4.txt
12626 108593 614062 ../Clarissa_Harlowe/clarissa_volume5.txt
12434 107576 607619 ../Clarissa_Harlowe/clarissa_volume6.txt
12818 112713 628322 ../Clarissa_Harlowe/clarissa_volume7.txt
12331 109785 611792 ../Clarissa_Harlowe/clarissa_volume8.txt
11771 104934 598265 ../Clarissa_Harlowe/clarissa_volume9.txt
9 153 1044 ../Clarissa_H结果实际上是相同的,只是总字数存在一个字的差异。在这里,您看到的是 Linux 版本的wc。macOS 版本报告了985716字,与 Linux 实现相差三个词。我注意到其中两个文件中存在一些特殊字符导致了这些差异。我没有花更多时间调查它们,因为它超出了这篇文章的范围。
扫描摘要(10微秒内)
我首先测试了小说的简短摘要。它只有 1 KB(9 行和 153 个字)。
$ dotnet run ../Clarissa_Harlowe/summary.md
9 153 1044 ../Clarissa_Harlowe/summary.md我们来数数有几个字。

我把这个结果称为平局。因为很少有应用程序会在性能上考虑 1微秒的差距。我不会(仅仅)为了获胜而额外编写数十行代码。
Team byte 赢得了与Team string 的内存竞赛
让我们看看同一个小文档的内存使用情况。

注意:1_048_576 字节是 1 兆字节 (mebibyte)。 10_000 字节是其中的 1%。 注意:我使用的是整数文字格式。
您会看到一组 API 返回字节,另一组返回堆分配的字符串。 在中间,File.OpenText 返回 char 值。
File.OpenText 依赖于 StreamReader 和 FileStream 类来执行所需的处理。 返回 API 的string依赖于相同的类型。 这些 API 使用的 StreamReader 对象分配多个缓冲区,其中包括 1k 缓冲区。 它还创建一个 FileStream 对象,该对象在默认情况下分配一个 4k 缓冲区。 对于 File.OpenText(使用 StreamReader.Read 时),这些缓冲区是固定成本,而 File.ReadLines 和 File.ReadAllLines 还分配字符串(每行一个;可变成本)。
快速阅读《Clarissa_Harlowe》(1毫秒内)
让我们看看计算Clarissa_Harlowe 第一卷中的行数、字数和字节数需要多长时间。
$ dotnet run ../Clarissa_Harlowe/clarissa_volume1.txt
11716 110023 610515 ../Clarissa_Harlowe/clarissa_volume1.txt也许我们在处理610_515字节的文本时将在性能上看到更大的差异。

确实如此。byte和 char返回 API 聚集在一起,仅高于 1 毫秒。我们现在还看到 File.ReadLine 和 File.ReadAllLines 之间的区别。然而,我们应该看到,对于 600k 的文本来说,差距仅为 2ms。高级API使用简单的算法时也展现了极具竞争力的性能。
File.ReadLine 和 File.ReadAllLines 之间的差异值得更多的解释。
- 所有 API 均以字节开头。File.ReadLines 将字节读取到 char 值中,查找下一个换行符,然后将该文本块转换为字符串,每次返回一个。
- File.ReadAllLines 执行相同的操作,并同时创建所有字符串行并将它们全部打包到 string[] 中。 这是大量的前期工作,需要大量额外的内存,而这些内存通常不会提供额外的价值
File.OpenText 返回一个 StreamReader,它公开 ReadLine 和 Read API。 前者返回一个string,后者返回一个string或一个char值。 ReadLine 选项与使用 File.ReadLines 非常相似,它基于相同的 API 构建。在图表中,我使用 StreamReader.Read 显示了 File.OpenText。这样效率要高得多。
内存:最好一次读一页
基于速度的差异,我们可能也会看到很大的内存差异。

我们可以宽容一点。这是一个巨大的差异。低级 API 具有固定成本,而string API 的内存需求则随着文档的大小而变化。
我编写的 FileOpenHandle 和 FileOpen 基准测试使用 ArrayPool 数组,其成本没有显示在基准测试中。
Encoding encoding = Encoding.UTF8;
Decoder decoder = encoding.GetDecoder();
// BenchmarkValues.Size = 4 * 1024
// charBufferSize = 4097
int charBufferSize = encoding.GetMaxCharCount(BenchmarkValues.Size);
char[] charBuffer = ArrayPool<char>.Shared.Rent(charBufferSize);
byte[] buffer = ArrayPool<byte>.Shared.Rent(BenchmarkValues.Size);上面这段代码显示了使用的两个ArrayPool数组(及其大小)。根据观察,4k 缓冲区具有显著的性能优势,超过4k 缓冲区的性能优势有限(或没有)。4k 缓冲区对于处理 600k 文件似乎是合理的。
我本可以使用私有数组(或接受调用者的缓冲区)。我对 ArrayPool 数组的使用展示了底层 API 中内存使用的差异。 正如您所看到的,File.Open 和 File.OpenHandle 的成本实际上为零(至少相对而言)。
