
本文翻译于Brennan Conroy的这篇英文文章:Performance improvements in ASP.NET Core 7。
性能是 .NET 的一个特性。在每个版本中,.NET 团队和社区贡献者都会花时间改进性能,为的是使.NET 应用程序更快并且使用更少的资源。
这篇博文重点介绍了 ASP.NET Core 7 中的一些性能改进。这是去年关于 ASP.NET Core 6 性能改进的文章的延续。当然,它继续受到 .NET 7 中的性能改进的启发。其中许多改进间接或直接地提高了 ASP.NET Core 的性能。
基准设置
我们将在这篇博文中的大部分示例中使用 BenchmarkDotNet。
首先设置基准测试项目:
- 创建一个新的控制台应用程序(dotnet new console)
- 添加对 BenchmarkDotnet 的 Nuget 引用(dotnet add package BenchmarkDotnet)version 0.13.2+
- 将Program.cs 更改为 var summary = BenchmarkSwitcher.FromAssembly(typeof(Program).Assembly).Run();
- 在下面添加您要运行的基准测试代码片段
- 运行 dotnet run -c Release 并在出现提示时输入要运行的基准测试的编号
有些基准测试内部类型,无法编写自包含基准。 在这些情况下,我将参考通过在存储库中运行基准获得的数字,或者我将提供一个简化的示例来展示改进的作用。
在某些情况下,我会参考我们在 https://aka.ms/aspnet/benchmarks 上公开的端到端基准。 但是我们只显示最近几个月的数据,是为了方便页面在合理的时间内加载。
通用服务器
Ampere 机器基于 ARM,具有许多内核,并且由于其较低的功耗和与 x64 机器的奇偶性而被用作云环境中的服务器。 作为 .NET 7 的一部分,我们确定了许多核心机器无法很好地扩展的一些领域,并修复它们以带来巨大的性能提升。 dotnet/runtime#69386 和 dotnet/aspnetcore#42237 分别对全局线程池队列和套接字连接使用的内存池进行了分区。 分区使内核能够在自己的队列上运行,这有助于减少争用并提高大型内核计算机的可扩展性。 在我们的 80 核 Ampere 机器上,明文平台基准提高 514%,240 万 RPS 到 1460 万 RPS,JSON 平台提高 311%,270k RPS 到 110 万 RPS!
为了提高性能,我们做了一些权衡。 首先,工作项到全局线程队列的严格 FIFO 排序不再得到保证,因为现在有多个队列被读取。 其次,当机器由于工作窃取而处于低负载状态时,需要更多的队列来搜索工作,CPU 使用率可能会略有增加。
dotnet/runtime#64834 带来了一个重大变化(特定于 Windows),它将 Windows IO 池切换为使用托管实现。 虽然这一变化本身带来了性能改进,例如我们的 JSON 平台基准测试的 RPS 增加了约 11%,但它还允许我们在 dotnet/aspnetcore#43449 中删除之前存在的 Kestrel 中的线程池调度 IO 线程。 在 Windows 上删除调度使 RPS 再增加约 18%,导致总 RPS 增加约 27%,从 800k RPS 增加到 110 万 RPS。
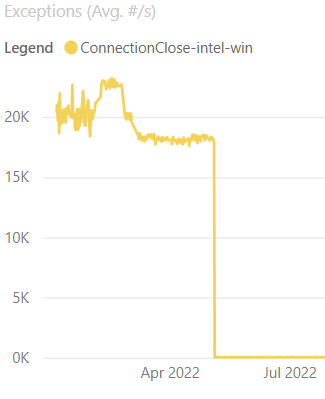