尽管如此,FileOpen 和 FileOpenHandle 基准测试的内存使用情况将与我调用不使用ArrayPool的 FileOpenText 的时候非常相似。 这应该会让您觉得 FileOpenText 非常好(当不使用 StreamReader.ReadLine 时)。当然,我的实现可以更新为使用更小的缓冲区,但它们运行速度会更慢。
性能与wc相当
我已经证明 System.IO 可用于产生与 wc 相同的结果。同样,我应该使用我的最佳性能基准来比较性能。在这里,我将使用 time 命令来记录整个调用(进程开始到终止),处理单个卷(小说)和所有卷。您会发现整部小说(共 9 卷)包含了超过 5MB 的文本和将近100 万的字数。
让我们从wc开始。
$ time wc ../Clarissa_Harlowe/clarissa_volume1.txt
11716 110023 610515 ../Clarissa_Harlowe/clarissa_volume1.txt
real 0m0.009s
user 0m0.006s
sys 0m0.003s
$ time wc ../Clarissa_Harlowe/*
11716 110023 610515 ../Clarissa_Harlowe/clarissa_volume1.txt
12124 110407 610557 ../Clarissa_Harlowe/clarissa_volume2.txt
11961 109622 606948 ../Clarissa_Harlowe/clarissa_volume3.txt
12168 111908 625888 ../Clarissa_Harlowe/clarissa_volume4.txt
12626 108592 614062 ../Clarissa_Harlowe/clarissa_volume5.txt
12434 107576 607619 ../Clarissa_Harlowe/clarissa_volume6.txt
12818 112713 628322 ../Clarissa_Harlowe/clarissa_volume7.txt
12331 109785 611792 ../Clarissa_Harlowe/clarissa_volume8.txt
11771 104934 598265 ../Clarissa_Harlowe/clarissa_volume9.txt
9 153 1044 ../Clarissa_Harlowe/summary.md
109958 985713 5515012 total
real 0m0.026s
user 0m0.026s
sys 0m0.000s这是相当快的。即 9 毫秒和 26 毫秒。
让我们尝试使用 .NET,使用FileOpenHandleCharSearchValuesBenchmark实现。
$ time ./app/count ../Clarissa_Harlowe/clarissa_volume1.txt
11716 110023 610515 ../Clarissa_Harlowe/clarissa_volume1.txt
real 0m0.070s
user 0m0.033s
sys 0m0.016s
$ time ./app/count ../Clarissa_Harlowe/
11716 110023 610515 ../Clarissa_Harlowe/clarissa_volume1.txt
12124 110407 610557 ../Clarissa_Harlowe/clarissa_volume2.txt
11961 109622 606948 ../Clarissa_Harlowe/clarissa_volume3.txt
12168 111908 625888 ../Clarissa_Harlowe/clarissa_volume4.txt
12626 108593 614062 ../Clarissa_Harlowe/clarissa_volume5.txt
12434 107576 607619 ../Clarissa_Harlowe/clarissa_volume6.txt
12818 112713 628322 ../Clarissa_Harlowe/clarissa_volume7.txt
12331 109785 611792 ../Clarissa_Harlowe/clarissa_volume8.txt
11771 104934 598265 ../Clarissa_Harlowe/clarissa_volume9.txt
9 153 1044 ../Clarissa_Harlowe/summary.md
109958 985714 5515012 total
real 0m0.124s
user 0m0.095s
sys 0m0.010s这可不好!还差得远呢。
.NET 分别为 70 和 124 毫秒,而 wc 分别为 9 和 26 毫秒。非常有趣的是,持续时间并不随着内容的大小而变化,特别是在 .NET 实现中。运行时启动成本显然占主导地位。
每个人都知道托管语言运行时在启动时无法跟上本机代码。数字证实了这一点。如果我们有一个本机托管运行时就好了。
哦!我们的确有。我们有本机AOT。我们来试试吧。
由于我喜欢使用容器,因此我使用了我们的 SDK 容器映像之一(带有卷安装)来进行编译,这样我就无需在我的计算机上安装本机工具链。
$ docker run --rm mcr.microsoft.com/dotnet/nightly/sdk:8.0-jammy-aot dotnet --version
8.0.100-rtm.23523.2
$ docker run --rm -v $(pwd):/source -w /source mcr.microsoft.com/dotnet/nightly/sdk:8.0-jammy-aot dotnet publish -o /source/napp
$ ls -l napp/
total 4936
-rwxr-xr-x 1 root root 1944896 Oct 30 11:57 count
-rwxr-xr-x 1 root root 3107720 Oct 30 11:57 count.dbg如果您仔细观察,您会发现使用本机 AOT 编译的基准应用程序小于 2MB (1_944_896)。 这就是所有的东西(运行时、库和应用程序代码)。事实上,符号(count.dbg)文件更大。例如,我可以将该可执行文件放到 Ubuntu 22.04 x64 计算机上,然后运行它。
让我们测试一下本机AOT。
$ time ./napp/count ../Clarissa_Harlowe/clarissa_volume1.txt
11716 110023 610515 ../Clarissa_Harlowe/clarissa_volume1.txt
real 0m0.004s
user 0m0.005s
sys 0m0.000s
$ time ./napp/count ../Clarissa_Harlowe/
11716 110023 610515 ../Clarissa_Harlowe/clarissa_volume1.txt
12124 110407 610557 ../Clarissa_Harlowe/clarissa_volume2.txt
11961 109622 606948 ../Clarissa_Harlowe/clarissa_volume3.txt
12168 111908 625888 ../Clarissa_Harlowe/clarissa_volume4.txt
12626 108593 614062 ../Clarissa_Harlowe/clarissa_volume5.txt
12434 107576 607619 ../Clarissa_Harlowe/clarissa_volume6.txt
12818 112713 628322 ../Clarissa_Harlowe/clarissa_volume7.txt
12331 109785 611792 ../Clarissa_Harlowe/clarissa_volume8.txt
11771 104934 598265 ../Clarissa_Harlowe/clarissa_volume9.txt
9 153 1044 ../Clarissa_Harlowe/summary.md
109958 985714 5515012 total
real 0m0.022s
user 0m0.025s
sys 0m0.007s本机 AOT 分别为 4 毫秒和 22 毫秒,而 wc 分别为 9 毫秒和 25 毫秒。 这些都是非常出色的成绩,而且很有竞争力! 这些数字是如此之好,以至于我几乎不得不仔细检查,但计数验证了计算结果。
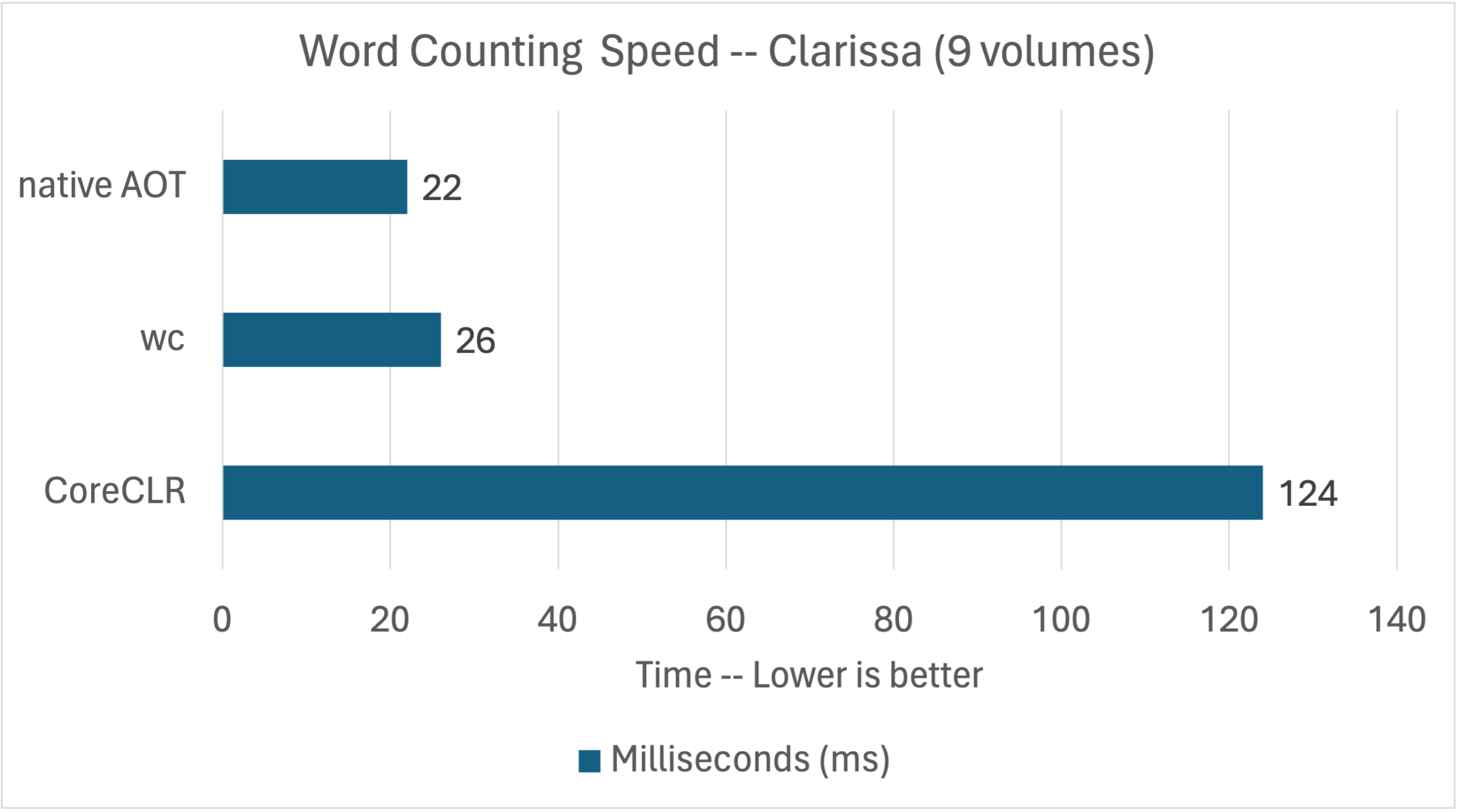
注意:我使用 <OptimizationPreference>Speed</OptimizationPreference> 配置了应用程序。 它提供了小小的好处。
文本、Runes和 Unicode
文本无处不在。事实上,您现在正在阅读它。.NET 包含多种用于处理和存储文本的类型,包括Char、Encoding、Rune和String.
Unicode编码超过一百万个字符,包括表情符号emoji。ASCII和 Unicode的前 128 个字符匹配。Unicode 编码共有三种:UTF8、UTF16 和 UTF32,用于编码每个字符的不同字节数。
以下是《霍比特人》中的一些(半相关)文字。
“月亮字母是符文字母,但你看不到它们,”埃尔隆德说
我不禁认为月亮字母是奇妙的空白字符。
以下是一个小实用程序的结果,它使用该文本打印出有关每个 Unicode 字符的信息。字节长度和字节特定于 UTF8 表示形式。
$ dotnet run elrond.txt | head -n 16
char, codepoint, byte-length, bytes, notes
“, 8220, 3, 11100010_10000000_10011100,
M, 77, 1, 01001101,
o, 111, 1, 01101111,
o, 111, 1, 01101111,
n, 110, 1, 01101110,
-, 45, 1, 00101101,
l, 108, 1, 01101100,
e, 101, 1, 01100101,
t, 116, 1, 01110100,
t, 116, 1, 01110100,
e, 101, 1, 01100101,
r, 114, 1, 01110010,
s, 115, 1, 01110011,
, 32, 1, 00100000,whitespace
a, 97, 1, 01100001,左引号字符需要三个字节进行编码。其余字符都需要一个字节,因为它们在 ASCII 字符范围内。我们还看到一个空白字符,即空格字符。
使用一字节编码的字符的二进制表示形式与其代码点整数值完全匹配。例如,代码点“M”(77)的二进制表示是0b01001101,与整数77相同。相反,整数8220的二进制表示是0b_100000_00011100,而不是我们上面看到的“三字节二进制值。这是因为 Unicode 编码不仅仅描述代码点值。
using System.Text;
char englishLetter = 'A';
char fancyQuote = '“';
// char emoji = (char)0x1f600; // won't compile
string emoji = "\U0001f600";
Encoding encoding = Encoding.UTF8;
PrintChar(englishLetter);
PrintChar(fancyQuote);
PrintChar(emoji[0]);
PrintUnicodeCharacter(emoji);
void PrintChar(char c)
{
int value = (int)c;
// Rune rune = new Rune(c); // will throw since emoji[0] is an invalid rune
Console.WriteLine($"{c}; bytes: {encoding.GetByteCount([c])}; integer value: {(int)c}; round-trip: {(char)value}");