抛出异常可能代价高昂,并且 dotnet/aspnetcore#38094 标识了 Kestrel 的 Socket 传输中的一个区域,我们可以避免在连接关闭期间在某个层抛出异常。 在我们的连接关闭基准测试中,不抛出异常会降低 CPU 使用率。 Linux 上 50% 到 40% CPU,Windows 上 15% 到 14% CPU,28 核 ARM Linux 上 24% 到 18% CPU! 更改的另一个不错的副作用是每秒的异常数量(如下图所示)急剧下降,这总是一件好事。
我们在 6.0 中开始使用 PoolingAsyncValueTaskMethodBuilder 和 dotnet/aspnetcore#35011,它更新了 Kestrel 中的许多 ReadAsync 方法,以减少从请求中读取时使用的内存。 在 7.0 中,我们将 PoolingAsyncValueTaskMethodBuilder 应用于 dotnet/aspnetcore#41345、dotnet/runtime#68467 和 dotnet/runtime#68457 中的更多方法。
WebSockets 是展示分配差异的绝佳示例,因为它们是从请求中多次读取的长期连接。 在下图中,一个基准测试在单个 WebSocket 连接上执行了 1000 次读取。
在 6.0 中,1000 次读取会导致分配 3000 个状态机。
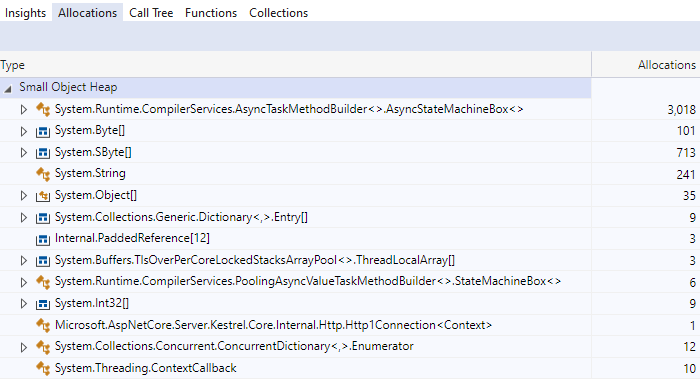
深入研究它们,我们可以看到每次读取三个独立的状态机。

在 7.0 中,所有状态机分配都已从 WebSocket 连接读取中消除。
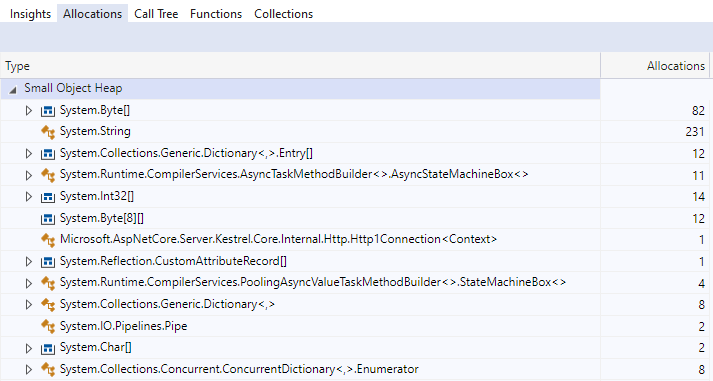
请注意,PoolingAsyncValueTaskMethodBuilder 不仅仅是免费的性能,并且可以用于所有异步 API。 虽然从分配的角度来看它可能看起来不错并且可以改进微基准,但它在实际应用程序中的表现可能会更差。 池化在承诺使用之前会被彻底测量,这就是为什么我们只将此功能应用于特定 API 的原因。
HTTP/2
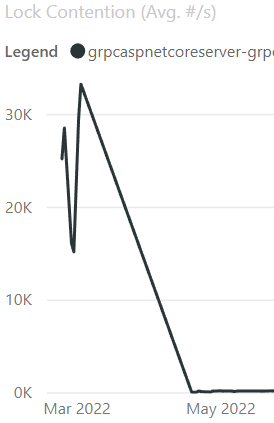
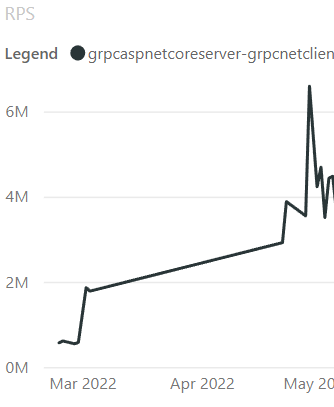
在 6.0 中,我们在 Kestrel 的 HTTP/2 处理中发现了一个锁争用较高的区域。 HTTP/2 具有单个连接上的多个流的概念。当一个流写入连接时,它需要一个可以阻塞其他并发流的锁。我们尝试了几种不同的方法来提高并发性。我们发现了一个潜在的改进,方法是对 Channel 的写入进行排队,并让单个消费者任务处理队列并完成所有写入,从而消除了大部分的锁争用。PR dotnet/aspnetcore#40925 重写了 HTTP/2 输出处理以使用 Channel 方法,结果不言而喻。使用每个连接 70 个流和 28 个连接的 gRPC 基准测试,我们看到 110k RPS 和服务器 CPU 大约 14%,这是一个很好的指标,要么我们没有从客户端产生足够的负载,要么有什么东西阻止了服务器做更多的处理。更改后,RPS 变为 4.1m,服务器 CPU 现在为 100%,表明我们正在生成足够的负载,并且服务器不再被锁争用阻塞!这一变化还将单流多连接基准从 1.2m 提高到 6.8m RPS。这个基准测试不受锁争用的影响,并且在更改之前已经处于 100% CPU,所以当它通过改变我们处理 HTTP/2 帧的方式得到如此大的改进时,真是令人惊喜!
看到图表的显着改进总是很高兴,因此这里是更改前后的锁争用情况:
这是 RPS 的改进:
HTTP/2 中的另一个概念称为流控制。流控制是客户端和服务器都采用的协议,用于指定在等待发送更多数据之前可以向任一方发送多少数据。在连接开始时,窗口大小被指定并用作允许通过连接发送的最大数据量,直到接收到 WINDOW_UPDATE 帧。此帧指定已读取的数据量,并让发送者知道可以通过连接发送更多数据。默认情况下,Kestrel 使用 96kb 的窗口大小,一旦读取了大约一半的窗口,就会发送 WINDOW_UPDATE。窗口大小意味着上传大文件的客户端将在收到 WINDOW_UPDATE 帧之前一次将 48kb 到 96kb 发送到服务器。使用这些数字,我们可以粗略得出一个 108Mb 文件和 10ms 往返延迟需要多长时间。 108mb / 48kb = 2,250 段。 2,250 段 / 10 毫秒 = 22.5 秒上限。 108mb / 96kb = 1,125 段。下限 1,125 段 / 10ms = 11.25 秒。这些数字并不精确,因为在发送和处理数据时会有一些开销,但它们让我们大致了解了需要多长时间。 dotnet/aspnetcore#43302 将 Kestrel 使用的默认窗口大小增加到 768kb,并显示上传 108mb 文件现在需要 4.3 秒,而之前需要 26.9 秒。新的上限和下限变为 2.8 秒 – 1.4 秒,同样不考虑开销。
这就提出了一个问题,为什么不让窗口尽可能大以允许更快的上传呢? 原因是一次可以发送多少字节仍然存在连接级别限制,并且该限制是为了避免任何单个连接在服务器上使用过多的内存。
HTTP/3
ASP.NET Core 6 引入了对 HTTP/3 的实验性支持。 在 7.0 中,HTTP/3 不再是实验性的,但仍可选择加入。 许多使 HTTP/3 成为非实验性的更改都围绕着可靠性、正确性和最终确定 API 的形式。 但这并没有阻止我们进行性能改进。
让我们从 dotnet/aspnetcore#38826 的 900 倍性能提升开始,它提高了 HTTP/3 用于编码标头的 QPack 的性能。 客户端和服务器都使用 QPack,我们通过与 ASP.NET Core 中的服务器代码和 .NET 中的客户端代码 (HttpClient) 共享 .NET QPack 实现来利用这一点。 因此,对 QPack 的任何改进都将有益于客户端和服务器!