}
void PrintUnicodeCharacter(string s)
{
char[] chars = s.ToCharArray();
int value = char.ConvertToUtf32(s, 0);
Rune r1 = (Rune)value;
Rune r2 = new Rune(chars[0], chars[1]);
Console.WriteLine($"{s}; chars: {chars.Length}; bytes: {encoding.GetByteCount(chars)}; integer value: {value}; round-trip {char.ConvertFromUtf32(value)};");
Console.WriteLine($"{s}; Runes match: {r1 == r2 && r1.Value == value}; {nameof(Rune.Utf8SequenceLength)}: {r1.Utf8SequenceLength}; {nameof(Rune.Utf16SequenceLength)}: {r1.Utf16SequenceLength}");
}它打印出以下内容:
A; bytes: 1; integer value: 65; round-trip: A
“; bytes: 3; integer value: 8220; round-trip: “
�; bytes: 3; integer value: 55357; round-trip: �
😀; chars: 2; bytes: 4; integer value: 128512; round-trip 😀;
😀; Runes match: True; Utf8SequenceLength: 4; Utf16SequenceLength: 2我可以再次运行该应用程序,将encoding切换为 UTF16。我将encoding的值切换为Encoding.Unicode。
A; bytes: 2; integer value: 65; round-trip: A
“; bytes: 2; integer value: 8220; round-trip: “
�; bytes: 2; integer value: 55357; round-trip: �
😀; chars: 2; bytes: 4; integer value: 128512; round-trip 😀;
😀; Runes match: True; Utf8SequenceLength: 4; Utf16SequenceLength: 2这告诉我们一些事情:
- UTF8编码具有非统一的字节编码。
- UTF16编码更加统一。
- 需要单个代码点的字符可以与 int 进行互操作,从而启用 (char)8220 或 (char)0x201C 等模式。
- 需要两个代码点的字符可以存储在string、(UTF32) 整数值或 Rune 中,从而启用 (Rune)128512 等模式。
- 如果代码直接处理字符或(更糟糕的)字节,则很容易编写有错误的软件。例如,想象一下编写一个支持表情符号搜索词的文本搜索算法。
- 对于任何开发人员来说,多代码点字符就足够了。
- 我的终端支持表情符号(我对此感到非常高兴)。
我们可以将这些 Unicode 概念与 .NET 类型联系起来。
- String和char使用UTF16编码。
- Encoding类允许处理编码和byte值之间的文本。
- string 支持需要一或两个代码点的 Unicode 字符。
- 与char不同,Rune可以表示所有Unicode字符(包括代理字符对)。
所有这些类型都在基准测试中使用。所有的基准测试(除了作弊的基准测试)都正确使用这些类型,以便正确处理 Unicode 文本。
让我们看一下基准测试。
File.ReadLines和File.ReadAllLines
以下基准测试实现了基于string行的高级算法:
结果部分中的性能图表包括这两个基准,因此无需再次显示这些结果。
FileReadLines基准为我们的分析设置了基线。它在IEnumerable<string>上使用foreach。
public static Count Count(string path)
{
long wordCount = 0, lineCount = 0, charCount = 0;
foreach (string line in File.ReadLines(path))
{
lineCount++;
charCount += line.Length;
bool wasSpace = true;
foreach (char c in line)
{
bool isSpace = char.IsWhiteSpace(c);
if (!isSpace && wasSpace)
{
wordCount++;
}
wasSpace = isSpace;
}
}
return new(lineCount, wordCount, charCount, path);
}上面这段代码通过外部 foreach 计算行数和字符数。内部 foreach 计算空格后的单词数,查看行中的每个字符。它使用 char.IsWhiteSpace 来确定字符是否为空格。这个算法对于字数统计来说是最简单的。
$ wc ../Clarissa_Harlowe/clarissa_volume1.txt
11716 110023 610515 ../Clarissa_Harlowe/clarissa_volume1.txt
$ dotnet run -c Release 1 11
FileReadLinesBenchmark
11716 110023 587080 /Users/rich/git/convenience/wordcount/wordcount/bin/Release/net8.0/Clarissa_Harlowe/clarissa_volume1.txt注意:在我自己的测试中,该应用程序在基准测试中以几种不同的方式启动。这就是有奇怪的命令行参数的原因。