QPack 处理标头压缩以更有效地发送和接收标头。 dotnet/aspnetcore#38565 为 QPack 引入了一堆常见的头文件。 dotnet/aspnetcore#38681 通过压缩一些标头值进一步改进了 QPack。
给定Headers:
headers.ContentLength = 0; headers.ContentType = "application/json"; headers.Age = "0"; headers.AcceptRanges = "bytes"; headers.AccessControlAllowOrigin = "*";
最初 QPack 的输出是 109 个字节: 0x00 0x00 0x37 0x05 0x63 0x6F 0x6E 0x74 0x65 0x6E 0x74 0x2D 0x74 0x79 0x70 0x65 …
经过上面的两次改动后,QPack输出变成如下7个字节:0x00 0x00 0xEE 0xE0 0xE3 0xC2 0xC4
查看从 0x63 字节到 0x65 的字节,它们代表十六进制的 ASCII 字符串content-type。 在 .NET 7 中,我们将这些压缩到索引中,因此本示例中的每个标头都变成了一个字节。
在更改前后运行基准测试显示了 5 倍的改进。
| 更改前: | 方法 | 均值 | 错误 | 标准差 | 操作/秒 |
| DecodeHeaderFieldLine_Static_Multiple | 235.32 ns | 2.981 ns | 2.788 ns | 4,249,586.2 |
| 更改后: | 方法 | 均值 | 错误 | 标准差 | 操作/秒 |
| DecodeHeaderFieldLine_Static_Multiple | 45.47 ns | 0.556 ns | 0.520 ns | 21,992,040.2 |
其他
SignalR
dotnet/aspnetcore#41465 确定了 SignalR 中的一个区域,我们在该区域中一遍又一遍地分配相同的字符串。 通过缓存字符串并将它们与原始 Span<byte> 进行比较来删除分配。 该更改确实使代码路径零分配,但它使微基准测试慢了几纳秒(这可能很好,因为我们正在降低完整应用程序中的 GC 压力)。 尽管如此,我们对此并不完全满意,因此 dotnet/aspnetcore#41644 改进了修改。 它假定区分大小写的比较将是最常见的(在此用例中应该如此),并在进行相同大小写比较时避免使用 UTF8 编码。 .NET 7 代码现在可以免费且更快地分配。
| 方法 | 意思 | 错误 | 标准差 | 第0代 | 已分配 |
| StringLookup | 100.19 ns | 1.343 ns | 1.256 ns | 0.0038 | 32B |
| Utf8LookupBefore | 109.24 ns | 2.243 ns | 2.203 ns | – | – |
| Utf8LookupAfter | 85.20 ns | 0.831 ns | 0.777 ns | – | – |
Auth
来自@Kahbazi 中的 dotnet/aspnetcore#43210 缓存了 PolicyAuthorizationResult,因为它们是不可变的,并且在通常情况下,它们是使用相同的属性创建的。 您可以通过以下简化的基准测试来了解这有多有效。
[MemoryDiagnoser]public class CachedBenchmark{ private static readonly object _cachedObject = new object(); [Benchmark] public object GetObject() { return new object(); } [Benchmark] public object GetCachedObject() { return _cachedObject; }}
| 方法 | 均值 | 错误 | 标准差 | 第0代 | 已分配 |
| GetObject | 3.5884 ns | 0.0488 ns | 0.0432 ns | 0.0029 | 24B |
| GetCachedObject | 0.7896 ns | 0.0439 ns | 0.0389 ns | – | – |
dotnet/aspnetcore#43268,同样来自@Kahbazi,对 Authentication 中的多种类型应用了相同的更改,并在解析授权策略时额外添加了 Task<AuthorizationPolicy> 的缓存。 服务器在启动时了解授权策略,因此它可以预先创建所有任务并保存每个请求的任务分配。
[MemoryDiagnoser]
public class CachedBenchmark
{
private static readonly object _cachedObject = new object();
[Benchmark]
public object GetObject()
{
return new object();
}
[Benchmark]
public object GetCachedObject()
{
return _cachedObject;
}
}
| 方法 | 均值 | 错误 | 标准差 | 比率 | 第0代 | 已分配 |
| GetTask | 22.59 ns | 0.322 ns | 0.285 ns | 1.00 | 0.0092 | 72B |