结果与 wc 工具基本匹配。字节数不匹配,因为此代码适用于字符而不是字节。这意味着字节顺序标记、多字节编码和行终止字符已从视图中隐藏。我本可以为每行的 charCount 添加 +1,但这对我来说似乎没什么用,特别是因为有多个换行符方案。我决定准确地计算字符或字节,而不是尝试近似它们之间的差异。
总结:这些 API 非常适合小型文档或者内存使用不是一个强约束时。如果我的算法依赖于预先了解文档中的行数并且仅适用于小文档,我只会使用 File.ReadAllLines。对于较大的文档,我会采用更好的算法来计算换行符,以避免使用该 API。
File.OpenText
下面的基准测试实现了多种方法,它们都基于 StreamReader,其中File.OpenText 只是一个包装器。 一些 StreamReader API 公开string行,其他 API 公开char值。 在这里,我们将看到性能上的较大差异。
- FileOpenTextReadLineSearchValuesBenchmark
- FileOpenTextCharBenchmark
- FileOpenTextCharLinesBenchmark
- FileOpenTextCharIndexOfAnyBenchmark
- FileOpenTextCharSearchValuesBenchmark
这些基准测试的目标是确定 SearchValues 以及 char 与 string 的优势。 我还添加了 FileReadLinesBenchmark 基准测试作为前一组基准测试的基准。
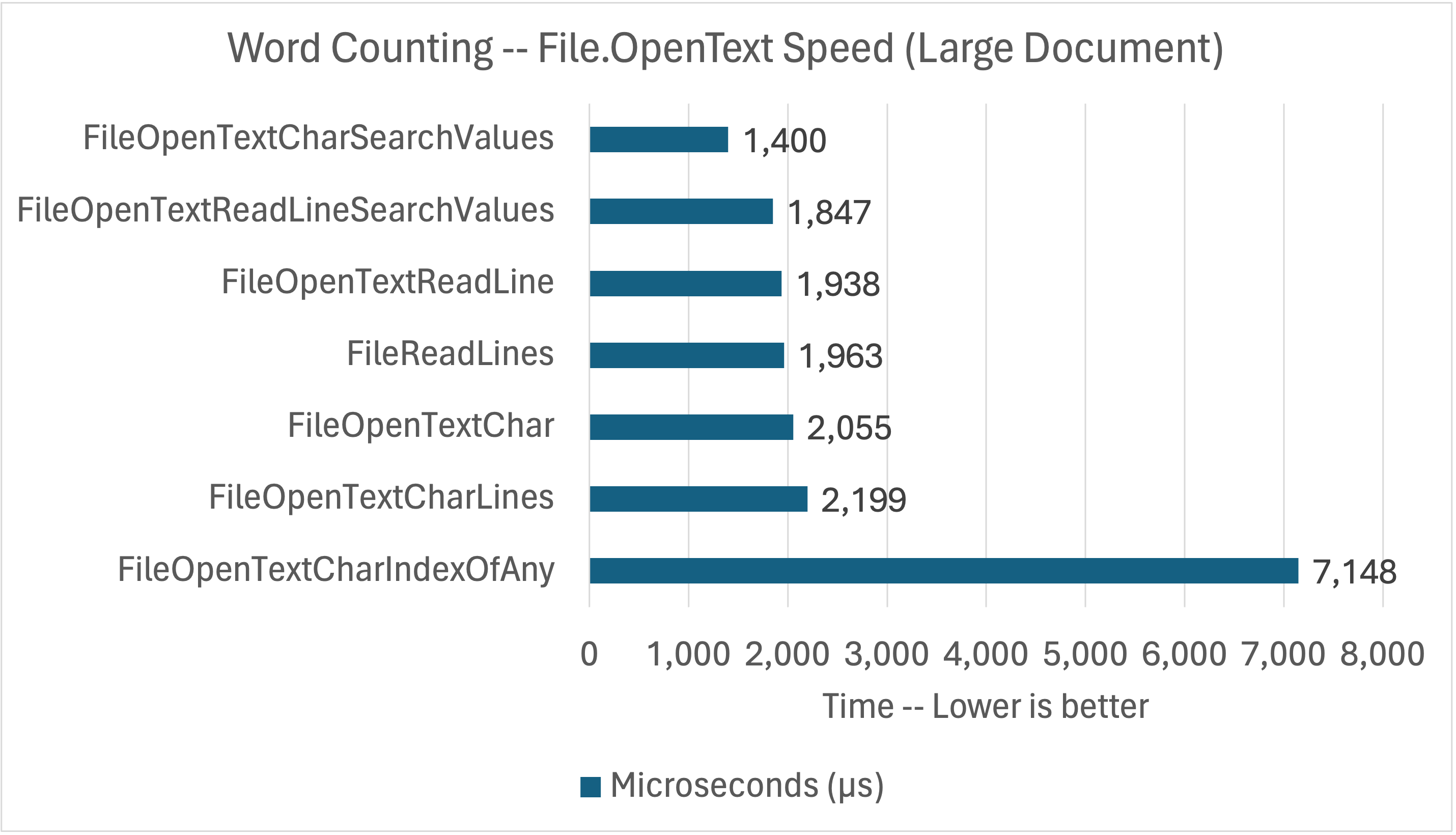
您可能想知道内存。 StreamReader 的内存使用是char与string的函数,您可以在本文前面的初始内存图表中看到这一点。这些算法的差异会影响速度,但不会影响内存。
FileOpenTextReadLineBenchmark 基准测试实际上与 FileReadLines 相同,只是没有 IEnumerable<string> 抽象
FileOpenTextReadLineSearchValuesBenchmark基准测试开始变得更花哨了。
public static Count Count(string path)
{
long wordCount = 0, lineCount = 0, charCount = 0;
using StreamReader stream = File.OpenText(path);
string? line = null;
while ((line = stream.ReadLine()) is not null)
{
lineCount++;
charCount += line.Length;
ReadOnlySpan<char> text = line.AsSpan().TrimStart();
if (text.Length is 0)
{
continue;
}
int index = 0;
while ((index = text.IndexOfAny(BenchmarkValues.WhitespaceSearchValuesNoLineBreak)) > 0)
{
wordCount++;
text = text.Slice(index).TrimStart();
}
wordCount++;
}
return new(lineCount, wordCount, charCount, path);
}这个基准测试只是简单地计算空格(它不会修剪)。它利用新的 SearchValues 类型,在搜索多个值时可以加快 IndexOfAny 的速度。 SearchValues 对象由除(大多数)换行符之外的空白字符构造。我们可以假设换行符不再存在,因为代码依赖于 StreamReader.ReadLine。
我本可以在之前的基准测试实现中使用相同的算法,但是,我希望将最平易近人的 API 与最平易近人的基准测试实现相匹配。
IndexOfAny表现如此出色的很大一部分原因是矢量化。
$ dotnet run -c Release 2
Vector64.IsHardwareAccelerated: False
Vector128.IsHardwareAccelerated: True
Vector256.IsHardwareAccelerated: True
Vector512.IsHardwareAccelerated: False.NET 8 包含了高达 512 位的矢量 API。您可以在自己的算法中使用它们,也可以依赖 IndexOfAny 等内置 API 来利用改进的处理能力。便利的 IsHardwareAccelerated API 可以告诉您给定 CPU 上的矢量寄存器有多大。这是在我的 Intel 机器上得到的结果。我尝试了 Azure 中提供的一些较新的 Intel 硬件,它们将 Vector512.IsHardwareAccelerated 报告为 True。我的 MacBook M1 机器报告为 Vector128.IsHardwareAccelerated 作为最高可用值。
现在我们可以离开string并切换到char值。预期会有两大好处。首先,底层 API 不需要提前读取来查找换行符,也不会再有任何字符串需要进行堆分配和垃圾收集。 我们应该看到速度有了显著的提高,并且我们已经从之前的图表中知道内存有了显著的减少。
我构建了以下基准来梳理各种策略的价值。
- FileOpenTextCharBenchmark — 与 FileReadLines 相同的基本算法,但添加了对换行符检查。
- FileOpenTextCharLinesBenchmark— 试图通过合成字符行来简化核心算法。
- FileOpenTextCharSearchValuesBenchmark— 类似于 FileOpenTextReadLineSearchValuesBenchmark的SearchValues的使用,以加快空间搜索,但没有预先计算行。
- FileOpenTextCharIndexOfAnyBenchmark —完全相同的算法,但使用 IndexOfAny 和 Span<char> 而不是新的 SearchValues 类型。
这些基准(如上图所示)告诉我们,带有 SearchValues<char> 的 IndexOfAny 非常有用。 有趣的是,当给定很多的值(25)进行检查时,IndexOfAny 的表现非常糟糕。这比简单地用char.IsWhiteSpace 检查遍历每个字符要慢得多。如果您在 IndexOfAny 中使用大量搜索词,这些结果应该会让您有所顾虑。
我在其他一些机器上做了一些测试。 我注意到 FileOpenTextCharLinesBenchmark 在 AVX512 机器(时钟速度较低)上表现得很好。 这可能是因为它更依赖于 IndexOfAny(只有两个搜索词),并且是一个非常精简的算法。
下面是 FileOpenTextCharSearchValuesBenchmark 实现。
public static Count Count(string path)
{
long wordCount = 0, lineCount = 0, charCount = 0;
bool wasSpace = true;
char[] buffer = ArrayPool<char>.Shared.Rent(BenchmarkValues.Size);
using StreamReader reader = File.OpenText(path);
int count = 0;
while ((count = reader.Read(buffer)) > 0)
{
charCount += count;
Span<char> chars = buffer.AsSpan(0, count);
while (chars.Length > 0)
{
if (char.IsWhiteSpace(chars[0]))
{
if (chars[0] is '\n')
{
lineCount++;
}
wasSpace = true;
chars = chars.Slice(1);
continue;
}
else if (wasSpace)
{
wordCount++;
wasSpace = false;
chars = chars.Slice(1);
}
int index = chars.IndexOfAny(BenchmarkValues.WhitespaceSearchValues);
if (index > -1)
{
if (chars[index] is '\n')
{
lineCount++;
}
wasSpace = true;
chars = chars.Slice(index + 1);
}
else
{
wasSpace = false;
chars = [];
}
}
}
ArrayPool<char>.Shared.Return(buffer);
return new(lineCount, wordCount, charCount, path);
}这与最初的实现并没有什么不同。第一个块需要考虑 char.IsWhiteSpace 检查中的换行符。 之后,IndexOfAny 与 SearchValue<char> 一起使用来查找下一个空白字符,以便可以完成下一次检查。 如果 IndexOfAny 返回 -1,我们就知道不再有空白字符,因此无需进一步读取缓冲区。
Span<T> 在此实现中被广泛使用。 Spans 提供了一种在底层数组上创建窗口的廉价方法。 它们是如此方便,以至于当 chars.Length > 0 不再为 true 时,实现可以继续切片。 我只在需要一次切片 >1 个字符的算法中使用这种方法。 否则,我使用 for 循环来迭代 Span,这样更快。
注意:Visual Studio 会建议将 chars.Slice(1) 简化为 chars[1..]。我发现这种简化并不等同,并且在基准测试中表现为性能回归。 这在应用程序中不太可能成为问题。
$ wc ../Clarissa_Harlowe/clarissa_volume1.txt
11716 110023 610515 ../Clarissa_Harlowe/clarissa_volume1.txt
$ dotnet run -c Release 1 4
FileOpenTextCharBenchmark
11716 110023 610512 /Users/rich/git/convenience/wordcount/wordcount/bin/Release/net8.0/Clarissa_Harlowe/clarissa_volume1.txt对于字节结果(对于 ASCII 文本),FileOpenTextChar* 基准测试更接近匹配 wc。
在这些 API 开始返回值之前,会消耗字节顺序标记 (BOM)。 因此,返回 char 的 API 的字节总是差三个字节(BOM 的大小)。与返回string的 API 不同,所有换行符都会被计算在内。
总结:StreamReader(File.OpenText 的基础)提供了一组灵活的 API,涵盖了广泛的易用性和性能。 对于大多数用例(如果 File.ReadLines 不合适),StreamReader 是一个很好的默认选择。
File.Open和File.OpenHandle
以下基准测试实现了基于字节的最低级别的算法。File.Open 是 FileStream 的包装器。 File.OpenHandle返回一个操作系统句柄,需要RandomAccess.Read来访问。
- FileOpenCharSearchValuesBenchmark
- FileOpenHandleCharSearchValuesBenchmark
- FileOpenHandleRuneBenchmark
- FileOpenHandleAsciiCheatBenchmark
这些 API 提供了更多的控制功能。现在行和字符都消失了,只剩下字节了。这些基准测试的目标是尽可能获得最佳的性能,并探索在 API 返回字节的情况下正确读取 Unicode 文本的方法。
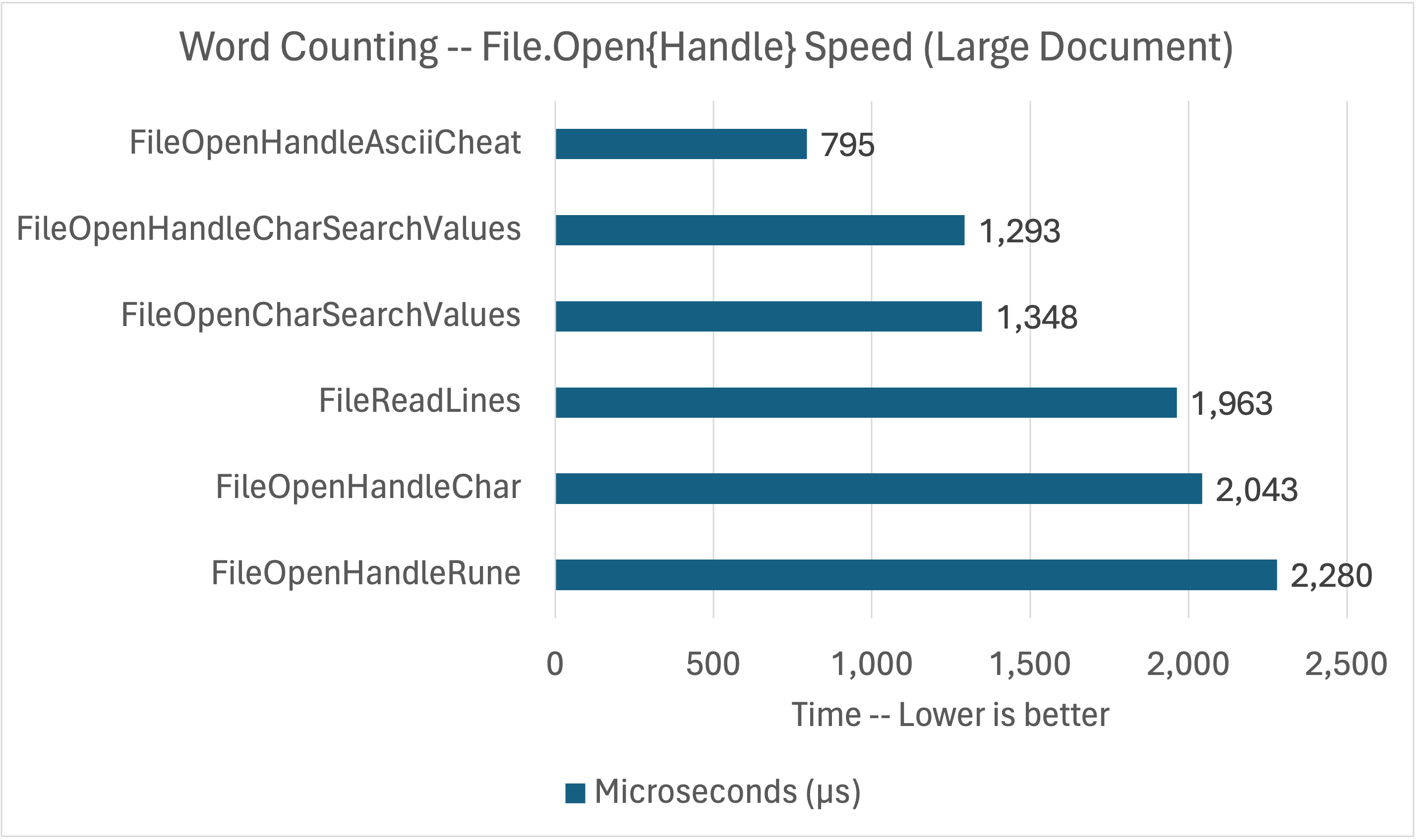