| GetCachedTask | 11.70 ns | 0.065 ns | 0.055 ns | 0.52 | – | – |
dotnet/aspnetcore#43124 将缓存添加到授权中间件,这将避免针对每个端点的每个请求重新计算组合的 AuthorizationPolicy。 因为端点在启动后通常保持不变,我们不需要为每个请求从端点获取授权元数据并将它们组合成一个策略。 相反,我们可以在首次访问端点时缓存组合策略。 如果您实现自定义 IAuthorizationPolicyProvider 可以显着节省缓存,这些 IAuthorizationPolicyProvider 具有昂贵的操作,如数据库访问,并且只需要在应用程序的生命周期内运行一次。
HttpResult
dotnet/aspnetcore#40965 是探索多条路由以实现更好性能的绝佳示例。 目标是缓存 HttpResult 类型。 大多数结果类型类似于 UnauthorizedHttpResult,它没有参数,可以通过创建一次静态实例并始终返回它来缓存。 一个更有趣的结果是 StatusCodeHttpResult,可以给它任何整数来表示返回给调用者的状态码。 PR 探索了多种缓存 StatusCodeHttpResult 对象的方法,并展示了每种方法的性能数据。
| 已知状态码(例如 200): | 方法 | 均值 | 错误 | 标准差 | 0代 | 已分配 |
| NoCache | 2.725 ns | 0.0285 ns | 0.0253 ns | 0.0001 | 24B | |
| StaticCacheWithDictionary | 5.733 ns | 0.0373 ns | 0.0331 ns | – | – | |
| DynamicCacheWithFixedSizeArray | 2.184 ns | 0.0227 ns | 0.0212 ns | – | – | |
| DynamicCacheWithFixedSizeArrayPerStatusGroup | 3.371 ns | 0.0151 ns | 0.0134 ns | – | – | |
| DynamicCacheWithConcurrentDictionary | 5.450 ns | 0.1495 ns | 0.1468 ns | – | – | |
| StaticCacheWithSwitchExpression | 1.867 ns | 0.0045 ns | 0.0042 ns | – | – | |
| DynamicCacheWithSwitchExpression | 1.889 ns | 0.0143 ns | 0.0119 ns | – | – |
| 未知状态码(例如 150): | 方法 | 均值 | 错误 | 标准差 | 0代 | 已分配 |
| NoCache | 2.477 ns | 0.0818 ns | 0.1005 ns | 0.0001 | 24B | |
| StaticCacheWithDictionary | 8.479 ns | 0.0650 ns | 0.0576 ns | 0.0001 | 24B | |
| DynamicCacheWithFixedSizeArray | 2.234 ns | 0.0361 ns | 0.0302 ns | – | – | |
| DynamicCacheWithFixedSizeArrayPerStatusGroup | 4.809 ns | 0.0360 ns | 0.0281 ns | 0.0001 | 24B | |
| DynamicCacheWithConcurrentDictionary | 6.076 ns | 0.0672 ns | 0.0595 ns | – | – | |
| StaticCacheWithSwitchExpression | 4.195 ns | 0.0823 ns | 0.0770 ns | 0.0001 | 24B | |
| DynamicCacheWithSwitchExpression | 4.146 ns | 0.0401 ns | 0.0335 ns | 0.0001 | 24B
|
我们最终选择了“StaticCacheWithSwitchExpression”,它使用 T4 模板为众所周知的状态代码生成缓存字段,并使用 switch 表达式返回它们。 这种方法为已知状态代码提供了最佳性能,这将是大多数应用程序的常见情况。
IndexOfAny
来自@martincostello 的dotnet/aspnetcore#39743 注意到我们将长度为2 的char[] 传递给string.IndexOfAny 的一些地方。 char 数组重载比将 2 个字符直接传递给 ReadOnlySpan<char>.IndexOfAny 方法要慢。 此更改更新了多个调用站点以删除 char[] 并使用更快的方法。 请注意,IndexOfAny 为 2 和 3 个字符提供此方法。
public class IndexOfAnyBenchmarks
{
private const string AUrlWithAPathAndQueryString = "http://www.example.com/path/to/file.html?query=string";
private static readonly char[] QueryStringAndFragmentTokens = new[] { '?', '#' };
[Benchmark(Baseline = true)]
public int IndexOfAny_String()
{