最后一次尝试匹配 wc 的结果。
$ wc ../Clarissa_Harlowe/clarissa_volume1.txt
11716 110023 610515 ../Clarissa_Harlowe/clarissa_volume1.txt
$ dotnet run -c Release 1 0
FileOpenHandleCharSearchValuesBenchmark
11716 110023 610515 /Users/rich/git/convenience/wordcount/wordcount/bin/Release/net8.0/Clarissa_Harlowe/clarissa_volume1.txt字节数现在匹配。我们现在查看给定文件中的每个字节。
FileOpenHandleCharSearchValuesBenchmark 添加了一些新概念。 与FileOpenCharSearchValuesBenchmark 实际上是相同的。
public static Count Count(string path)
{
long wordCount = 0, lineCount = 0, byteCount = 0;
bool wasSpace = true;
Encoding encoding = Encoding.UTF8;
Decoder decoder = encoding.GetDecoder();
int charBufferSize = encoding.GetMaxCharCount(BenchmarkValues.Size);
char[] charBuffer = ArrayPool<char>.Shared.Rent(charBufferSize);
byte[] buffer = ArrayPool<byte>.Shared.Rent(BenchmarkValues.Size);
using Microsoft.Win32.SafeHandles.SafeFileHandle handle = File.OpenHandle(path, FileMode.Open, FileAccess.Read, FileShare.Read, FileOptions.SequentialScan);
// Read content in chunks, in buffer, at count length, starting at byteCount
int count = 0;
while ((count = RandomAccess.Read(handle, buffer, byteCount)) > 0)
{
byteCount += count;
int charCount = decoder.GetChars(buffer.AsSpan(0, count), charBuffer, false);
ReadOnlySpan<char> chars = charBuffer.AsSpan(0, charCount);
while (chars.Length > 0)
{
if (char.IsWhiteSpace(chars[0]))
{
if (chars[0] is '\n')
{
lineCount++;
}
wasSpace = true;
chars = chars.Slice(1);
continue;
}
else if (wasSpace)
{
wordCount++;
wasSpace = false;
chars = chars.Slice(1);
}
int index = chars.IndexOfAny(BenchmarkValues.WhitespaceSearchValues);
if (index > -1)
{
if (chars[index] is '\n')
{
lineCount++;
}
wasSpace = true;
chars = chars.Slice(index + 1);
}
else
{
wasSpace = false;
chars = [];
}
}
}
ArrayPool<char>.Shared.Return(charBuffer);
ArrayPool<byte>.Shared.Return(buffer);
return new(lineCount, wordCount, byteCount, path);
}该算法的主体实际上与我们刚才看到的FileOpenTextCharSearchValuesBenchmark实现相同。不同的是初始设置。
以下是两段新代码。
Encoding encoding = Encoding.UTF8;
Decoder decoder = encoding.GetDecoder();
int charBufferSize = encoding.GetMaxCharCount(BenchmarkValues.Size);上面这段代码获取用于将字节转换为字符的 UTF8 解码器。它还获取解码器在给定将使用的字节缓冲区大小的情况下可能产生的最大字符数。此实现是硬编码的为了使用 UTF8。它可以动态地(通过读取字节顺序标记)以使用其他 Unicode 编码。
int charCount = decoder.GetChars(buffer.AsSpan(0, count), charBuffer, false);
ReadOnlySpan<char> chars = charBuffer.AsSpan(0, charCount);上面这段代码将字节缓冲区解码为字符缓冲区。 根据报告的byte和char计数值,两个缓冲区的大小都是正确的(使用 AsSpan)。之后,代码采用了更熟悉的基于char的算法。 没有明显的方法可以使用 SearchValues<byte> 来很好地处理多字节 Unicode 编码。 这种方法效果很好,所以这并不重要。
这篇文章是关于便利性的。我发现 Decoder.GetChars 非常便利。它是低级 API 的一个完美示例,它完全满足了我们的需求,并在某种程度上节省了时间。 我通过阅读 File.ReadLines 如何(间接)解决同样的问题发现了这种模式。 所有这些代码都可供阅读。它是开源的!