return AUrlWithAPathAndQueryString.IndexOfAny(QueryStringAndFragmentTokens);
}
[Benchmark]
public int IndexOfAny_Span_Array()
{
return AUrlWithAPathAndQueryString.AsSpan().IndexOfAny(QueryStringAndFragmentTokens);
}
[Benchmark]
public int IndexOfAny_Span_Two_Chars()
{
return AUrlWithAPathAndQueryString.AsSpan().IndexOfAny('?', '#');
}
}
| 方法 | 均值 | 错误 | 标准差 | 比率 |
| IndexOfAny_String | 7.004 ns | 0.1166 ns | 0.1091 ns | 1.00 |
| IndexOfAny_Span_Array | 6.847 ns | 0.0371 ns | 0.0347 ns | 0.98 |
| IndexOfAny_Span_Two_Chars | 5.161 ns | 0.0697 ns | 0.0582 ns | 0.73 |
过滤器
在 .NET 7 中,我们为 Minimal API 引入了过滤器。 在设计该功能时,我们非常注重性能。 我们在预览期间分析了过滤器,以找到在功能初始合并后可以提高代码性能的领域。
dotnet/aspnetcore#41740 修复了我们在使用过滤器时为每个对无参数端点的请求分配一个空数组的情况。 这可以通过使用 Array.Empty<object>() 而不是 new object[0] 来解决。 这似乎很明显,但是在编写表达式树时,这很容易做到。
dotnet/aspnetcore#41379 删除了 Minimal API 中 ValueTask<object> 返回方法的装箱分配,这是用于包装用户提供的委托的过滤器。 删除装箱使得添加过滤器的唯一开销是分配一个上下文对象,该对象允许用户代码检查从请求到其端点的参数。
dotnet/aspnetcore#41406 通过在端点中添加 1 到 10 个参数,参数的通用类实现改进了创建过滤上下文对象的分配。 此更改避免了用于保存参数值的 object[] 分配以及使用结构参数时可能发生的任何装箱。 可以通过一个简化的示例来显示改进:
[MemoryDiagnoser]
public class FilterContext
{
internal abstract class Context
{
public abstract T GetArgument<T>(int index);
}
internal sealed class DefaultContext : Context
{
public DefaultContext(params object[] arguments)
{
Arguments = arguments;
}
private IList<object?> Arguments { get; }
public override T GetArgument<T>(int index)
{
return (T)Arguments[index]!;
}
}
internal sealed class Context<T0> : Context
{
public Context(T0 argument)
{
Arg0 = argument;
}
public T0 Arg0 { get; set; }
public override T GetArgument<T>(int index)
{
return index switch
{
0 => (T)(object)Arg0!,
_ => throw new IndexOutOfRangeException()
};
}
}
[Benchmark]
public TimeSpan GetArgBoxed()
{
var defaultContext = new DefaultContext(new TimeSpan());
return defaultContext.GetArgument<TimeSpan>(0);
}
[Benchmark]
public TimeSpan GetArg()
{
var typedContext = new Context<TimeSpan>(new TimeSpan());
return typedContext.GetArgument<TimeSpan>(0);
}
}
| 方法 | 均值 | 错误 | 标准差 | 第0代 | 已分配 |
| GetArgBoxed | 16.865 ns | 0.1878 ns | 0.1466 ns | 0.0102 | 80B |
| GetArg | 3.292 ns | 0.0806 ns | 0.0792 ns | 0.0031 | 24B |
总结
请试用 .NET 7,让我们知道您的应用程序的性能发生了怎样的变化! 我们一直在寻找有关如何改进产品的反馈,并期待您的贡献,无论是问题报告还是 PR。 如果您想要更多的性能优势,您可以阅读 .NET 7 中的性能改进帖子。 此外,请查看开发人员故事,其中展示了 Microsoft 的多个团队从 .NET Framework 迁移到 .NET Core 并看到主要性能和 COGS 的胜利。
感谢您成为.NET中的一员!
0 comments
Be the first to start the discussion.