FileOpenHandleRuneBenchmark 使用 Rune 类而不是 Encoding。结果发现速度变慢了,部分原因是我回到了更基本的算法。将 IndexOfAny 或 SearchValues 与 Rune 一起使用并不明显,部分原因是 Rune 没有与 detector.GetChars 类似的东西。
public static Count Count(string path)
{
long wordCount = 0, lineCount = 0, byteCount = 0;
bool wasSpace = true;
byte[] buffer = ArrayPool<byte>.Shared.Rent(BenchmarkValues.Size);
using Microsoft.Win32.SafeHandles.SafeFileHandle handle = File.OpenHandle(path, FileMode.Open, FileAccess.Read, FileShare.Read, FileOptions.SequentialScan);
int index = 0;
// Read content in chunks, in buffer, at count length, starting at byteCount
int count = 0;
while ((count = RandomAccess.Read(handle, buffer.AsSpan(index), byteCount)) > 0 || index > 0)
{
byteCount += count;
Span<byte> bytes = buffer.AsSpan(0, count + index);
index = 0;
while (bytes.Length > 0)
{
OperationStatus status = Rune.DecodeFromUtf8(bytes, out Rune rune, out int bytesConsumed);
// bad read due to low buffer length
if (status == OperationStatus.NeedMoreData && count > 0)
{
bytes[..bytesConsumed].CopyTo(buffer); // move the partial Rune to the start of the buffer before next read
index = bytesConsumed;
break;
}
if (Rune.IsWhiteSpace(rune))
{
if (rune.Value is '\n')
{
lineCount++;
}
wasSpace = true;
}
else if (wasSpace)
{
wordCount++;
wasSpace = false;
}
bytes = bytes.Slice(bytesConsumed);
}
}
ArrayPool<byte>.Shared.Return(buffer);
return new(lineCount, wordCount, byteCount, path);
}这里没有太大的不同,这是一件好事。Rune很大程度上是char的替代品。
下面这行代码是关键的区别。
var status = Rune.DecodeFromUtf8(bytes, out Rune rune, out int bytesConsumed);我想要一个从 Span<byte> 返回 Unicode 字符并报告读取了多少字节的 API。 它可以是 1 到 4 个字节。 Rune.DecodeFromUtf8 就是这样做的。就我的目的而言,我并不在乎我得到是Rune还是char。它们都是结构体。
我把 FileOpenHandleAsciiCheatBenchmark 留到最后。 我想看看如果可以应用最大数量的假设,代码的运行速度会有多快。 简而言之,只使用 ASCII 算法会是什么样子?
public static Count Count(string path)
{
const byte NEWLINE = (byte)'\n';
const byte SPACE = (byte)' ';
ReadOnlySpan<byte> searchValues = [SPACE, NEWLINE];
long wordCount = 0, lineCount = 0, byteCount = 0;
bool wasSpace = true;
byte[] buffer = ArrayPool<byte>.Shared.Rent(BenchmarkValues.Size);
using Microsoft.Win32.SafeHandles.SafeFileHandle handle = File.OpenHandle(path, FileMode.Open, FileAccess.Read, FileShare.Read, FileOptions.SequentialScan);
// Read content in chunks, in buffer, at count length, starting at byteCount
int count = 0;
while ((count = RandomAccess.Read(handle, buffer, byteCount)) > 0)
{
byteCount += count;
Span<byte> bytes = buffer.AsSpan(0, count);
while (bytes.Length > 0)
{
// what's this character?
if (bytes[0] <= SPACE)
{
if (bytes[0] is NEWLINE)
{
lineCount++;
}
wasSpace = true;
bytes = bytes.Slice(1);
continue;
}
else if (wasSpace)
{
wordCount++;
}
// Look ahead for next space or newline
// this logic assumes that preceding char was non-whitespace
int index = bytes.IndexOfAny(searchValues);
if (index > -1)
{
if (bytes[index] is NEWLINE)
{
lineCount++;
}
wasSpace = true;
bytes = bytes.Slice(index + 1);
}
else
{
wasSpace = false;
bytes = [];
}
}
}
ArrayPool<byte>.Shared.Return(buffer);
return new(lineCount, wordCount, byteCount, path);
}这段代码与您之前看到的代码几乎相同,除了它搜索的字符少很多,这加快了算法的速度。您可以在本文前面的图表中看到这一点。这里没有使用SearchValues,因为它没有针对两个值进行优化。
$ dotnet run -c Release 1 3
FileOpenHandleAsciiCheatBenchmark
11716 110023 610515 /Users/rich/git/convenience/wordcount/wordcount/bin/Release/net8.0/Clarissa_Harlowe/clarissa_volume1.txt该算法仍然能够产生预期的结果。这只是因为文本文件满足了代码的假设。
总结:File.Open 和 File.OpenHandle 提供最高的控制和性能。对于文本数据,虽然它们可以提供比File.OpenText(带字符)更好的性能,但它们显然不值得付出额外的努力。在这种情况下,这些 API 需要匹配字节数基线。对于非文本数据,这些 API 是更明智的选择。
总结
System.IO 提供了涵盖许多用例的高效 API。我喜欢使用 File.ReadLines 创建简单算法。 它非常适合基于行的内容。 File.OpenText 可以在不增加复杂性的情况下编写更快的算法。 最后,File.Open 和 File.OpenHandle 非常适合访问文件的二进制内容并能够编写最高性能和最准确的算法。
我并没有打算如此深入地探索 .NET 全球化 API 或 Unicode。我以前使用过编码 API,但从未尝试过Rune。这些 API 非常适合我的项目而且它们的性能很好,给我留下了深刻的印象。这些 API 是使本文便利的前提下的一个令人惊讶的典型例子。便利并不意味着“高级”,而是“合适且平易近人的工作工具”。
另一个见解是,对于这个问题,高级 API 既方便又有效,然而,只有低级 API 能够完成与wc结果完全匹配的任务。当我开始这个项目时,我并不理解这种动态,但是,我很高兴所需的 API 触手可及。
感谢Levi Broderick审阅了基准测试并帮助我更好地理解 Unicode 的细节。感谢David Fowler、Jan Kotas和Stephen Toub对本系列的帮助。
如果大家有任何的技术问题,欢迎到我们的官方的.NET中文论坛 提问。
0 comments
Be the first to start the discussion.